Downloaded 78 times













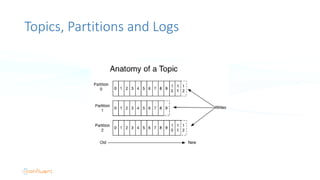
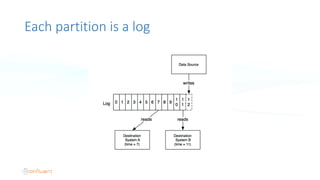
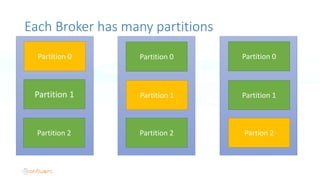
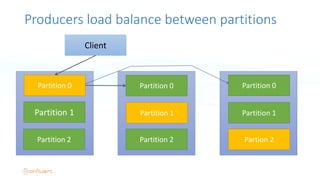
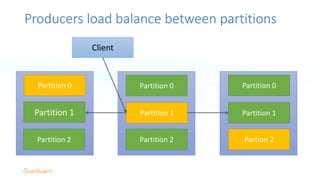
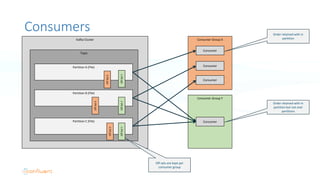





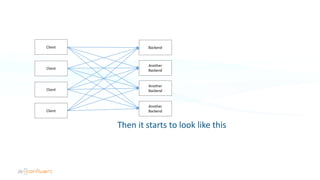
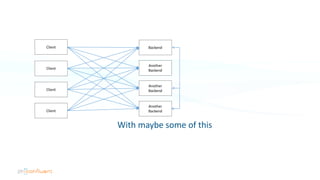

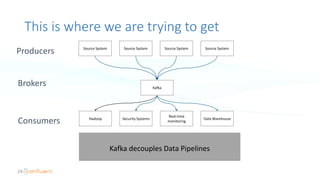



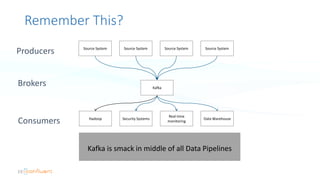

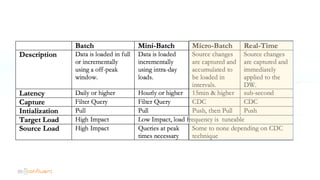

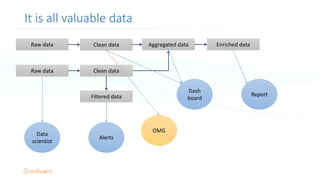

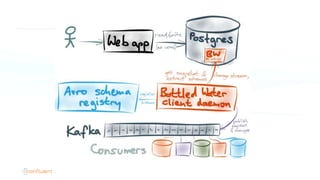
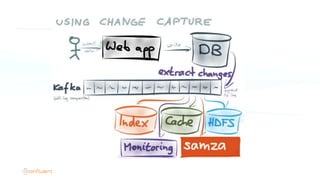





The document serves as an introduction to Apache Kafka and its applications in real-time ETL (Extract, Transform, Load) processes. It explains Kafka's architecture, data handling capabilities, and how it can decouple data pipelines while integrating various data sources. The author emphasizes Kafka's high performance, scalability, and versatility in modern data workflows.



































![Building streaming data applications using Kafka*[Connect + Core + Streams] b...](https://cdn.slidesharecdn.com/ss_thumbnails/buildingstreamingdataapplicationsusingapachekafka-171011211455-thumbnail.jpg?width=640&height=640&fit=bounds)



















































