More Related Content

PDF

PDF
企業における自然言語処理技術の活用の現場(情報処理学会東海支部主催講演会@名古屋大学) 
PDF

PDF
Session4:「先進ビッグデータ応用を支える機械学習に求められる新技術」/比戸将平 
PDF

PDF

PDF
Twitter分析のためのリアルタイム分析基盤@第4回Twitter研究会 
PDF
Jubatusの紹介@第6回さくさくテキストマイニング What's hot

PPTX

PDF
Jubatus: 分散協調をキーとした大規模リアルタイム機械学習プラットフォーム 
PDF
20180305_ppl2018_演繹から帰納へ~新しいシステム開発パラダイム~ 
PDF

PDF

PDF
ICML2013読み会 ELLA: An Efficient Lifelong Learning Algorithm 
PDF
Deep learning を用いた画像から説明文の自動生成に関する研究の紹介 
PDF
IPAB2017 深層学習を使った新薬の探索から創造へ 
PDF
情報抽出入門 〜非構造化データを構造化させる技術〜 
PDF

PDF

PDF

PDF

PDF

PDF

PDF
Chainerのテスト環境とDockerでのCUDAの利用 
PDF

PDF

PDF
Facebookの人工知能アルゴリズム「memory networks」について調べてみた 
PDF
Viewers also liked

PPTX

PDF

PPTX

PDF

PDF

PDF
Twitterのリアルタイム分散処理システム「Storm」入門 demo 
PDF
論文紹介 Semi-supervised Learning with Deep Generative Models 
PDF
デブサミ2014-Stormで実現するビッグデータのリアルタイム処理プラットフォーム ~ストリームデータ処理から機械学習まで~ 
PDF

PDF

PPTX
Jubatus Casual Talks #2: 大量映像・画像のための異常値検知とクラス分類 
PDF

PDF

PDF
TensorFlow を使った�機械学習ことはじめ (GDG京都 機械学習勉強会) 
PDF

PDF

PDF
Tech-Circle Pepperで機械学習体験ハンズオン勉強会inアトリエ秋葉原 
PDF
Similar to Jubatusにおける大規模分散オンライン機械学習@先端金融テクノロジー研究会

PDF

PPTX
「ビジネス活用事例で学ぶ データサイエンス入門」輪読会#7資料 
PDF
Oracle Cloud Developers Meetup@東京 
PDF

PDF

PDF
Jubatusにおける大規模分散オンライン機械学習 
PDF

PDF
MapReduceによる大規模データを利用した機械学習 
PDF
行動計量シンポジウム20140321 http://lab.synergy-marketing.co.jp/activity/bsj_98th 
PDF
Introductory materials for Ziktas, a corporate reskilling training program 
PPT

PDF

PDF
データマイニングCROSS 第2部-機械学習・大規模分散処理 
PDF
Introductory materials for Ziktas, a corporate reskilling training program 
PPTX
(2017.8.27) Elasticsearchと科学技術ビッグデータが切り拓く日本の知の俯瞰と発見 
PDF

PDF

PDF

PDF
Jubatusのリアルタイム分散レコメンデーション@TokyoWebmining#17 
PDF
Jubatusのリアルタイム分散レコメンデーション@TokyoNLP#9 More from Yuya Unno

PDF

PDF

PDF

PDF

PDF

PDF

PDF

PDF
NIP2015読み会「End-To-End Memory Networks」 
PDF
最先端NLP勉強会�“Learning Language Games through Interaction”�Sida I. Wang, Percy L... 
PDF

PDF

PDF
ベンチャー企業で言葉を扱うロボットの研究開発をする 
PDF
大規模データ時代に求められる自然言語処理 -言語情報から世界を捉える- 
PDF
形態素列パターンマッチャー�MIURAをつくりました @DSIRNLP#6 
PDF

PDF

PDF

PDF
EMNLP2014読み会 "Efficient Non-parametric Estimation of Multiple Embeddings per ... 
PDF

PDF
ACL読み会@PFI �“How to make words with vectors: Phrase generation in distributio... Jubatusにおける大規模分散オンライン機械学習@先端金融テクノロジー研究会
- 1.
- 2.
株式会社 Preferred Infrastructure
l 略略称 PFI
l 設⽴立立2006年年3⽉月
l 代表者 ⻄西川 徹
l 社員数 26名(2012/4現在)
l 所在地 〒113-‐‑‒0033 東京都⽂文京区本郷2-‐‑‒40-‐‑‒1
l URL http://preferred.jp/
l 事業概要 検索索/推薦(レコメンデーション)分野での製品開発
販売、サービス提供および技術提供
⼤大規模分散コンピューティング分野での技術提供
2
会社概要
- 3.
- 4.
- 5.
- 6.
- 7.
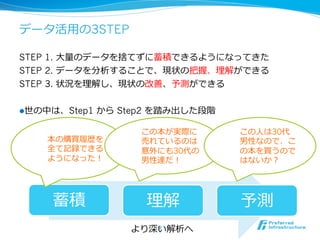
Big Data !
l 巨⼤大なデータがあらゆる分野で⽣生まれ続けている
l データが⼤大きいことも重要だが、増加し続けていることが重要
l データ量量の変化に対応できるスケーラブルなシステムが求められる
l データの種類・⽣生成される場所は多様化
l 定形データのみならず、⾮非定形データも増加
7
テキスト ⾏行行動履履歴 画像 ⾳音声 映像 信号 ⾦金金融 ゲノム
⼈人 PC モバイル センサー ⾞車車 ⼯工場 EC 病院
⽣生成される場所
データの種類
- 8.
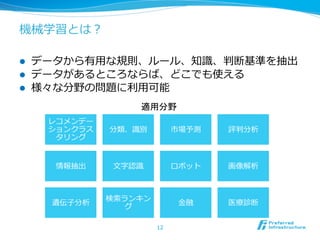
ビッグデータ解析の現状
l ウェブから他の産業領領域へ
l ウェブ領領域では成功事例例多数(Google,Amazon, Facebook)
l ウェブ以外の分野でのビッグデータ活⽤用の可能性は未知数
l ⾦金金融・保険・医療療・⼩小売・運輸・製造・インフラ
l 新しい技術・戦略略・ビジネス構築が必要になっていく
l 分析は量量のみならず多様化・質・速さへ
l データの種類や性質は様々であり分野の専⾨門的知識識も必要
l 単なる集計のみならず予測・発⾒見見・分類など深い分析が必要
l いくつかの分析ではリアルタイム処理理が鍵となる
→即時処理理、即時対応 情報の在庫を作らない
8
- 9.
- 10.
- 11.
- 12.
- 13.
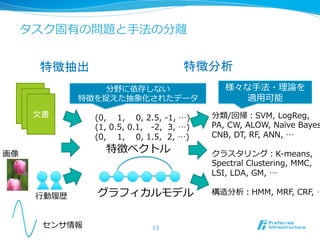
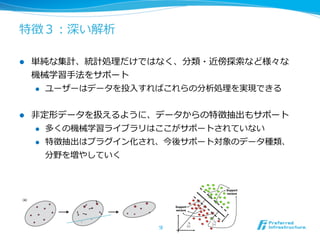
タスク固有の問題と⼿手法の分離離
13
⽂文書 (0, 1, 0, 2.5, -‐‑‒1, …)
(1, 0.5, 0.1, -‐‑‒2, 3, …)
(0, 1, 0, 1.5, 2, …)
特徴ベクトル
グラフィカルモデル
分類/回帰:SVM, LogReg,
PA, CW, ALOW, Naïve Bayes
CNB, DT, RF, ANN, …
クラスタリング:K-‐‑‒means,
Spectral Clustering, MMC,
LSI, LDA, GM, …
構造分析:HMM, MRF, CRF, …
画像
センサ情報
⾏行行動履履歴
分野に依存しない
特徴を捉えた抽象化されたデータ
様々な⼿手法・理理論論を
適⽤用可能
特徴抽出
特徴分析
- 14.
- 15.
- 16.
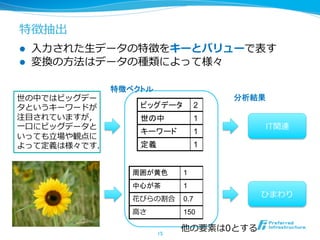
特徴分析
l 予測
l ⼊入⼒力力xから出⼒力力yを推定(分類:yがカテゴリ値 回帰:yが連続値)
l 近傍探索索
l 似たデータはこれまで無かったか,それらはどういうデータか
l 統計分析
l 平均・最⼤大/最⼩小・エントロピー・モーメント・相関
l 外れ値、コンセプトドリフト分析
l これまでのデータ傾向から外れた値はあるか、傾向は変わってるか
l クラスタリング
l 似たデータ同⼠士を纏め上げ、グループ化する
l 原因分析
l 複数の特徴の中で最も現象を説明し得る原因は何か?
16
- 17.
- 18.
- 19.
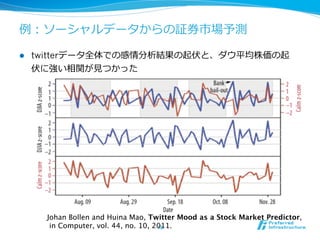
例例1:ECサイトの分析
19
l ユーザー分析
l 属性予測
l 性別、年年齢、家族構成、地域、嗜好、過去の⾏行行動
l ⾏行行動予測
l 商品を購⼊入するか、良良い評判を作るか、継続的に会社と関わるか
l ユーザーへの推薦
l ユーザーの近傍探索索を⾏行行い、似たユーザーを調べどのような商品
を購⼊入するかどうかを調べ、推薦する
l ユーザーへのサポート
l 外れ値、コンセプトドリフトを調べ、何か問題が起きているか、
⾏行行動パターンが変わってきているのかを分析する
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
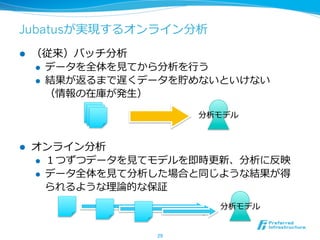
Jubatus
25
リアルタイム
ストリーム 分散並列列深い解析
l NTT SIC*とPreferred Infrastructureによる共同開発
l 2011年年10⽉月よりOSSで公開 http://jubat.us/
* NTT SIC: NTT研究所 サイバーコミュニケーション研究所 ソフトウェアイノベーションセンタ
- 26.
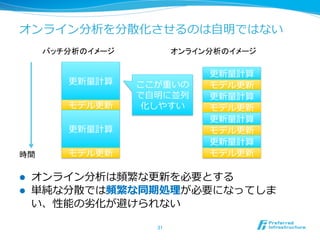
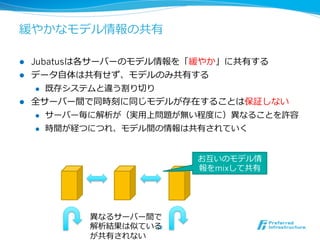
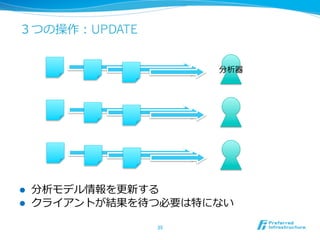
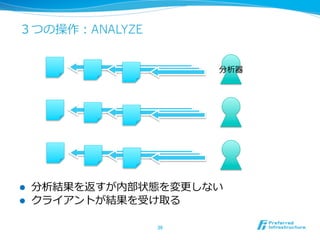
特徴1: リアルタイム /ストリーム処理理
l 解析結果は、データ投⼊入後すぐ返って来る
l 分類などの学習/分析も⼀一瞬で処理理
l twitterの内容を分析して分類するのは6000QPS
l 分類、統計分析、回帰、近傍探索索など様々な処理理をリアルタイム
、ストリームで処理理
l データを貯めることなく、その場で処
l 従来バッチで処理理していた様々な解析をリアルタイム・ストリー
ムで同様の精度度処理理できるよう、新しく解析⼿手法を開発
26
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
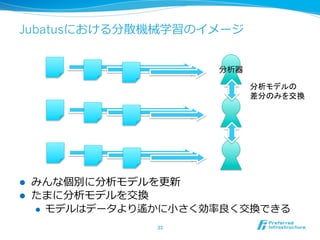
Jubatusの分析
l 現在, 以下の分析をサポート
l 分類
l 教師有多クラス分類:Perceptron, PA, CW, AROW
l 回帰
l 教師有回帰分析:PA
l 近傍探索索
l Inverted File Index, LSH
l 統計
l 平均、分散、エントロピー、モーメント
l また、グラフデータを対象にした分析もサポート予定
l ソーシャルデータやネットワーク分析なども可能となる
40
- 41.
- 42.
- 43.
- 44.
- 45.