Download as PDF, PPTX




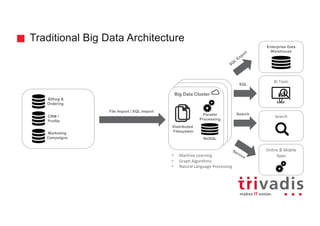
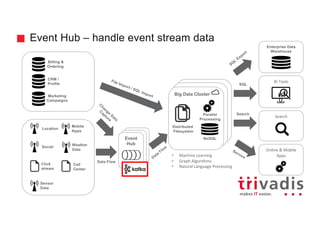
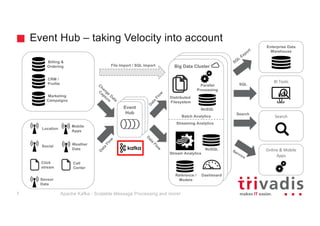
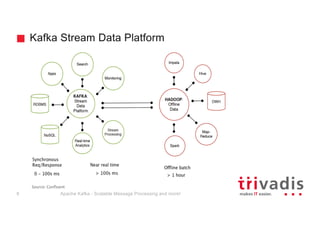



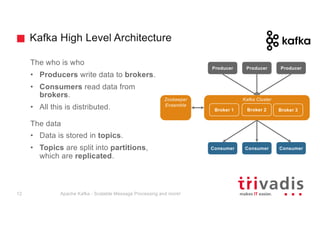
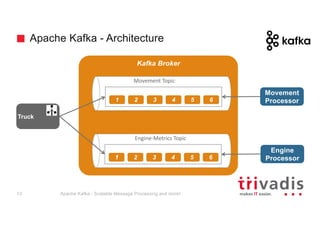
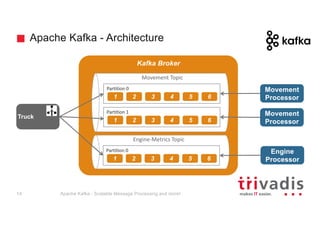
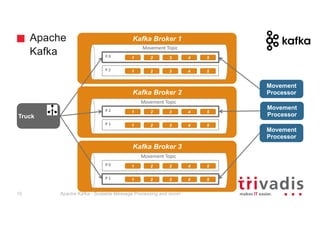
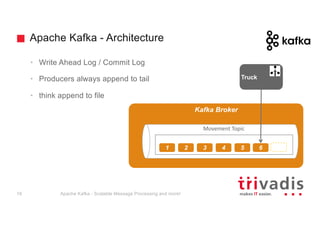
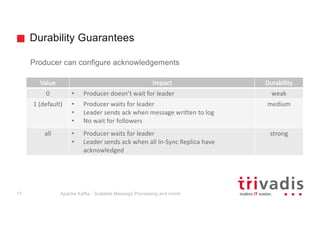
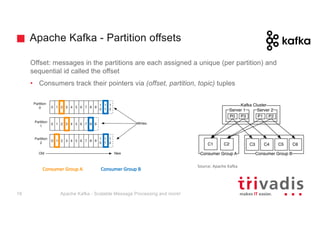





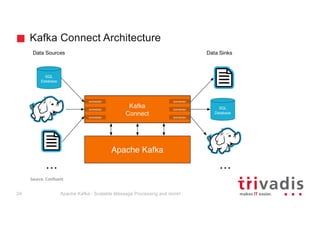




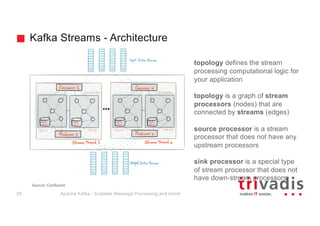
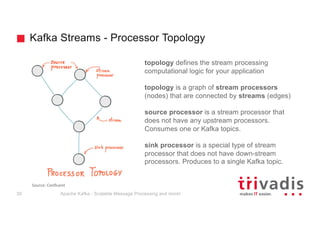

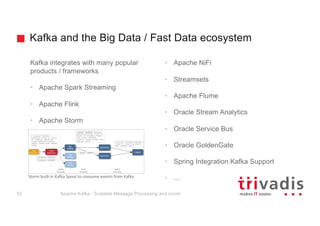

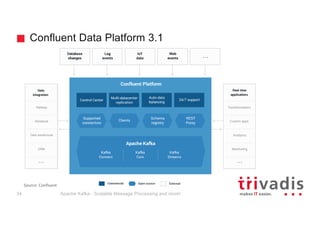

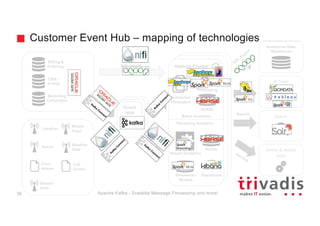



The document provides an overview of Apache Kafka, highlighting its role as a scalable message processing system designed for handling real-time data feeds. It discusses the architecture, components such as producers and consumers, performance benchmarks, and integration with the big data ecosystem. Additionally, it emphasizes Kafka's capabilities for high throughput, fault tolerance, and low-latency message delivery.























































































