Downloaded 17 times


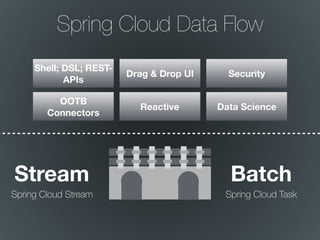
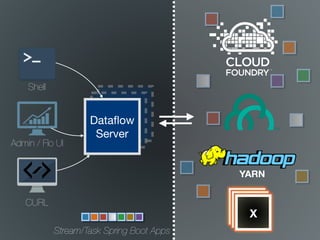





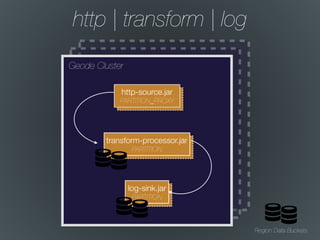


The document discusses the integration of Spring Cloud Data Flow with Apache Geode for managing stream and batch data processes. It emphasizes the need for low latency, high throughput, and efficient data handling in data pipelines. Key features mentioned include a drag-and-drop UI, security, and various configurations for processing data in real-time.
































































































