Downloaded 44 times










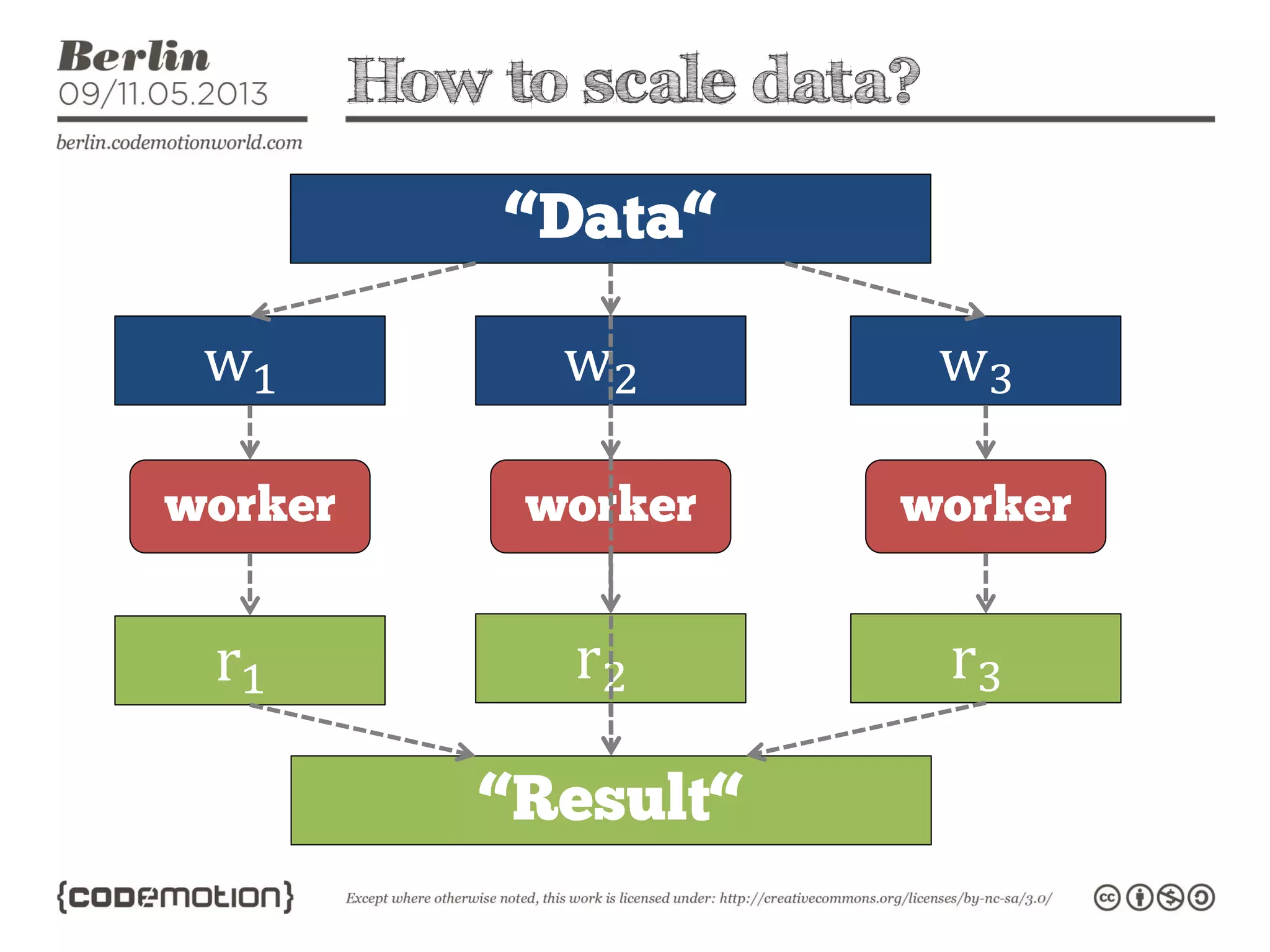




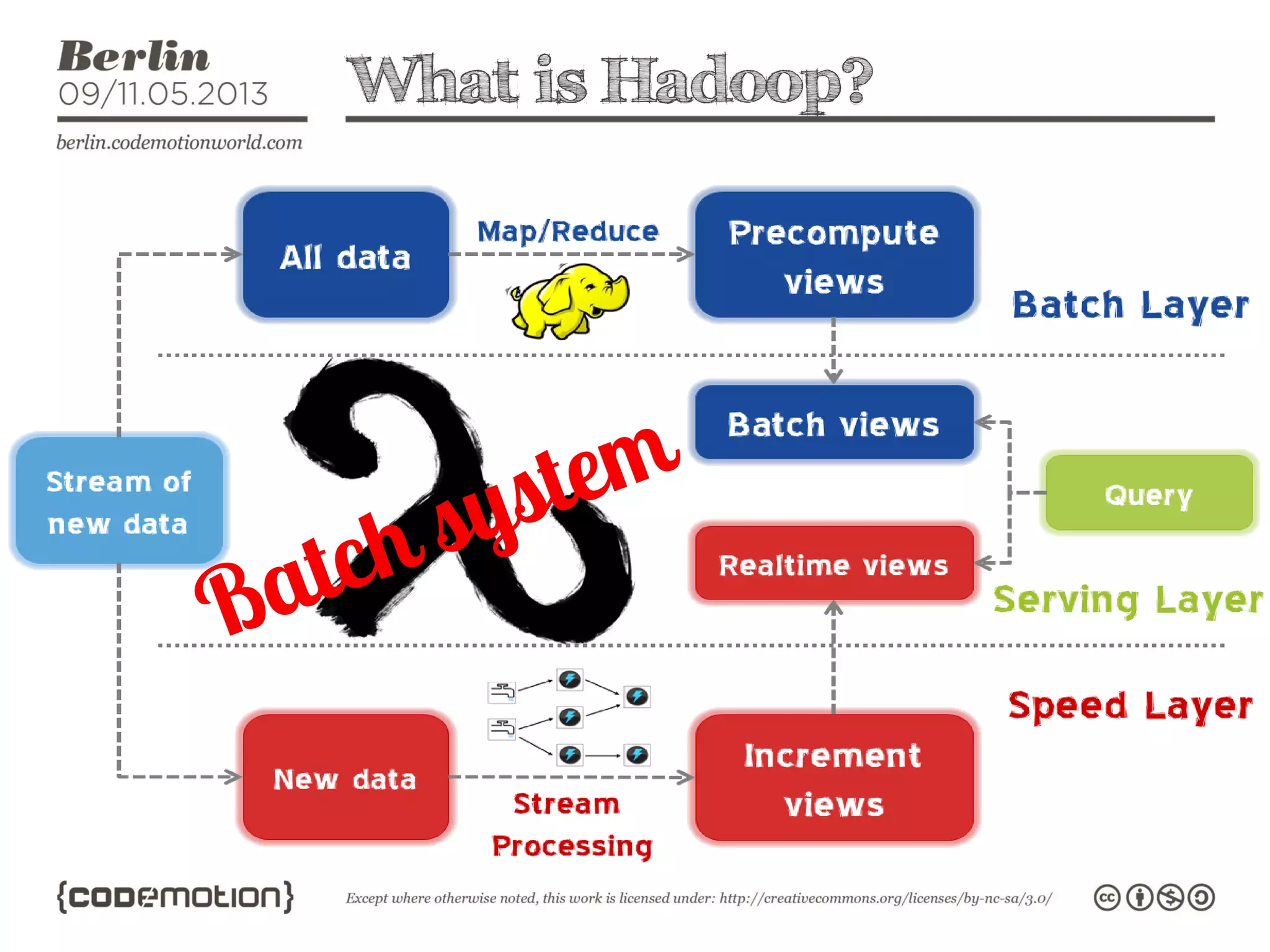






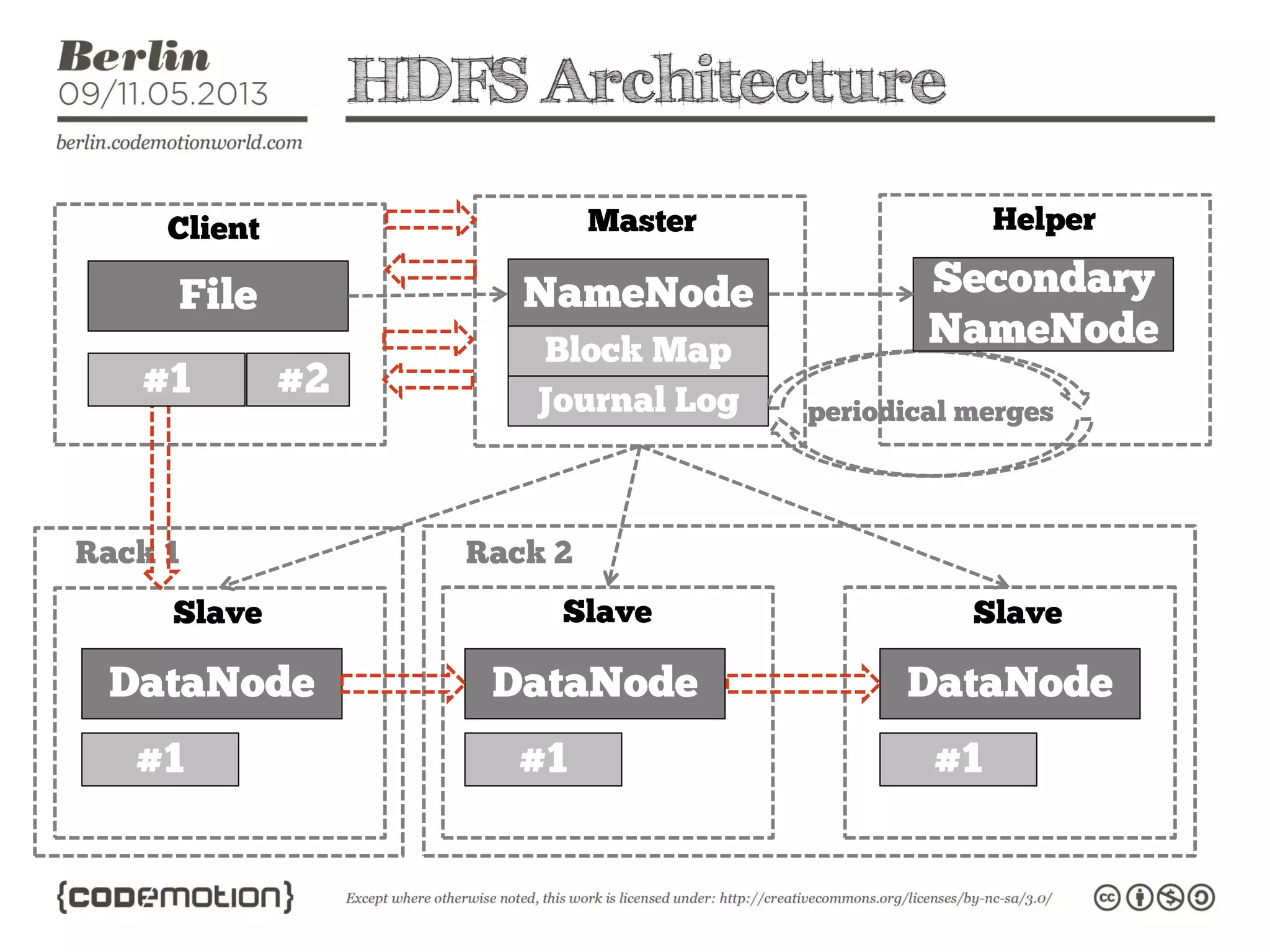




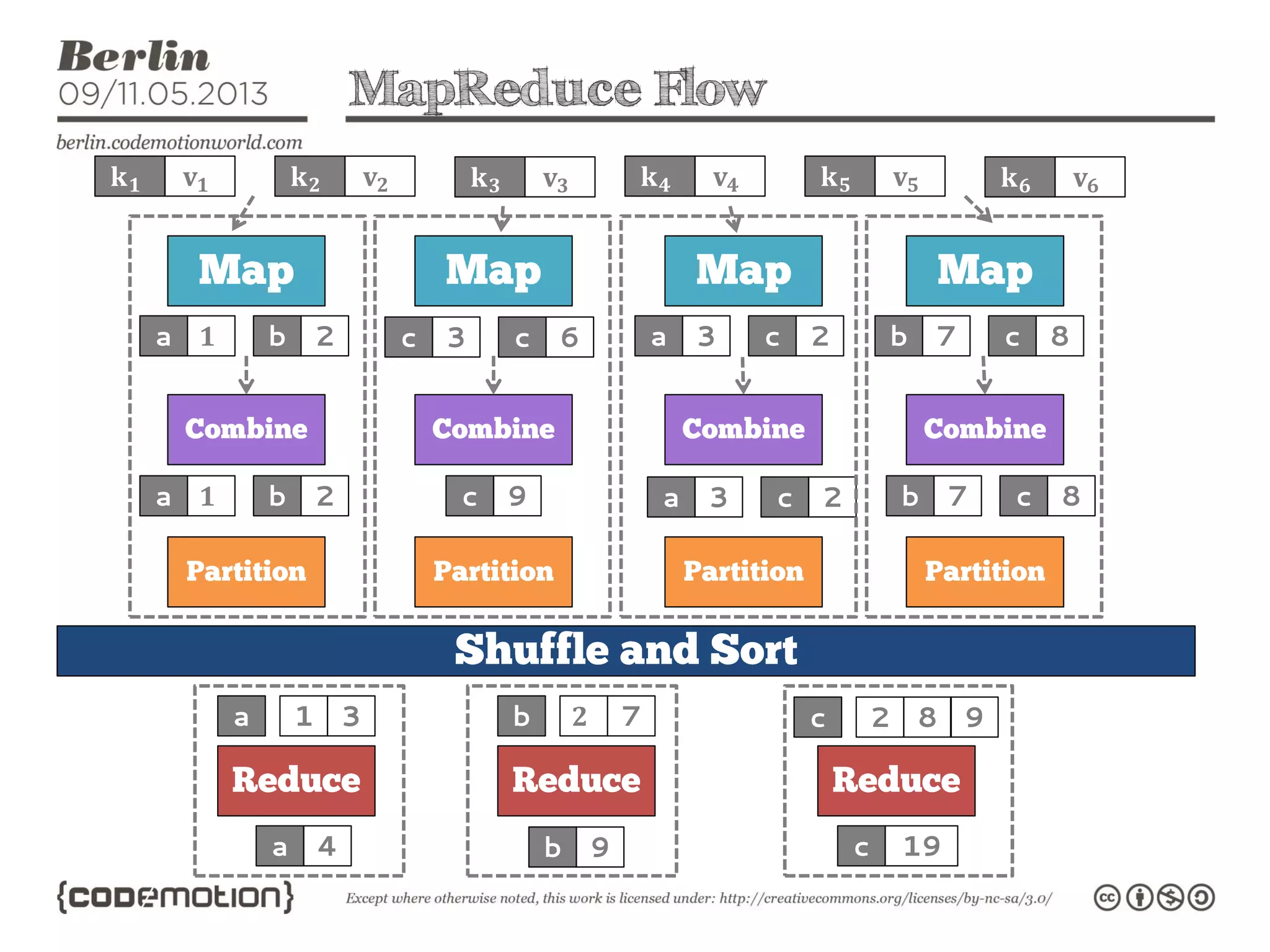

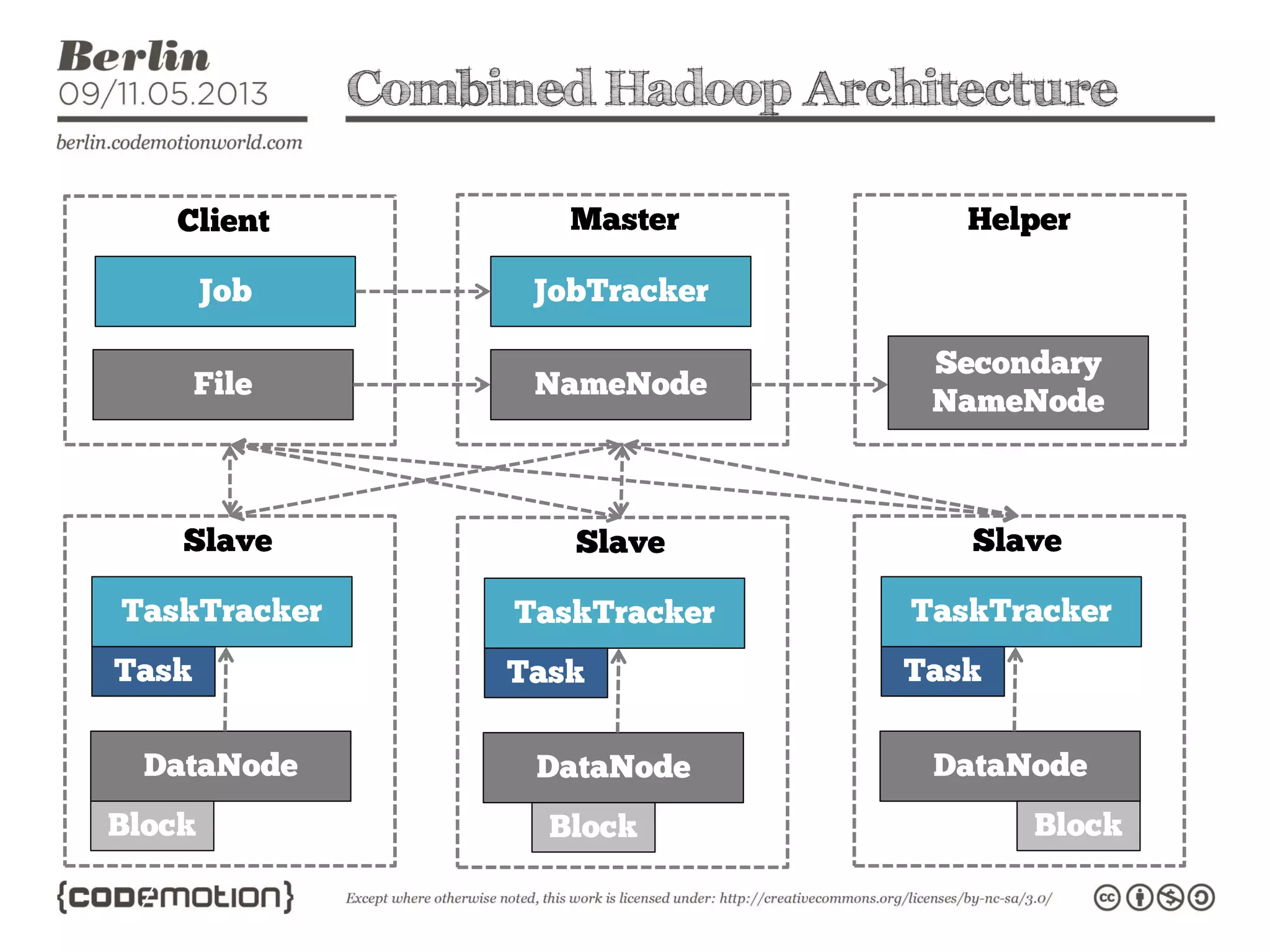





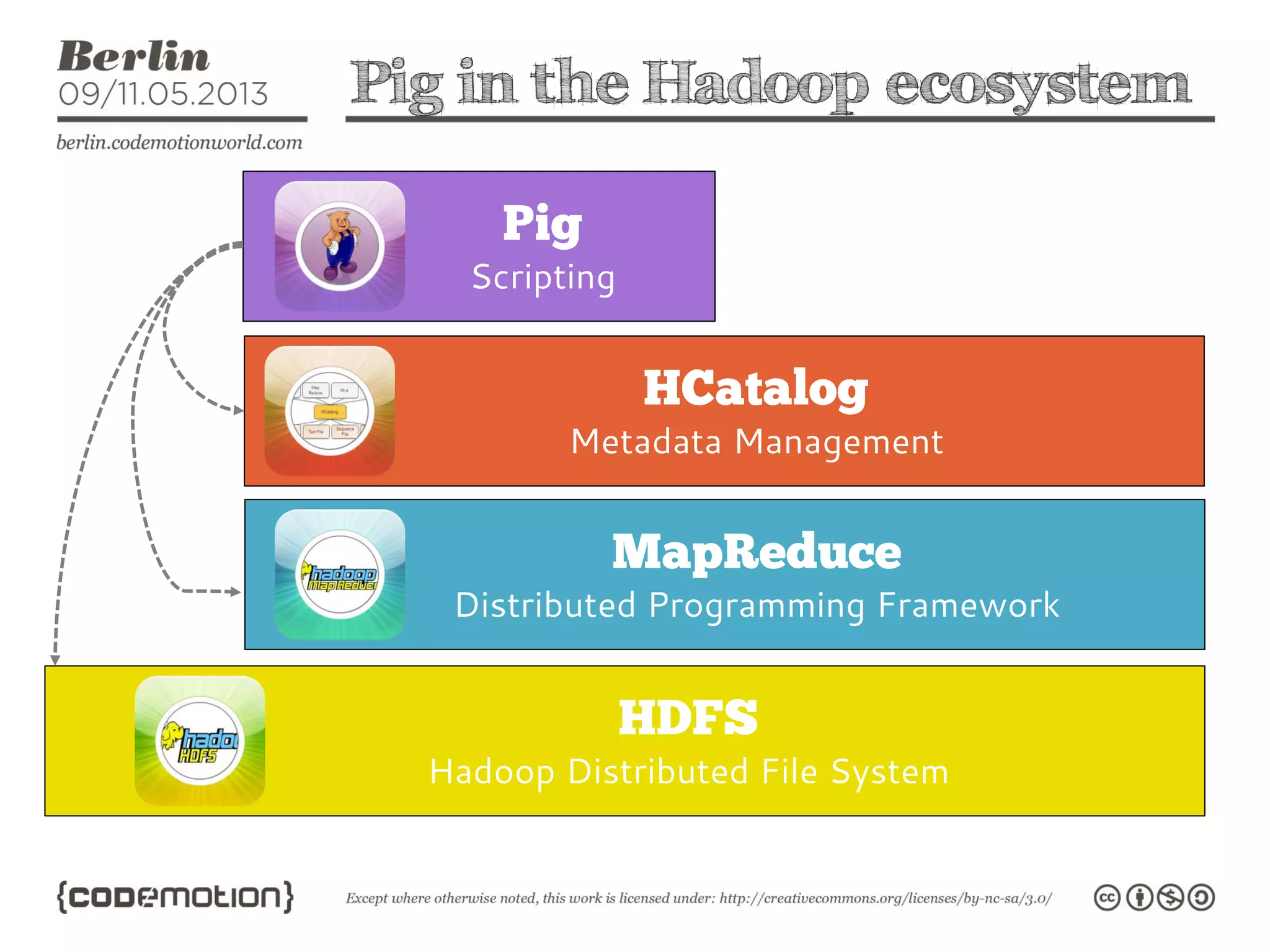

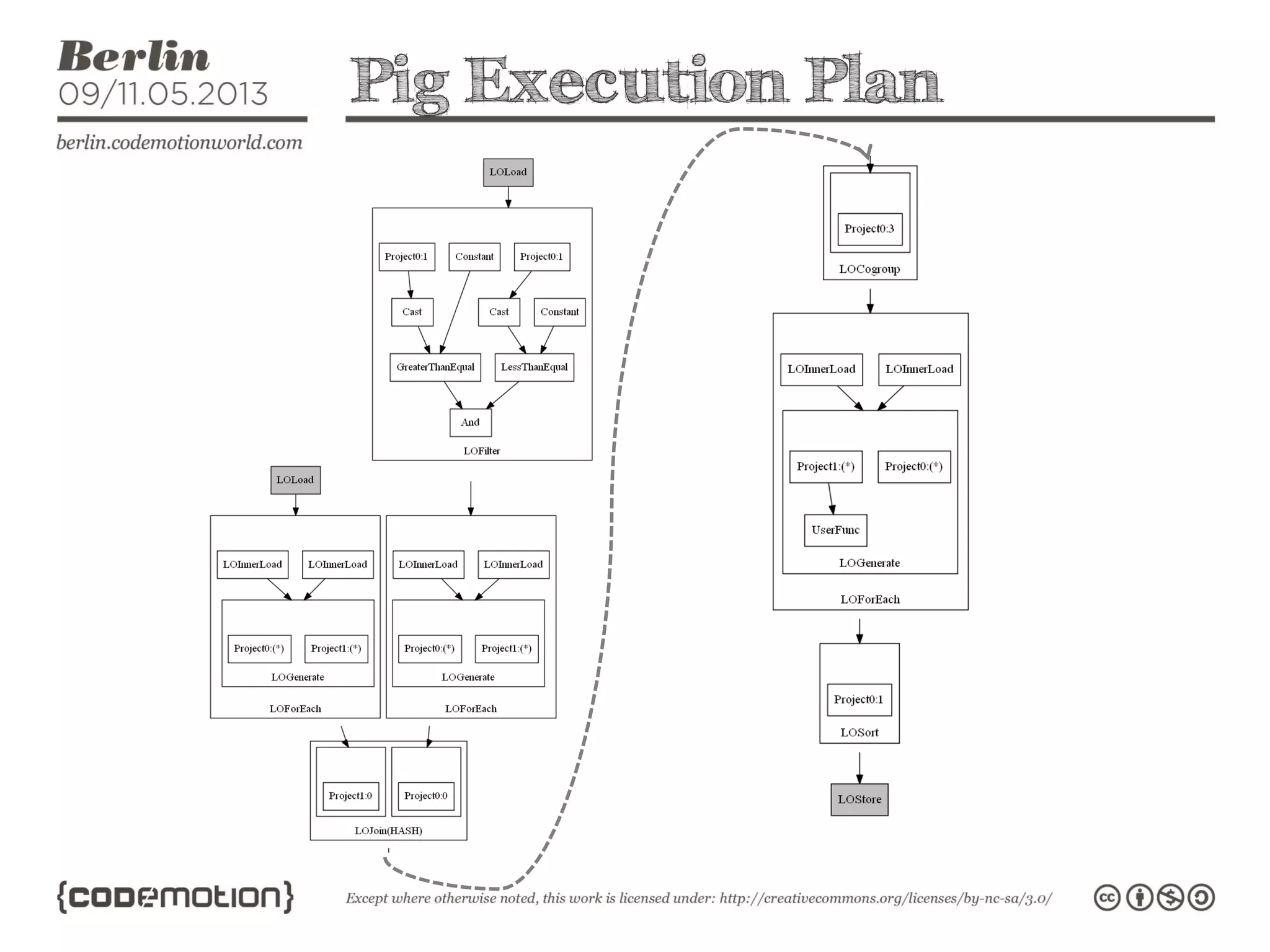




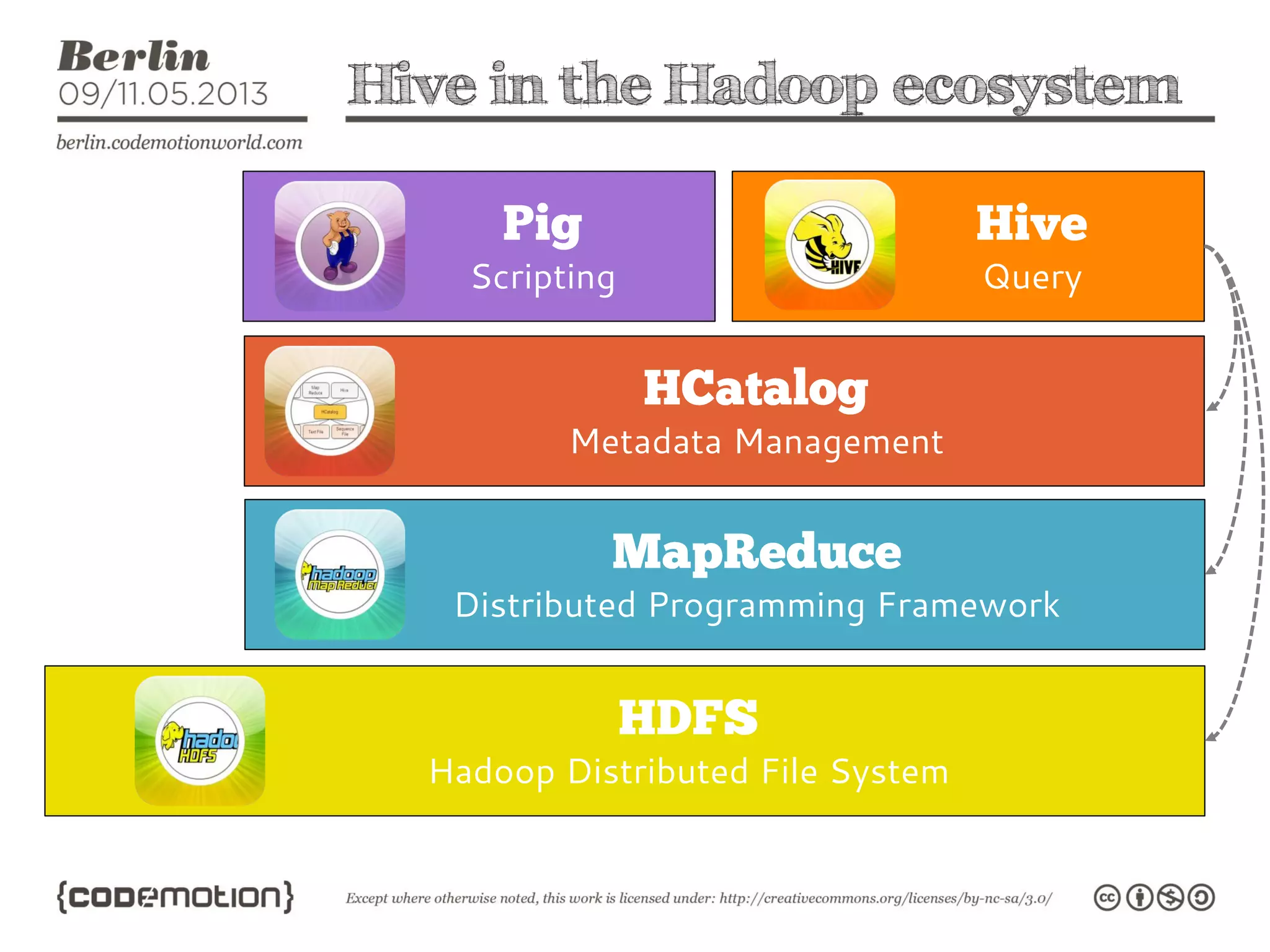
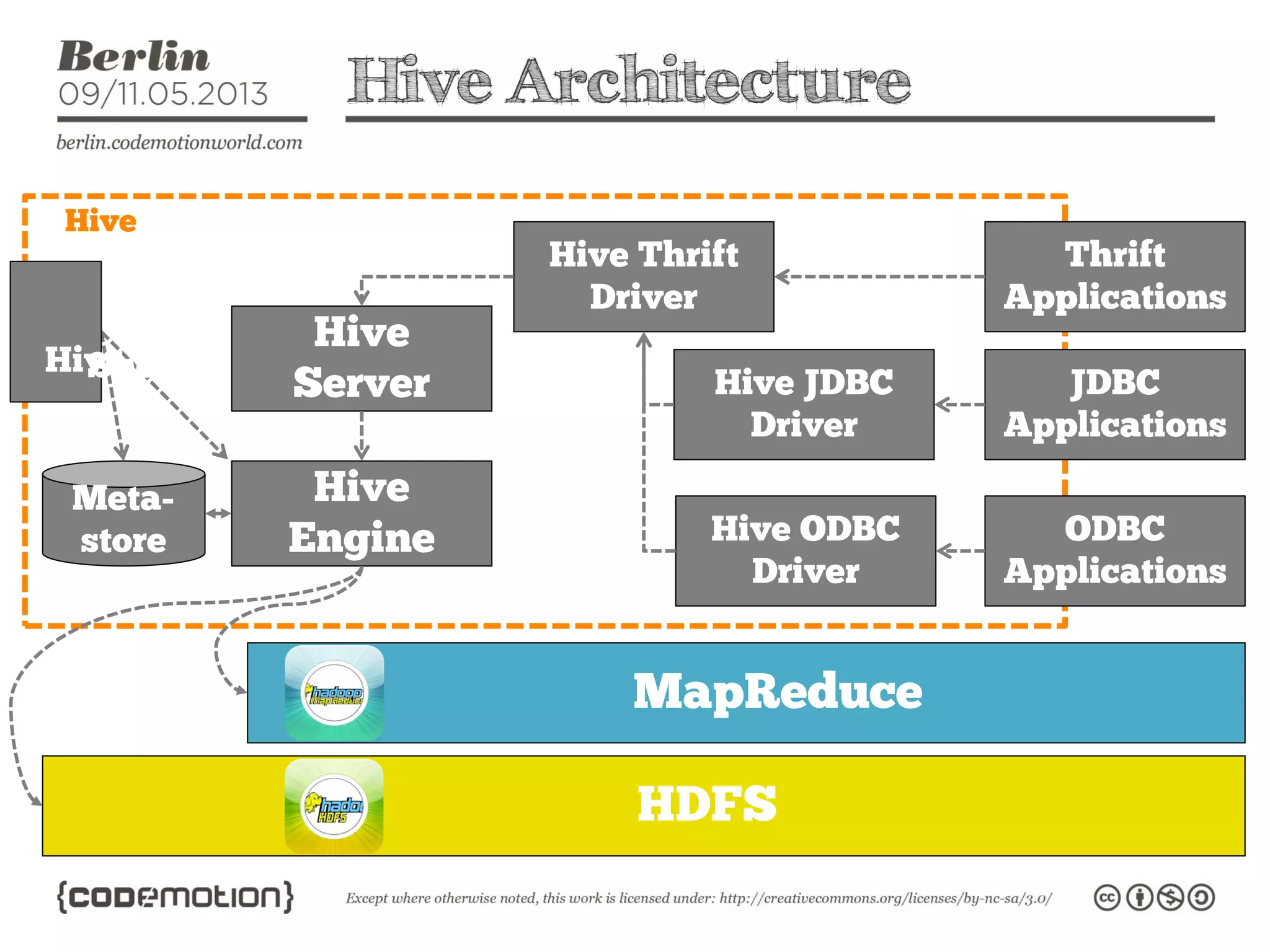


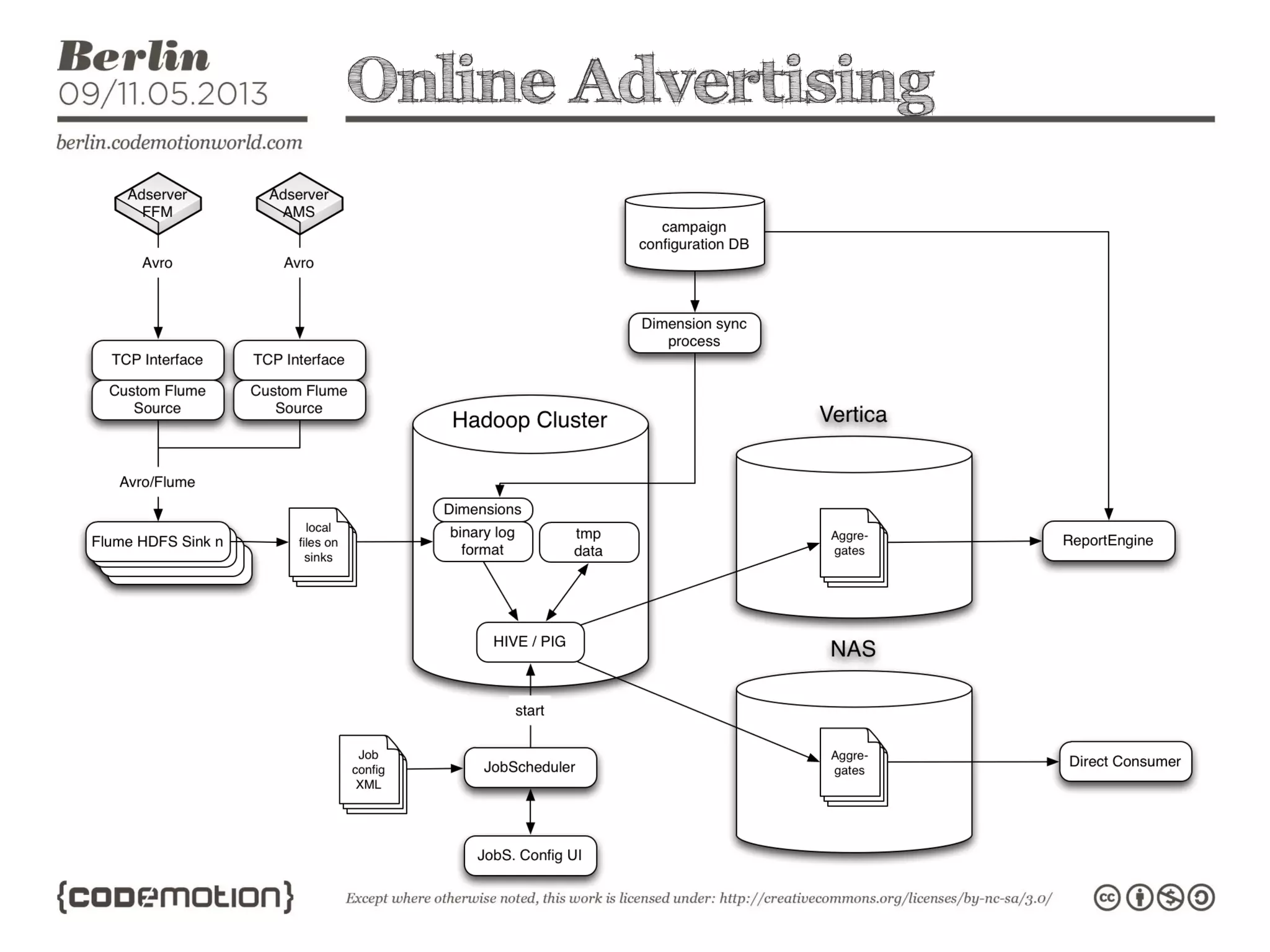




This document provides an introduction to the Hadoop ecosystem. It discusses data storage with HDFS and data processing with MapReduce. It also describes higher-level tools like Pig and Hive that provide interfaces for data analysis. Pig uses a language called Pig Latin to analyze data in Hadoop, while Hive provides an SQL-like interface. These tools sit on top of core Hadoop components to simplify big data workflows.

























































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)











