Downloaded 14 times

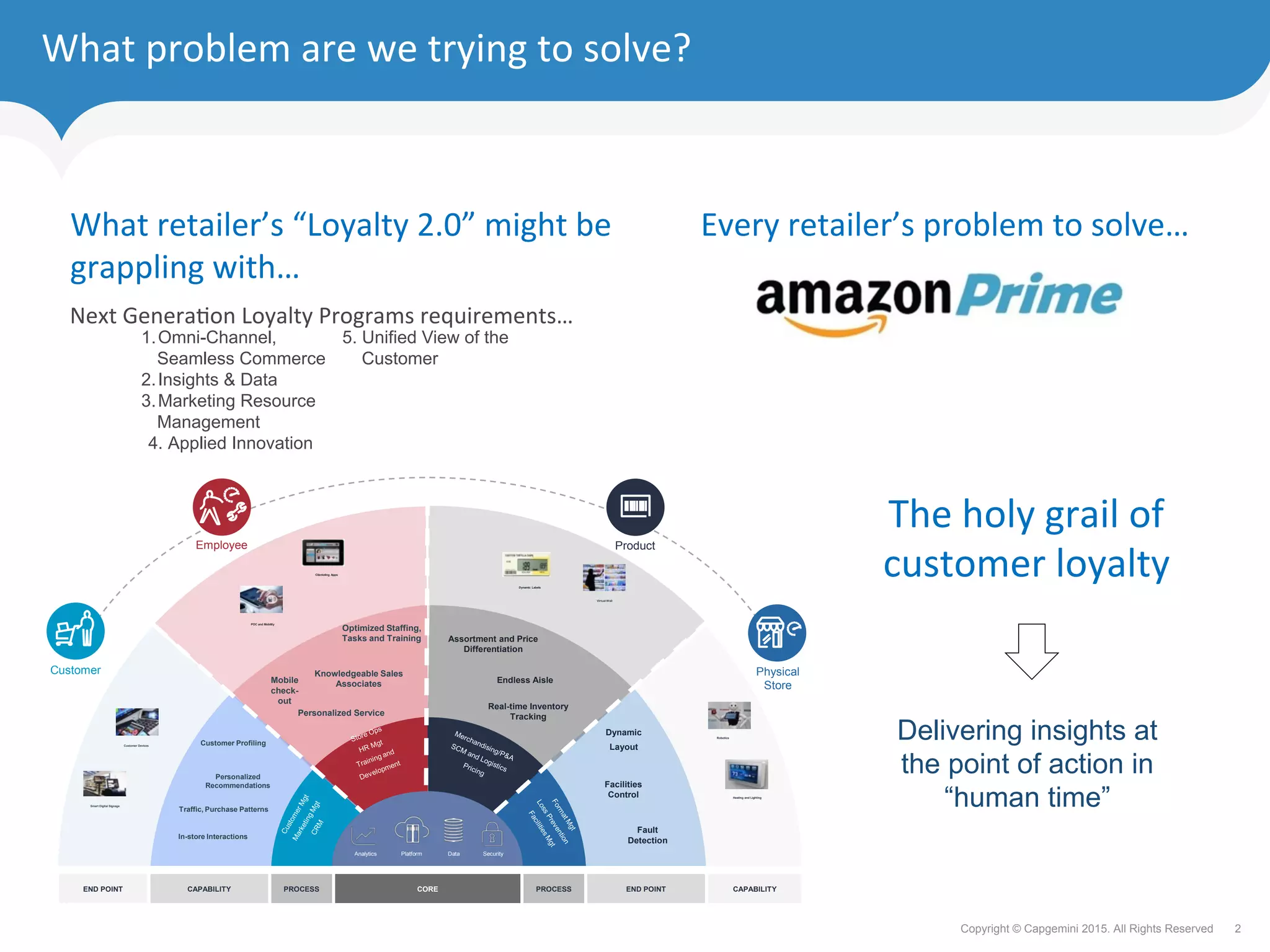

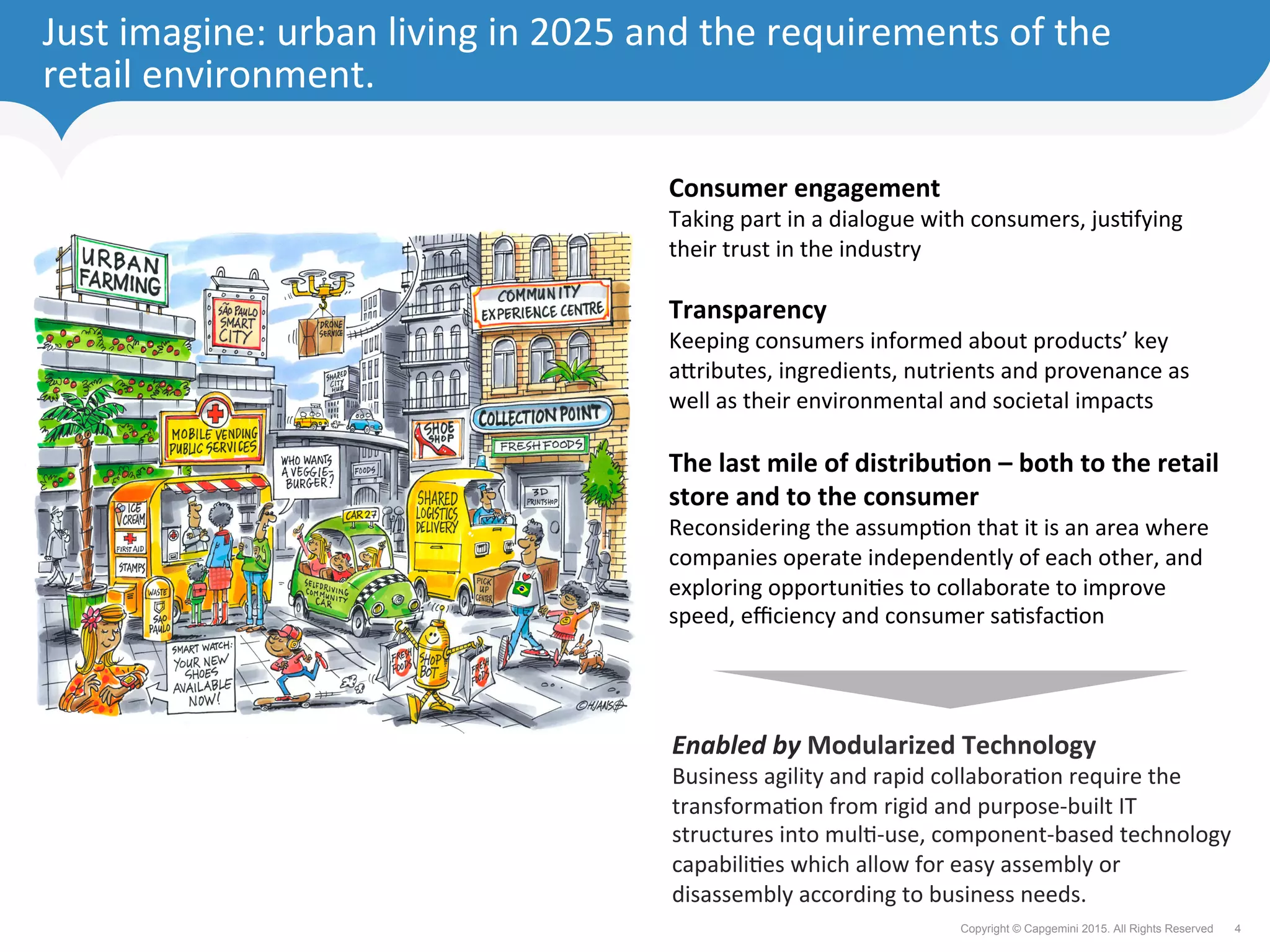

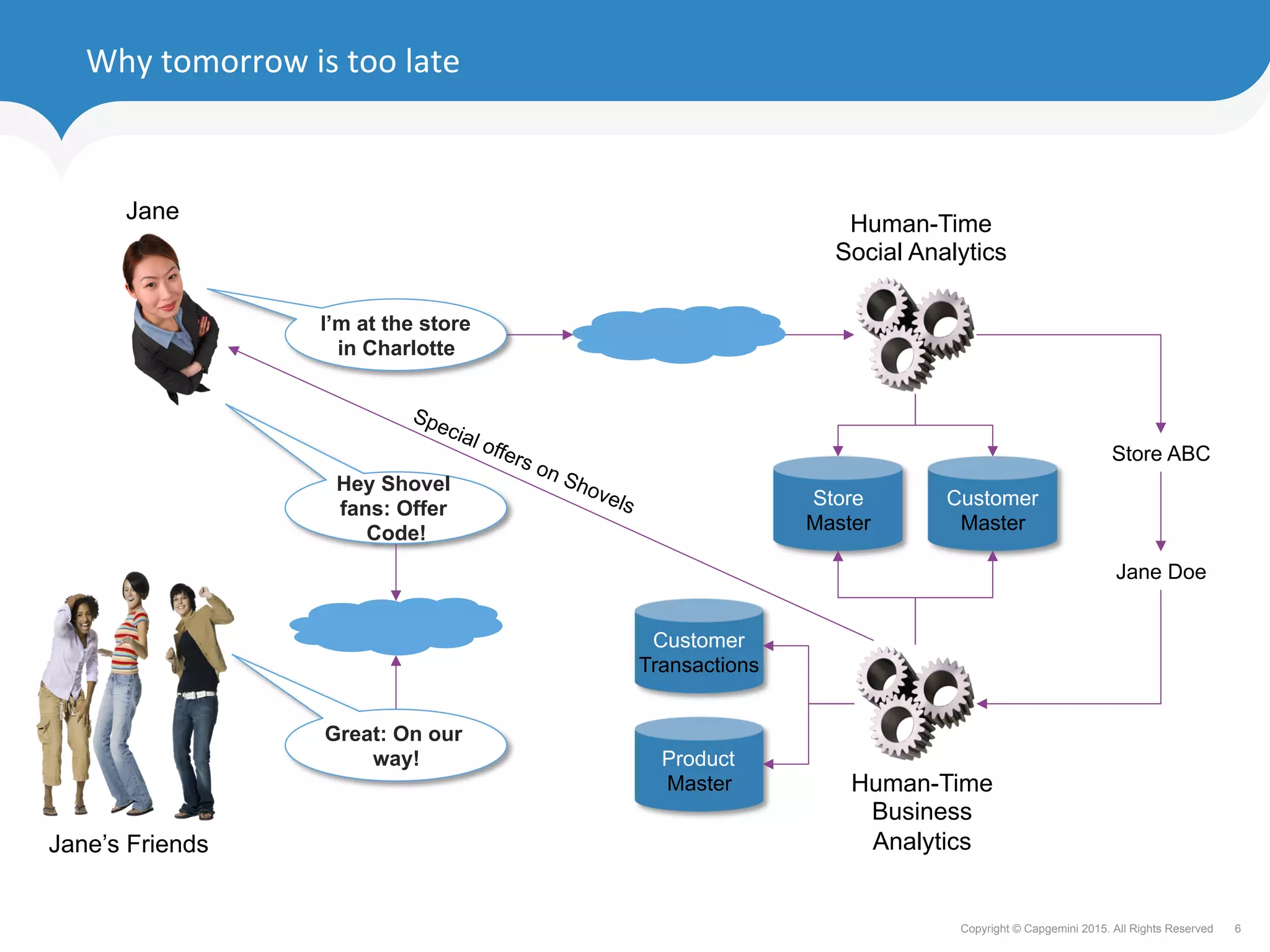
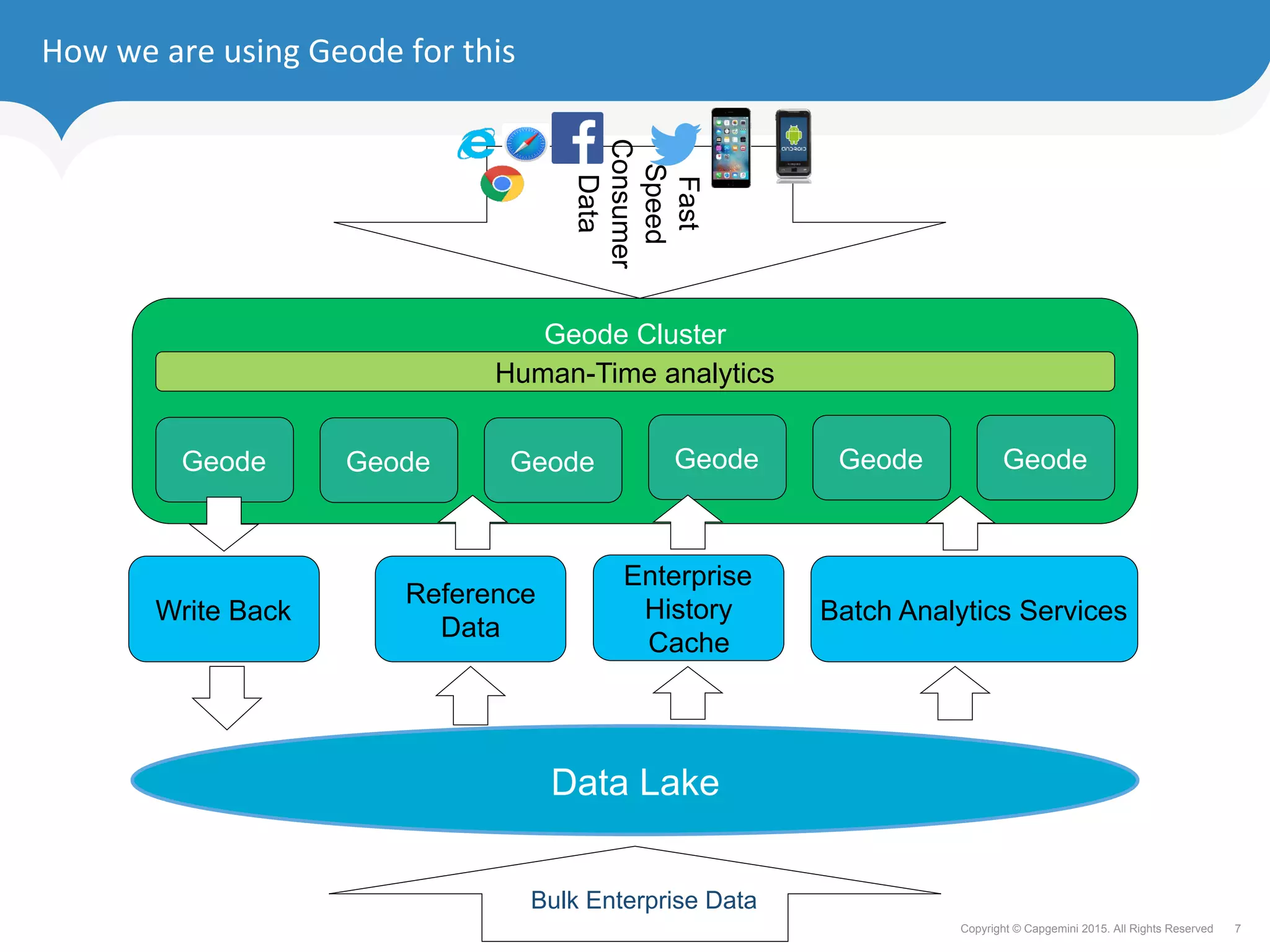


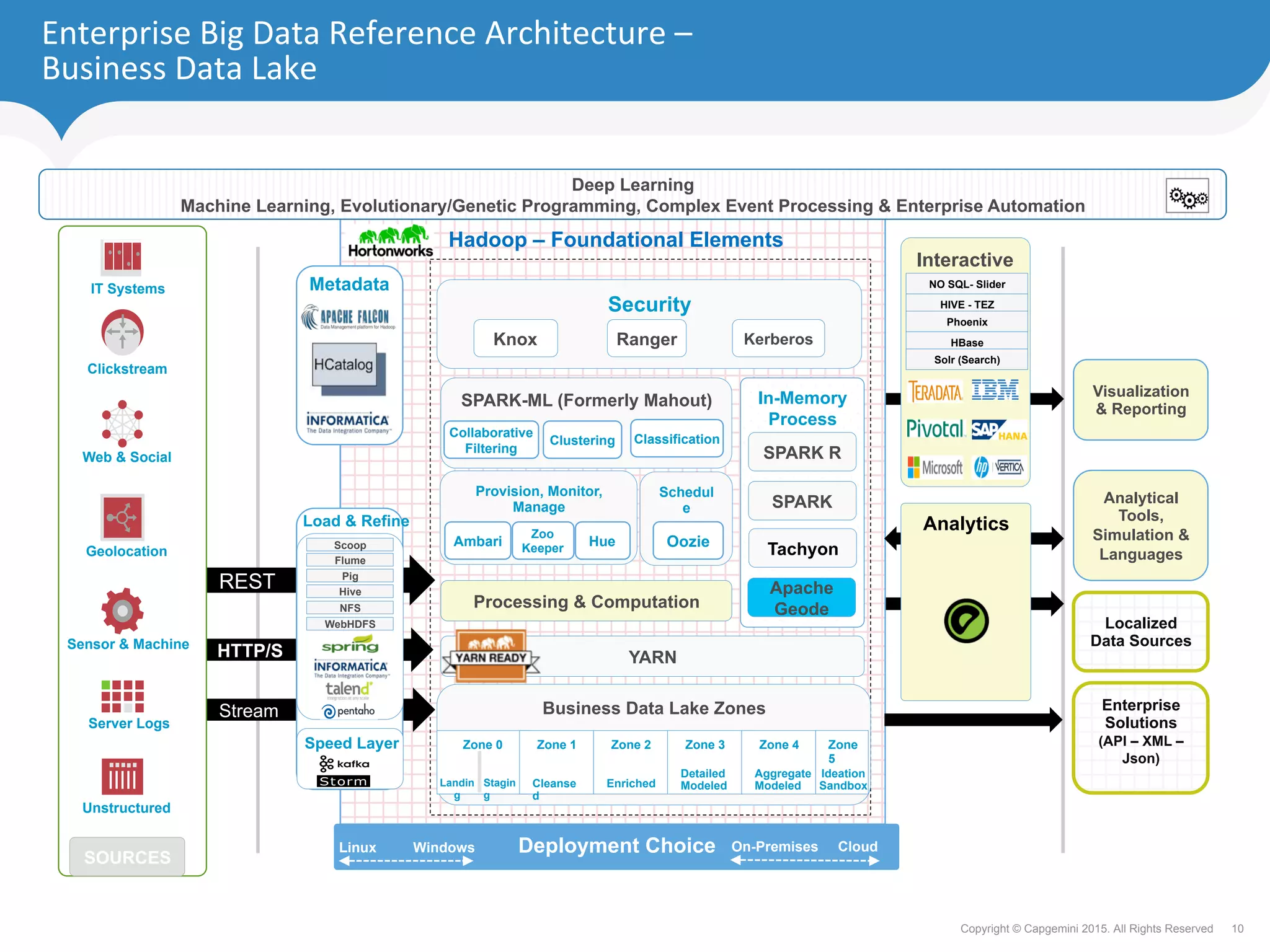


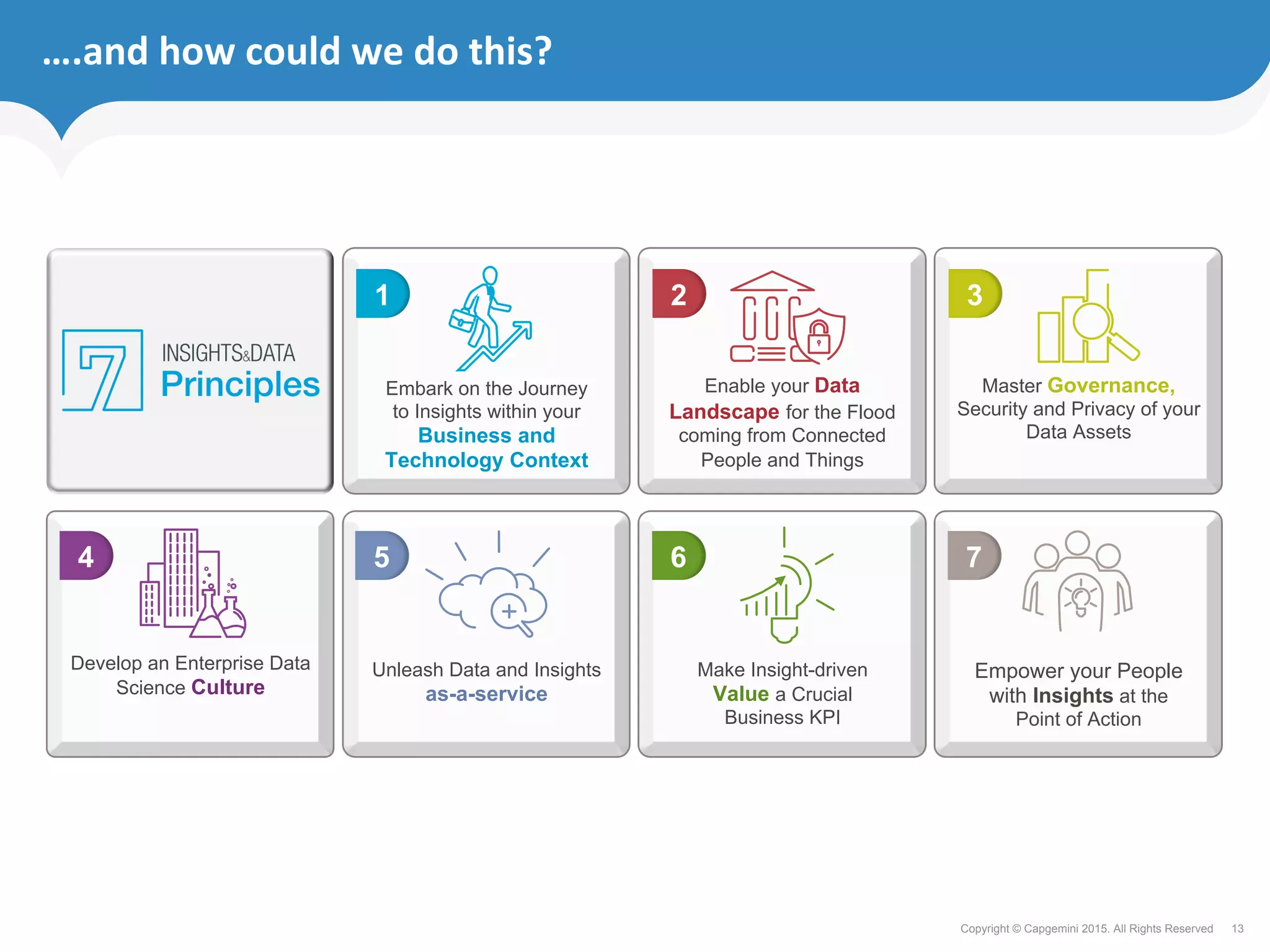


The document discusses how retailers can enhance customer experience through personalized services and improved data analytics using technologies like Apache Geode. Key challenges include managing vast data volumes and integrating insights for better customer engagement in a rapidly evolving retail landscape. Strategies proposed focus on leveraging real-time data, omnichannel capabilities, and modern IT architectures to drive customer loyalty and satisfaction.





































































































