Downloaded 41 times






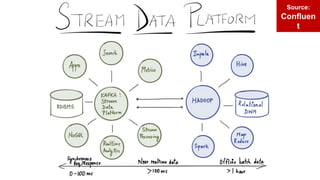




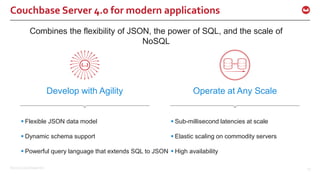
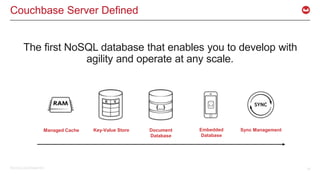
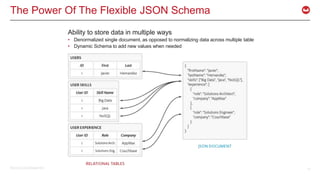
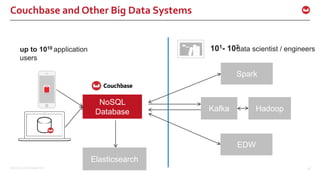

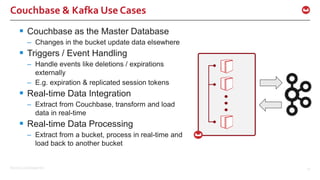



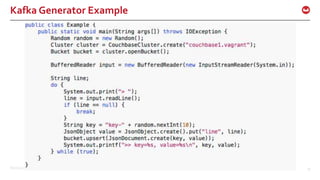









The document discusses the use of Apache Kafka in real-time message processing at scale, highlighting its architecture and integration with Couchbase. It covers various use cases for Kafka within Couchbase, including real-time data integration and event handling. The document also provides examples of Kafka producers and consumers, as well as information on the Couchbase Kafka connector and its roadmap.



































































