Downloaded 438 times























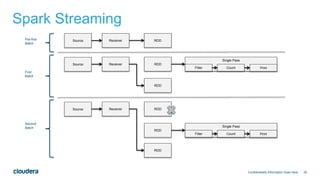

errCountStream.foreachRDD(rdd => {
System.out.println("Errors this minute:%d".format(rdd.first()._2))
})
Click to enter confidentiality information](https://image.slidesharecdn.com/stratasj-robustdecisionmaking-150221002740-conversion-gate01/85/Data-Architectures-for-Robust-Decision-Making-36-320.jpg)

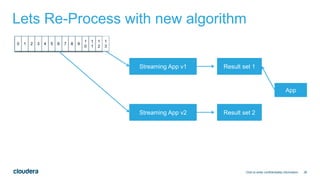
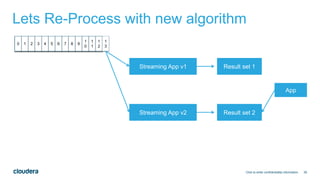
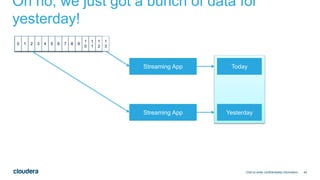



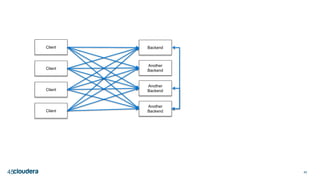
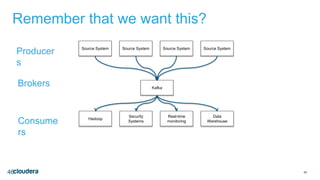
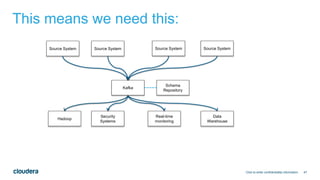








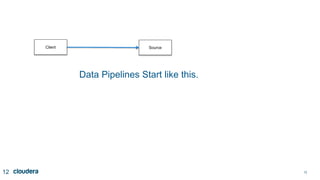
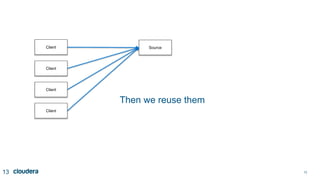
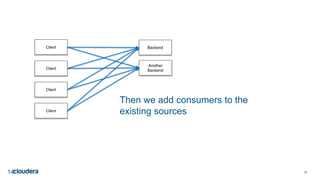
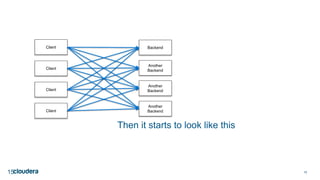
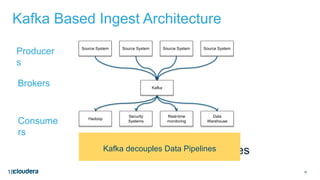
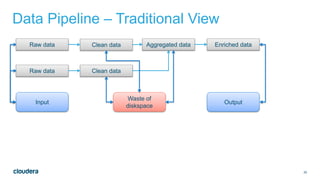
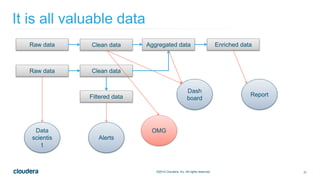
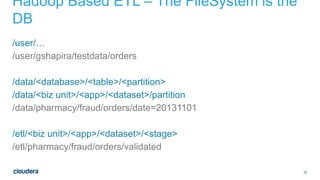
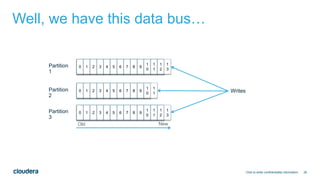
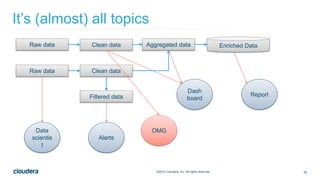
The document discusses designing robust data architectures for decision making. It advocates for building architectures that can easily add new data sources, improve and expand analytics, standardize metadata and storage for easy data access, discover and recover from mistakes. The key aspects discussed are using Kafka as a data bus to decouple pipelines, retaining all data for recovery and experimentation, treating the filesystem as a database by storing intermediate data, leveraging Spark and Spark Streaming for batch and stream processing, and maintaining schemas for integration and evolution of the system.





























































































