Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Koichi Hamada
8,468 views
データマイニングCROSS 第2部-機械学習・大規模分散処理
データマイニングCROSS 2012 パネルディスカッション第2部-機械学習・大規模分散処理 実ビジネス・サービス活用のノウハウと展望
Technology
◦
Read more
5
Save
Share
Embed
Embed presentation
1
/ 23
2
/ 23
3
/ 23
4
/ 23
5
/ 23
6
/ 23
7
/ 23
8
/ 23
9
/ 23
10
/ 23
11
/ 23
12
/ 23
13
/ 23
14
/ 23
15
/ 23
16
/ 23
17
/ 23
18
/ 23
19
/ 23
20
/ 23
21
/ 23
22
/ 23
23
/ 23
More Related Content
PDF
『Mobageの大規模データマイニング活用と 意思決定』- #IBIS 2012 -ビジネスと機械学習の接点-
by
Koichi Hamada
PDF
データマイニングCROSS 2012 Opening Talk - データマイニングの実サービス・ビジネス適用と展望
by
Koichi Hamada
PDF
『モバゲーの大規模データマイニング基盤におけるHadoop活用』-Hadoop Conference Japan 2011- #hcj2011
by
Koichi Hamada
PDF
『MobageのAnalytics活用したサービス開発』 - データマイニングCROSS2014 #CROSS2014
by
Koichi Hamada
PDF
Large Scale Data Mining of the Mobage Service - #PRMU 2011 #Mahout #Hadoop
by
Koichi Hamada
PDF
DeNAの大規模データマイニング活用したサービス開発
by
Koichi Hamada
PDF
ソーシャルウェブ と レコメンデーション -第4回データマイニング+WEB勉強会@東京
by
Koichi Hamada
PDF
ソーシャルデザインパターン -評判と情報収集-
by
Koichi Hamada
『Mobageの大規模データマイニング活用と 意思決定』- #IBIS 2012 -ビジネスと機械学習の接点-
by
Koichi Hamada
データマイニングCROSS 2012 Opening Talk - データマイニングの実サービス・ビジネス適用と展望
by
Koichi Hamada
『モバゲーの大規模データマイニング基盤におけるHadoop活用』-Hadoop Conference Japan 2011- #hcj2011
by
Koichi Hamada
『MobageのAnalytics活用したサービス開発』 - データマイニングCROSS2014 #CROSS2014
by
Koichi Hamada
Large Scale Data Mining of the Mobage Service - #PRMU 2011 #Mahout #Hadoop
by
Koichi Hamada
DeNAの大規模データマイニング活用したサービス開発
by
Koichi Hamada
ソーシャルウェブ と レコメンデーション -第4回データマイニング+WEB勉強会@東京
by
Koichi Hamada
ソーシャルデザインパターン -評判と情報収集-
by
Koichi Hamada
What's hot
PDF
Generative Adversarial Networks (GAN) @ NIPS2017
by
Koichi Hamada
PDF
DeNAのAI活用したサービス開発
by
Koichi Hamada
PDF
リクルートのビッグデータ活用基盤とデータ活用に向けた取組み
by
Recruit Technologies
PDF
[Developers Summit 2015 講演資料] リクルートテクノロジーズ 14,000件/秒の配信を実現した リクルートのモバイルアプリを支え...
by
Recruit Technologies
PDF
Generative Adversarial Networks (GAN) の学習方法進展・画像生成・教師なし画像変換
by
Koichi Hamada
PDF
A3RT -The details and actual use cases of“Analytics & Artificial intelligence...
by
Recruit Technologies
PPTX
決定版:サービスの盛り上がり具合をユーザの数(DAU)から読み解く方法
by
Daisuke Nogami
PPTX
何故DeNAがverticaを選んだか?
by
Kenshin Yamada
PDF
"Mahout Recommendation" - #TokyoWebmining 14th
by
Koichi Hamada
PDF
リクルート式Hadoopの使い方
by
Recruit Technologies
PPTX
【機械学習勉強会】画像の翻訳 ”Image-to-Image translation”
by
yoshitaka373
PDF
20150625 cloudera
by
Recruit Technologies
PDF
リクルートテクノロジーズが語る 企業における、「AI/ディープラーニング」活用のリアル
by
Recruit Technologies
PDF
Laplacian Pyramid of Generative Adversarial Networks (LAPGAN) - NIPS2015読み会 #...
by
Koichi Hamada
PPTX
[DL輪読会] MoCoGAN: Decomposing Motion and Content for Video Generation
by
Deep Learning JP
PDF
リクルート式AIの活用法
by
Recruit Technologies
PDF
リクルートにおける画像解析事例紹介と周辺技術紹介
by
Recruit Technologies
PDF
リクルートのWebサービスを支える共通インフラ「RAFTEL」
by
Recruit Technologies
PPTX
人と機械の協働によりデータ分析作業の効率化を目指す協働型機械学習技術(NTTデータ テクノロジーカンファレンス 2020 発表資料)
by
NTT DATA Technology & Innovation
PDF
DataRobot活用状況@リクルートテクノロジーズ
by
Recruit Technologies
Generative Adversarial Networks (GAN) @ NIPS2017
by
Koichi Hamada
DeNAのAI活用したサービス開発
by
Koichi Hamada
リクルートのビッグデータ活用基盤とデータ活用に向けた取組み
by
Recruit Technologies
[Developers Summit 2015 講演資料] リクルートテクノロジーズ 14,000件/秒の配信を実現した リクルートのモバイルアプリを支え...
by
Recruit Technologies
Generative Adversarial Networks (GAN) の学習方法進展・画像生成・教師なし画像変換
by
Koichi Hamada
A3RT -The details and actual use cases of“Analytics & Artificial intelligence...
by
Recruit Technologies
決定版:サービスの盛り上がり具合をユーザの数(DAU)から読み解く方法
by
Daisuke Nogami
何故DeNAがverticaを選んだか?
by
Kenshin Yamada
"Mahout Recommendation" - #TokyoWebmining 14th
by
Koichi Hamada
リクルート式Hadoopの使い方
by
Recruit Technologies
【機械学習勉強会】画像の翻訳 ”Image-to-Image translation”
by
yoshitaka373
20150625 cloudera
by
Recruit Technologies
リクルートテクノロジーズが語る 企業における、「AI/ディープラーニング」活用のリアル
by
Recruit Technologies
Laplacian Pyramid of Generative Adversarial Networks (LAPGAN) - NIPS2015読み会 #...
by
Koichi Hamada
[DL輪読会] MoCoGAN: Decomposing Motion and Content for Video Generation
by
Deep Learning JP
リクルート式AIの活用法
by
Recruit Technologies
リクルートにおける画像解析事例紹介と周辺技術紹介
by
Recruit Technologies
リクルートのWebサービスを支える共通インフラ「RAFTEL」
by
Recruit Technologies
人と機械の協働によりデータ分析作業の効率化を目指す協働型機械学習技術(NTTデータ テクノロジーカンファレンス 2020 発表資料)
by
NTT DATA Technology & Innovation
DataRobot活用状況@リクルートテクノロジーズ
by
Recruit Technologies
Similar to データマイニングCROSS 第2部-機械学習・大規模分散処理
PDF
Session4:「先進ビッグデータ応用を支える機械学習に求められる新技術」/比戸将平
by
Preferred Networks
PDF
tut_pfi_2012
by
Preferred Networks
PDF
Data Science Summit 2012 レポート
by
nagix
PDF
[R勉強会][データマイニング] R言語による時系列分析
by
Koichi Hamada
PDF
Jubatus: 分散協調をキーとした大規模リアルタイム機械学習プラットフォーム
by
Preferred Networks
PDF
おしゃスタat銀座
by
Issei Kurahashi
PDF
基調講演:「多様化する情報を支える技術」/西川徹
by
Preferred Networks
PPTX
「ビジネス活用事例で学ぶ データサイエンス入門」輪読会#7資料
by
Shintaro Nomura
PDF
10回開催記念 「データマイニング+WEB ~データマイニング・機械学習活用による継続進化~」ー第10回データマイニング+WEB勉強会@東京ー #Toky...
by
Koichi Hamada
PDF
オープニングトーク - 創設の思い・目的・進行方針 -データマイニング+WEB勉強会@東京
by
Koichi Hamada
PDF
mlabforum2012_okanohara
by
Preferred Networks
PDF
避けては通れないビッグデータ周辺の重要課題
by
kurikiyo
PDF
情報処理学会第74回全国大会 私的勉強会と学会の未来
by
shunya kimura
PDF
オープンソースで開くビッグデータの扉
by
Open Source Software Association of Japan
PDF
Toward Research that Matters
by
Ryohei Fujimaki
PDF
SocialAnalyticsとCQ5がスゴイ
by
Makoto Shimizu
PDF
おしゃスタ@リクルート
by
Issei Kurahashi
PDF
(道具としての)データサイエンティストのつかい方
by
Shohei Hido
PPTX
【セミナー資料】ソーシャル×ビッグデータ×Biで切り開くこれからの企業のあり方
by
uhuru_jp
PDF
【Azureデータ分析シリーズ】非専門家向け/利用部門主導で始めるデータ分析_ナレッジコミュニケーション公開資料
by
Takaya Nakanishi
Session4:「先進ビッグデータ応用を支える機械学習に求められる新技術」/比戸将平
by
Preferred Networks
tut_pfi_2012
by
Preferred Networks
Data Science Summit 2012 レポート
by
nagix
[R勉強会][データマイニング] R言語による時系列分析
by
Koichi Hamada
Jubatus: 分散協調をキーとした大規模リアルタイム機械学習プラットフォーム
by
Preferred Networks
おしゃスタat銀座
by
Issei Kurahashi
基調講演:「多様化する情報を支える技術」/西川徹
by
Preferred Networks
「ビジネス活用事例で学ぶ データサイエンス入門」輪読会#7資料
by
Shintaro Nomura
10回開催記念 「データマイニング+WEB ~データマイニング・機械学習活用による継続進化~」ー第10回データマイニング+WEB勉強会@東京ー #Toky...
by
Koichi Hamada
オープニングトーク - 創設の思い・目的・進行方針 -データマイニング+WEB勉強会@東京
by
Koichi Hamada
mlabforum2012_okanohara
by
Preferred Networks
避けては通れないビッグデータ周辺の重要課題
by
kurikiyo
情報処理学会第74回全国大会 私的勉強会と学会の未来
by
shunya kimura
オープンソースで開くビッグデータの扉
by
Open Source Software Association of Japan
Toward Research that Matters
by
Ryohei Fujimaki
SocialAnalyticsとCQ5がスゴイ
by
Makoto Shimizu
おしゃスタ@リクルート
by
Issei Kurahashi
(道具としての)データサイエンティストのつかい方
by
Shohei Hido
【セミナー資料】ソーシャル×ビッグデータ×Biで切り開くこれからの企業のあり方
by
uhuru_jp
【Azureデータ分析シリーズ】非専門家向け/利用部門主導で始めるデータ分析_ナレッジコミュニケーション公開資料
by
Takaya Nakanishi
More from Koichi Hamada
PDF
Anime Generation with AI
by
Koichi Hamada
PDF
Generative Adversarial Networks @ ICML 2019
by
Koichi Hamada
PDF
AIによるアニメ生成の挑戦
by
Koichi Hamada
PDF
Generative Adversarial Networks (GANs) and Disentangled Representations @ N...
by
Koichi Hamada
PDF
対話返答生成における個性の追加反映
by
Koichi Hamada
PDF
NIPS 2016 Overview and Deep Learning Topics
by
Koichi Hamada
PDF
DeNAの機械学習・深層学習活用した 体験提供の挑戦
by
Koichi Hamada
PDF
複雑ネットワーク上の伝搬法則の数理
by
Koichi Hamada
PDF
Mahout JP - #TokyoWebmining 11th #MahoutJP
by
Koichi Hamada
PDF
「R言語による Random Forest 徹底入門 -集団学習による分類・予測-」 - #TokyoR #11
by
Koichi Hamada
PDF
Mahout Canopy Clustering - #TokyoWebmining 9
by
Koichi Hamada
PDF
Apache Mahout - Random Forests - #TokyoWebmining #8
by
Koichi Hamada
PDF
「樹木モデルとランダムフォレスト-機械学習による分類・予測-」-データマイニングセミナー
by
Koichi Hamada
PDF
「はじめてでもわかる RandomForest 入門-集団学習による分類・予測 -」 -第7回データマイニング+WEB勉強会@東京
by
Koichi Hamada
PDF
Introduction to Mahout Clustering - #TokyoWebmining #6
by
Koichi Hamada
PDF
ベイジアンネットとレコメンデーション -第5回データマイニング+WEB勉強会@東京
by
Koichi Hamada
Anime Generation with AI
by
Koichi Hamada
Generative Adversarial Networks @ ICML 2019
by
Koichi Hamada
AIによるアニメ生成の挑戦
by
Koichi Hamada
Generative Adversarial Networks (GANs) and Disentangled Representations @ N...
by
Koichi Hamada
対話返答生成における個性の追加反映
by
Koichi Hamada
NIPS 2016 Overview and Deep Learning Topics
by
Koichi Hamada
DeNAの機械学習・深層学習活用した 体験提供の挑戦
by
Koichi Hamada
複雑ネットワーク上の伝搬法則の数理
by
Koichi Hamada
Mahout JP - #TokyoWebmining 11th #MahoutJP
by
Koichi Hamada
「R言語による Random Forest 徹底入門 -集団学習による分類・予測-」 - #TokyoR #11
by
Koichi Hamada
Mahout Canopy Clustering - #TokyoWebmining 9
by
Koichi Hamada
Apache Mahout - Random Forests - #TokyoWebmining #8
by
Koichi Hamada
「樹木モデルとランダムフォレスト-機械学習による分類・予測-」-データマイニングセミナー
by
Koichi Hamada
「はじめてでもわかる RandomForest 入門-集団学習による分類・予測 -」 -第7回データマイニング+WEB勉強会@東京
by
Koichi Hamada
Introduction to Mahout Clustering - #TokyoWebmining #6
by
Koichi Hamada
ベイジアンネットとレコメンデーション -第5回データマイニング+WEB勉強会@東京
by
Koichi Hamada
データマイニングCROSS 第2部-機械学習・大規模分散処理
1.
CROSS 2012
2012/01/27 データマイニングCROSS パネルディスカッション第2部 機械学習・大規模分散処理 実ビジネス・サービス活用のノウハウと展望 モデレータ: 濱田晃一(@hamadakoichi) 1
2.
機械学習や大規模分散処理の実活用ノウハウと展望
2
3.
機械学習や大規模分散処理の実活用ノウハウと展望
充分な時間を充て パネリスト間での議論を優先する 3
4.
機械学習や大規模分散処理の実活用ノウハウと展望
充分な時間を充て パネリスト間での議論を優先する パネル項目を3つに絞る 4
5.
機械学習や大規模分散処理の実活用ノウハウと展望 ◆17:05-17:15(10分)
パネリスト紹介・業界特徴紹介 ◆17:15-17:35(20分) データマイニングの成功例・失敗例と そのポイント ◆17:35-17:55(20分) 今後注目していること どういう方向に向かってこうとしているか 5
6.
機械学習や大規模分散処理の実活用ノウハウと展望 ◆17:05-17:15(10分)
パネリスト紹介・業界特徴紹介 ◆17:15-17:35(20分) データマイニングの成功例・失敗例と そのポイント ◆17:35-17:55(20分) 今後注目していること どういう方向に向かってこうとしているか 6
7.
7
8.
8
9.
山崎大輔 広告配信エンジン
9
10.
パネリスト氏名
パネリスト経歴サマリーメッセージ 対談とか ◆項目: 講演とか xxxx 講座? ◆項目: 広告/マーケティングプランニングのお手伝いを、 xxxx データがちょっとしかなかったころから、 データ分析/統計分析をベースにやってきてます 図・表等 寄稿とか 10
11.
業界名 マーケティングコミュニケーション
広告費はGDPの1〜2% かつては「マーコム費は半分は無駄だがやめられない」 ネット広告は測れる 〜誤解/誤用も さらに“デジタルなもの”の普及でデータが絶賛爆発中 それでも不確定要素が88%くらい(勘) 11
12.
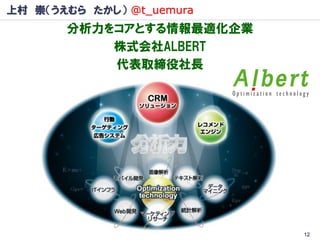
上村 崇(うえむら たかし)
@t_uemura 分析力をコアとする情報最適化企業 株式会社ALBERT 代表取締役社長 12
13.
広告最適化・データマイニング・レコメンデーション・CRM 消費者行動を予測するマーケティングサイエンス ◆データの特徴: 多種多様なデータ(業種・デバイス・データ種類etc) Behavior data(閲覧・クリック・お気に入り・購買etc) ◆解析の特徴: 消費者行動分析(マーケティングサイエンス) ソリューション視点(どのように打ち手につなげるか) 予測モデルの必要性(先回りの必要性)
13
14.
最近の課題意識(@t_uemura)
14
15.
奥野 陽 (@nokuno)
自然言語処理,機械学習,データマイニングを 専門とするソフトウェアエンジニア ◆Social IME開発者: 未踏ソフトウェア採択 非構造 ユーザ参加型IME 化データ ◆TokyoNLP主催者: 深い 大規模 かな漢字変換 スペル訂正 解析 データ 機械翻訳 15
16.
自然言語処理 人間の言語をコンピュータによって解析・生成する分野で, 検索エンジン・レコメンド・IMEなどの応用を持つ ◆データの特徴:
非構造化 基礎技術 応用技術 大規模 意味解析 検索エンジン ◆解析の特徴: スペル訂正 構文解析 系列の解析 機械翻訳 木構造の解析 形態素解析 日本語入力 グラフの解析 16
17.
機械学習や大規模分散処理の実活用ノウハウと展望 ◆17:05-17:15(10分)
パネリスト紹介・業界特徴紹介 ◆17:15-17:35(20分) データマイニングの成功例・失敗例と そのポイント ◆17:35-17:55(20分) 今後注目していること どういう方向に向かってこうとしているか 17
18.
機械学習や大規模分散処理の実活用ノウハウと展望 ◆17:05-17:15(10分)
パネリスト紹介・業界特徴紹介 ◆17:15-17:35(20分) データマイニングの成功例・失敗例と そのポイント ◆17:35-17:55(20分) 今後注目していること どういう方向に向かってこうとしているか 18
19.
業界全体での活用
各業界での データマイニング活用 各業界でそれぞれの人々にあった 適切なサービス提供 19
20.
業界全体での活用 データマイニングの活用へ向けた各オープンコミュニティ
みなさんぜひご参加ください 20
21.
業界全体での活用 データマイニングの活用へ向けた各オープンコミュニティ
みなさんぜひご参加ください TokyoWebmining Tokyo.R TokyoNLP DSIRNLP 21
22.
業界全体での活用 データマイニングの活用へ向けた各オープンコミュニティ
みなさんぜひご参加ください TokyoWebmining Tokyo.R TokyoNLP DSIRNLP ご清聴ありがとうございました 22
23.
機械学習や大規模分散処理の実活用ノウハウと展望 ◆17:05-17:15(10分)
パネリスト紹介・業界特徴紹介 ◆17:15-17:35(20分) データマイニングの成功例・失敗例と そのポイント ◆17:35-17:55(20分) 今後注目していること どういう方向に向かってこうとしているか 23































![[Developers Summit 2015 講演資料] リクルートテクノロジーズ 14,000件/秒の配信を実現した リクルートのモバイルアプリを支え...](https://cdn.slidesharecdn.com/ss_thumbnails/developerssummit2015upload-150225211319-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)










![[DL輪読会] MoCoGAN: Decomposing Motion and Content for Video Generation](https://cdn.slidesharecdn.com/ss_thumbnails/0911mocogan-170911121936-thumbnail.jpg?width=640&height=640&fit=bounds)








![[R勉強会][データマイニング] R言語による時系列分析](https://cdn.slidesharecdn.com/ss_thumbnails/r-100423232629-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)































