

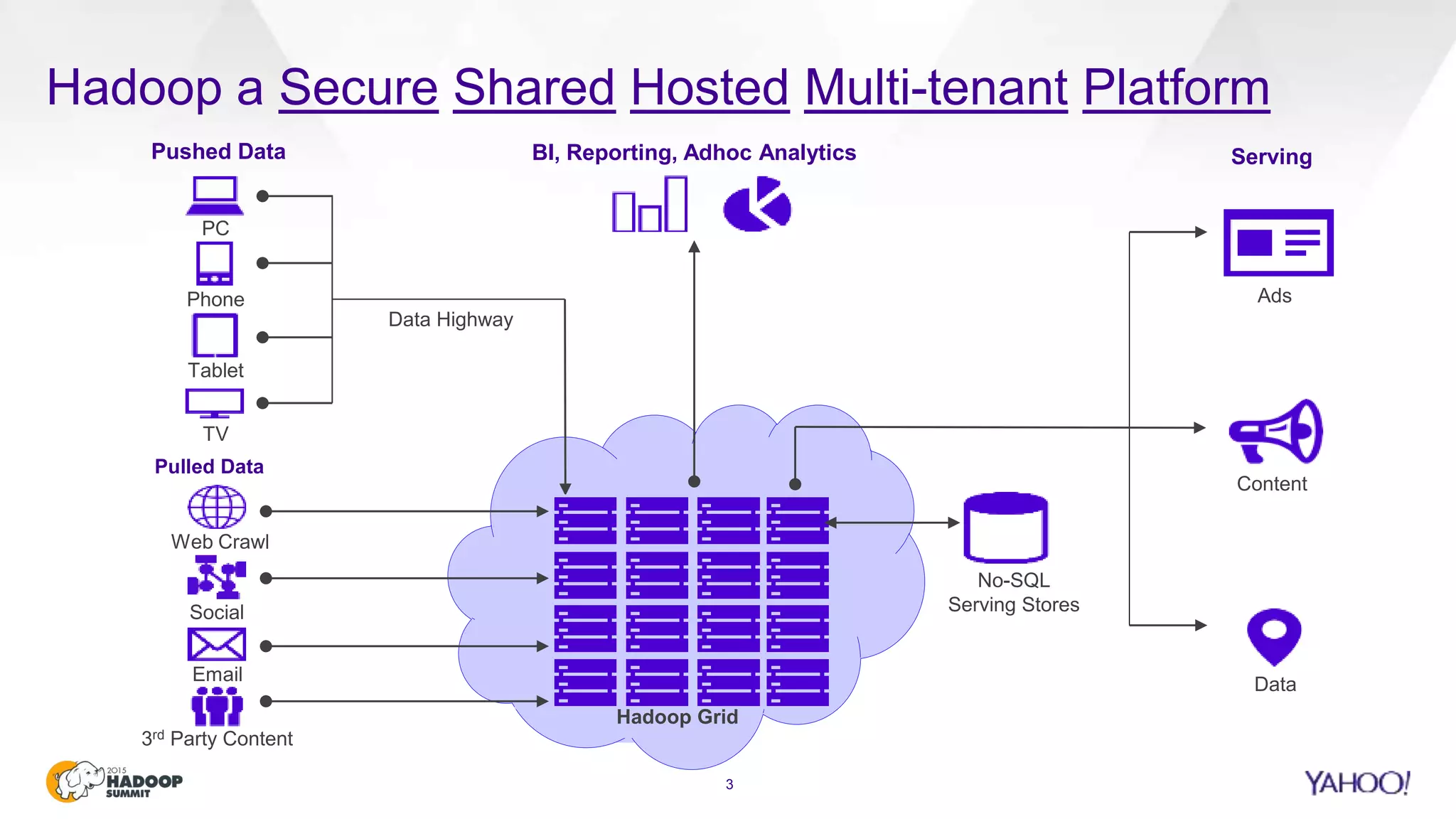
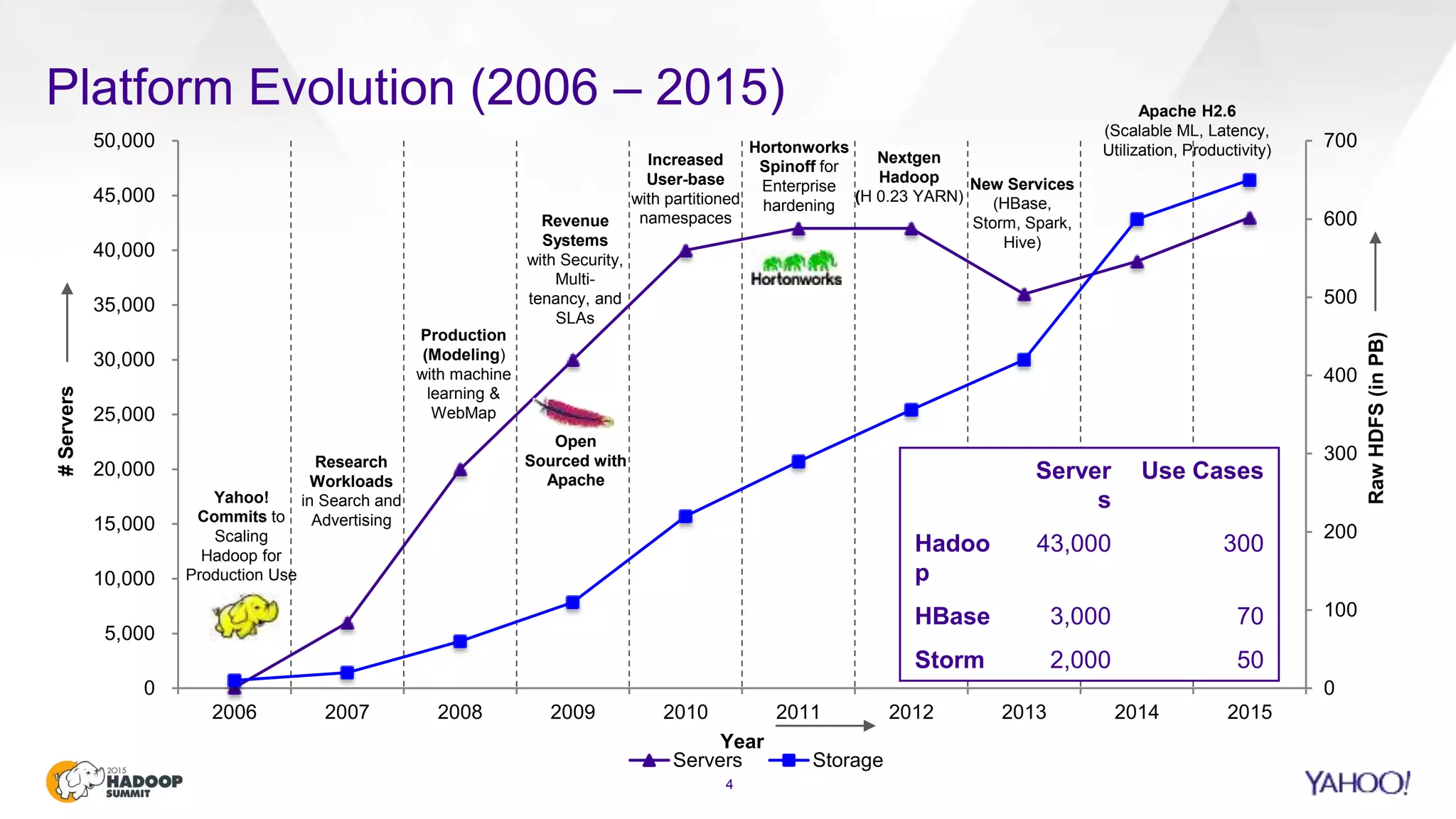

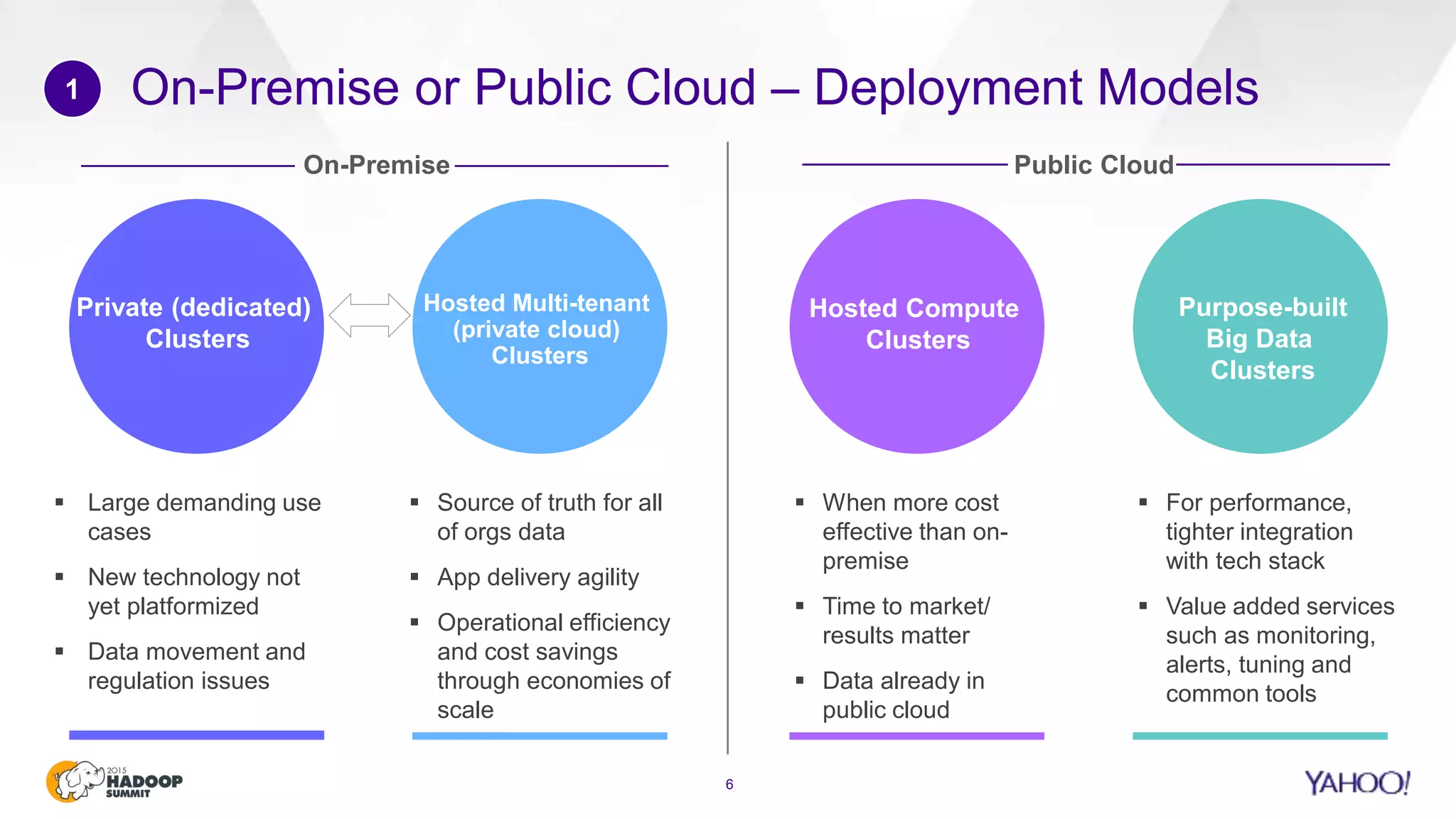
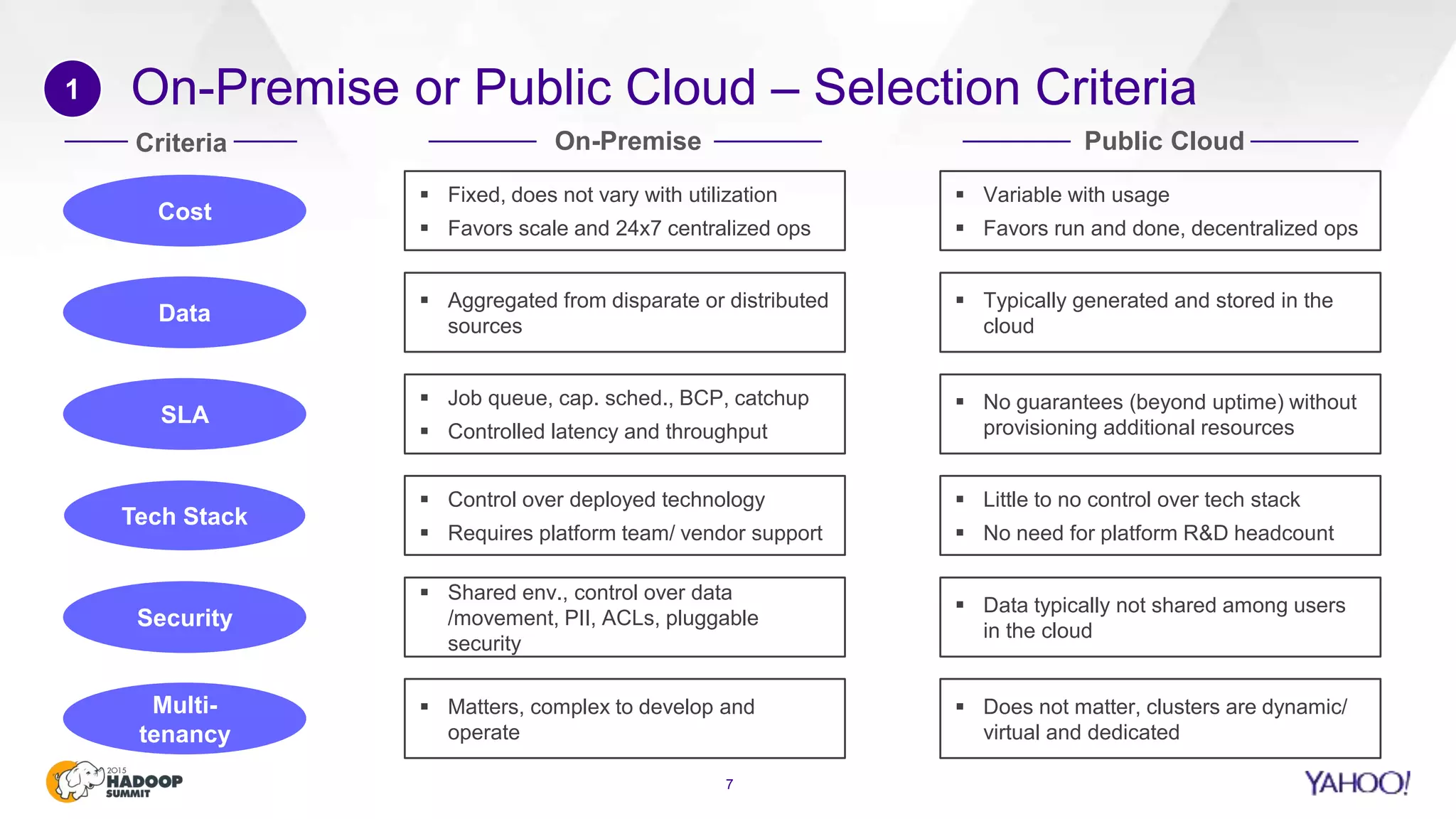
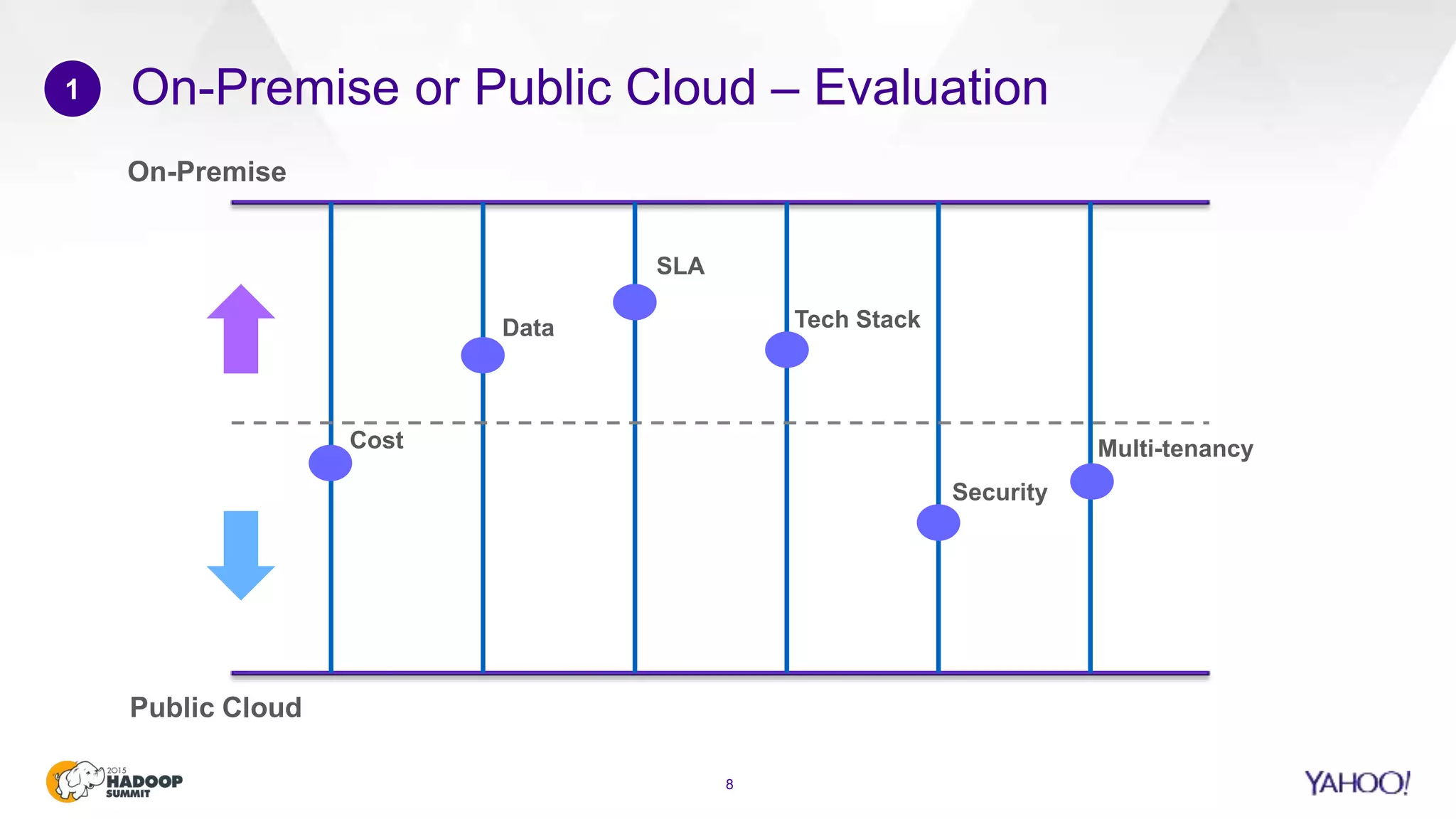
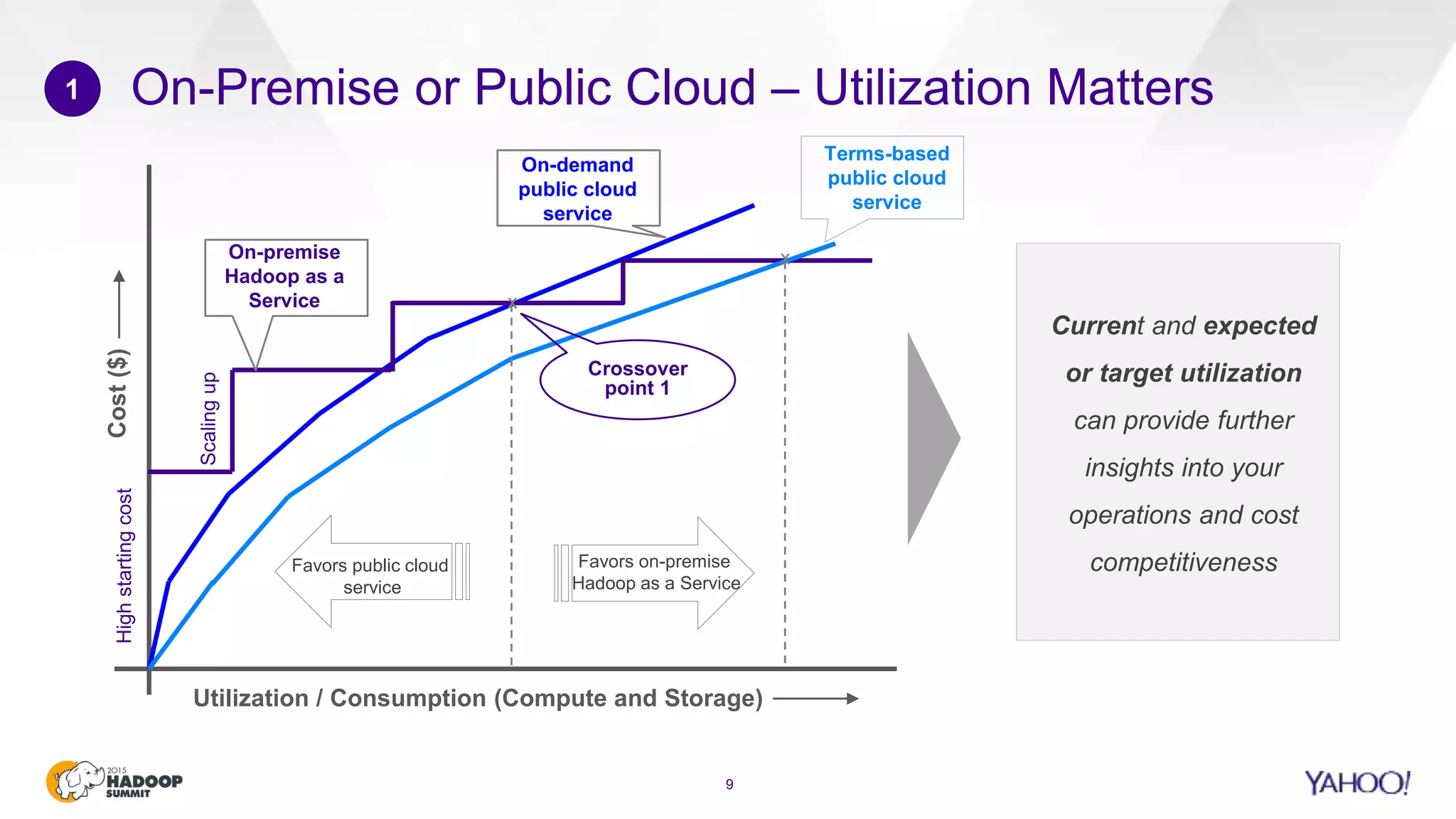

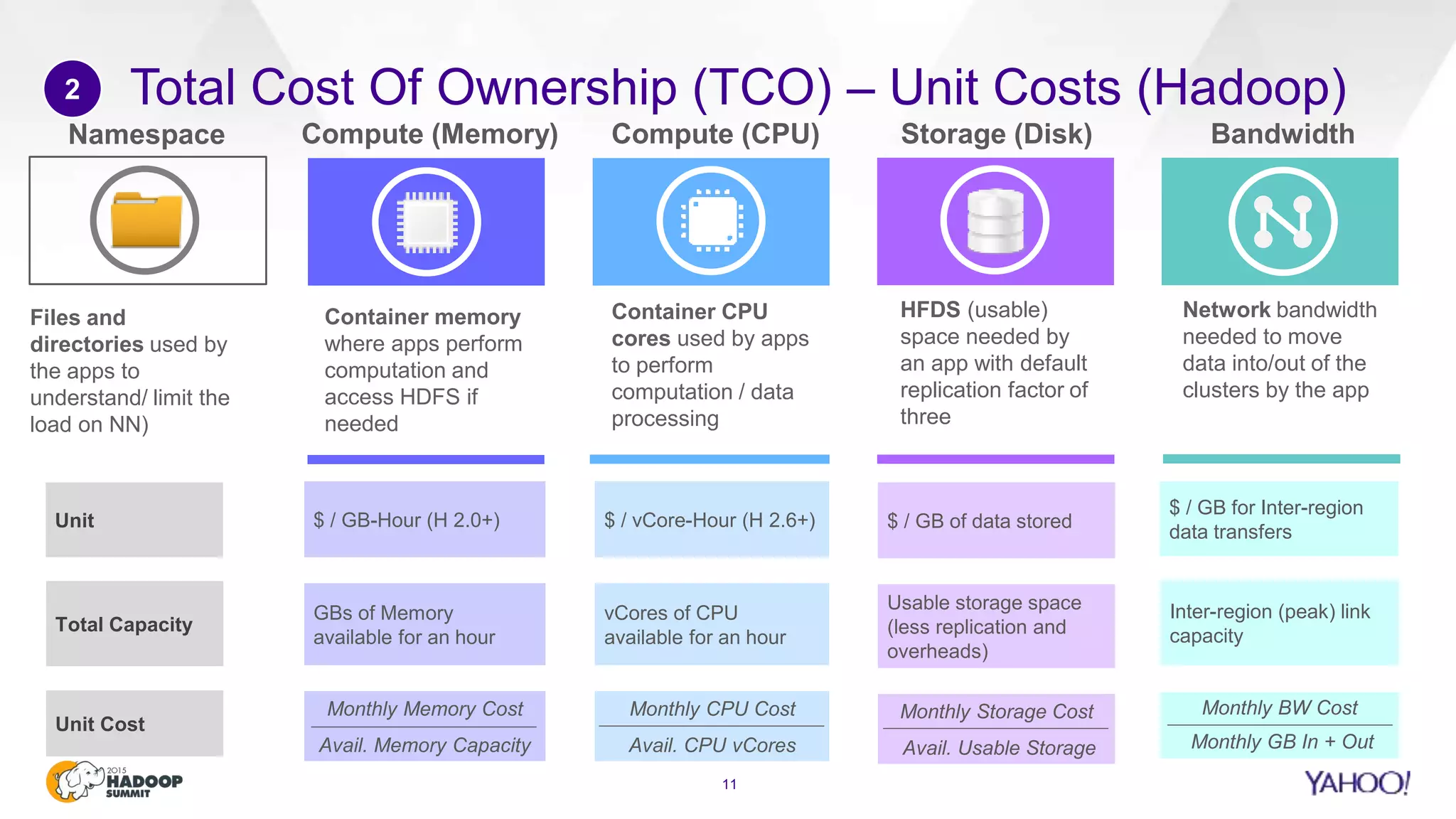
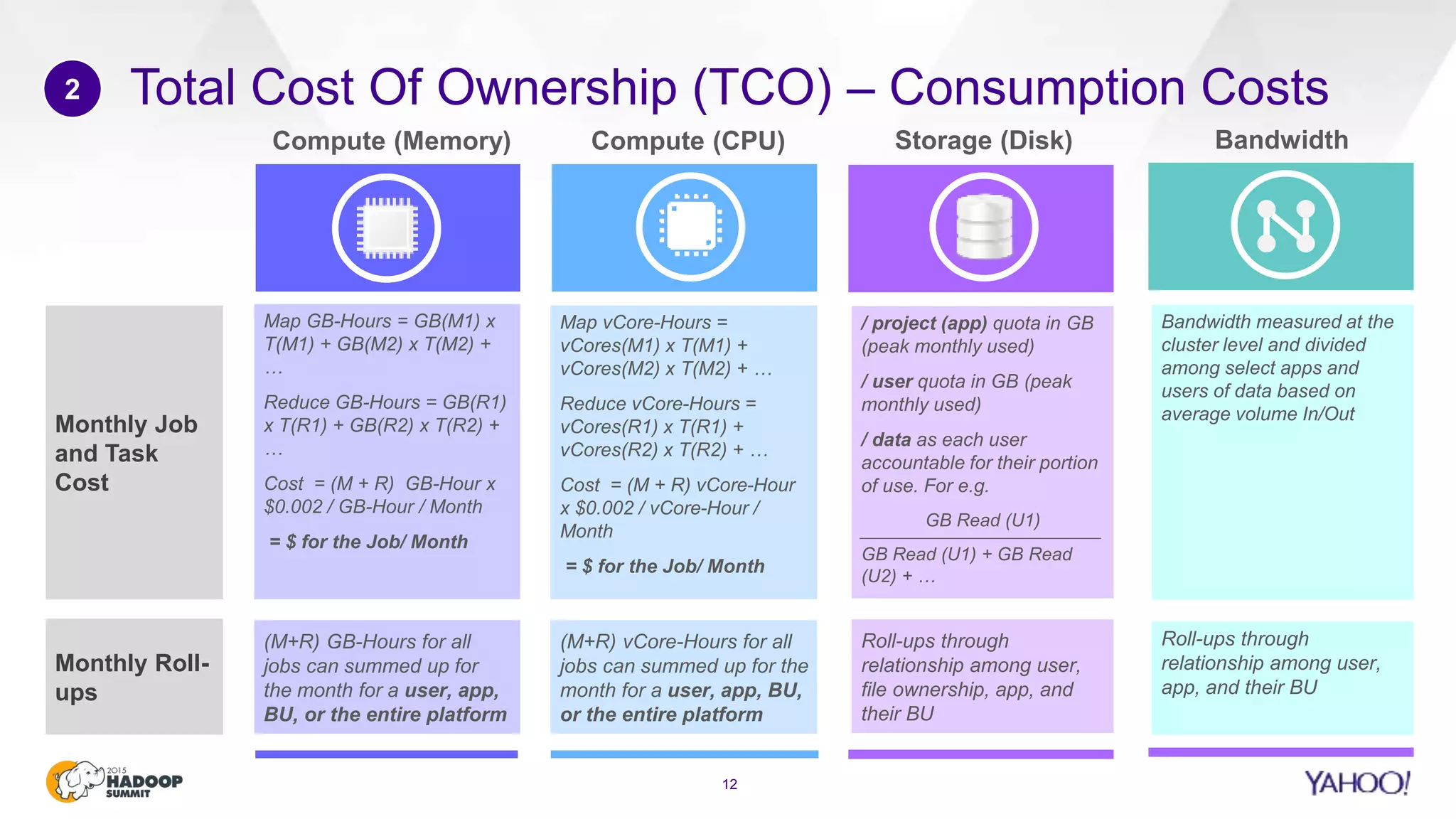
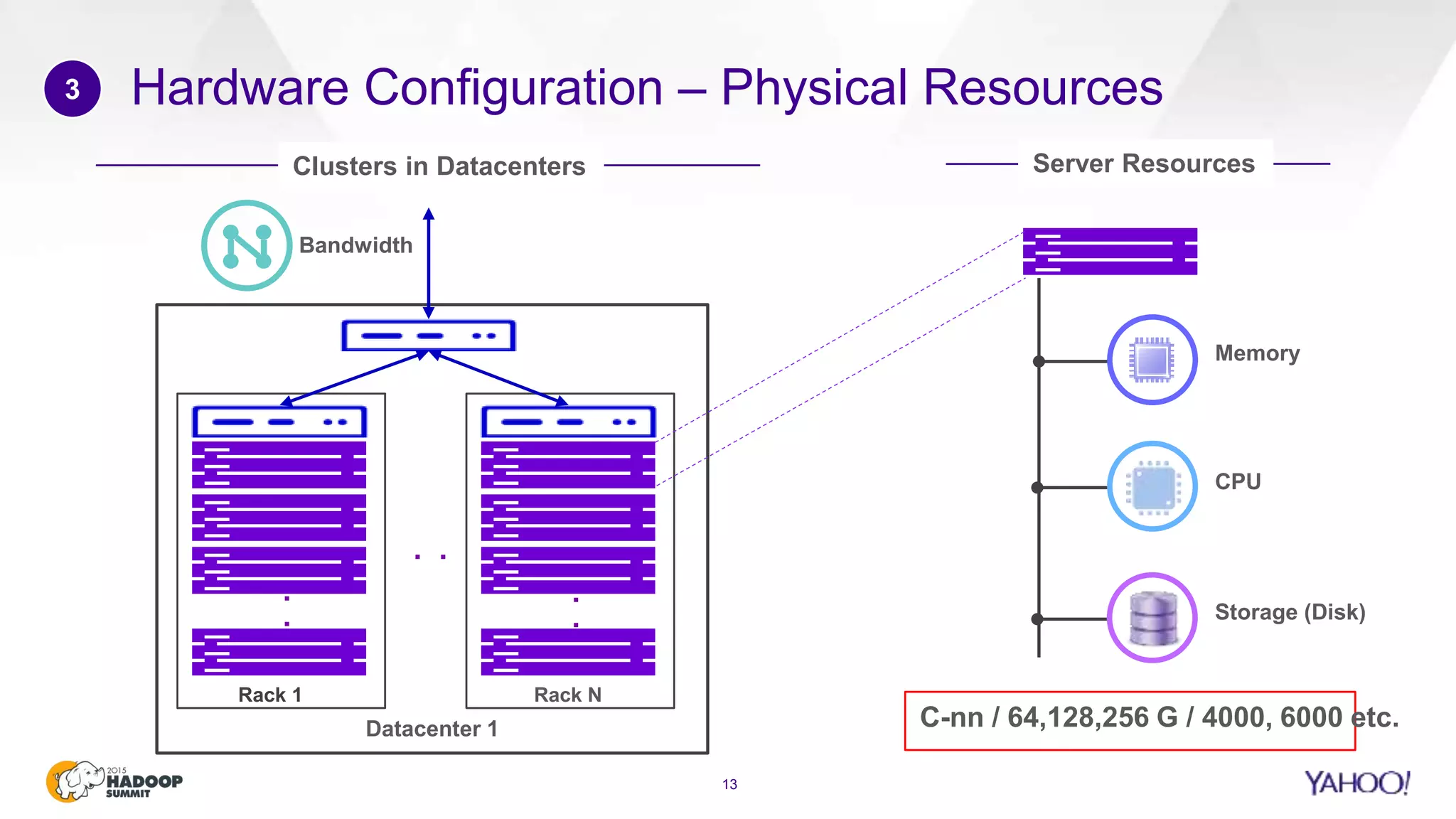
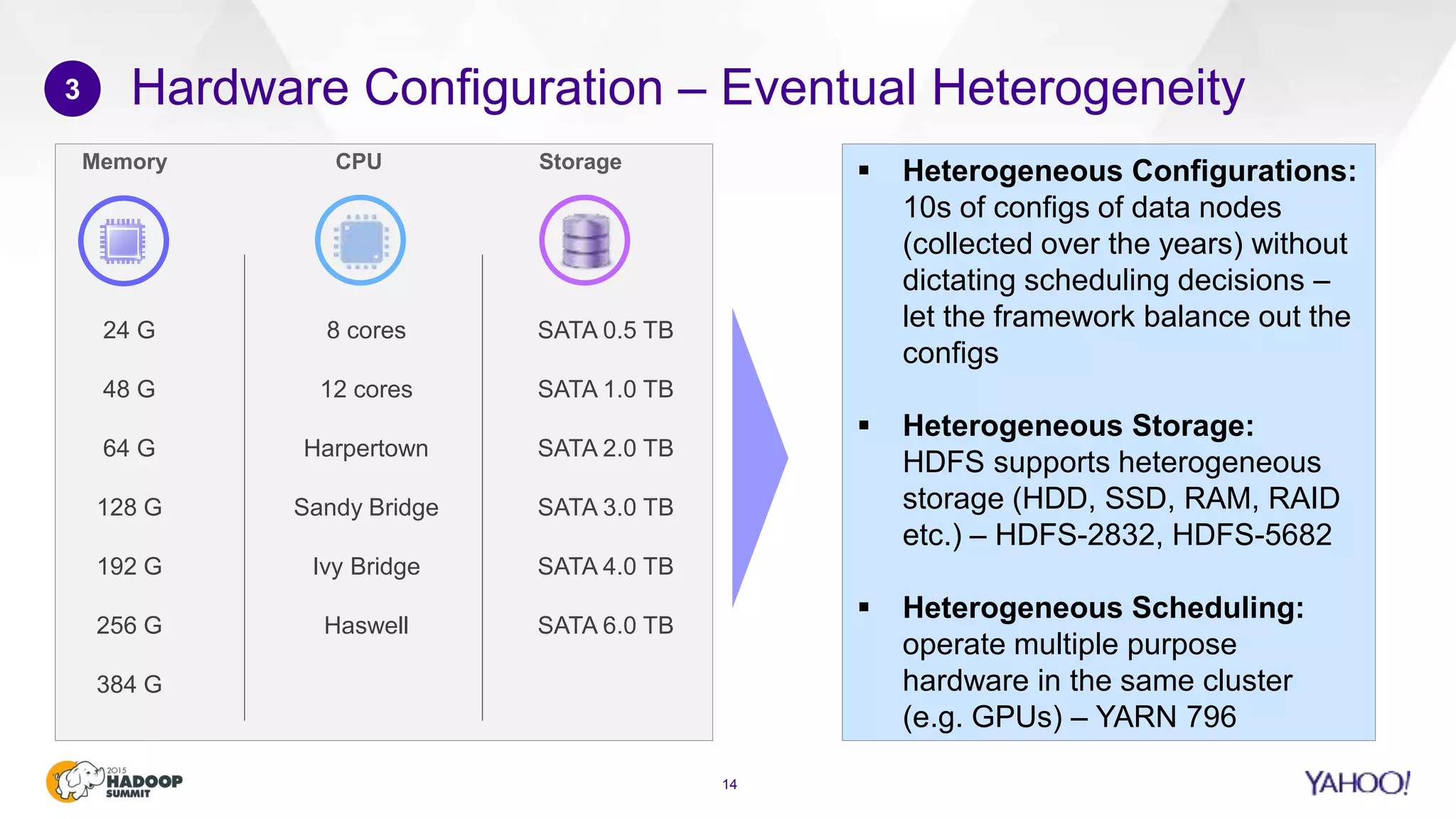
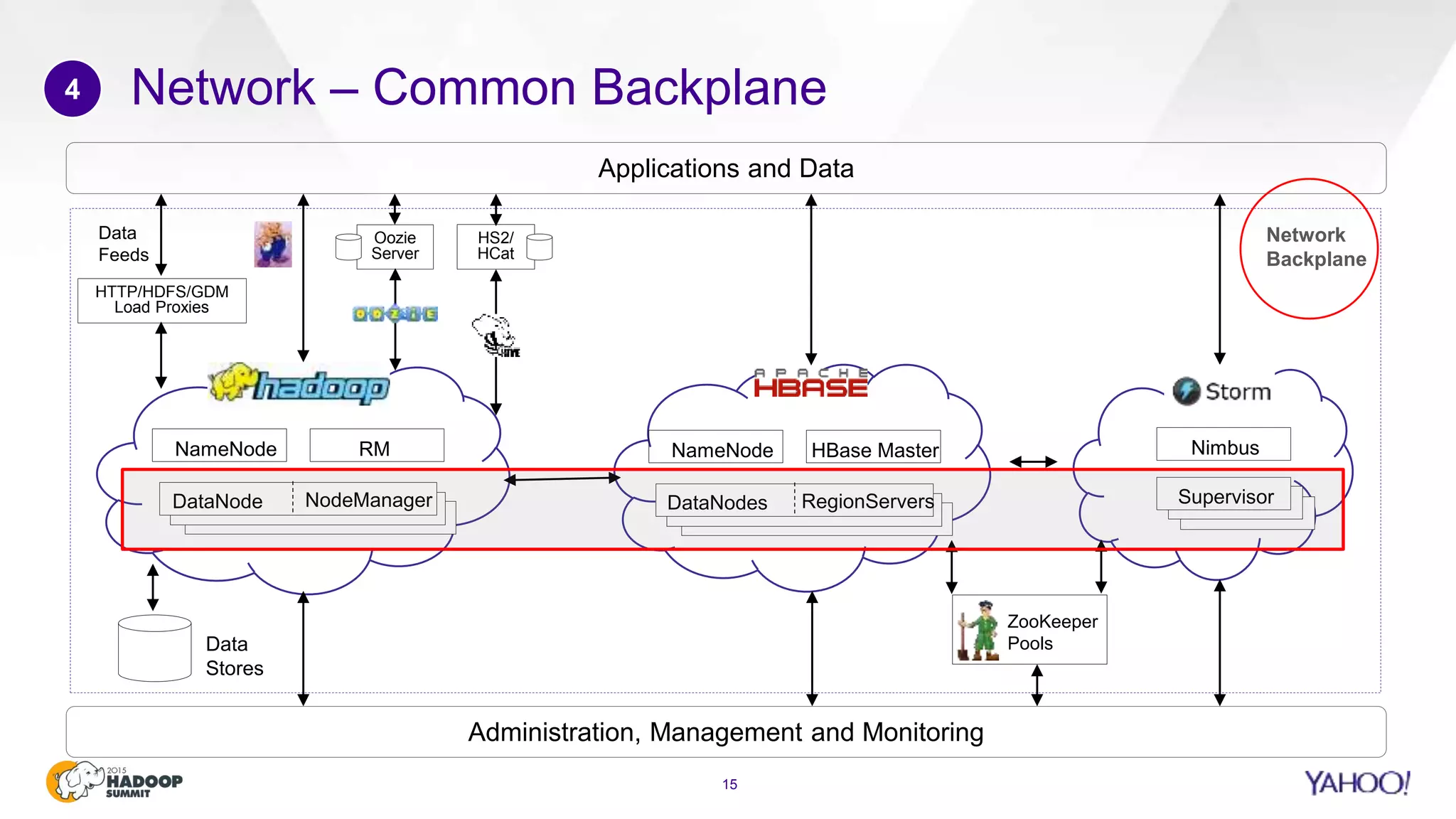
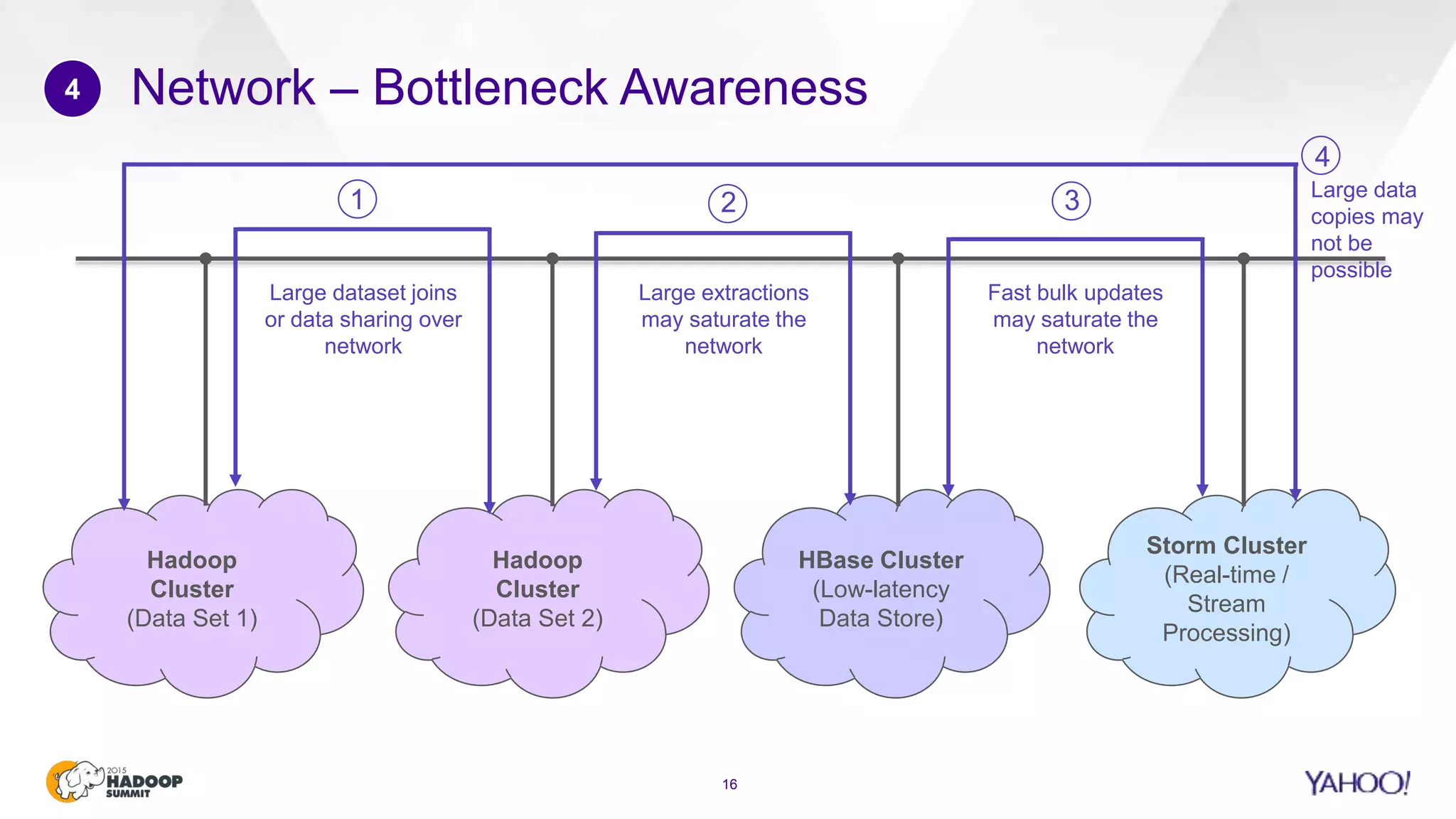
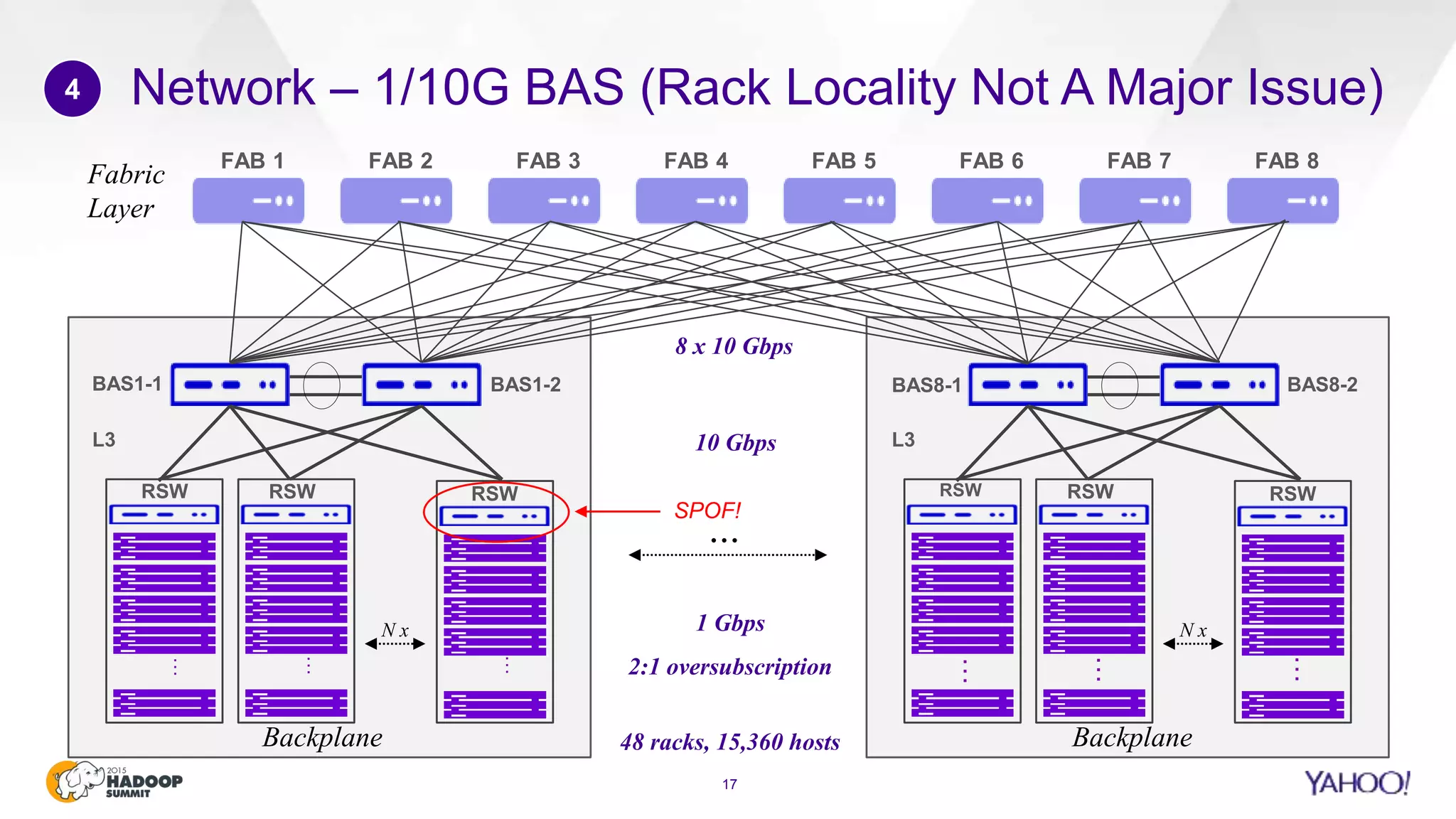
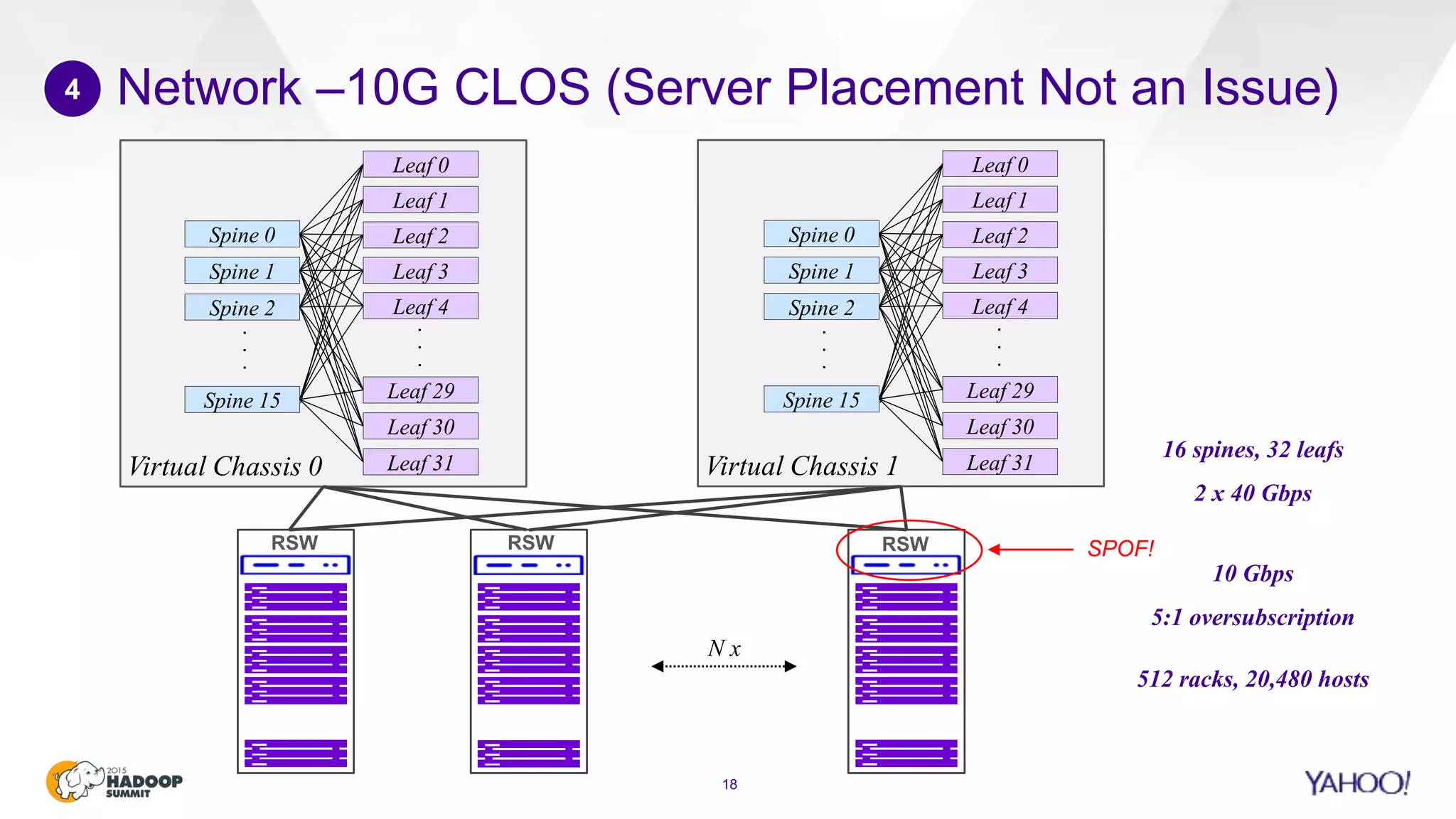
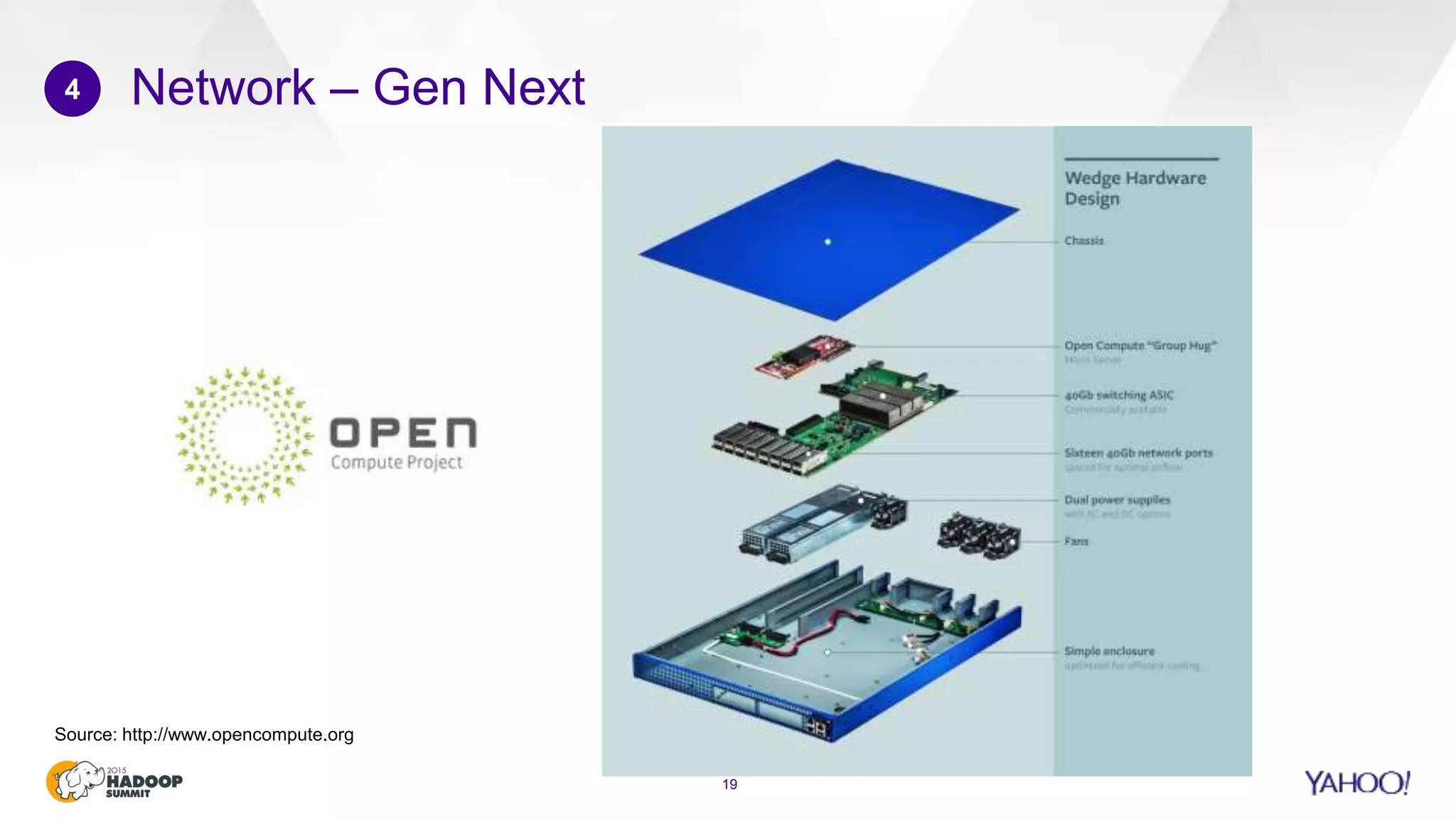
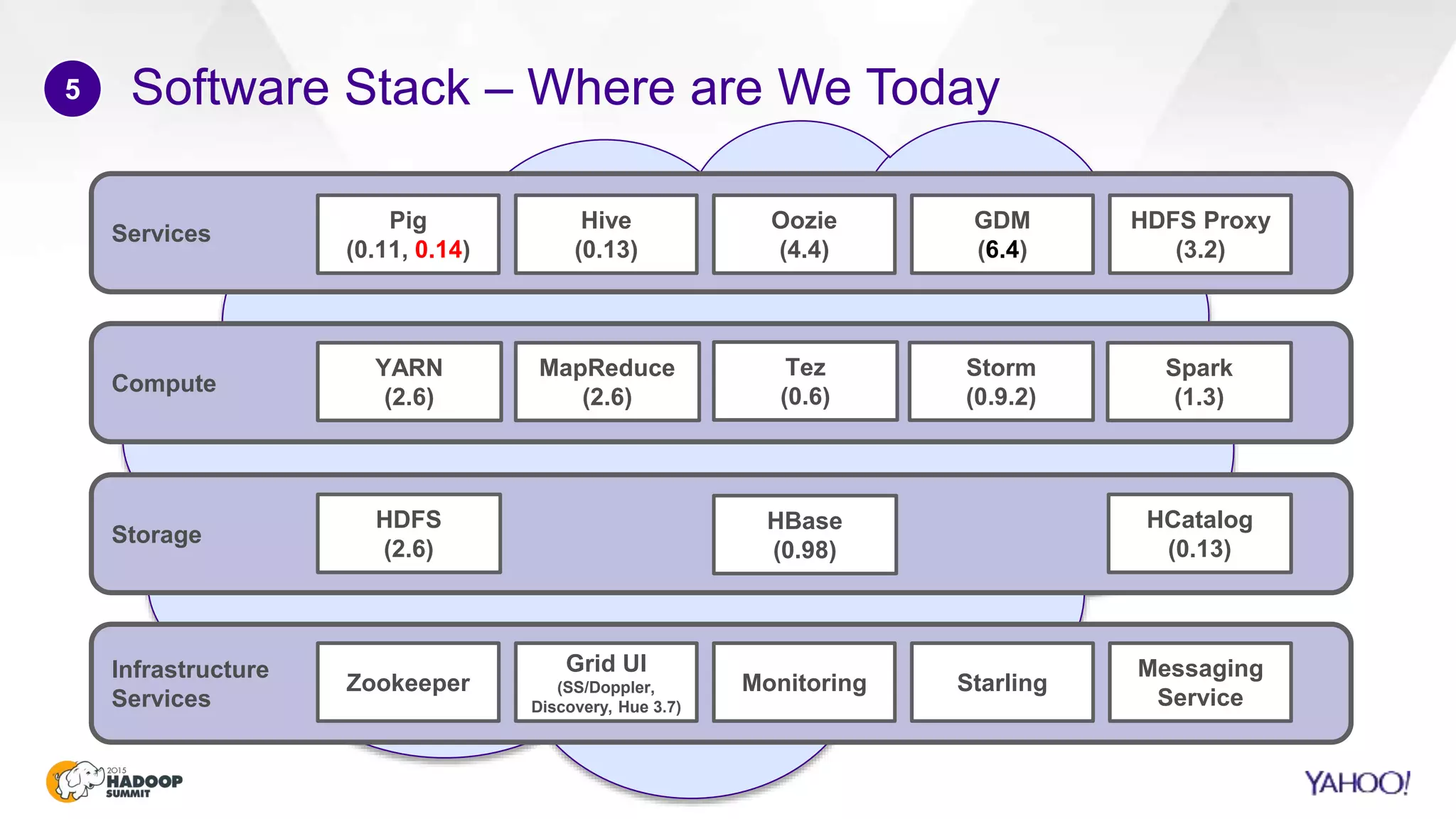
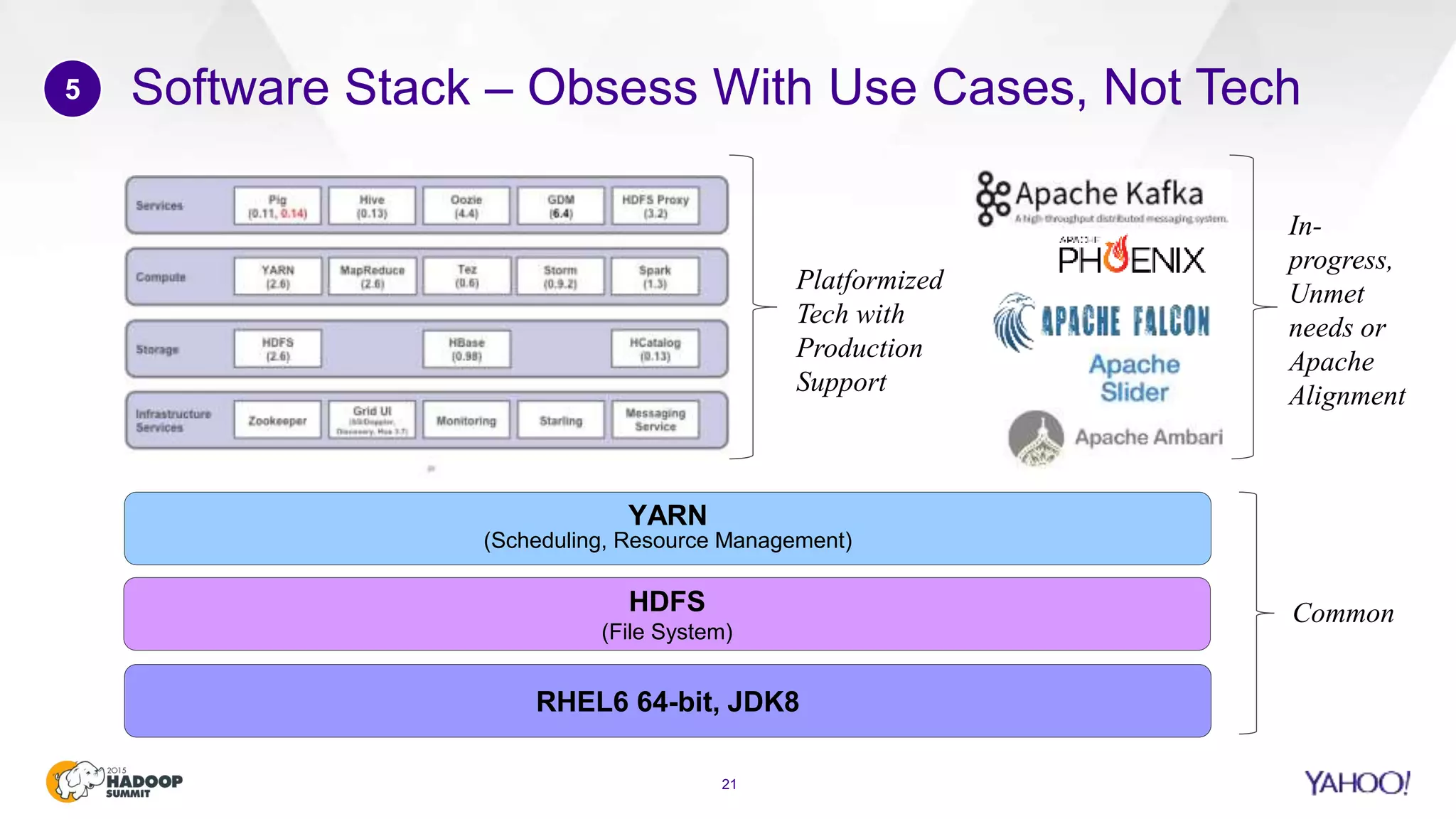
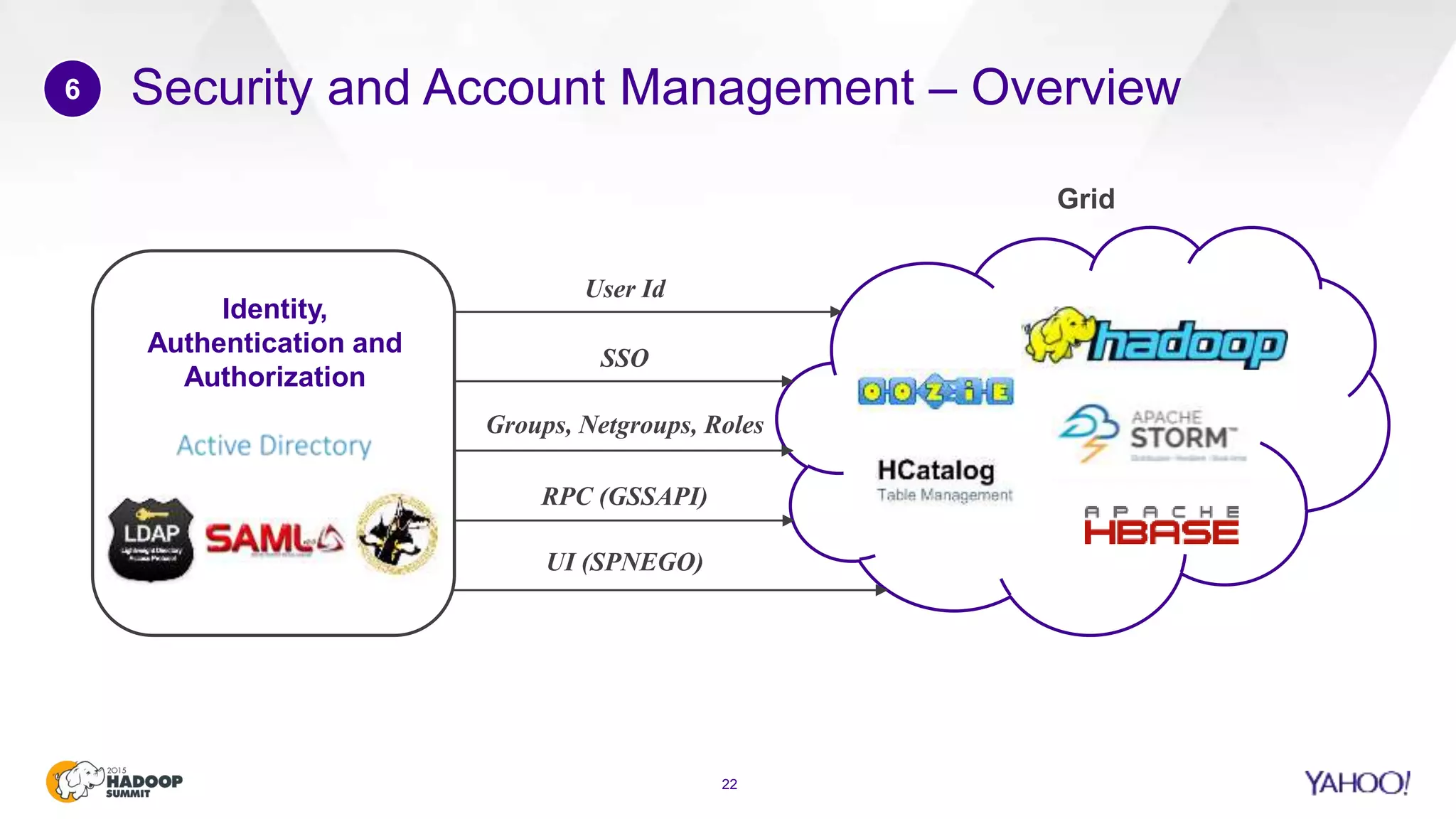
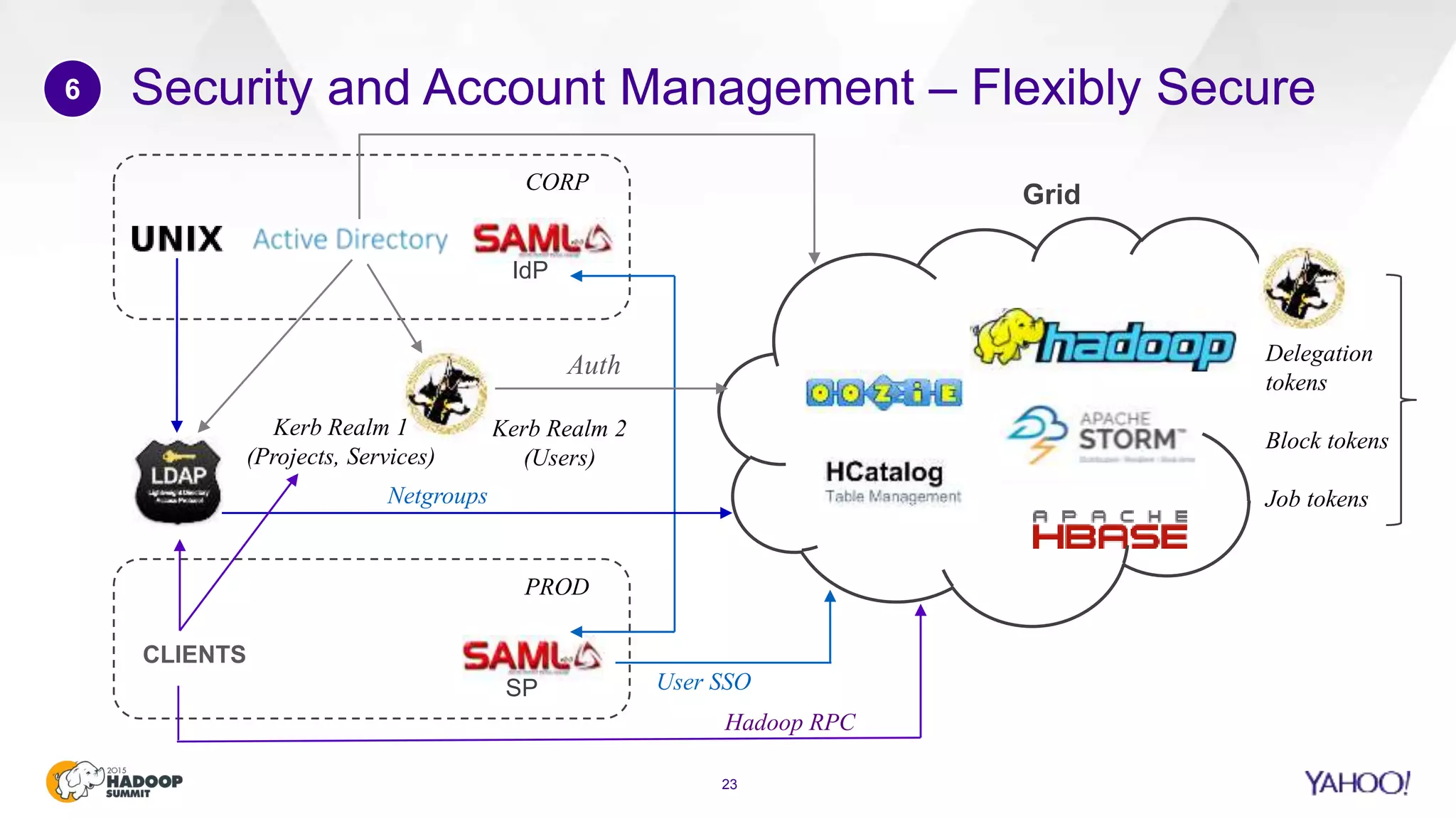
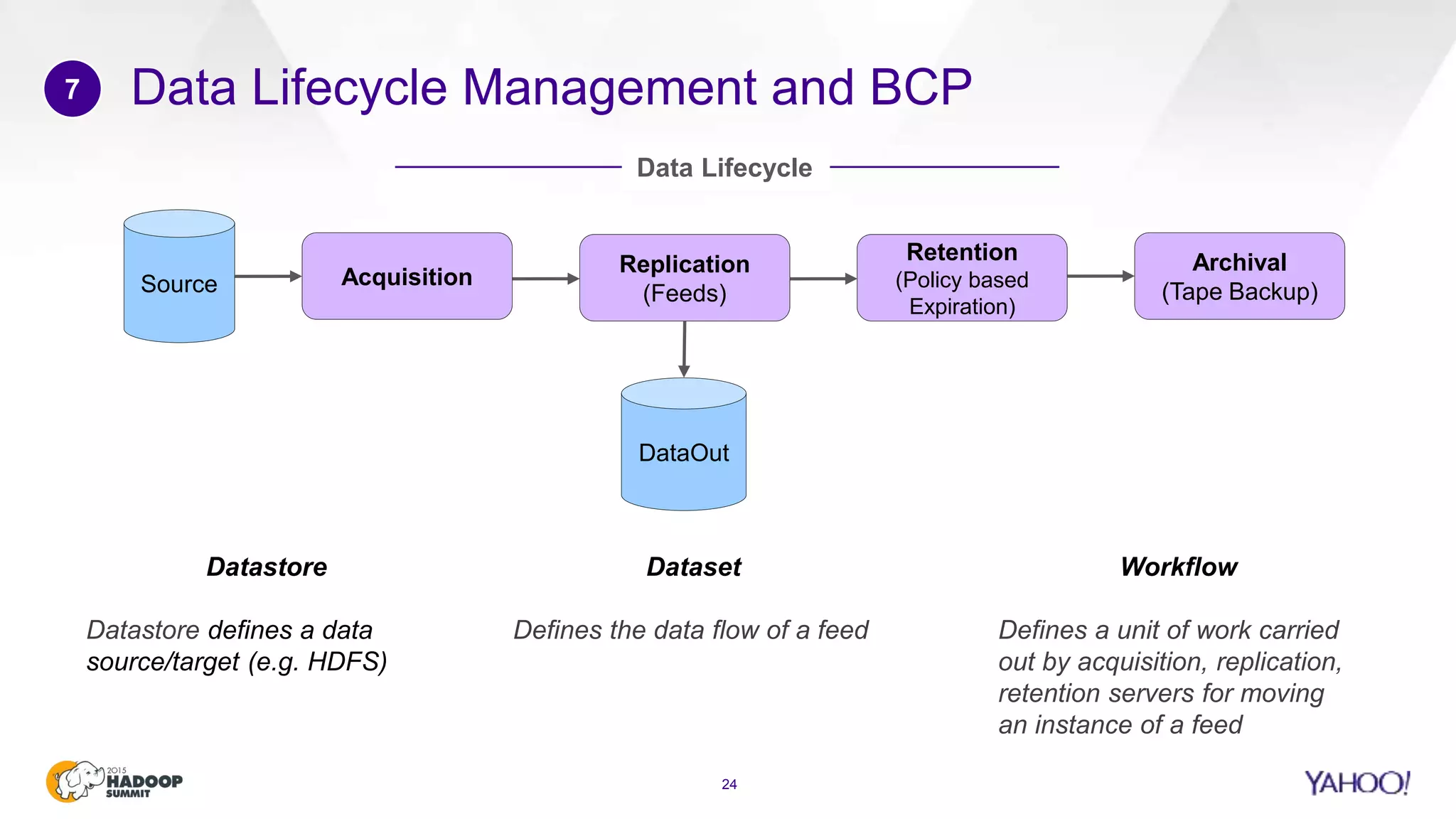
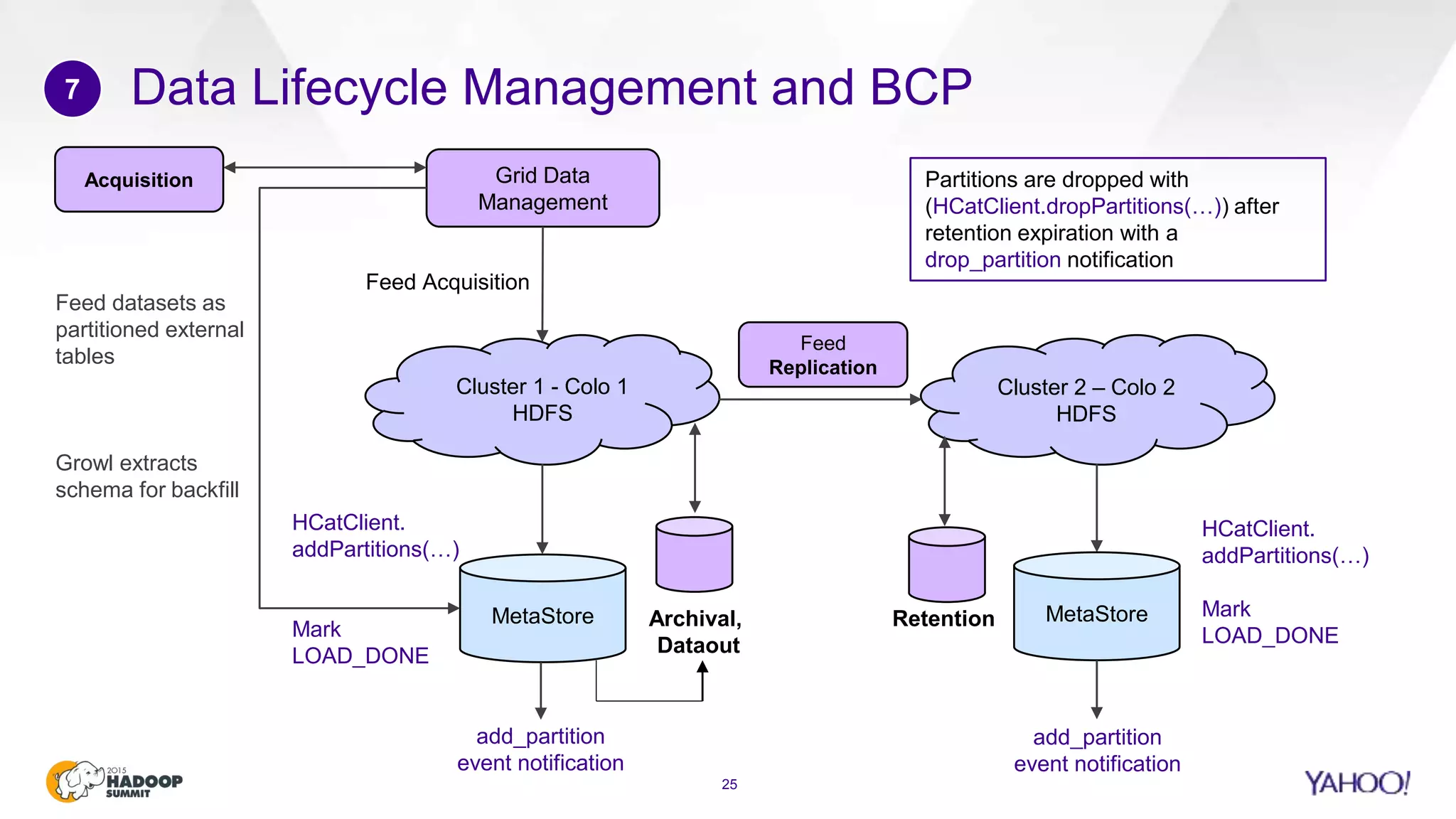
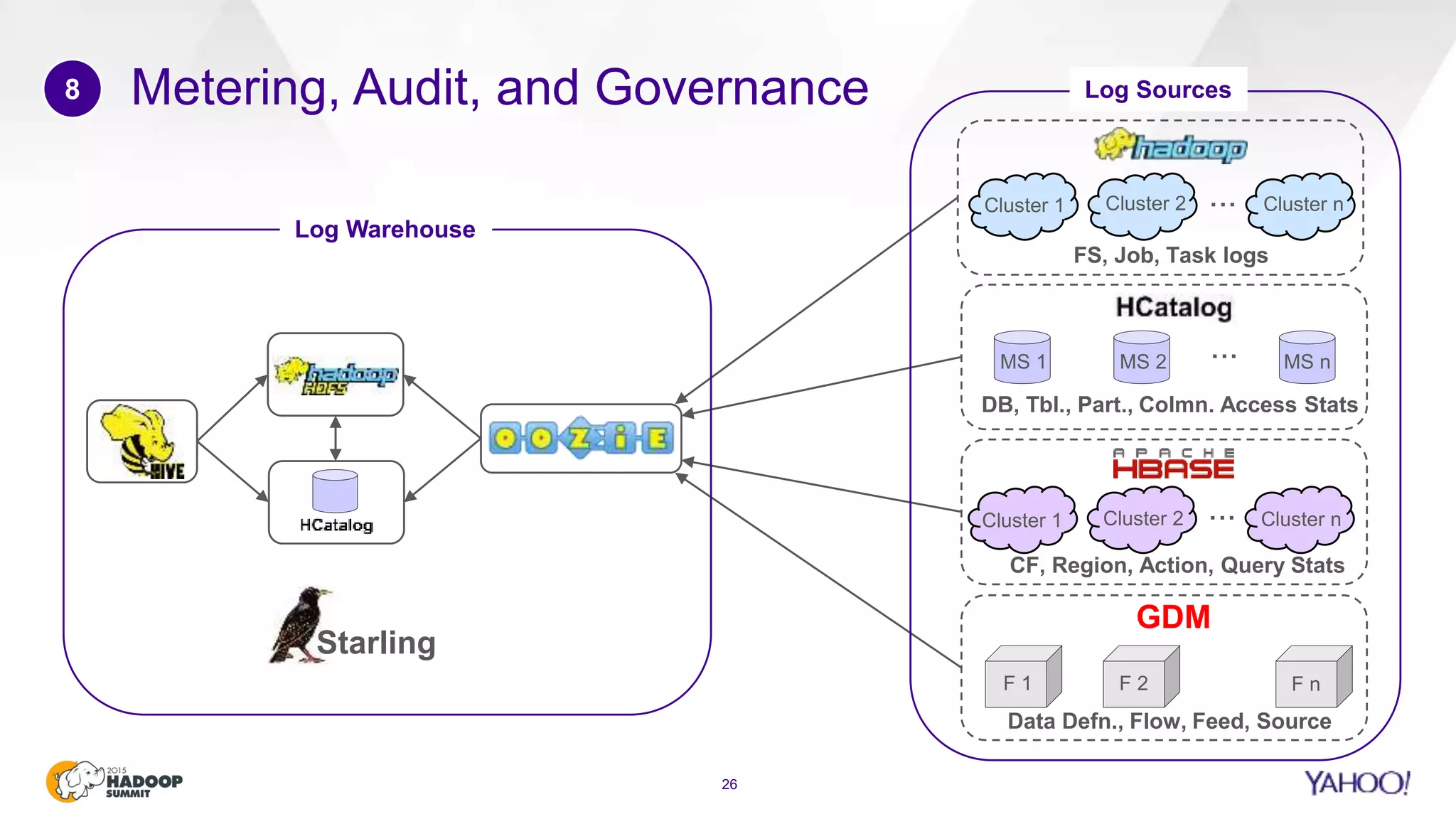
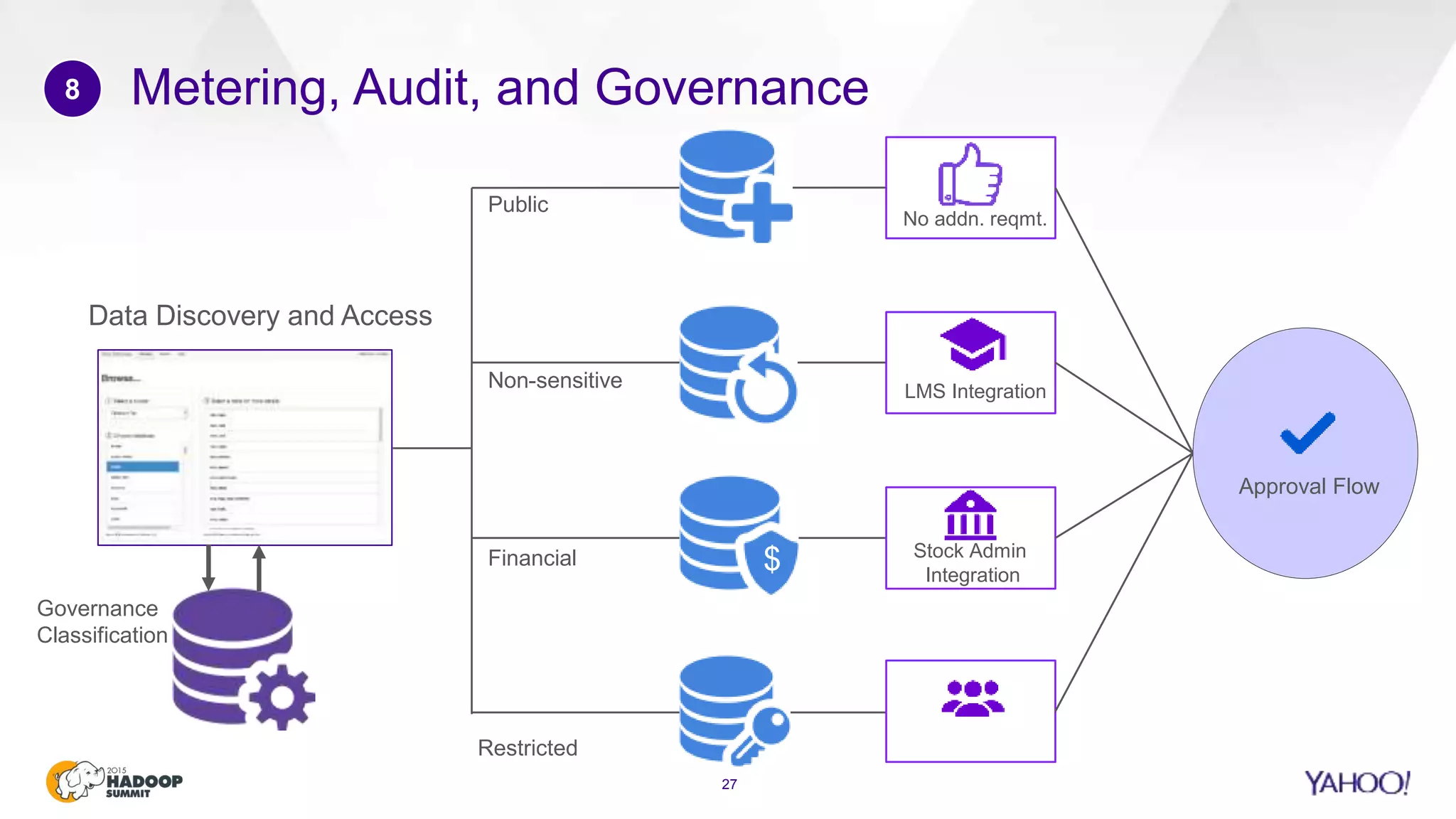
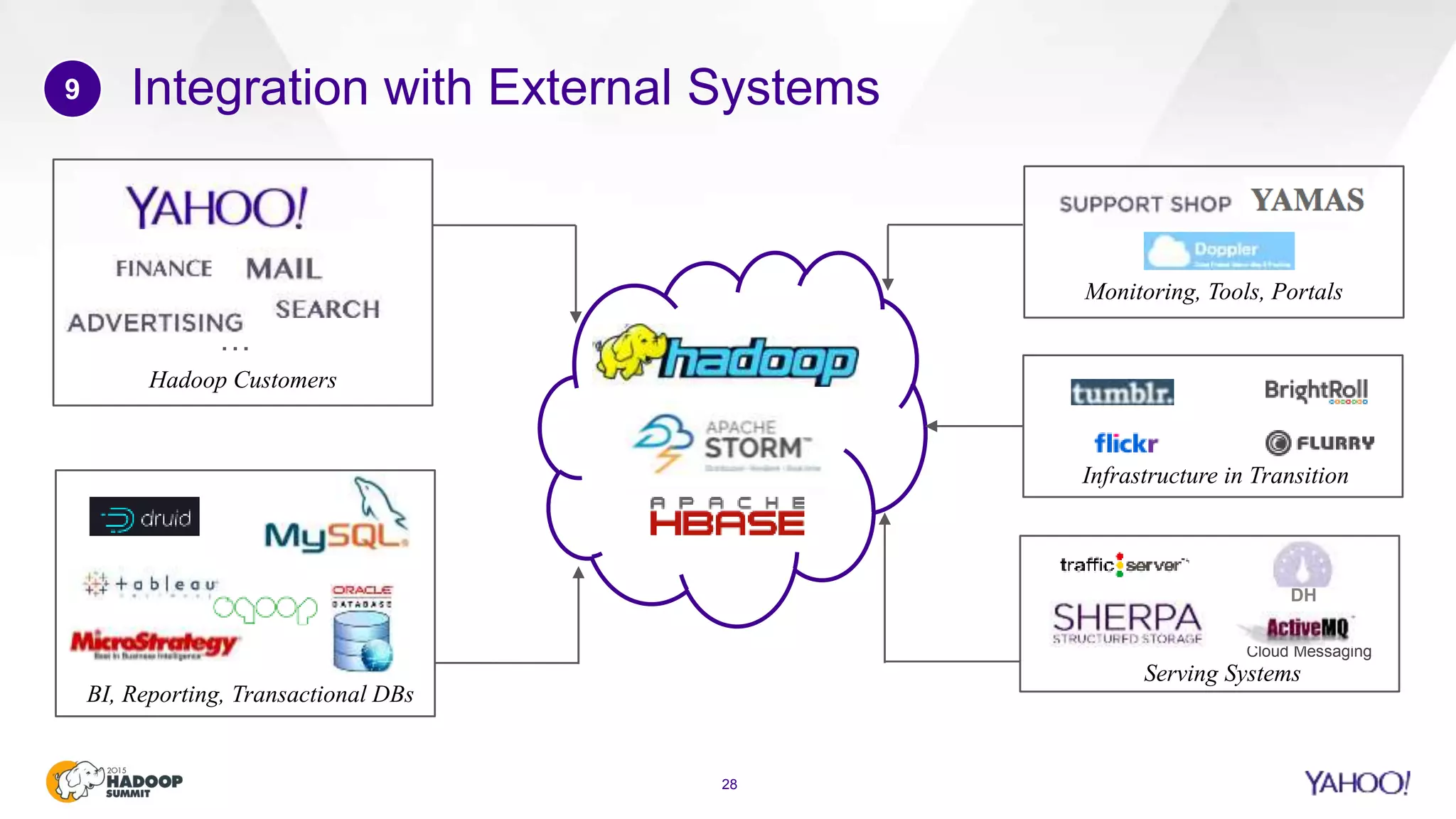



This document discusses considerations for scaling Hadoop platforms at Yahoo. It covers topics such as deployment models (on-premise vs. public cloud), total cost of ownership, hardware configuration, networking, software stack, security, data lifecycle management, metering and governance, and debunking myths. The key takeaways are that utilization matters for cost analysis, hardware becomes increasingly heterogeneous over time, advanced networking designs are needed to avoid bottlenecks, security and access management must be flexible, and data lifecycles require policy-based management.










![[211] HBase 기반 검색 데이터 저장소 (공개용)](https://cdn.slidesharecdn.com/ss_thumbnails/211hbase-171016101436-thumbnail.jpg?width=640&height=640&fit=bounds)



































![Big data application using hadoop in cloud [Smart Refrigerator]](https://cdn.slidesharecdn.com/ss_thumbnails/pushkarbhandari-160107183520-thumbnail.jpg?width=640&height=640&fit=bounds)





























![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)









