Downloaded 284 times






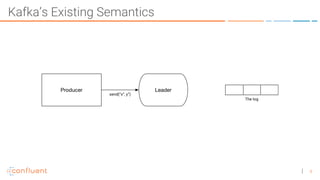
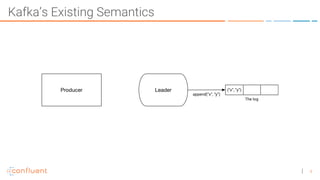
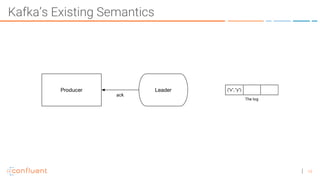
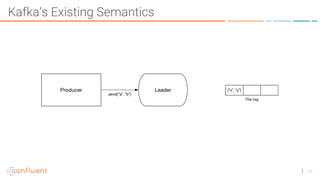
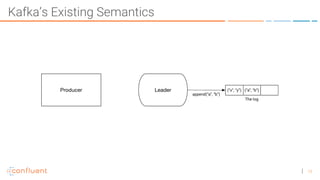
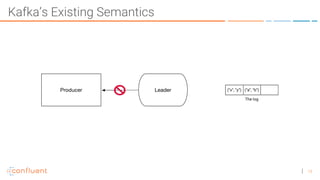
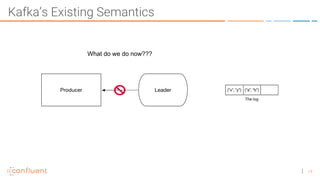
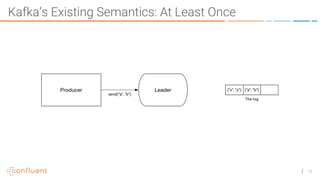
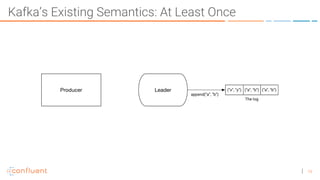
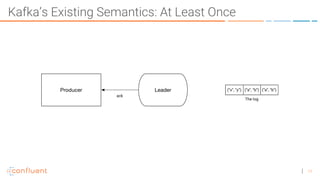




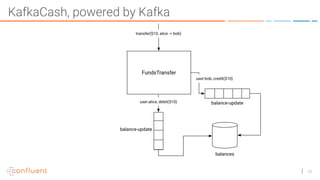
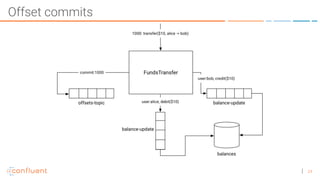
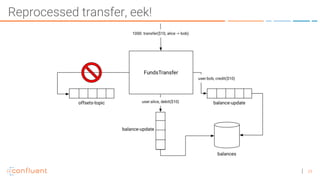
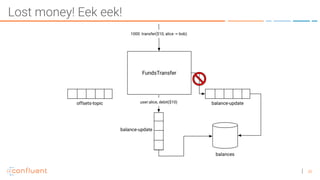





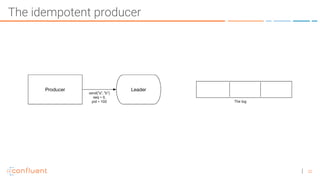
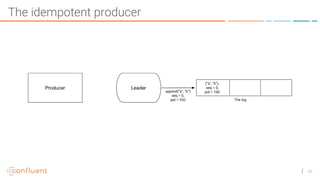
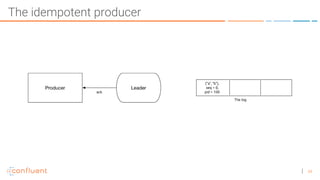
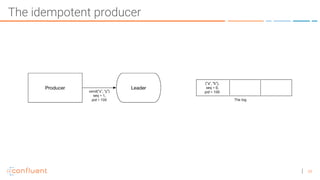
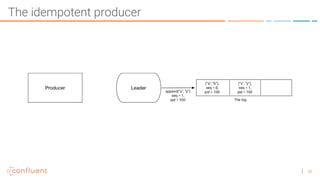
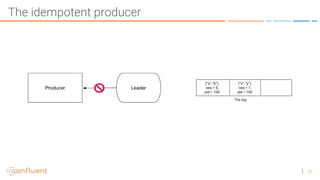
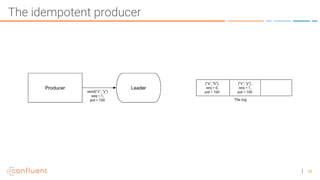
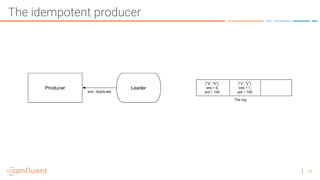





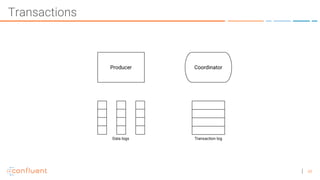

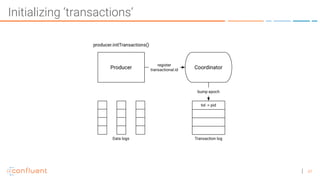

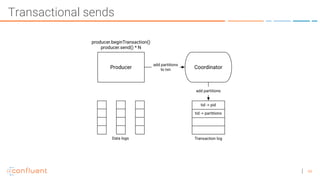
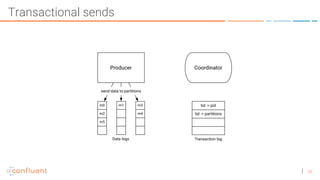

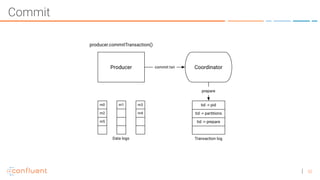
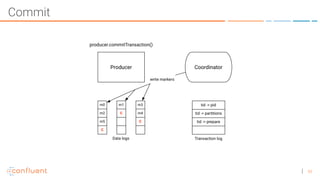
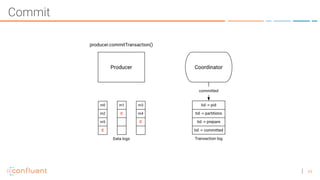
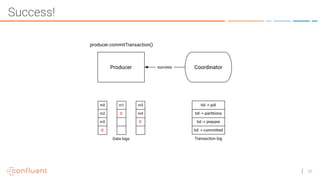






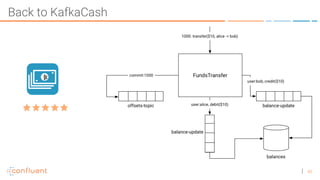


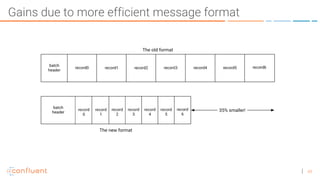


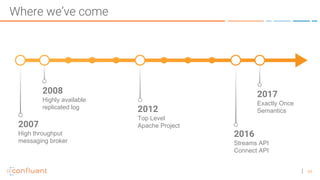



The document discusses the introduction of exactly-once semantics in Apache Kafka, outlining its significance for reliable stream processing. It explains the challenges and existing semantics, highlighting improvements through idempotent producers and transactional writes. The presentation concludes with insights on performance gains and future developments in Kafka's capabilities.



















































































![Lect 1 Number systems and base conversions. [Autosaved].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/lect1numbersystemsandbaseconversions-260111134109-67c2d865-thumbnail.jpg?width=640&height=640&fit=bounds)
















