Downloaded 44 times




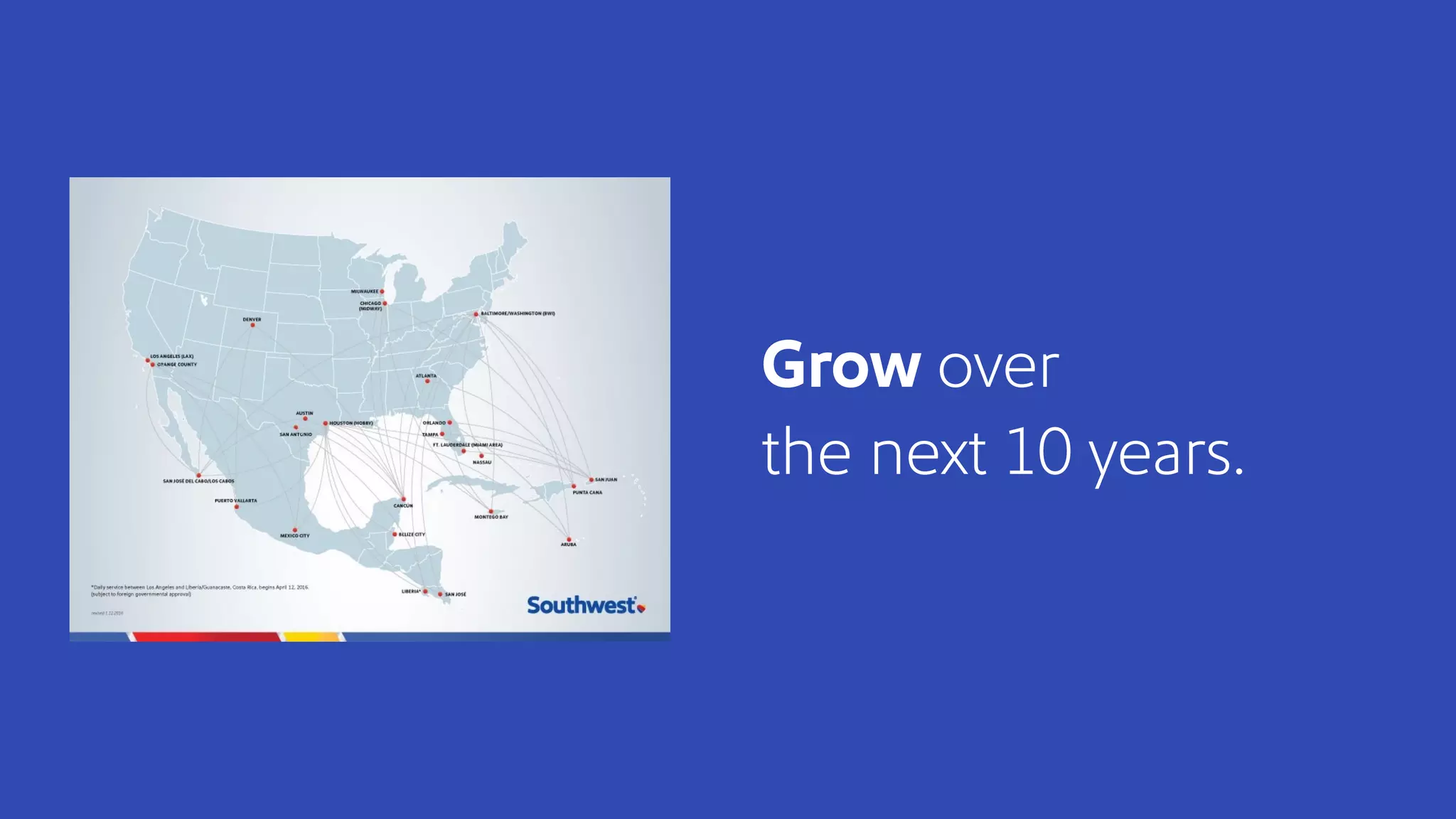




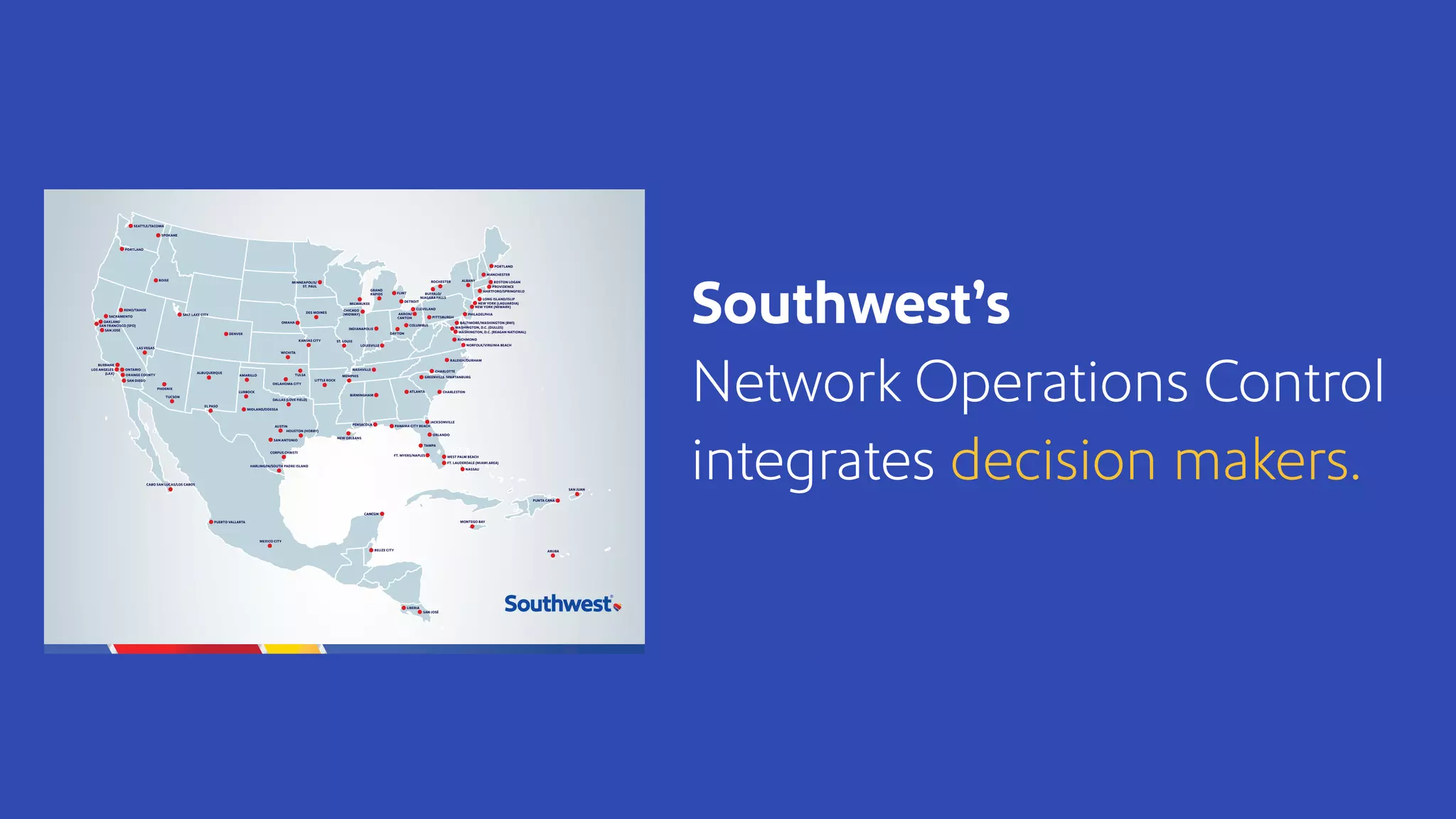




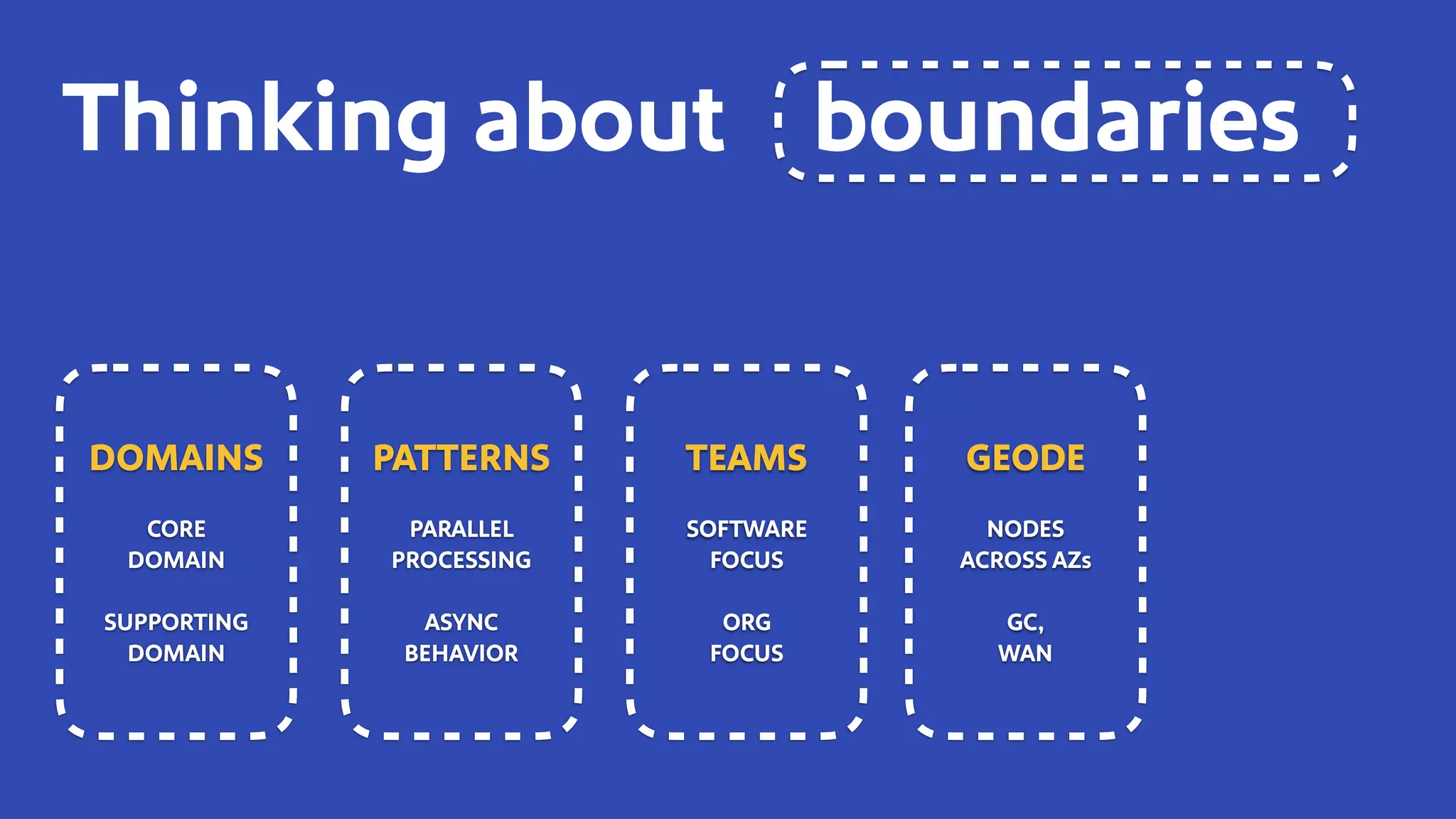
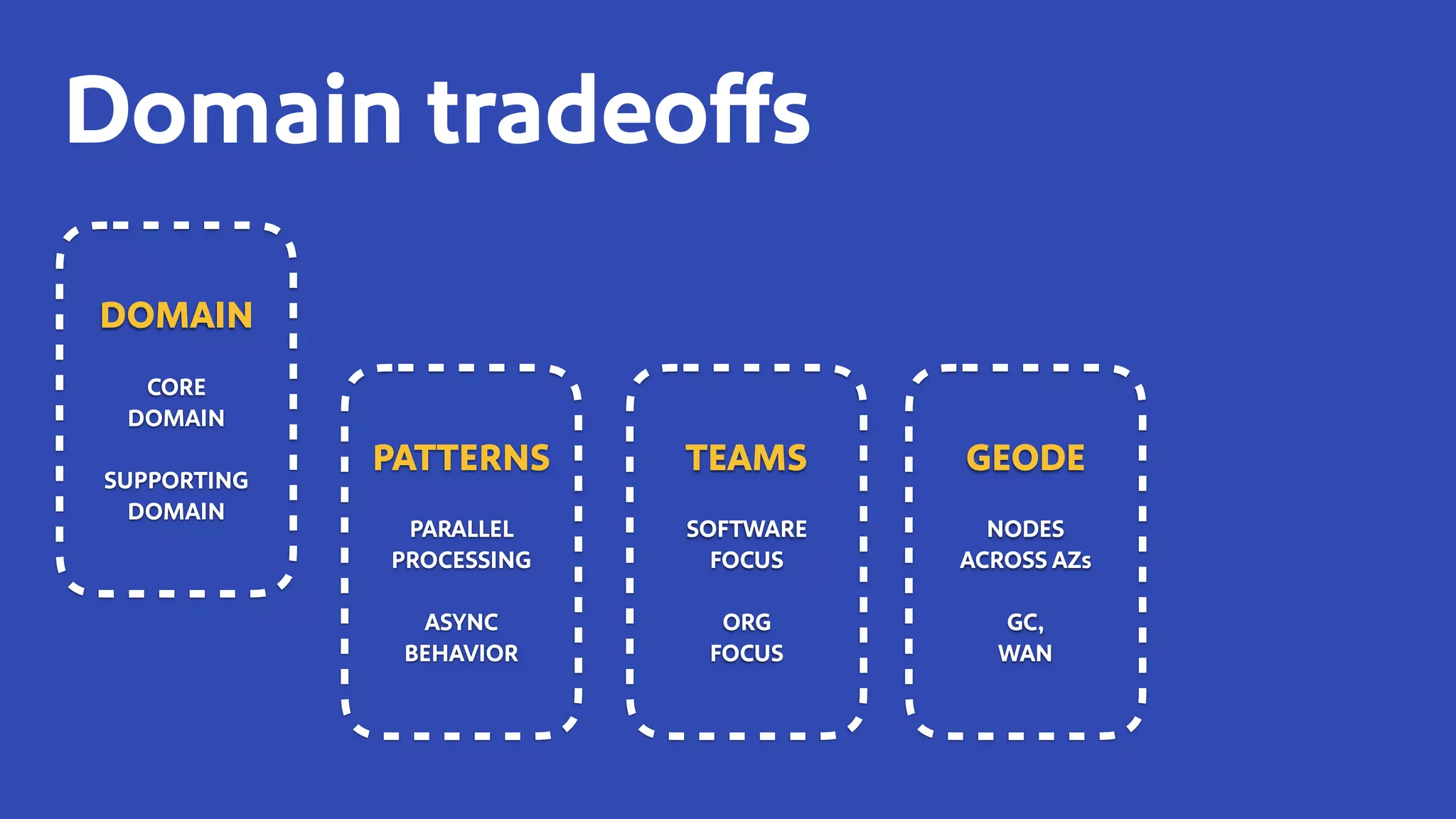




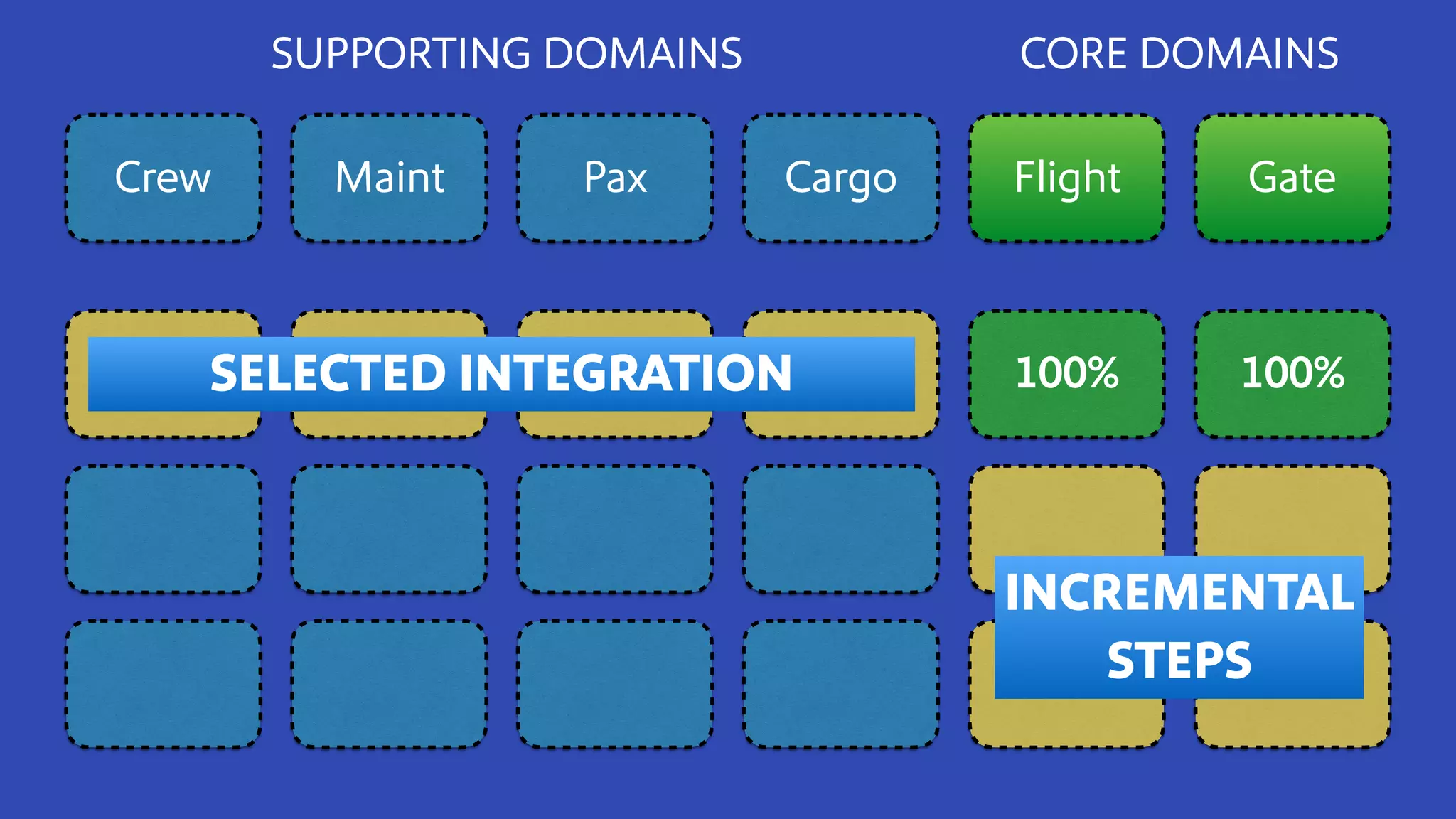




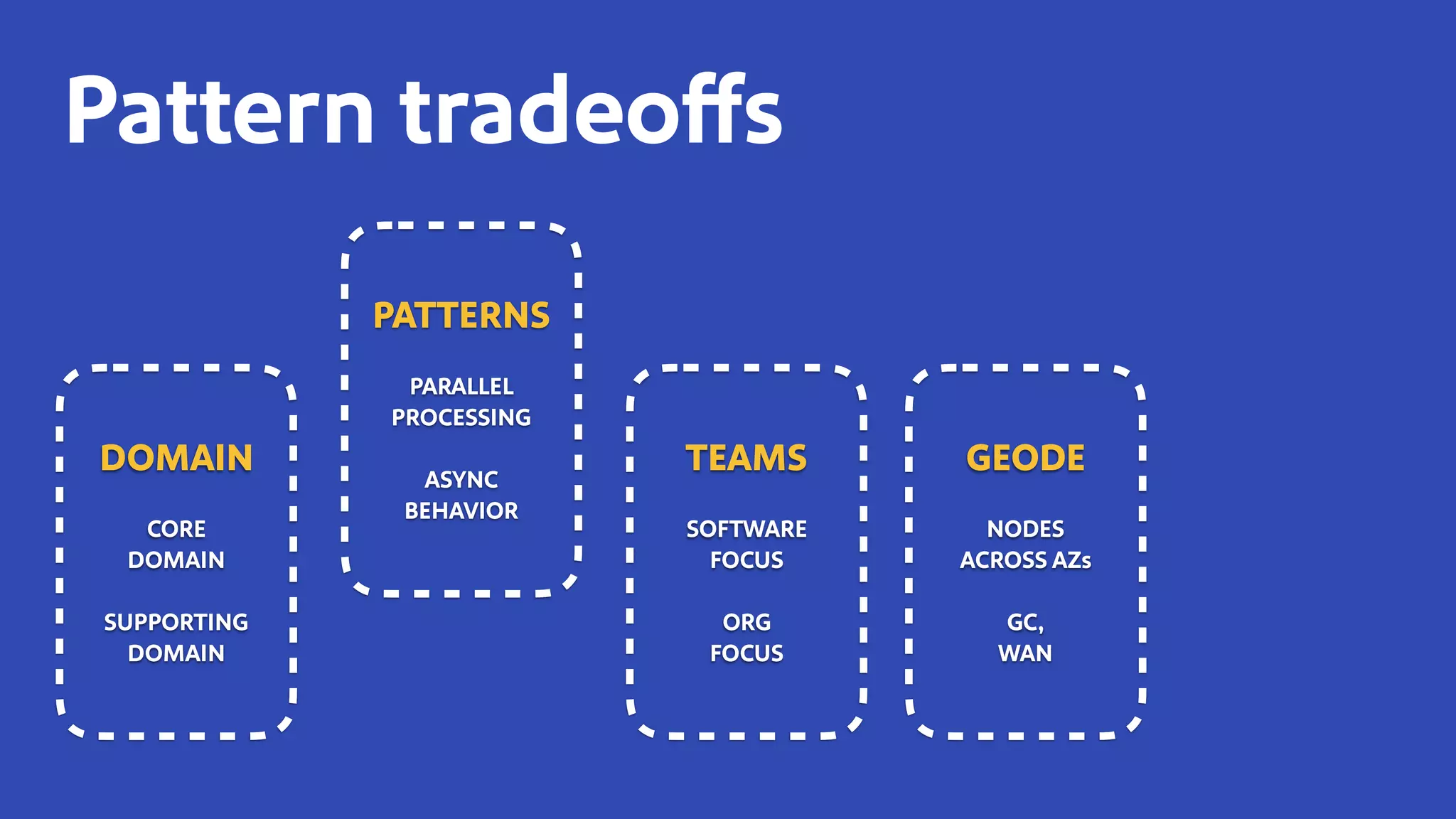


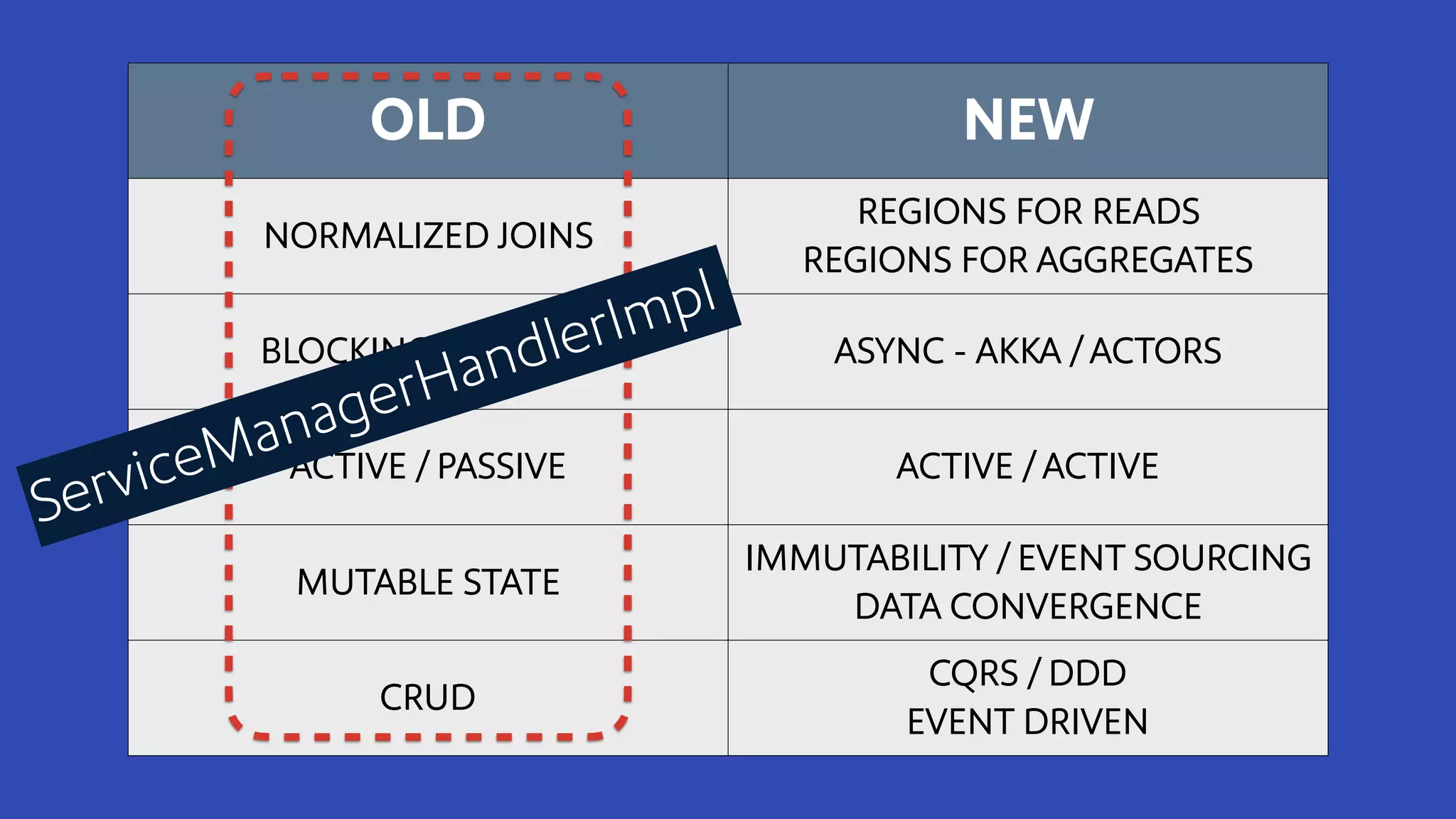

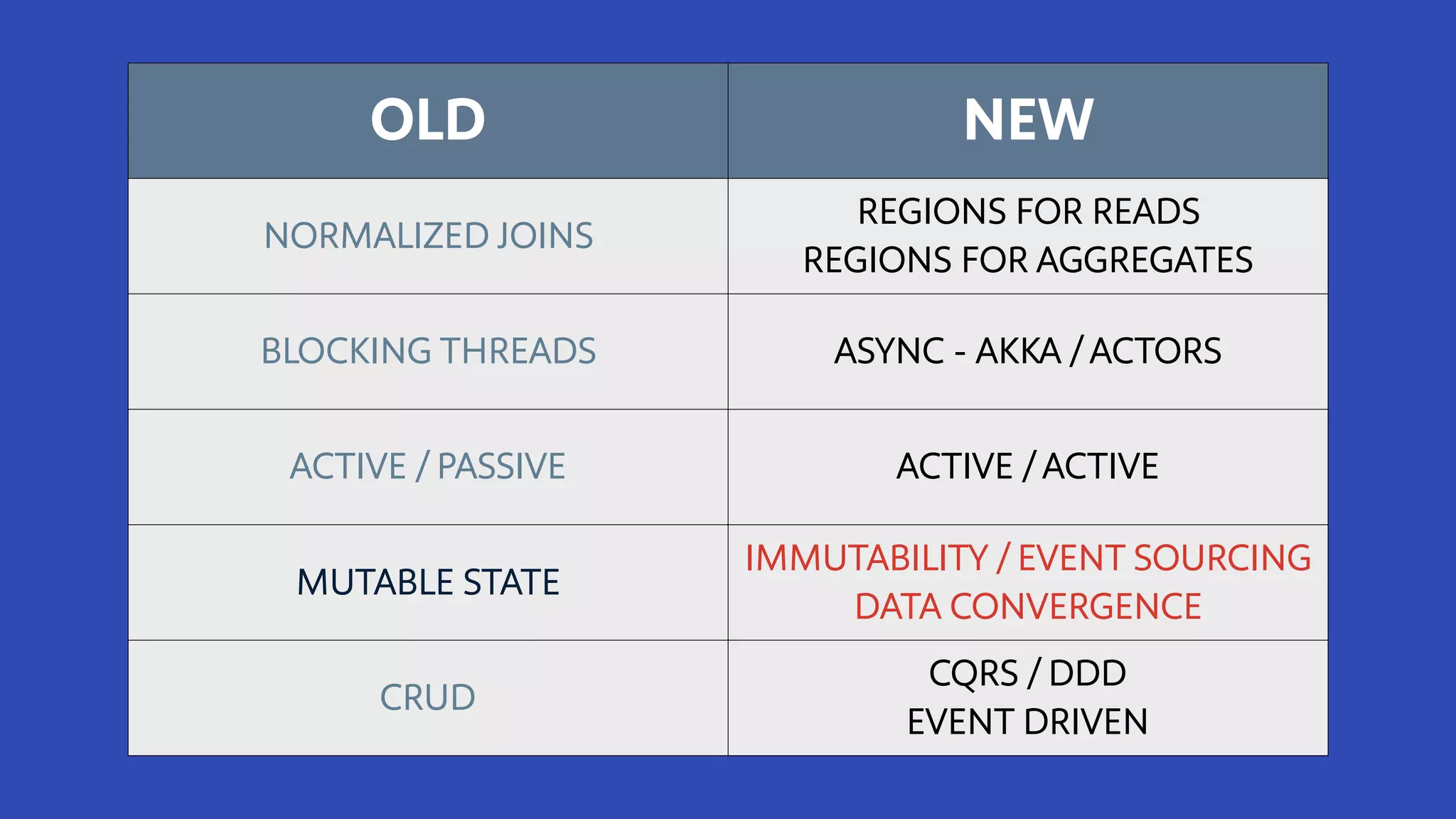





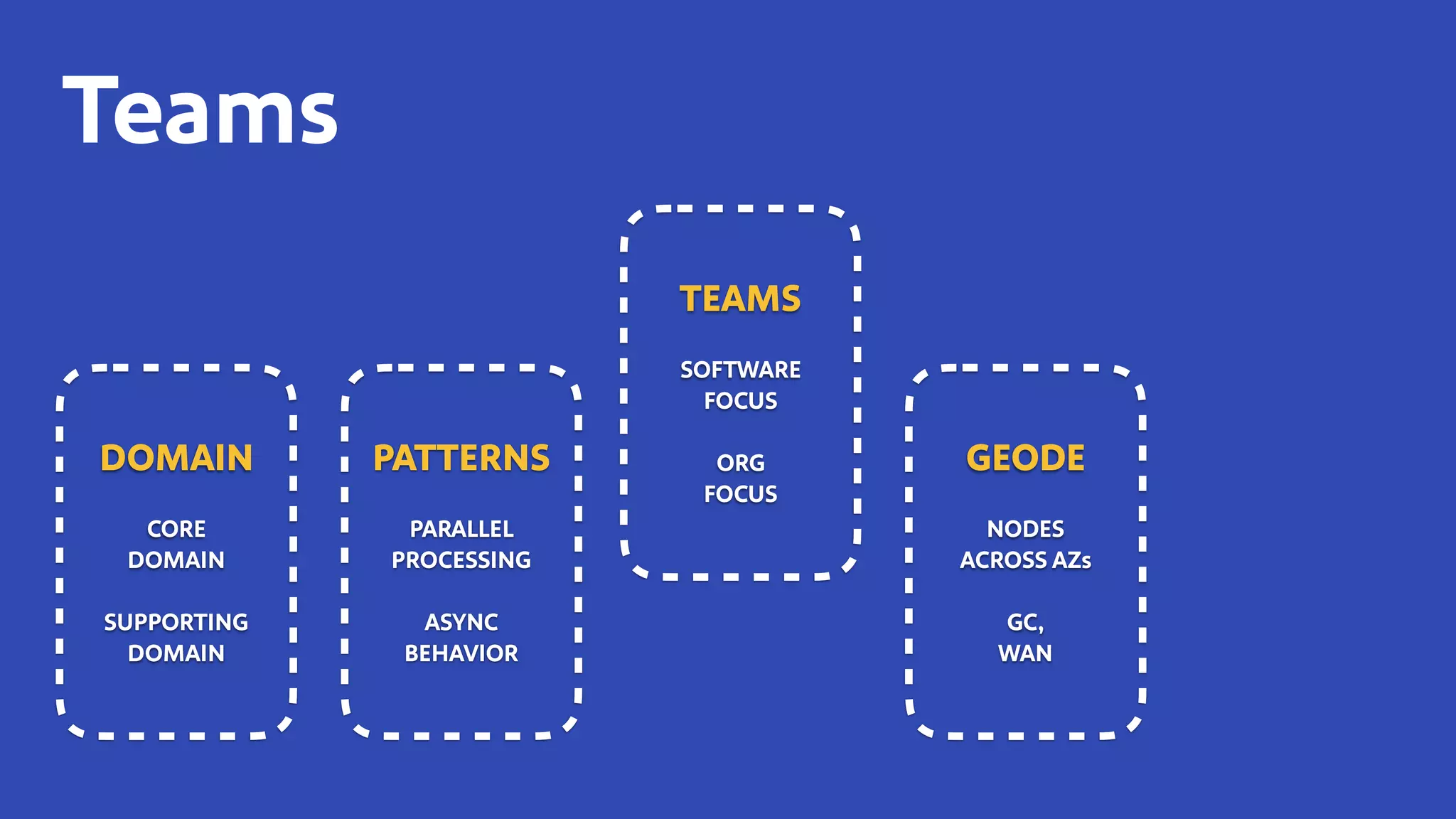






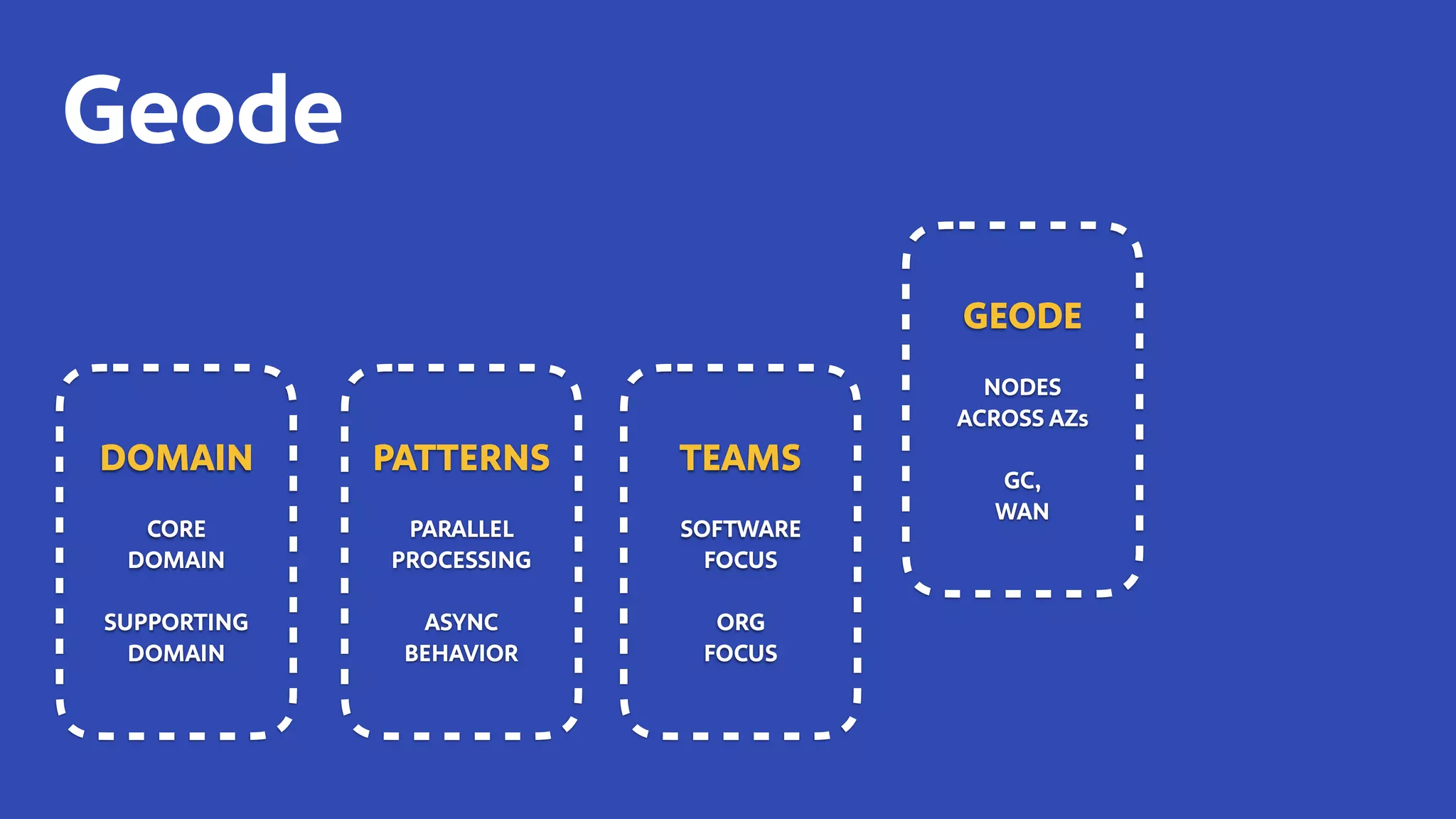





The document discusses how Southwest Airlines utilizes Apache Geode to optimize operational decisions across various data centers, handling extensive real-time data for thousands of users and critical systems. It highlights trade-offs in software and organizational domains while emphasizing the importance of scalability, recovery optimization, and effective structured communications within distributed teams. Additionally, it outlines best practices, safety tips, and important configurations for managing memory and performance in distributed systems.





























































































