






























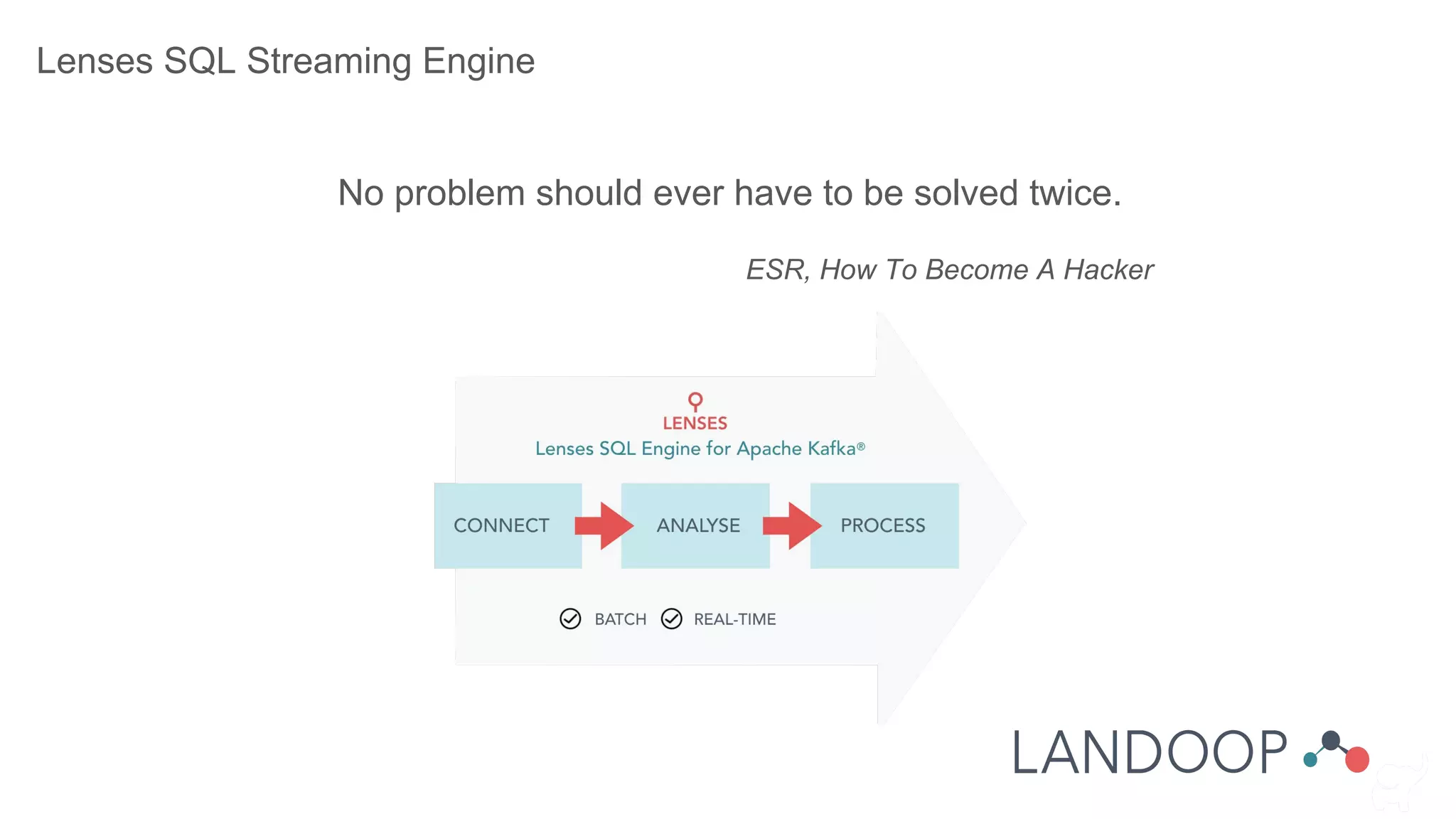







![Authorization
Implemented via ACLs in the form of:
Principal P is [Allowed/Denied] Operation O From Host H On Resource R
● Resources are: topic, consumer group, cluster
● Operations depend on resource: read, write, describe, create, cluster_action
● Principal and host must be an exact match or a wildcard (*)!
Important to know:
● The authorizer is pluggable. The default stores ACLs in zookeeper.
● A principal builder class may be desired.
● Brokers’ principals should be set as super.users.
● Mixed setups are hard to maintain.](https://image.slidesharecdn.com/14thathensbigdatameetup-landoopworkshop-181127115349/75/14th-Athens-Big-Data-Meetup-Landoop-Workshop-Apache-Kafka-Entering-The-Streaming-World-Via-Lenses-62-2048.jpg)


![Upgrades
Rolling upgrades are the norm.
Between upgrades, only the message format version
and inter broker protocol need care.
baseOffset: int64
batchLength: int32
partitionLeaderEpoch: int32
magic: int8 (current magic value is 2)
crc: int32
attributes: int16
bit 0~2:
0: no compression
1: gzip
2: snappy
3: lz4
bit 3: timestampType
bit 4: isTransactional (0 means not
transactional)
bit 5: isControlBatch (0 means not a control
batch)
bit 6~15: unused
lastOffsetDelta: int32
firstTimestamp: int64
maxTimestamp: int64
producerId: int64
producerEpoch: int16
baseSequence: int32
records: [Record]](https://image.slidesharecdn.com/14thathensbigdatameetup-landoopworkshop-181127115349/75/14th-Athens-Big-Data-Meetup-Landoop-Workshop-Apache-Kafka-Entering-The-Streaming-World-Via-Lenses-67-2048.jpg)





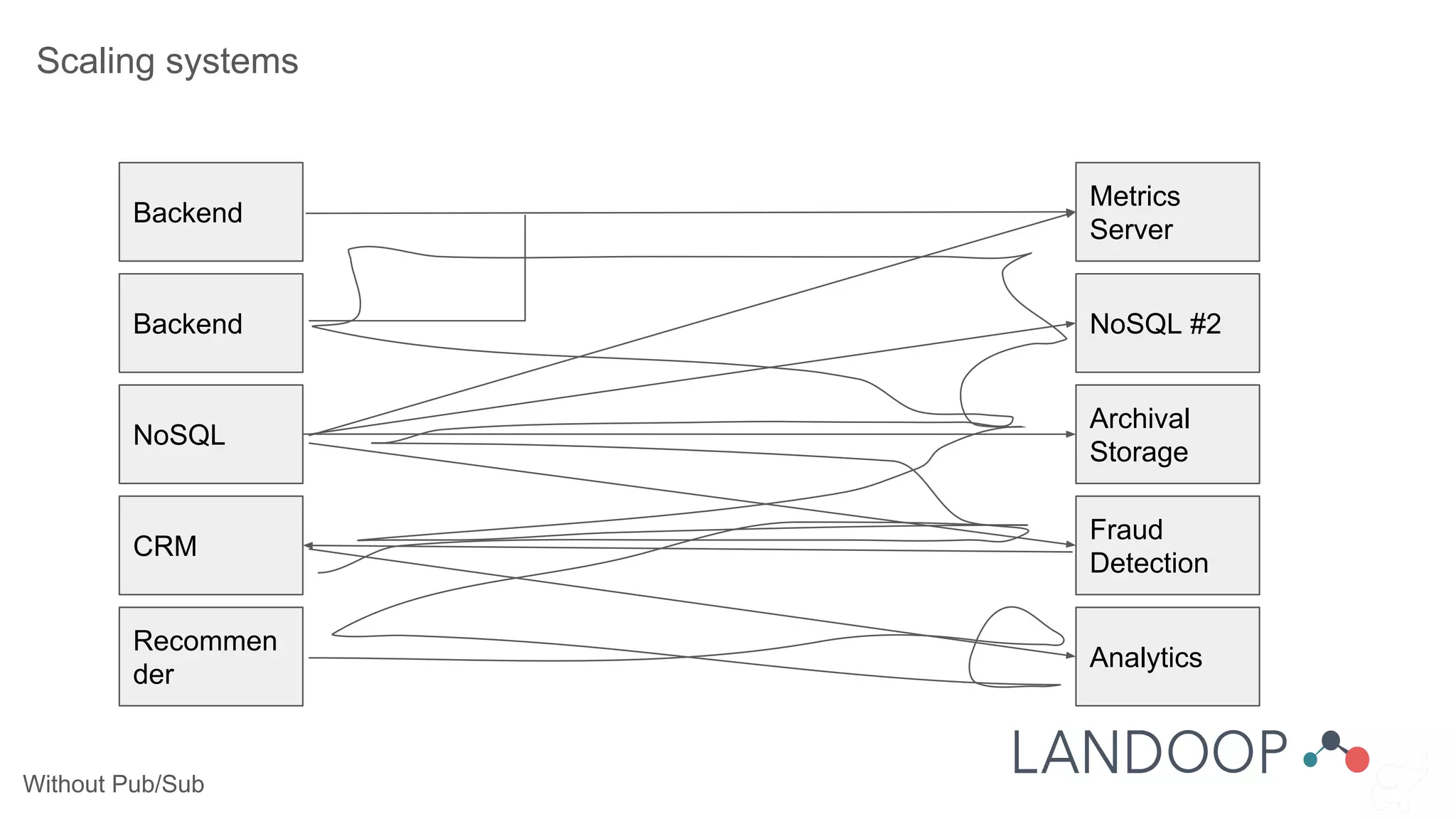
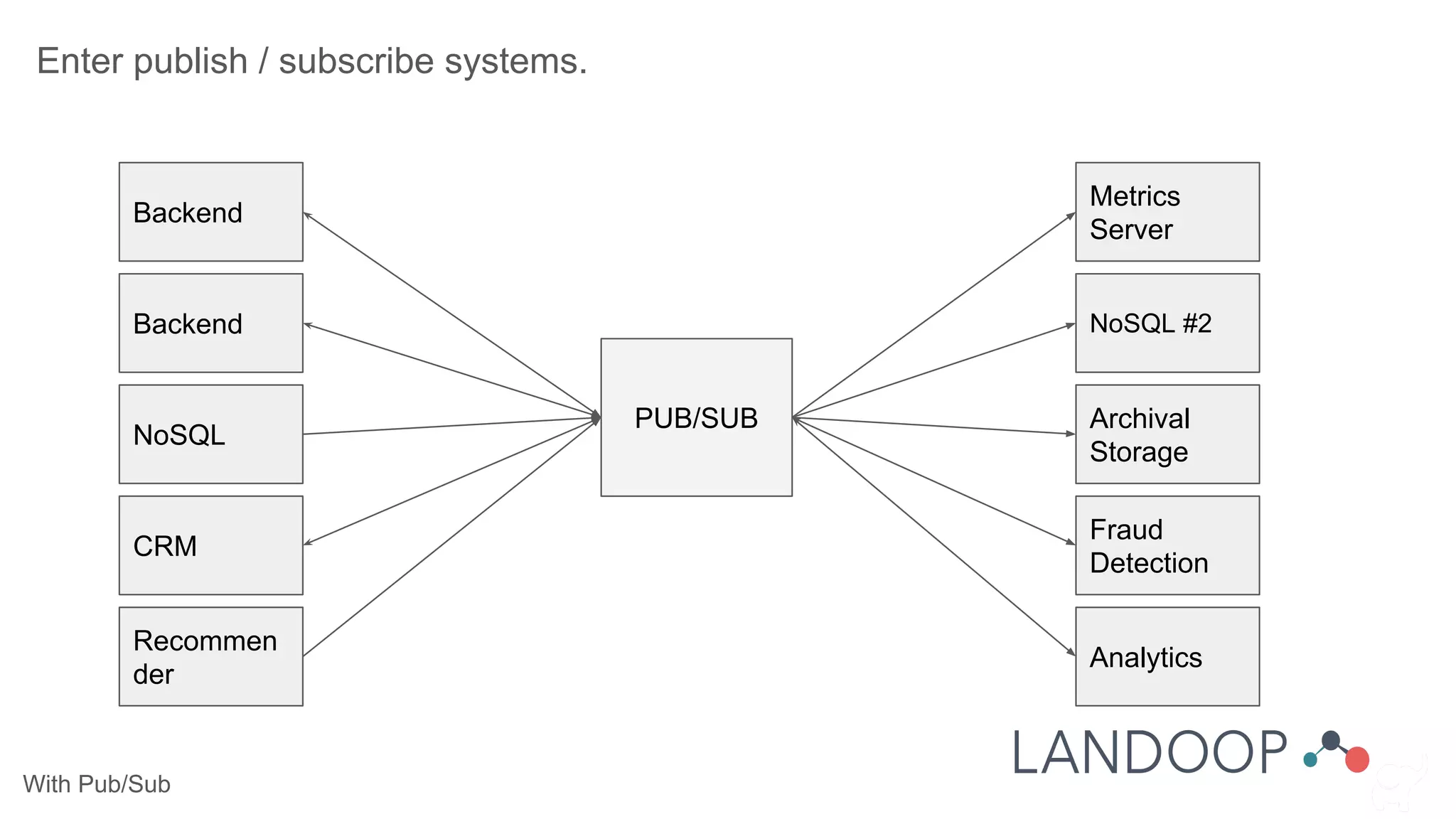
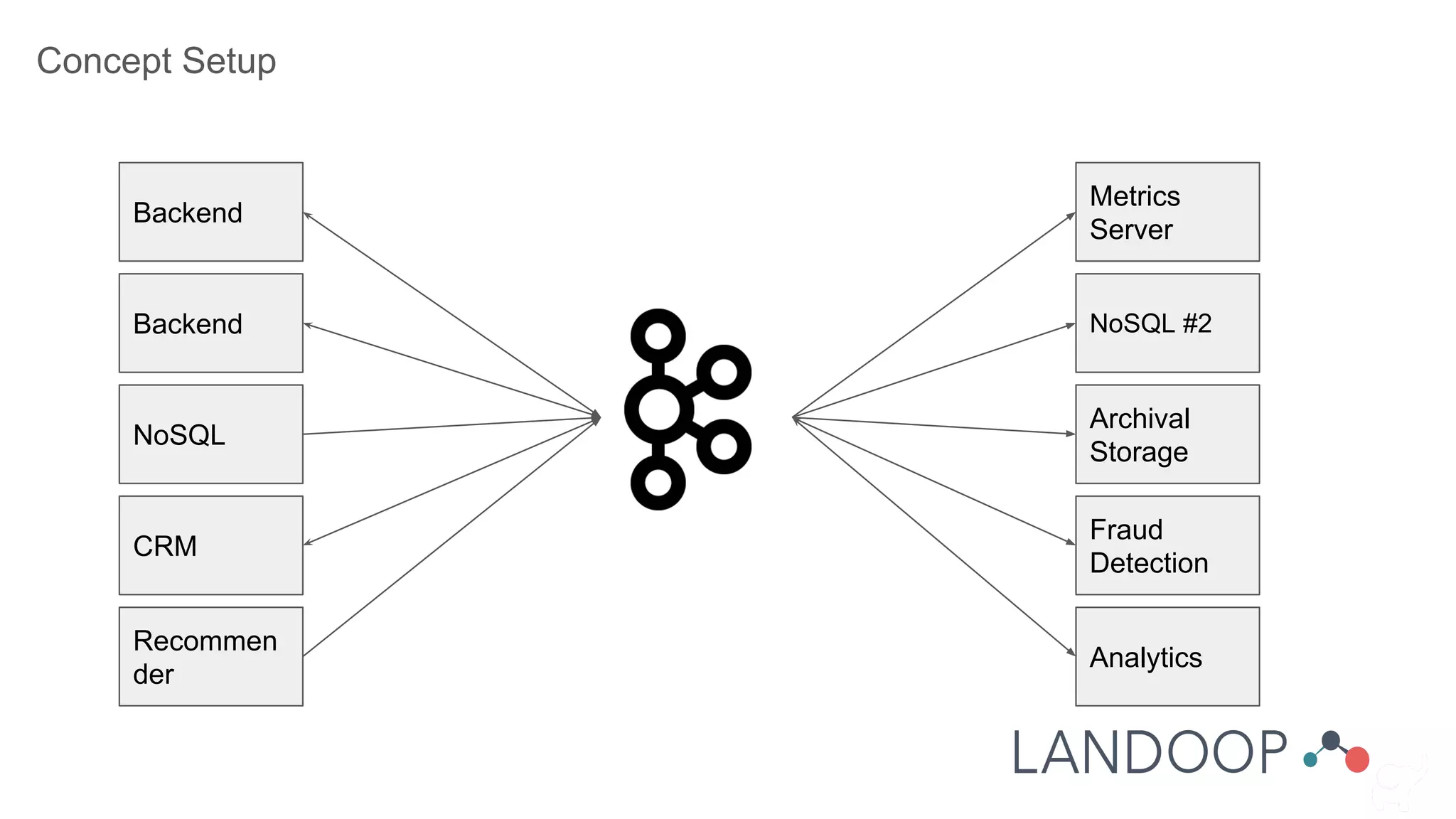
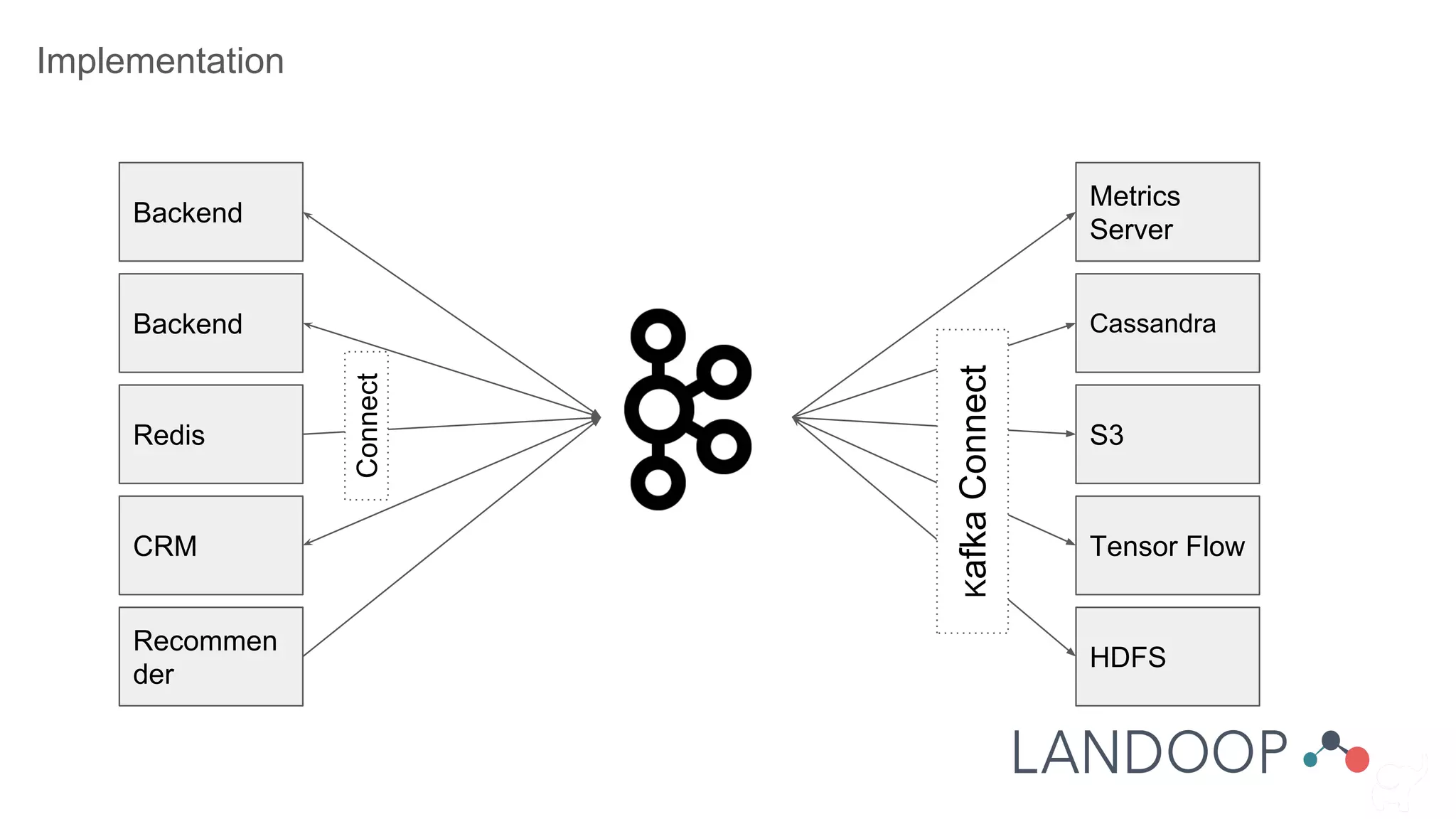
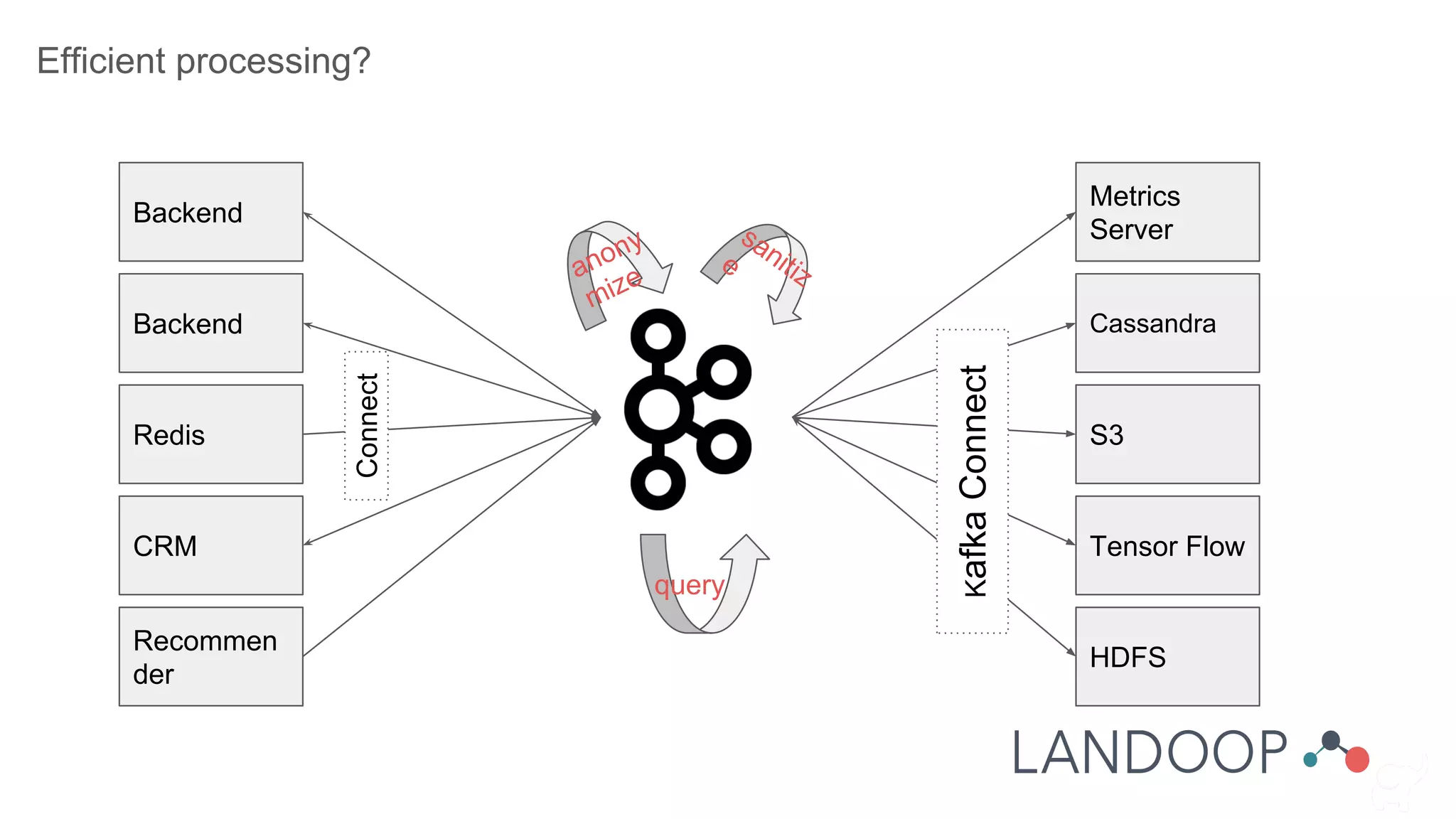
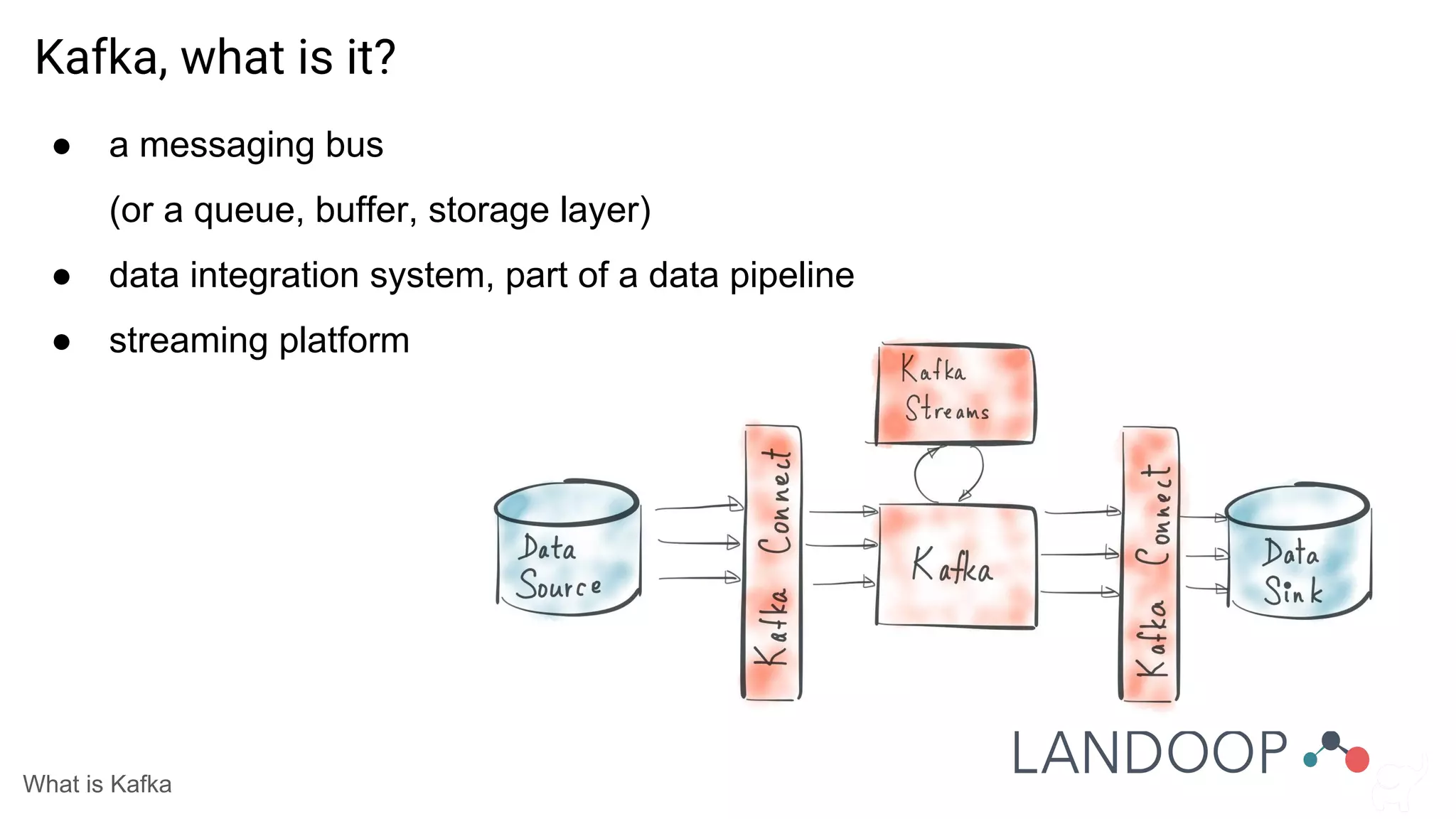
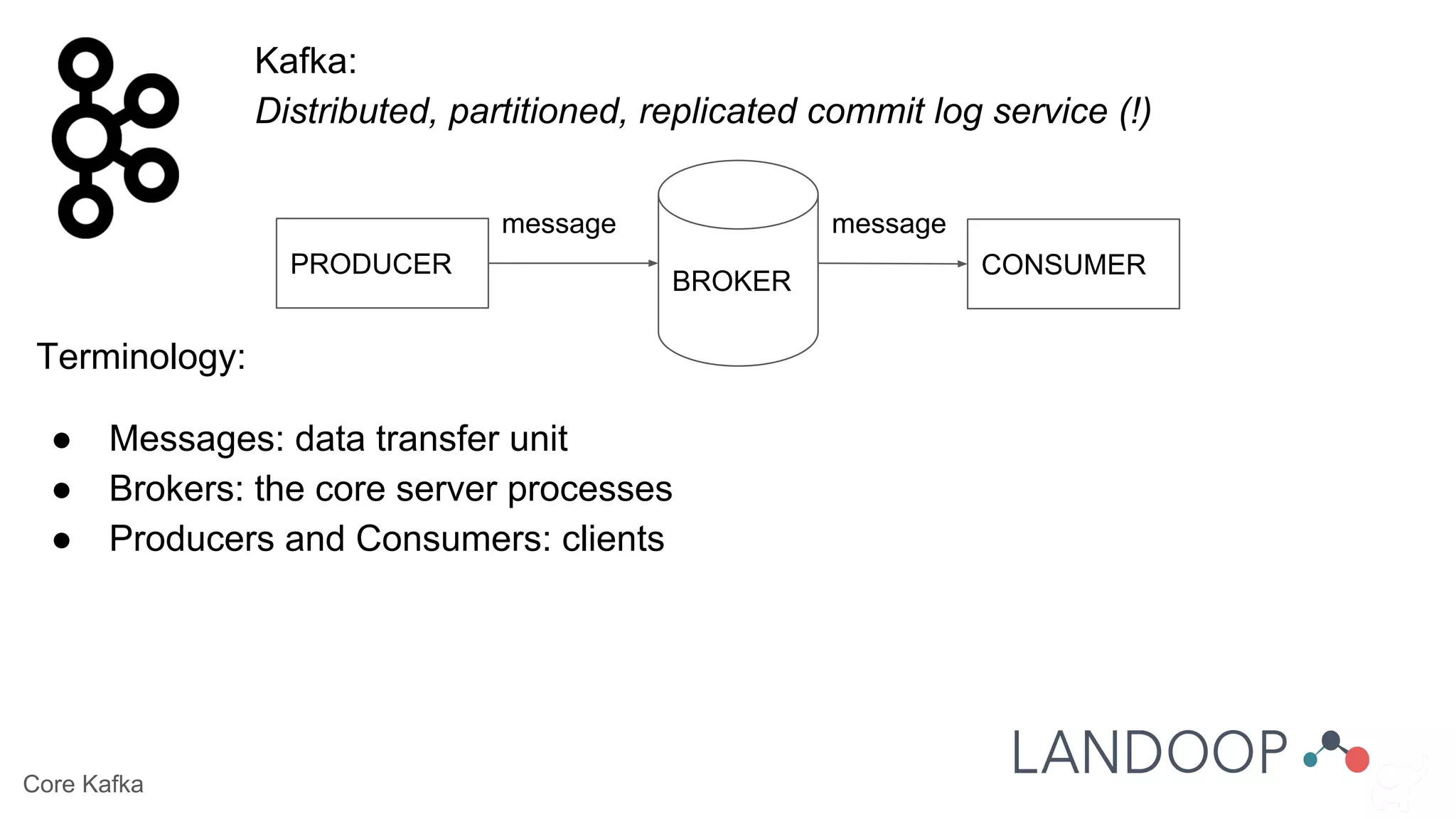
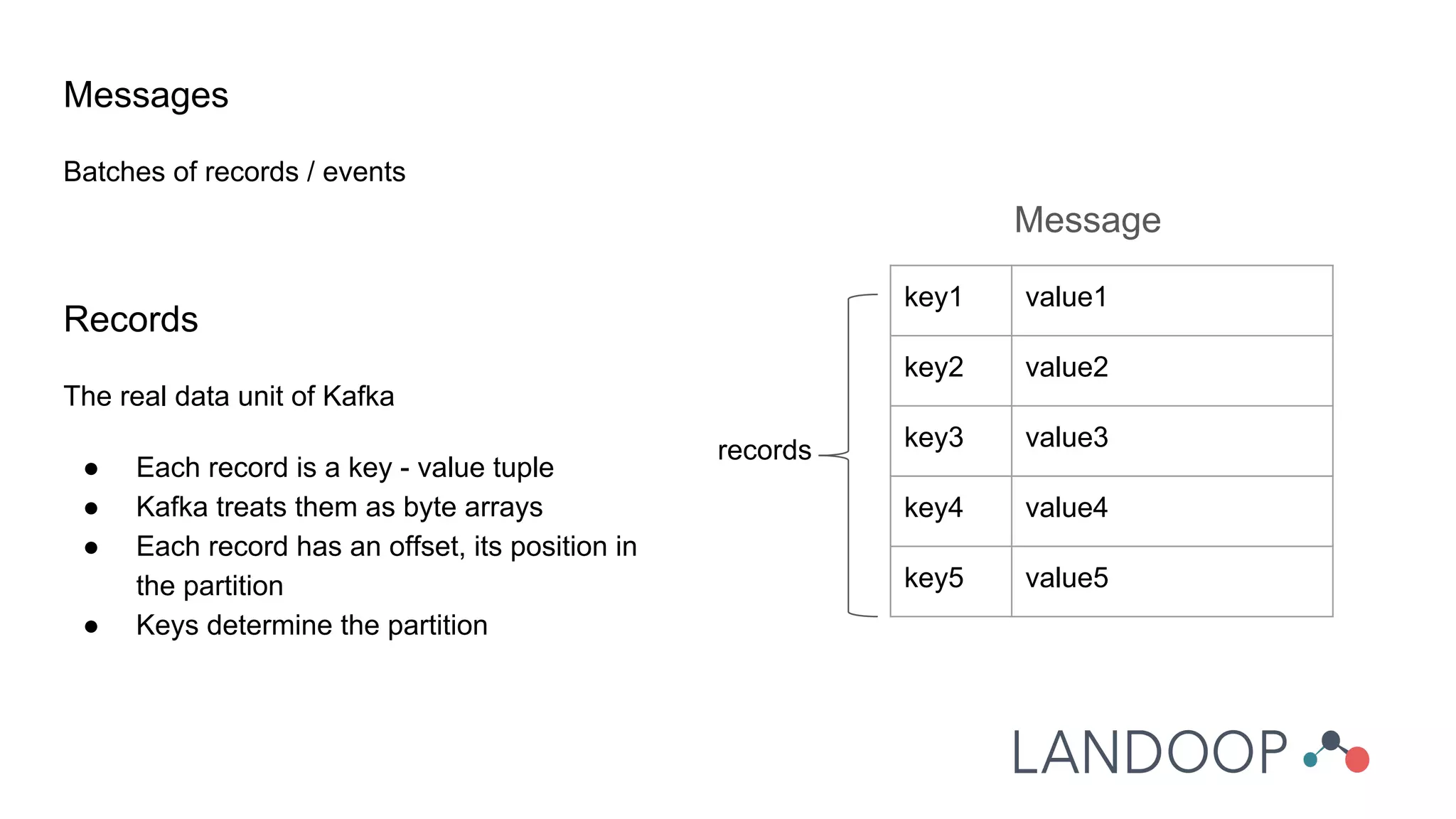
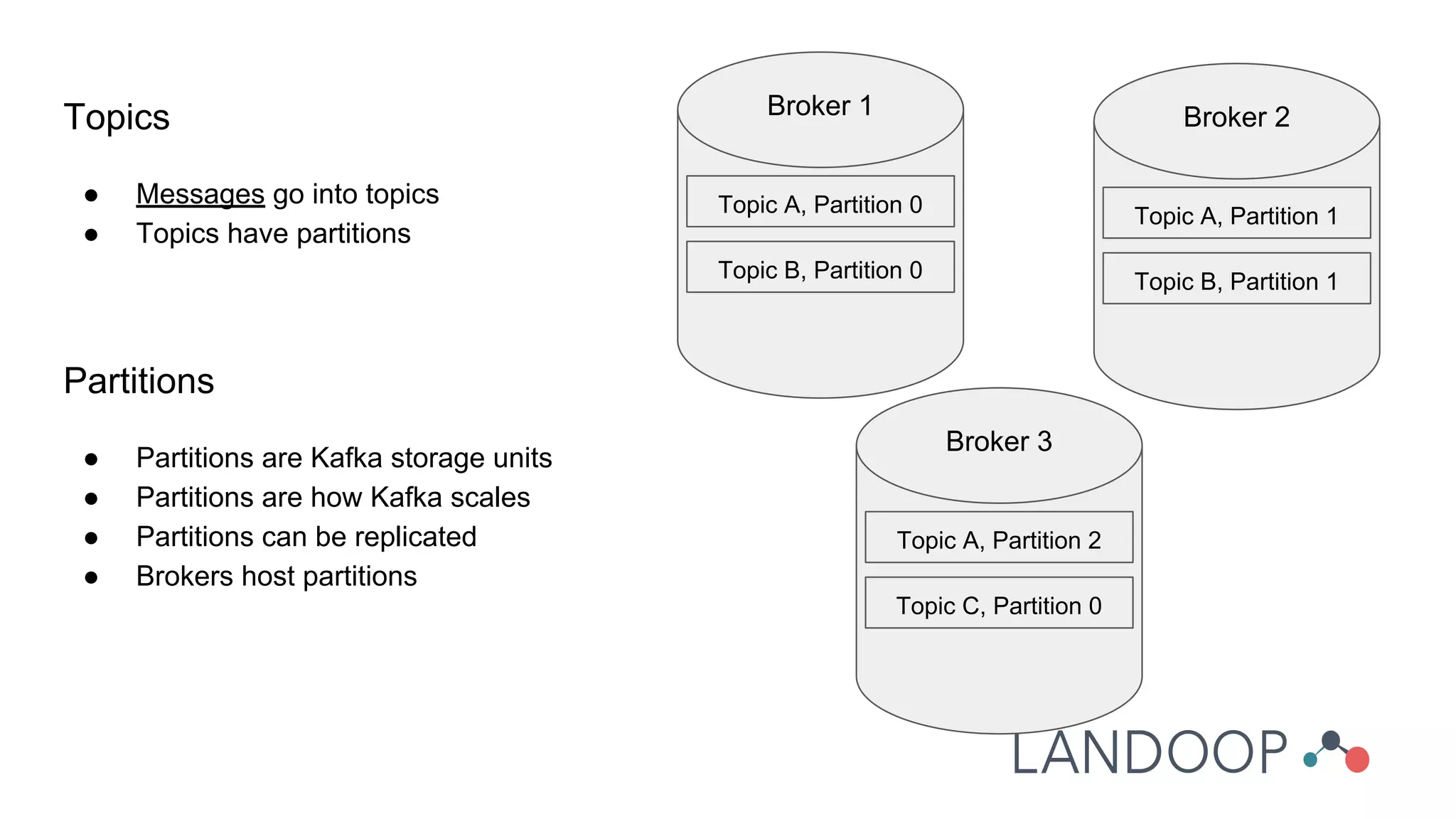
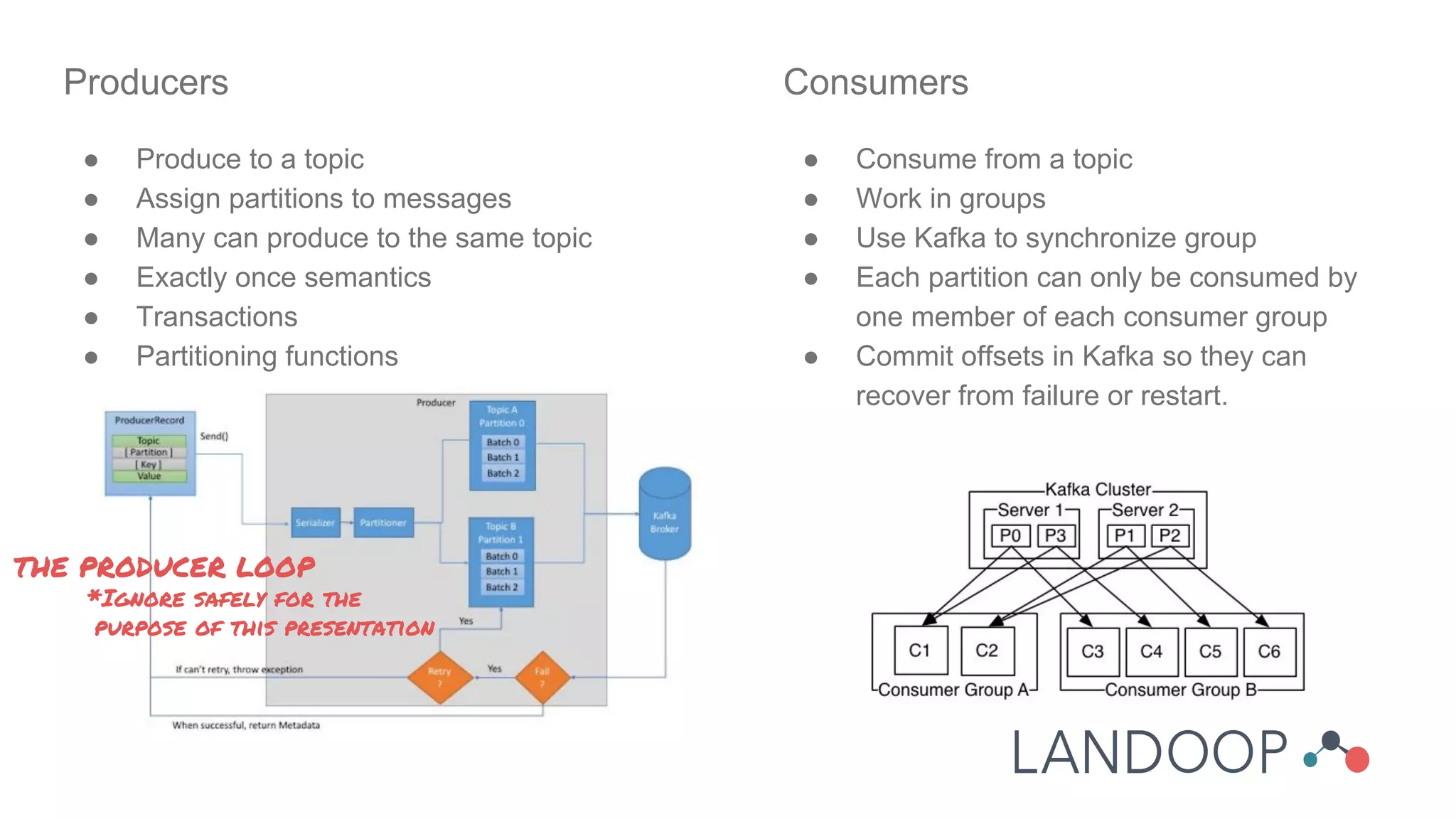
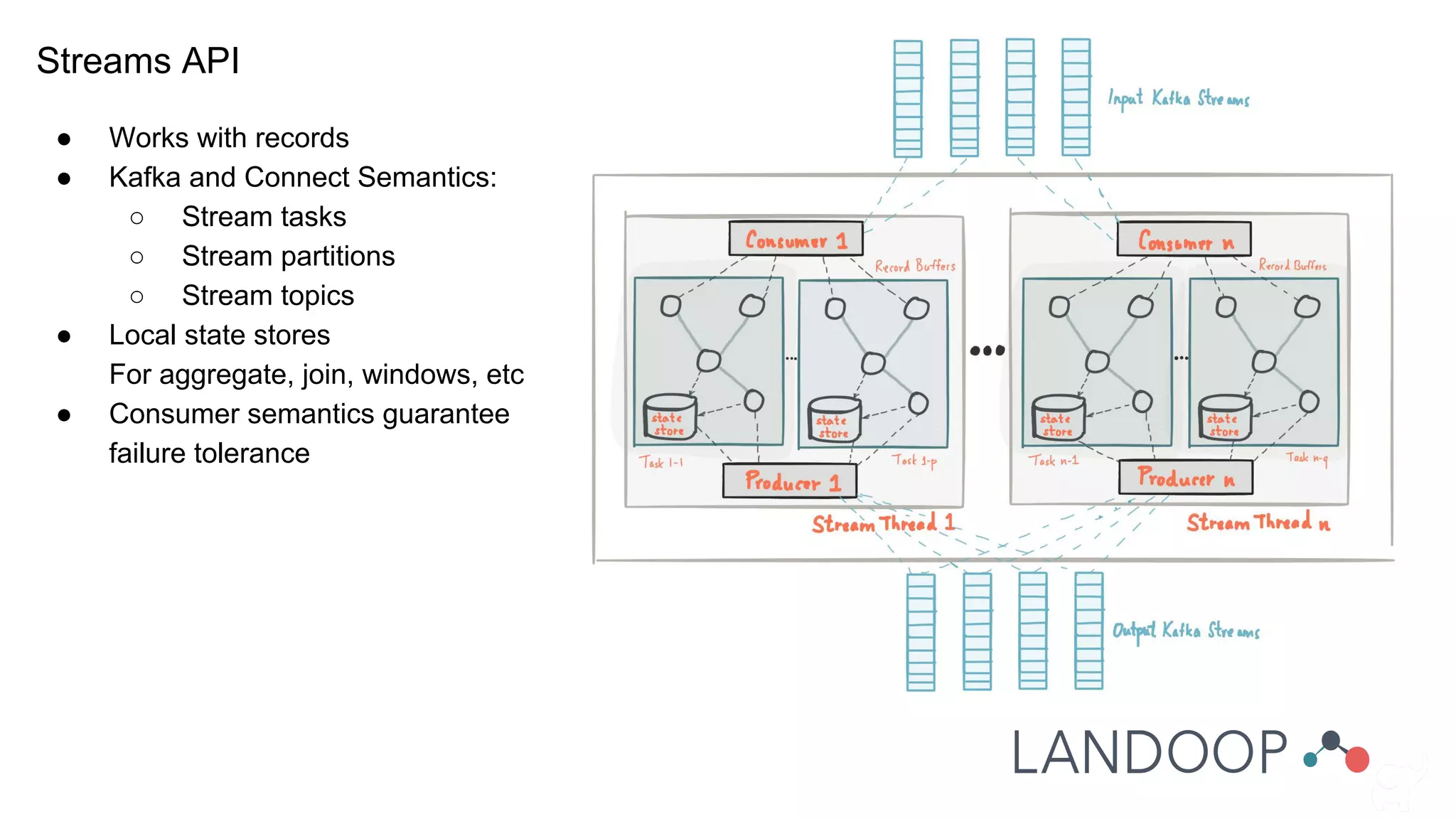
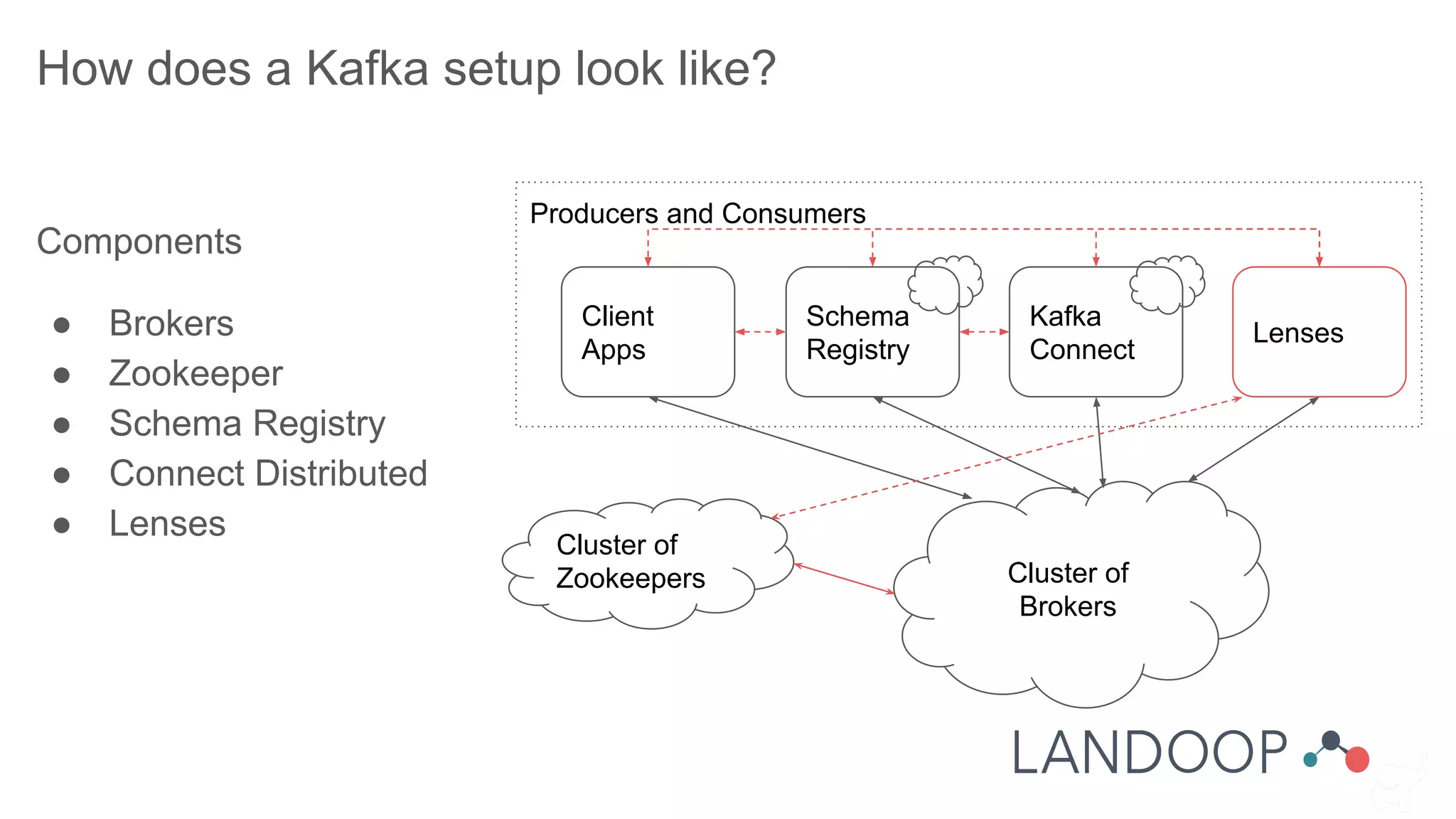
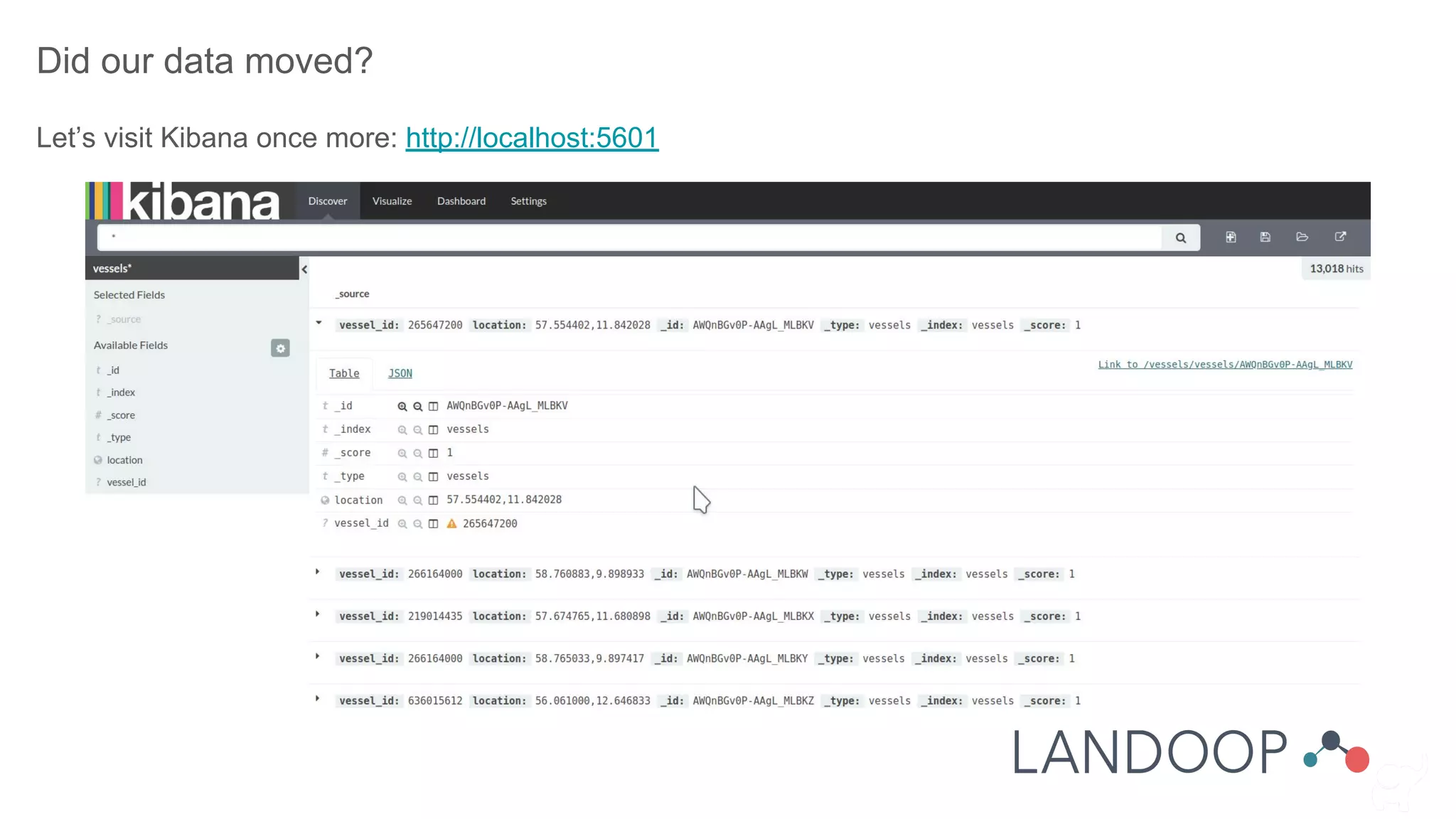
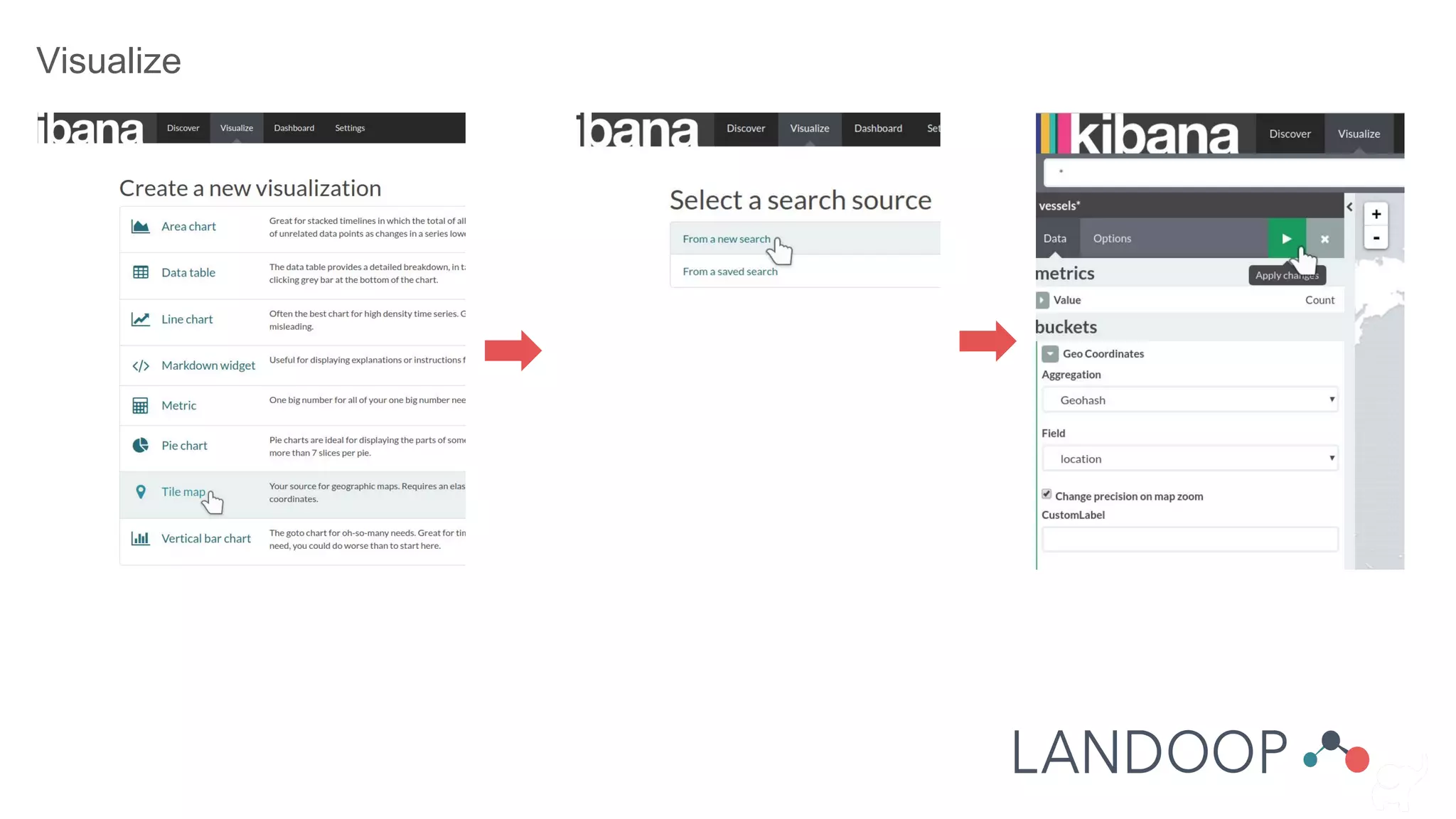
The document provides a comprehensive overview of Kafka, a distributed pub-sub system used for real-time data pipelines and streaming applications. It details Kafka's architecture, components, and functionalities such as message production/consumption, data connectors, and integration strategies with other systems like Elasticsearch. Additionally, it offers practical setup instructions, examples, and best practices for implementation and administration within a complex infrastructure.





































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)
















