Downloaded 71 times



















![#!/usr/bin/env python
# encoding: utf-8
import sys
sys.path.append(".")
from pymongo_hadoop import BSONMapper
def mapper(documents):
for doc in documents:
if doc['user'] != None:
yield {'_id': doc['user']['name'].encode('utf-8'),
'followers':doc['user']['followers_count']}
BSONMapper(mapper)
print >> sys.stderr, "Done Mapping!"](https://image.slidesharecdn.com/talkmongodbmunich20121016-121015163941-phpapp01/85/Map-Confused-A-practical-approach-to-Map-Reduce-with-MongoDB-30-320.jpg)
![#!/usr/bin/env python
# encoding: utf-8
import sys
sys.path.append('.')
from pymongo_hadoop import BSONReducer
def reducer(key, values):
print >> sys.stderr, "Processing key %s" % key.encode('utf-8')
_count = 0
for v in values:
if _count < v['followers']:
_count = v["followers"]
return {"_id": key.encode('utf-8'), "count": _count}
BSONReducer(reducer)
print >> sys.stderr, "Done Reducing!"](https://image.slidesharecdn.com/talkmongodbmunich20121016-121015163941-phpapp01/85/Map-Confused-A-practical-approach-to-Map-Reduce-with-MongoDB-31-320.jpg)
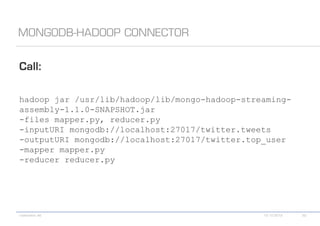

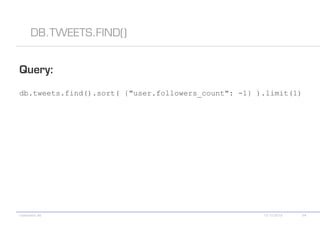

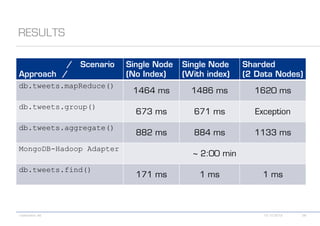

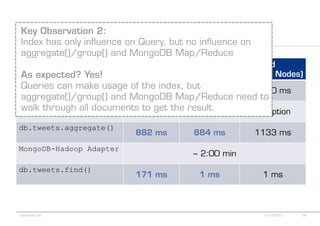
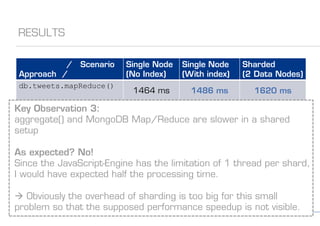
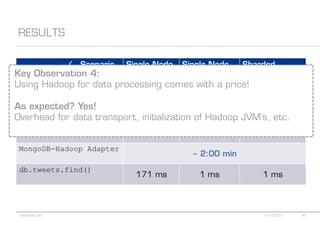




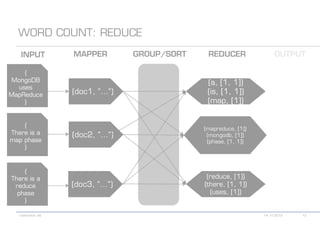
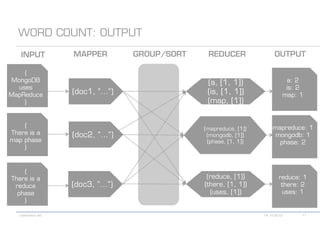
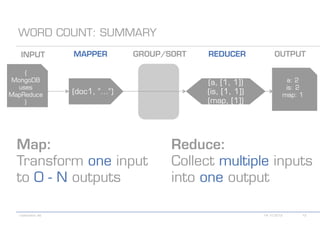
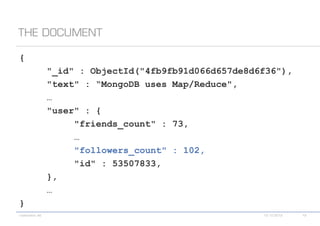
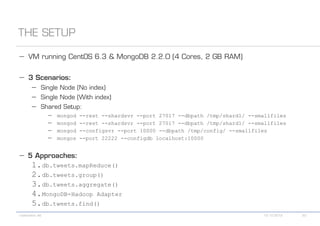
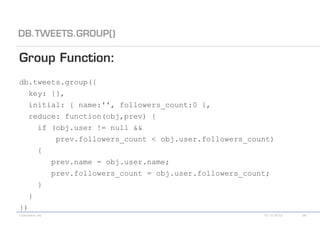
The document details various MongoDB commands and methods related to data processing, particularly focusing on querying and analyzing user data from tweets. It includes scripts for map/reduce operations and aggregation to identify users with the maximum followers. Additionally, it references the use of the MongoDB-Hadoop adapter for further data manipulation.



















































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)




