Downloaded 23 times





























![© 2016 MapR Technologies 40© 2016 MapR Technologies 40
Option C?
• Create a POJO “Tick”
with a single byte[]
attribute, and getters
that return fields by
directly indexing the
byte[]
• Annotate getters with
@JsonProperty](https://image.slidesharecdn.com/pjugkafka-shareable-161020194517/85/Design-Patterns-for-working-with-Fast-Data-40-320.jpg)










![© 2016 MapR Technologies 52© 2016 MapR Technologies 52
Performance Anti-Pattern
• I want to stream JSON strings to simplify DB persistence and
columnar selections in Spark.
• Fine, I’ll just convert every message to a JSON object at the first step
of my pipeline and use a JSON serializer.
– Lesson learned: parsing is expensive! Handling parsing errors is expensive.
Custom serializers are not as easy I as thought.
– This anti-pattern is illustrated here: https://github.com/mapr-demos/finserv-ticks-
demo/commit/35a0ddaad411bf7cec34919a4817482df2bf6462
– Solution: Stream a data structure containing a byte[] to hold raw data, and
annotate it with com.fasterxml.jackson.annotation.JsonProperty.
– Example: https://github.com/mapr-demos/finserv-ticks-
demo/blob/35a0ddaad411bf7cec34919a4817482df2bf6462/src/main/java/com/mapr/demo/finserv/Tick2.java](https://image.slidesharecdn.com/pjugkafka-shareable-161020194517/85/Design-Patterns-for-working-with-Fast-Data-52-320.jpg)




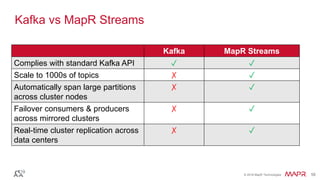

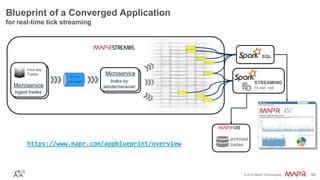
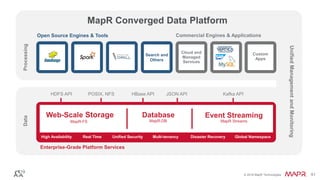



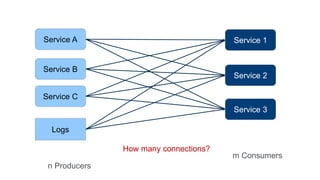
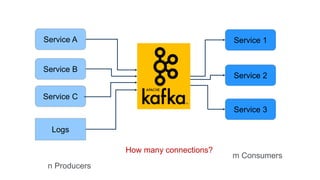
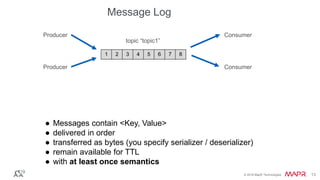
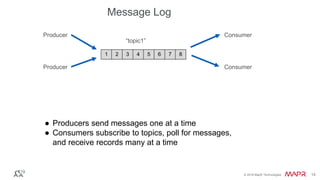
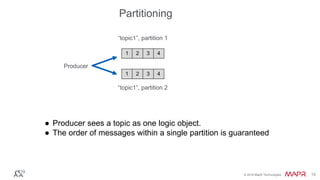
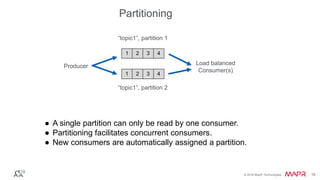
The document provides an introduction to Apache Kafka, explaining its capabilities as a distributed messaging system designed for fast data processing and storage. It covers various aspects of Kafka, including message delivery, partitioning, consumer groups, and performance factors, while offering code examples and demonstrations of its API. Key strategies for maximizing throughput are emphasized to help users effectively utilize Kafka in their applications.




















































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)









![7.__Developing_a_Research_Proposal[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/7-260131073037-df92dd7d-thumbnail.jpg?width=640&height=640&fit=bounds)
