Downloaded 134 times


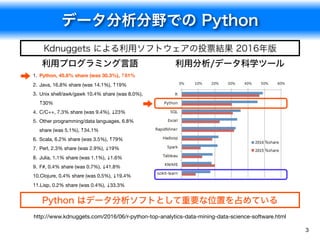






![scikit-learn:線形回帰の例
10
サンプルファイル:linear_regression.ipynb
線形回帰の利用例
パッケージの読み込み
In [1]: import numpy as np
from sklearn import linear_model
区間 [0, 10] と [0, 5] 上の一様分布に従う,2次元の独立変数のサンプルを100個生成
In [2]: X = np.array([np.random.uniform(0, 10, 100), np.random.uniform(0, 5, 100)]).T
回帰式 で従属変数を生成
In [3]: y = np.dot(np.array([[1, 3]]), X.T).ravel() + 10.0 + np.random.normal(0, 0.1, 100)
線形回帰用のクラスを生成する;データに依存しないパラメータを指定
ここでは切片項を使う指定を行う
In [4]: clr = linear_model.LinearRegression(fit_intercept=True)
y = 1 + 3 + 10x1 x2](https://image.slidesharecdn.com/fit2016-python-160905220248/85/Python-10-320.jpg)
![scikit-learn:線形回帰の例
11
http://scikit-learn.org/stable/documentation.html
の Tutorial や User Guide に多数のサンプル
fitメソッドでデータをあてはめ
In [5]: clr.fit(X, y)
従属変数の係数を調べると,ほぼ元の回帰式の と になっている
In [6]: clr.coef_
predictメソッドで推定したモデルに基づく予測
入力 に対する予測値は,ほぼ元の回帰式から得られる値 になっている
In [7]: clr.predict([1, 2])
Out[5]: LinearRegression(copy_X=True, fit_intercept=True, normalize=False)
1 3
Out[6]: array([ 0.99926392, 3.00026426])
x = (1, 2) 17
Out[7]: 17.00185966342633](https://image.slidesharecdn.com/fit2016-python-160905220248/85/Python-11-320.jpg)







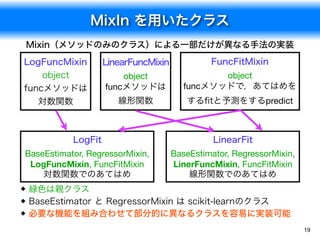

![scikit-learnとの連携
21
scikit-learn のクラスの規則に従うことで,その機能を利用する
fit() や predict() などのメソッドの規則を踏襲する
sklearn.base.BaseEstimator クラスを親とし,score() メソッドを
含む sklearn.base.ClassifierMixin なども継承する
交差確認による評価や,グリッド探索による超パラメータ設定が容易
になる
サンプルファイル:cross_validation.ipynb
IRISデータのロードと SVM 分類器の作成
In [5]: iris = datasets.load_iris()
clf = svm.SVC(kernel='linear', C=1)
交差確認による汎化誤差の評価.n_jobs=-1 とすると全CPUを使って並列計算
In [9]: scores = cross_validation.cross_val_score(clf, iris.data, iris.target, cv=5, n_jobs=5)
np.mean(scores)
Out[9]: 0.98000000000000009](https://image.slidesharecdn.com/fit2016-python-160905220248/85/Python-21-320.jpg)
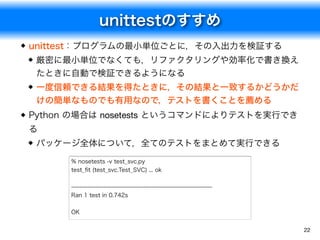
![unittestのファイル
23
class Test_SVC(unittest.TestCase):
def test_fit(self):
# 小さなテストデータから,テストする分類器でモデルを学習
from sklearn import svm
from sklearn import datasets
iris = datasets.load_iris()
clf = svm.SVC(kernel='linear', C=1)
clf.fit(iris.data[50:150, :], iris.target[50:150])
# 係数が一致しているかを検証
# 実数値は厳密な一致ではなく3桁か5桁ぐらいの精度で一致を検証
np.testing.assert_allclose(clf.coef_,
[[-0.59549776, -0.9739003 , 2.03099958, 2.00630267]],
rtol=1e-5)
# 分類結果が一致しているかを検証
# クラスのような離散値は厳密な一致を検証
classes = clf.predict(iris.data[[50, 51, 100, 101], :])
np.testing.assert_array_equal(classes, [1, 1, 2, 2])
サンプルファイル:test_svc.py](https://image.slidesharecdn.com/fit2016-python-160905220248/85/Python-23-320.jpg)



![NumPy 配列の生成
27
np.array を使った生成
要素が 1, 2, 3 である長さ 3 のベクトルの例
2重にネストしたリストで表した配列の例
np.empty:初期化なしの配列生成,メモリだけの確保
np.eye / np.identity:単位行列
np.ones, np.zeros:1行列,0行列
In [10]: a = np.array([1, 2, 3])
In [11]: a
Out[11]: array([1, 2, 3])
In [12]: a = np.array([[1.5, 0], [0, 3.0]])
In [13]: a
Out[13]:
array([[ 1.5, 0. ],
[ 0. , 3. ]])](https://image.slidesharecdn.com/fit2016-python-160905220248/85/Python-27-320.jpg)


![np.ndarrayの要素の参照
30
各次元ごとに何番目の要素を参照するかを指定する方法
例:1次元配列なら a[3],2次元配列なら a[1, 2] のように
※ 添え字の範囲は,1 からではなく 0 から,a.shape が返す値より
も一つ前の値まで(例:a.shape が (5,) なら 0 から 4 の範囲)
スライス:リストのスライスと同様の記法で配列の一部分を参照する
1次元配列:リストのスライス表記と同様の 開始:終了:増分 の形式
“:” のみを使って,行や列全体を取り出す操作は頻繁に利用
In [1]: x = np.array([0, 1, 2, 3, 4])
In [2]: x[1:3]
Out[2]: array([1, 2])
In [3]: x = np.array([[11, 12, 13], [21, 22, 23]])
In [4]: x[0, :]
Out[4]: array([11, 12, 13])
In [5]: x[:, 1]
Out[5]: array([12, 22])](https://image.slidesharecdn.com/fit2016-python-160905220248/85/Python-30-320.jpg)
![np.ndarrayと数学の行列
31
1次元の np.ndarray 配列には,線形代数でいう縦ベクトルや横ベ
クトルという区別はなく,1次元配列は転置できない
縦ベクトルや横ベクトルを区別して表現するには,それぞれ列数が1
である2次元の配列と,行数が1である2次元配列を利用
ベクトルを行列にするには np.newaxis や reshape メソッドを利用
※ reshpe で -1 は,全体の要素数を考慮して適宜選択の指定
In [1]: np.array([[1], [2], [3]])
Out[1]:
array([[1],
[2],
[3]])
In [1]: a = np.array([1, 2, 3])
In [2]: a[:, np.newaxis]
Out[2]:
array([[1],
[2],
[3]])
In [3]: a[np.newaxis, :]
Out[3]: array([[1, 2, 3]])
In [1]: a = np.array([1, 2, 3])
In [2]: a.reshape(-1, 1)
Out[2]:
array([[1],
[2],
[3]])
In [3]: a.reshape(1, -1)
Out[3]: array([[1, 2, 3]])](https://image.slidesharecdn.com/fit2016-python-160905220248/85/Python-31-320.jpg)
![ユニバーサル関数
32
ユニバーサル関数:入力した配列の各要素に関数を適用し,その結
果を入力と同じ形の配列して返す
ユニバーサル関数の機能を利用するには,mathパッケージの
math.log() などではなく,NumPy の np.log() を用いる
論理関数のユニバーサル関数は np.logical_and() など
ユーザ関数をユニバーサル化する np.vectorize() や np.frompyfunc()
np.vectorize() をデコレータとして使った例
In [10]: a
Out[10]: array([1, 2, 3])
In [11]: np.log(a)
Out[11]: array([ 0. , 0.69314718, 1.09861229])
In [1]: @np.vectorize
...: def squre_plus_one(x):
...: return x**2 + 1.0
In [2]: squre_plus_one(np.arange(3))
Out[2]: array([ 1., 2., 5.])](https://image.slidesharecdn.com/fit2016-python-160905220248/85/Python-32-320.jpg)
![ブロードキャスト
33
ブロードキャスト:要素ごとの演算を行うときに,配列の大きさが
異なっていれば自動的に要素をコピーして大きさを揃える機能
例:大きさがそれぞれ 0次元配列 a,長さ3の1次元ベクトル b,
2×3 の行列 c の要素積を求める
大きさが1の次元は,必要に応じて要素の値を自動的にコピーする
np.newaxis により次元数を合わせてから利用することを薦める
多重 for ループの各変数が,各次元に対応していると考えて実装する
とよいだろう
※ http://www.kamishima.net/mlmpyja/nbayes2/distclass.html
a b c
0 0
0 0 0 00 0
0 00 0
0 1 0 2
0 1 0 20 0
0 0 1 0 1 1 1 2
0 1 0 20 0
0 1 2
0
1
0 1 2
0
1
0 1 2
0
1
a[np.newaxis, np.newaxis] * b[np.newaxis, :] * c[:, :]](https://image.slidesharecdn.com/fit2016-python-160905220248/85/Python-33-320.jpg)
![行列演算の関数プログラミング的実装
34
map() と reduce() を使った関数プログラミング的な実装に基づく
と,NumPy による計算は理解しやすいだろう
リストではなく,共通の配列に map() して要素ごとの計算をしたあ
と,sum() や max() などの集約演算で reduce() すると考える
例:pLSAモデル
Pr[X, Y ] =
P
Z Pr[X|Z] Pr[Z|Y ] Pr[Y ]
Pr[X | Z ]
pXgZ[x, z]
Pr[Z | Y ]
pZgY[z, y]
Pr[Y ]
pY[y]
y
z
z
x
y](https://image.slidesharecdn.com/fit2016-python-160905220248/85/Python-34-320.jpg)
![行列演算の関数プログラミング的実装
35
pXgZ[x,z,np.newaxis]
z
x
np.newaxisやブロードキャストで共通の配列に揃える
pZgY[np.newaxis,z,y] pY[np.newaxis,np.newaxis,y]
z
y y
要素ごとの計算(map のイメージ)
pXgZ[x,z,np.newaxis] * pZgY[np.newaxis,z,y] * pY[np.newaxis,np.newaxis,y]
np.sum(pXgZ[x,z,np.newaxis] * pZgY[np.newaxis,z,y]
* pY[np.newaxis,np.newaxis,y], axis=1)
集約演算(reduceのイメージ)
z
y
x
newaxis
newaxis
newaxis
newaxis
sum()
x
y](https://image.slidesharecdn.com/fit2016-python-160905220248/85/Python-35-320.jpg)
![欠損値や無限値
36
欠損値 np.nan や無限大・無限小 np.inf などを含むデータの処理
配列の要素が全て有限値かどうかを検査する
np.all(np.isfinite(x)) の代わりに np.isfinite(x.sum())
np.nan を除外した集約演算
総和 np.nansum() や最大値 np.nanargmax() などがある
この場合に特化した bottleneck というパッケージも存在
欠損値を他の値で置き換える
ユニバーサルな3項演算子にあたる np.where() が便利
In [10]: a
Out[10]: array([ 0., nan, 1., inf, 2.])
In [11]: np.where(np.isfinite(a), a, -1.0)
Out[11]: array([ 0., -1., 1., -1., 2.])](https://image.slidesharecdn.com/fit2016-python-160905220248/85/Python-36-320.jpg)






![SymPy
43
数式処理を行うためのパッケージ
最初に sympy.init_session() を実行
しておくと便利
x, y, z, t を実数変数,k, m, n を
整数変数と認識するようになる
主な機能
微分:diff,積分:integrate,
極限:limit
展開:expand,単純化:
simplify,テイラー展開:series
方程式の解:solve
サンプルファイル:sympy_demo.ipynb
sympy.init_session() 実行後に行う
微分
In [2]:
diff((x ** 2 + log(x)) / x, x)
積分
In [3]:
integrate(x ** 3 + sin(x) ** 2, x)
展開
In [4]:
expand((x + 1)**2)
Out[2]:
(2x + ) − ( + log (x))
1
x
1
x
1
x2
x2
Out[3]:
+ − sin (x) cos (x)
x4
4
x
2
1
2
Out[4]:
+ 2x + 1x2](https://image.slidesharecdn.com/fit2016-python-160905220248/85/Python-43-320.jpg)
![scikit-statmodels
44
scikit-learn と同様に使える,scikit-learn に対する特色は
ARMA などの時系列分析モデル
R言語のように線形モデルを記述する記法を備える
多重検定など検定周辺の機能
パッケージの読み込み
In [1]: import numpy as np
import pandas as pd
import statsmodels.formula.api as smf
データの読み込み
In [2]: url = 'http://vincentarelbundock.github.io/Rdatasets/csv/HistData/Guerry.csv'
dat = pd.read_csv(url)
回帰モデルのあてはめ
In [3]: results = smf.ols('Lottery ~ Literacy + np.log(Pop1831)', data=dat).fit()
結果の表示
In [4]: print results.summary()
サンプルファイル:statsmodels_demo.ipynb](https://image.slidesharecdn.com/fit2016-python-160905220248/85/Python-44-320.jpg)

![PyMC
46
1. μ ~ Normal(0.0, 0.12
)
2. For i in 1 … N
(a) xi ~ Normal(μ, 1.02
)
μ x
N
仮想コード グラフィカルモデル
モデルの構築
生成モデルは,非常に単純:
※ NumPy の np.random.normal は平均と標準偏差で指定するが,PyMC の正規分布は,標準偏差ではなく精度(分散の逆数・逆行列)で指定す
る.
は,平均が で,分散が としておく.この については標本が観測される(グラフィカルモデルでいえば黒丸)ので,
value=x_sample と observed=True を指定しておく.
In [4]: mu = Normal('mu', 0, 1 / (0.1 ** 2))
x = Normal('x', mu=mu, tau=1/(1.0**2), value=x_sample, observed=True)
MCMCによる事後確率の推定
マルコフ連鎖のモデルを指定. input で関連する変数を指定し,適当な回数だけ反復する.
In [5]: M = MCMC(input=[mu, x])
M.sample(iter=10000)
μ ∼ Normal(0, )0.12
x ∼ Normal(μ, )1.02
x μ 1/0.01 x
[-----------------100%-----------------] 10000 of 10000 complete in 0.5 sec
サンプルファイル:pymc_demo.ipynb](https://image.slidesharecdn.com/fit2016-python-160905220248/85/Python-46-320.jpg)
![PyMC
47
左上は のサンプル値の反復中の変化,左下は自己相関で収束してるかどうかを確認できる.右が のデータを観測したあとのパラメータの事後
分布
In [6]: Matplot.plot(mu)
μ μ
Plotting mu](https://image.slidesharecdn.com/fit2016-python-160905220248/85/Python-47-320.jpg)
![自動微分
48
Theano や多くの深層
学習関連パッケージが
提供する機能
数値微分とは異なり,
解析的に微分し,数値
を代入した結果を得る
他にも数式を直接的に
定義可能
非線形最適化など各種
の数理計画法で結果を
利用できる
サンプルファイル:theano_auto_diff.ipynb
Theano 関連パッケージの読み込み
In [2]: import theano
import theano.tensor as T
スカラー変数のシンボルの定義
In [4]: x = T.dscalar('x') # double scalar
関数 を定義
In [5]: f = T.sin(x)
変数 に,値 を代入して関数 評価する:
In [10]: func_f = theano.function(inputs=[x], outputs=f)
func_f(np.pi)
関数 を微分して,値 で評価する:
In [12]: diff_f = theano.function(inputs=[x], outputs=T.grad(f, x))
diff_f(np.pi)
f(x) = sin(x)
x π f(x) sin(π) = 0
f(x) π (π) = cos(π) = −1.0sin′
Out[10]: array(1.2246467991473532e-16)
Out[12]: array(-1.0)](https://image.slidesharecdn.com/fit2016-python-160905220248/85/Python-48-320.jpg)
![Theano:シンボル変数の定義
49
In [1]: import theano
In [2]: import theano.tensor as T
In [3]: x = T.scalar('x')
In [4]: a = T.dmatrix('A')
In [5]: y = T.drow('y')
パッケージのインポート
シンボルの定義
dscalar は倍精度のスカラー,dmatrix は倍精度の行列など
引数はシンボルの名前.pprint などの表示に用いる
複数のシンボルをまとめて定義する scalars や matrices なども
b:バイト w:16bit整数 i:32bit整数 l:64bit整数
f:単精度 d:倍精度 c:複素数
scalar:スカラー vector:ベクトル
matrix:行列
row:行数1の行列 col:列数1の行列
tensor3:3次元テンソル tensor4:4次元テンソル](https://image.slidesharecdn.com/fit2016-python-160905220248/85/Python-49-320.jpg)
![Theano:関数の定義と評価
50
In [6]: f = theano.function([x, y], x + y)
In [7]: f(3, [[1, 2]])
Out[8]: array([[ 4., 5.]])
関数の定義と評価
theano.function( inputs=〈入力変数〉, outputs=〈出力式〉)
入力変数と出力式を指定して関数を定義
入力変数には定義したシンボルを与える
関数に入力を与えれば,関数をその入力値で評価して結果を返す
6行:入力はスカラー x と,行ベクトル y であることを,出力式は
出力式は x + y であることを指定して,関数 f を定義
7行:x=3,y=[[1, 2]] を与えると,x + y の式を評価して
[[4, 5]] の行ベクトルを得る](https://image.slidesharecdn.com/fit2016-python-160905220248/85/Python-50-320.jpg)
![Theano:関数の定義と評価
51
自動微分
In [9]: f = x**2 + T.log(x)
In [10]: grad_f = theano.function([x], T.grad(f, x))
In [11]: grad_f(1.0)
Out[11]: array(3.0)
T.grad(〈微分する式〉,〈微分する変数〉)
式や変数の指定には定義したシンボルを用いて記述する
9行:関数 f(x) = x2
+ log x を定義
10行:T.grad(f, x) で関数 f を変数 x
11行:f(x) を x で微分した f’(x) = 2x + 1/x を x=1.0 で評価して 3.0
の解を得る](https://image.slidesharecdn.com/fit2016-python-160905220248/85/Python-51-320.jpg)









こちらが改訂版なので,ダウンロードするならこちらで: http://www.kamishima.net/archive/scipy-overview.pdf 第15回情報科学技術フォーラム (FIT2016) での講演「科学技術計算関連Pythonパッケージの概要」の発表資料です. * 講演ページ: http://www.ipsj.or.jp/event/fit/fit2016/FIT2016program_web/data/html/event/event72.html * 小嵜 耕平さん資料「Python とデータ分析コンテストの実践」 https://speakerdeck.com/smly/python-todetafen-xi-kontesutofalseshi-jian * サンプルファイル: https://github.com/tkamishima/fit2016tutorial
![[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...](https://cdn.slidesharecdn.com/ss_thumbnails/20200221settransformer-200221020423-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Deep Learning 第15章 表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearning15-180601023904-thumbnail.jpg?width=640&height=640&fit=bounds)












![[DL輪読会]Vision Transformer with Deformable Attention (Deformable Attention Tra...](https://cdn.slidesharecdn.com/ss_thumbnails/dl0114-220114032933-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]A Higher-Dimensional Representation for Topologically Varying Neural R...](https://cdn.slidesharecdn.com/ss_thumbnails/ahigher-dimensionalrepresentationfortopologicallyvaryingneuralradiancefields1-210924021911-thumbnail.jpg?width=640&height=640&fit=bounds)












































