Downloaded 19 times










![12© 2014 Pivotal Software, Inc. All rights reserved.
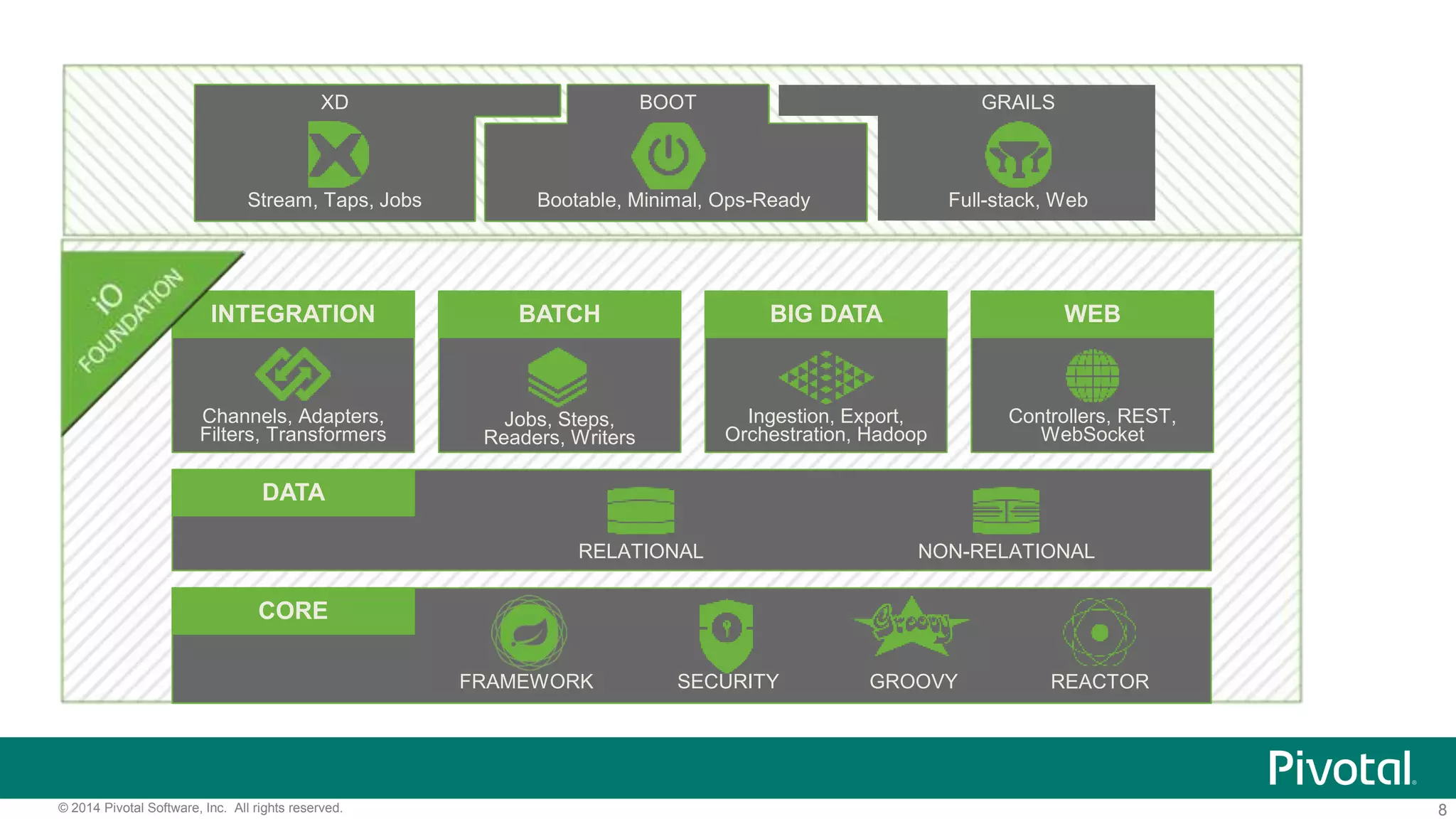
Bootstrapping Apache Geode with Spring
@SpringBootApplication
@ImportResource("/spring-gemfire-context.xml")
public class SpringGemFireApplication {
public static void main(String[] args) {
SpringApplication.run(SpringGemFireApplication.class, args);
}
}
gfsh>start server -–name=Example --spring-xml-location=
<classpath-to-spring-application-context.xml>](https://image.slidesharecdn.com/springdatagemfireapicurrentandfuture-160314235637/75/GeodeSummit-Spring-Data-GemFire-API-Current-and-Future-12-2048.jpg)



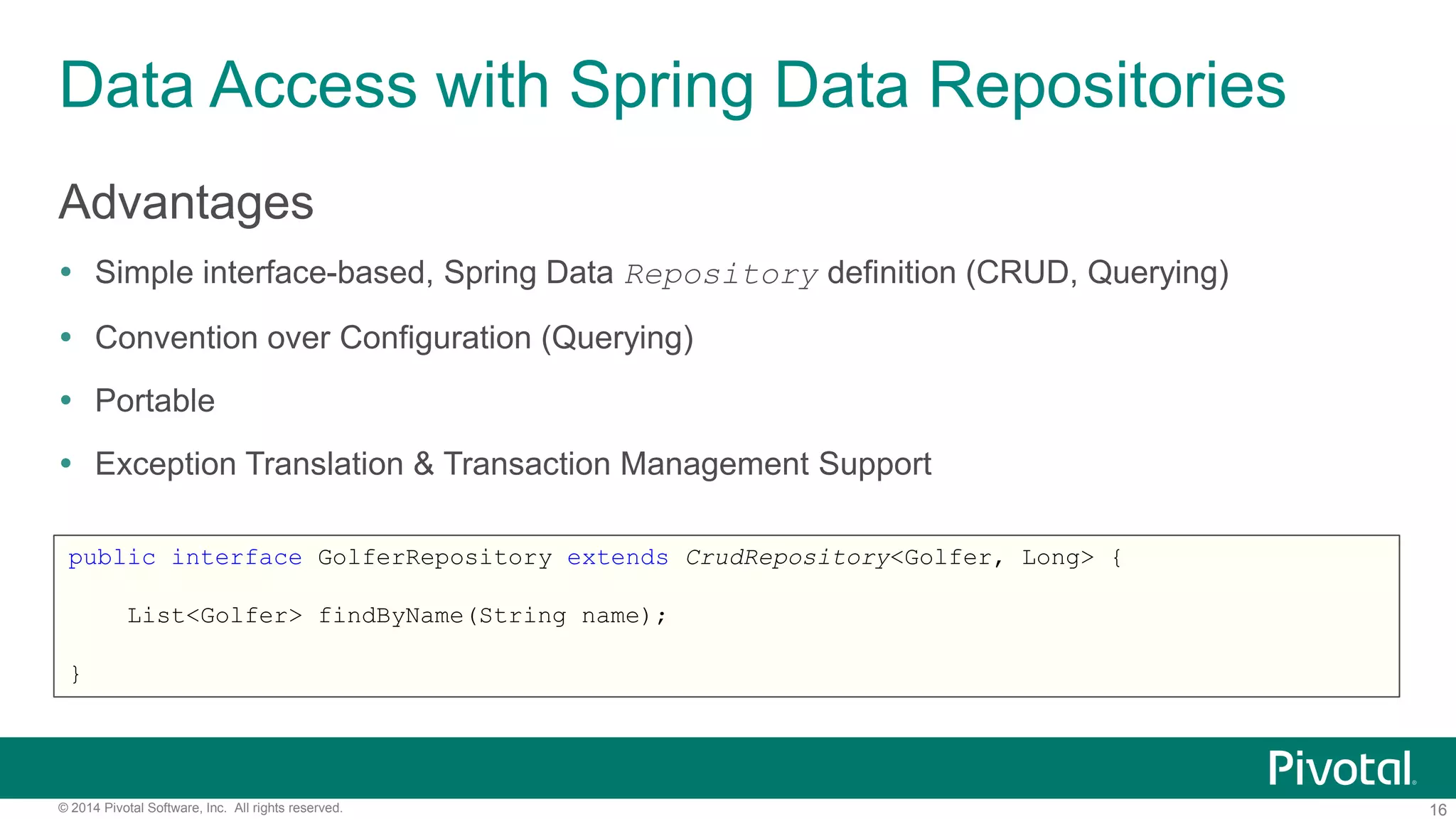



















The document discusses the Spring Data GemFire API, outlining its features, configuration, data access patterns, and future developments related to Apache Geode. It covers use cases such as cache configuration, application peer cache, and server/client interactions while highlighting benefits like simplified data access and integration within the Spring ecosystem. Additionally, it provides references for further exploration of Spring Data GemFire and Apache Geode resources.































































































