Download as PDF, PPTX


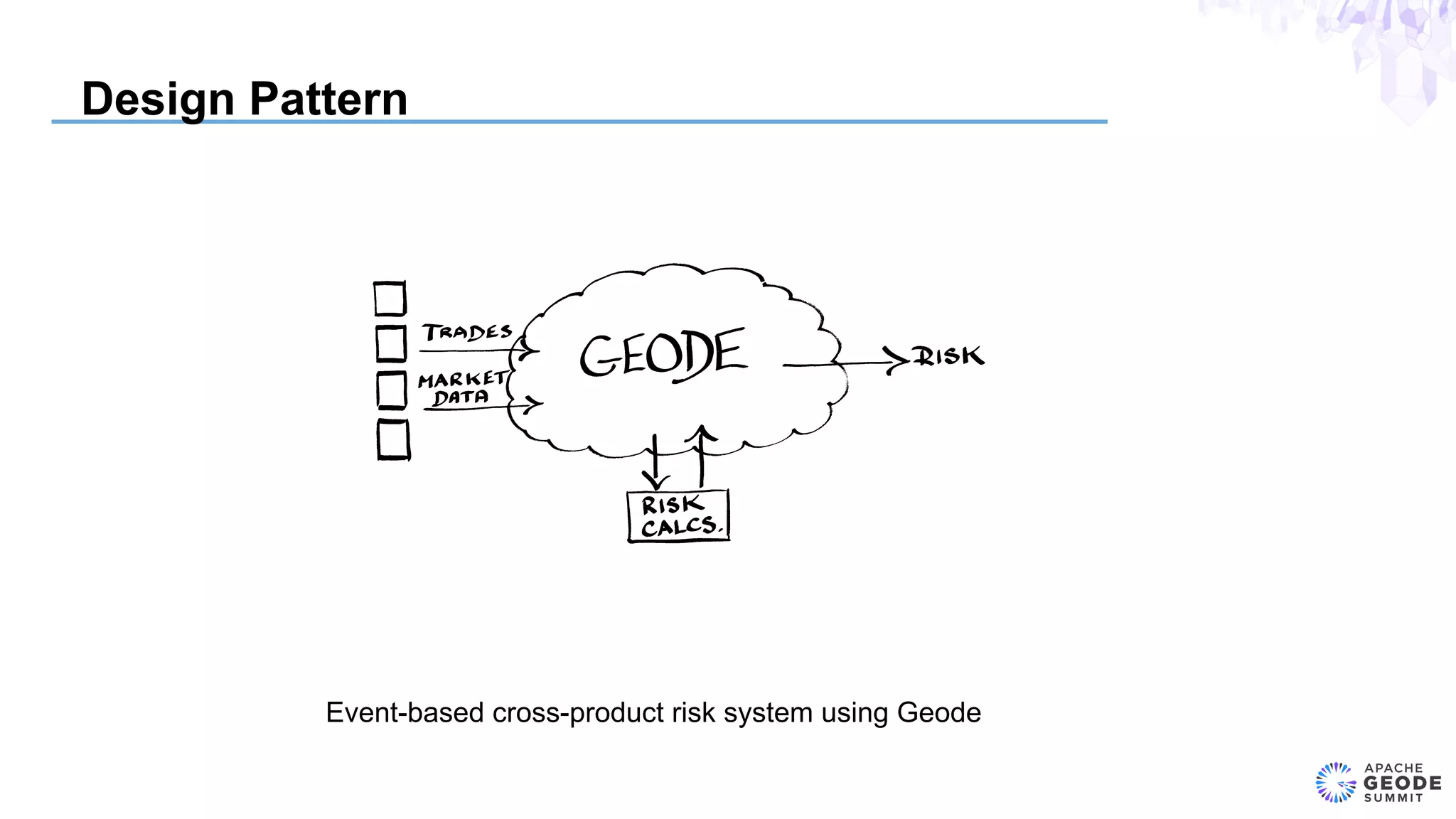



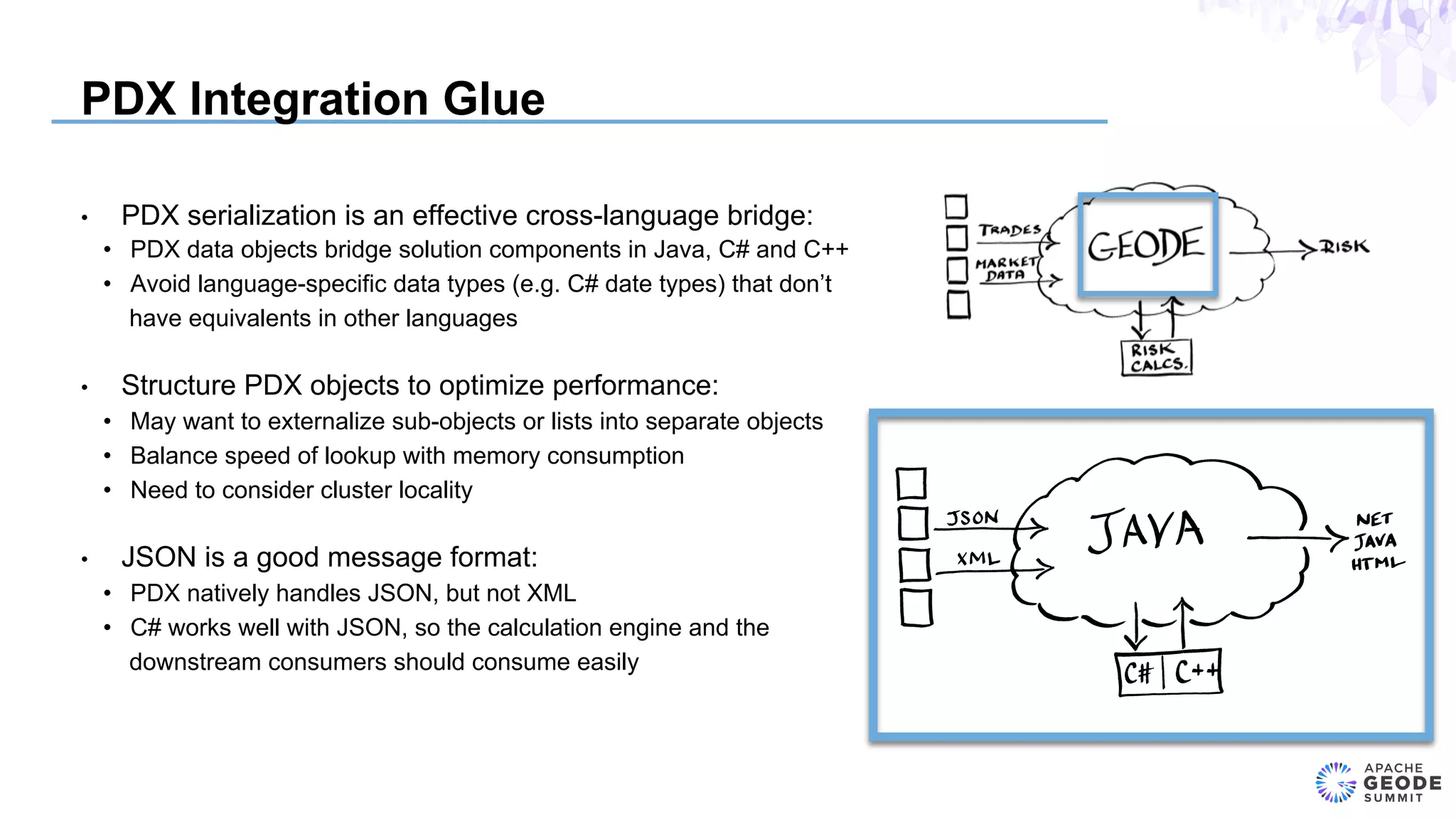
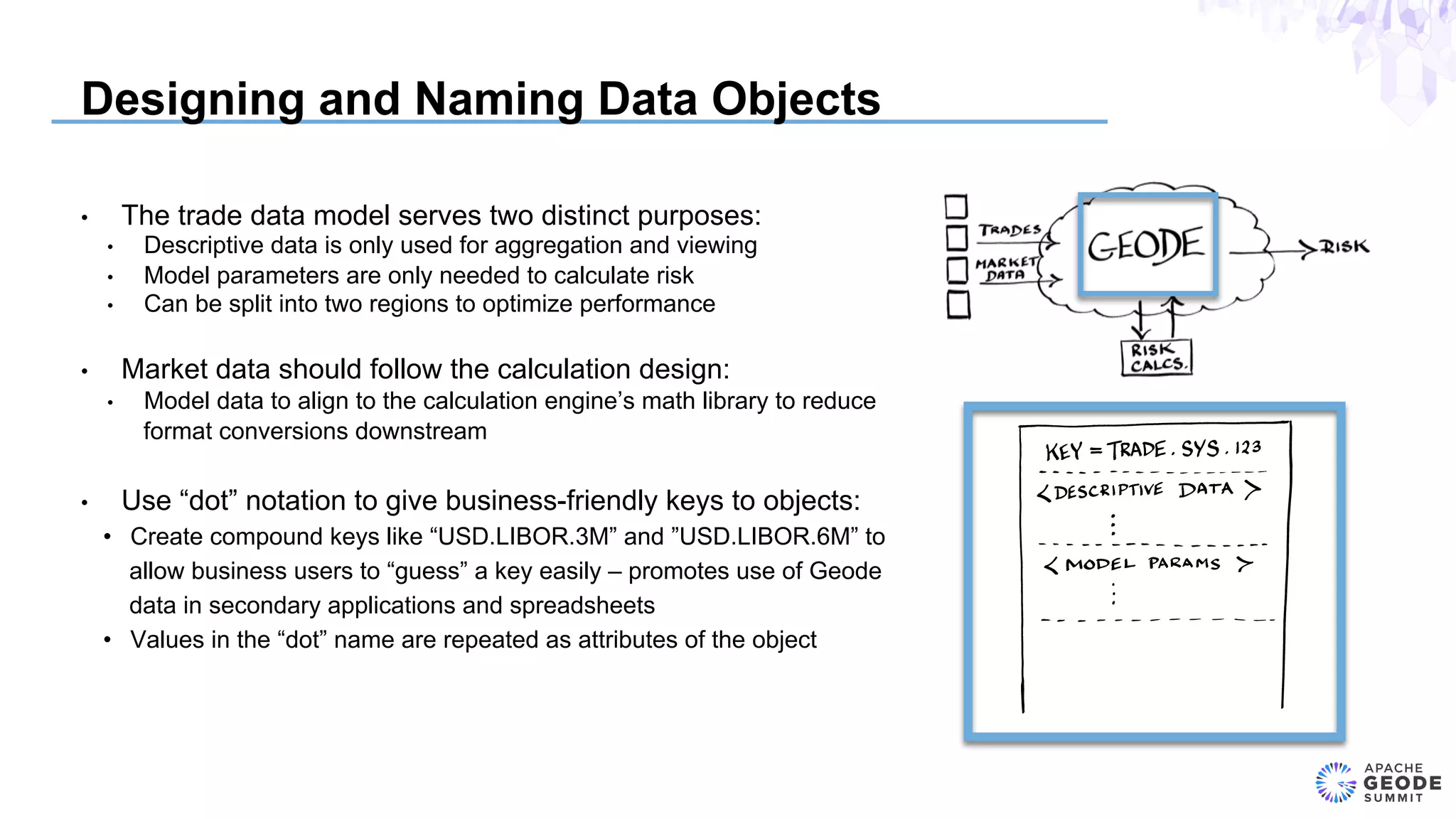
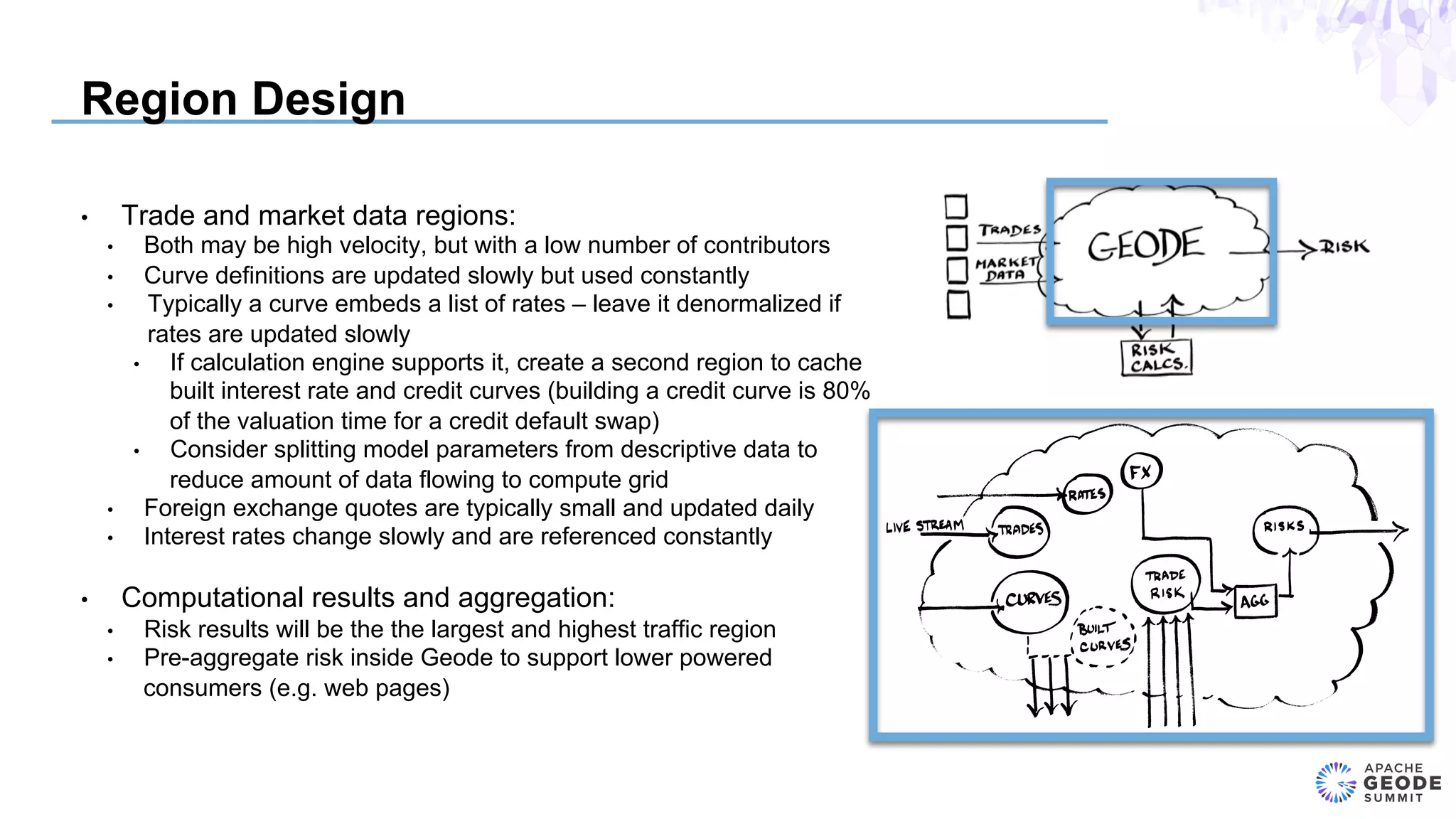
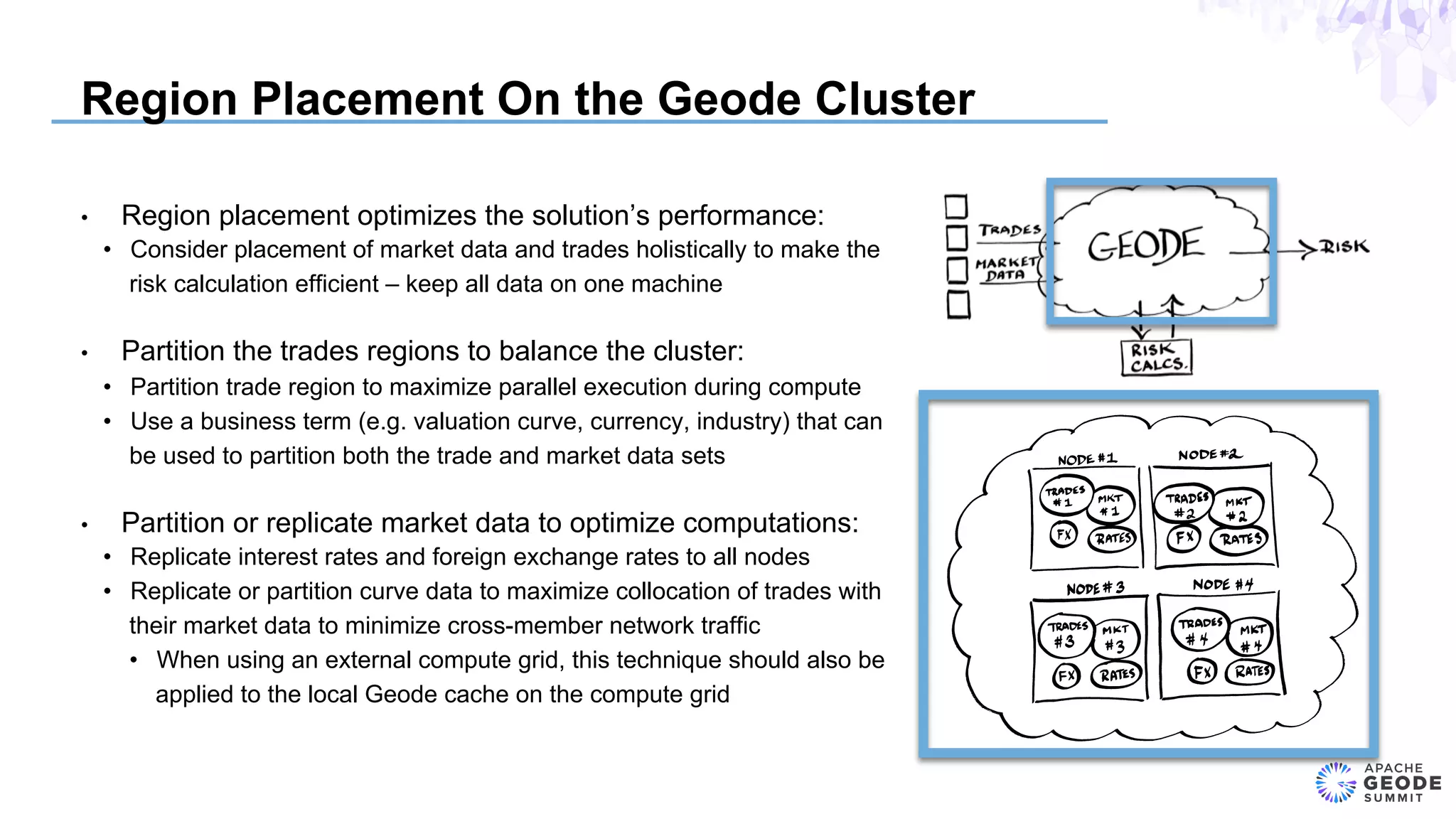
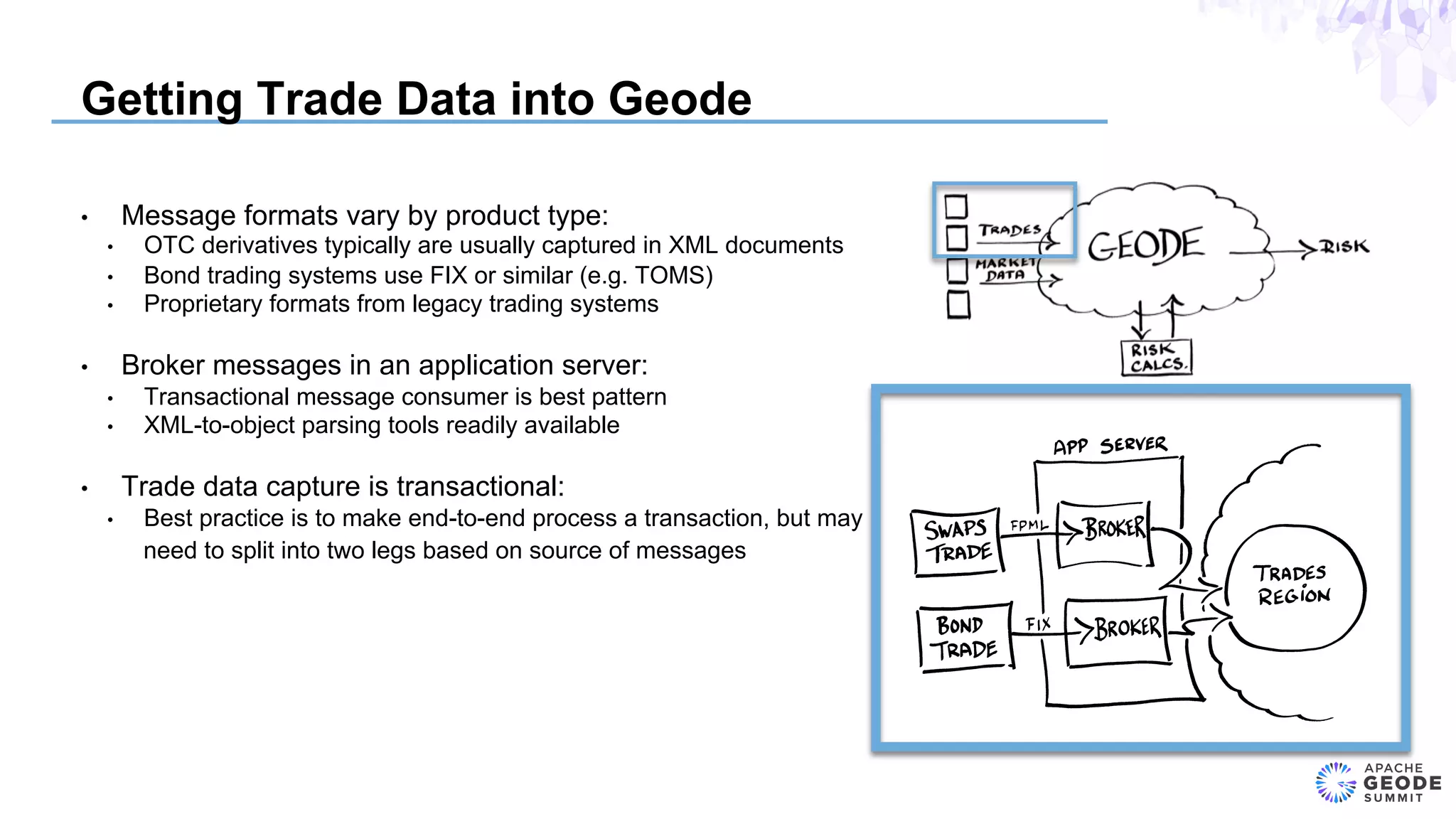
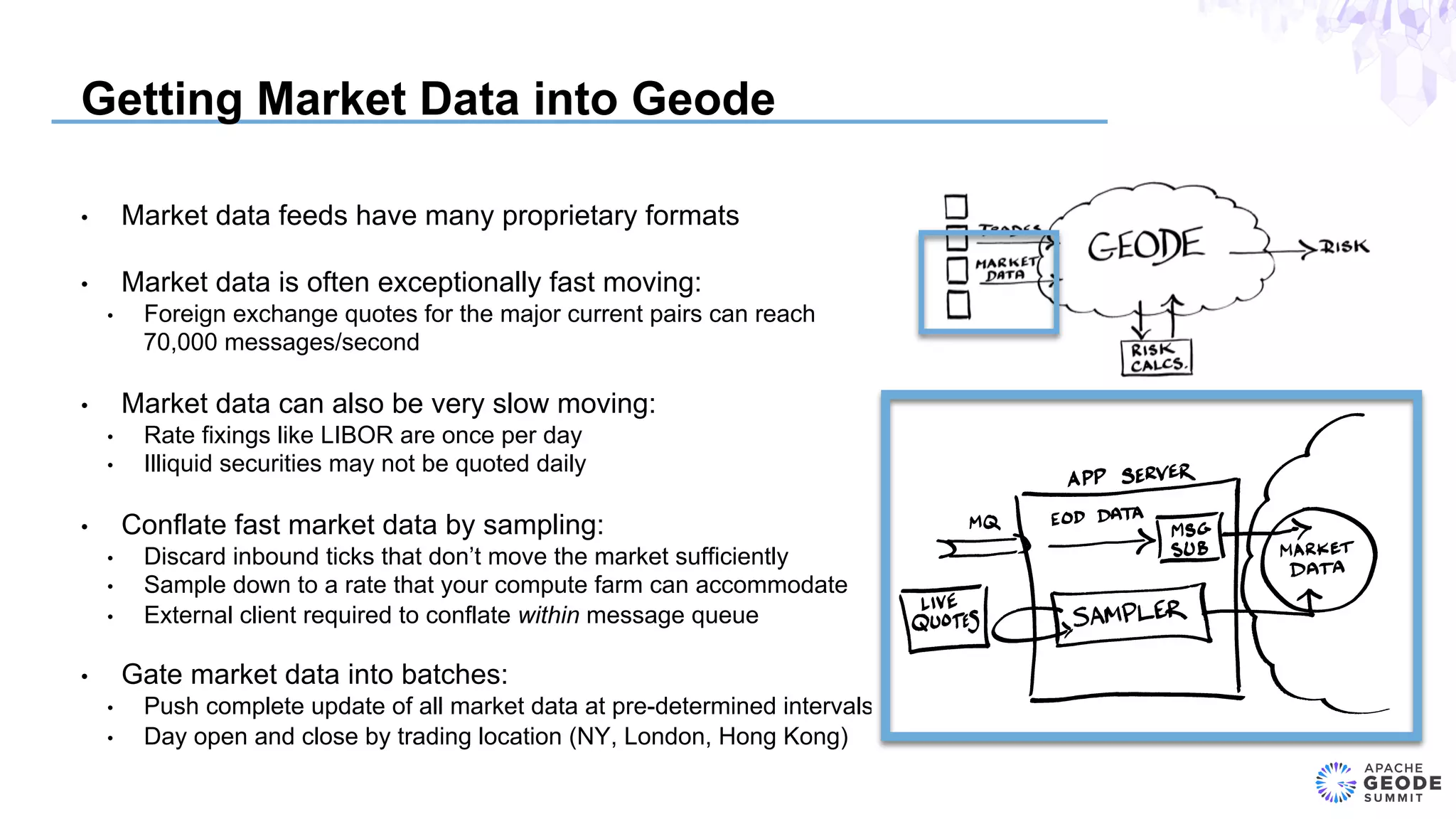
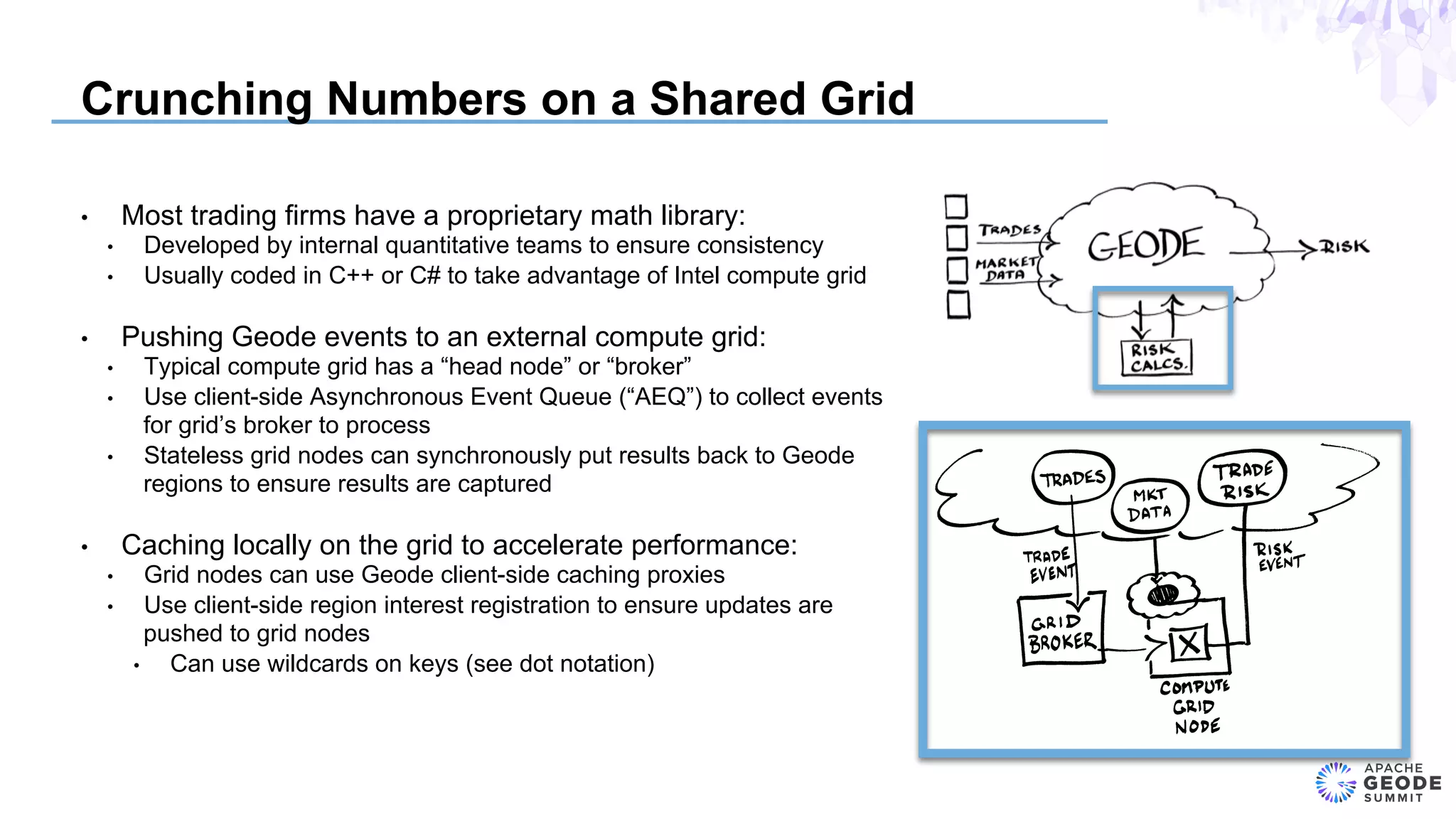
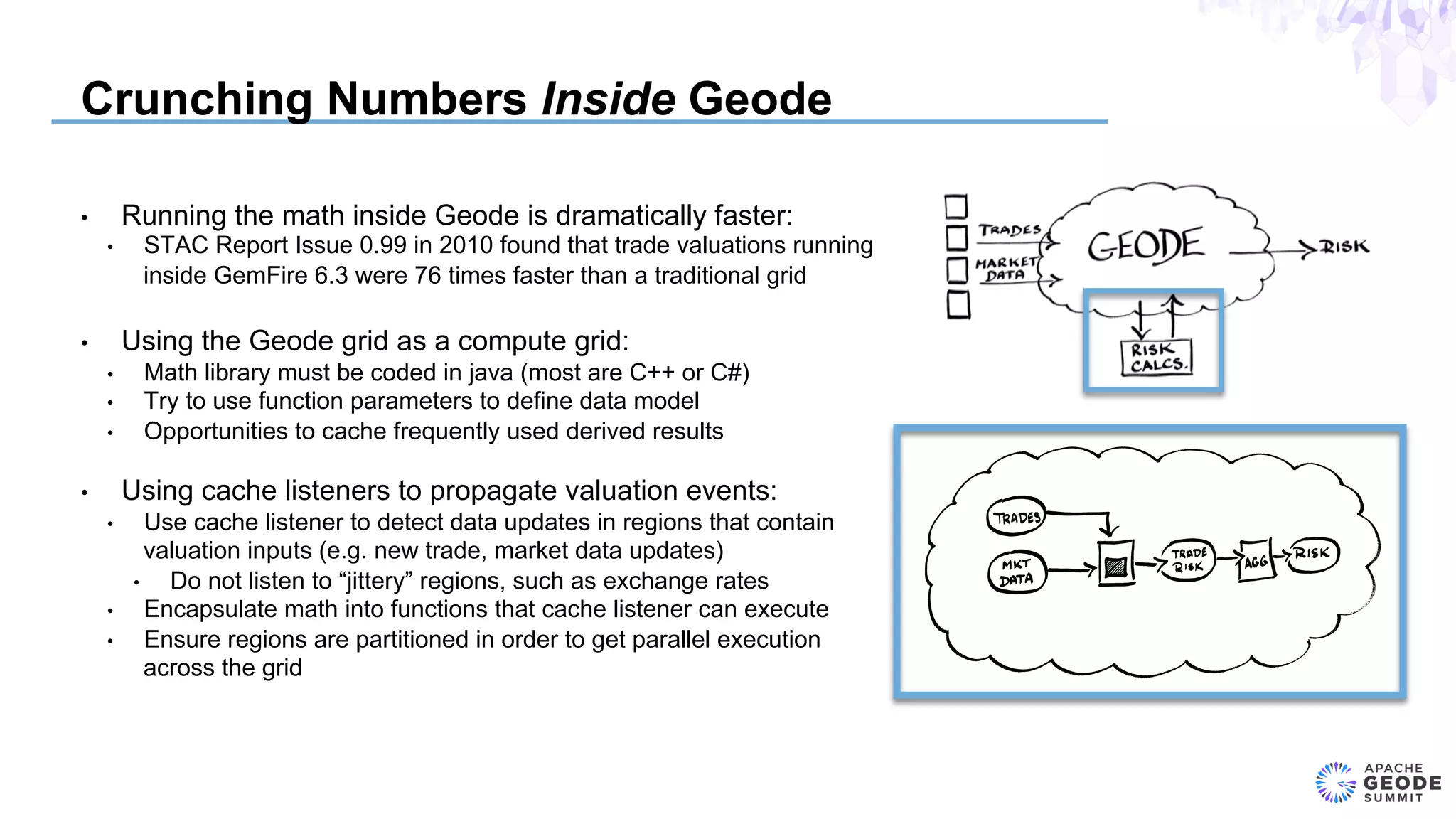
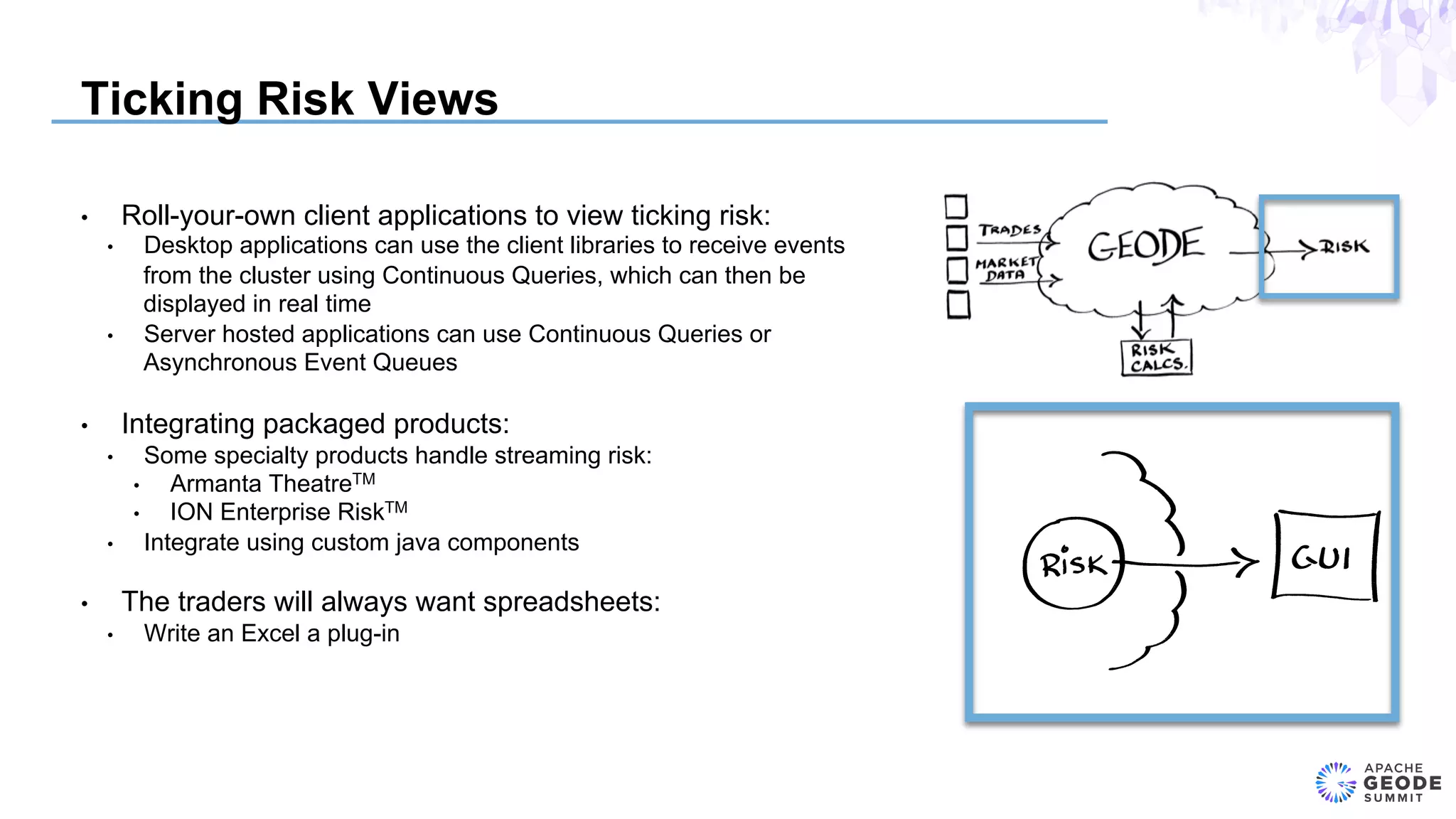



The document discusses the design of an event-based cross-product risk system for Wall Street trading firms using Apache Geode, focusing on the need for a consolidated risk view across various trading systems. It highlights the complexities of trading, risk measurement, and market data integration, emphasizing the importance of consistency and speed in computations. Additionally, the design elements, data object modeling, and performance optimization strategies for trading and market data within the Geode architecture are outlined.














































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)


















