Download as PDF, PPTX















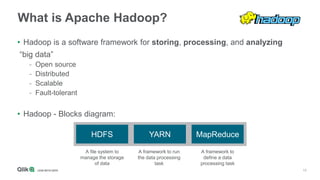
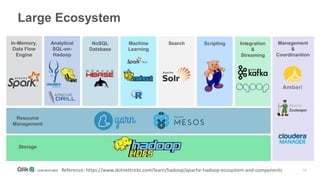
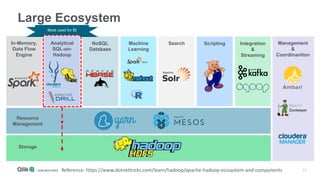

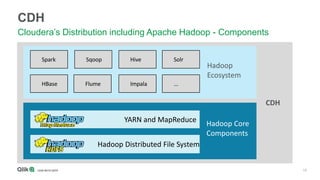
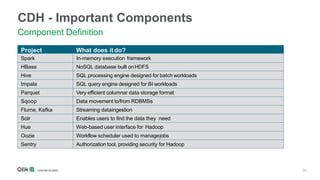





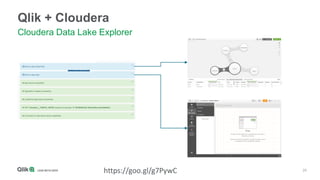



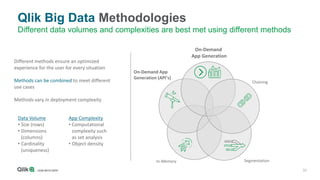
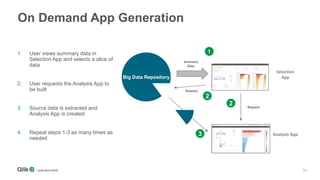
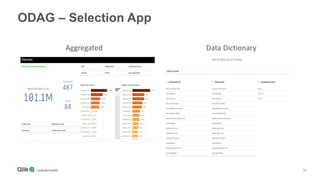






The document outlines the integration of Qlik with Cloudera, highlighting the big data landscape, Hadoop ecosystem, and 15 integration points. It discusses key components of Cloudera's distribution, such as Spark, HBase, and Hive, and describes various methodologies for handling big data. Additionally, it covers methods for on-demand app generation to optimize user experience in data analysis.























































































