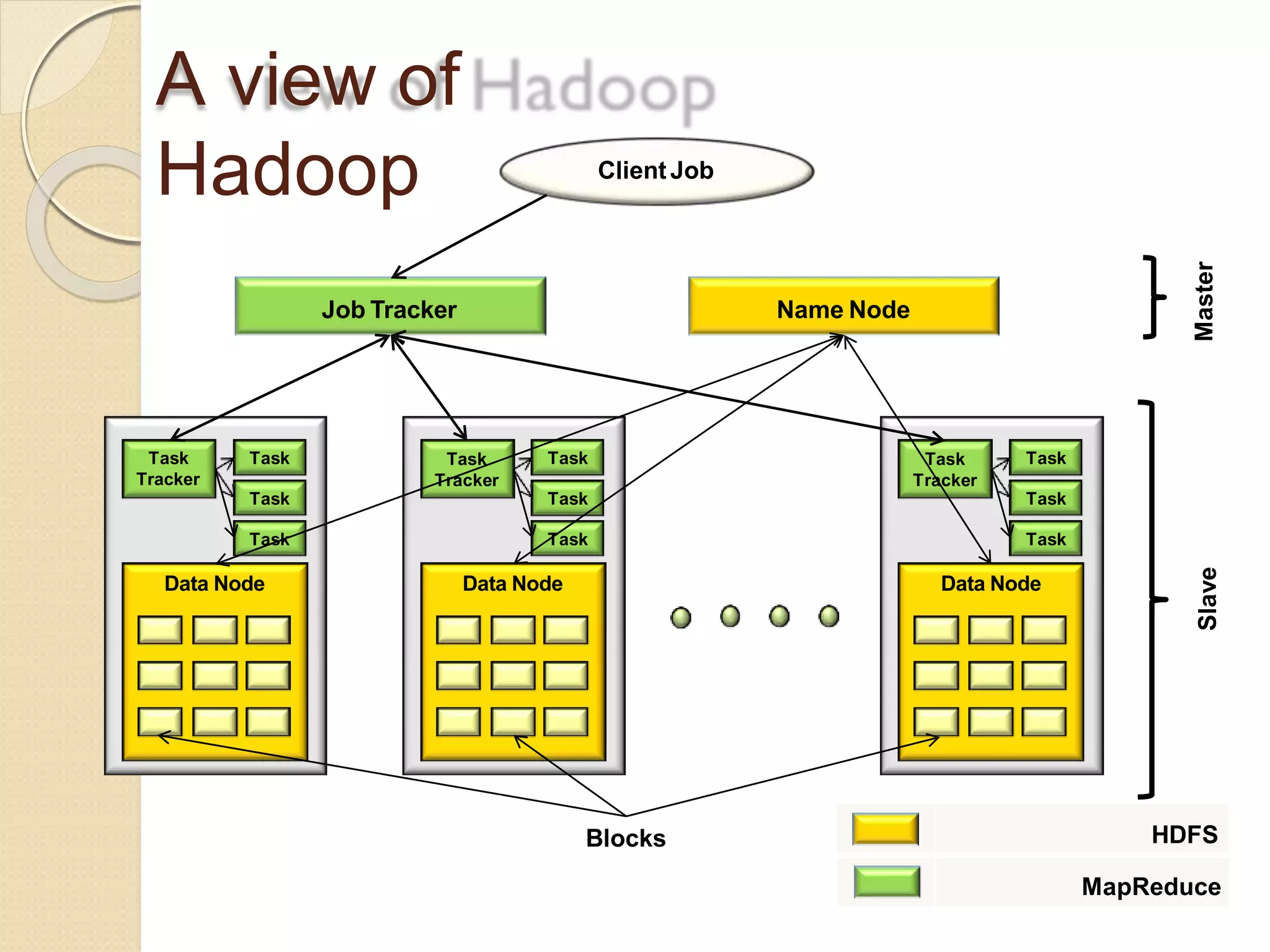
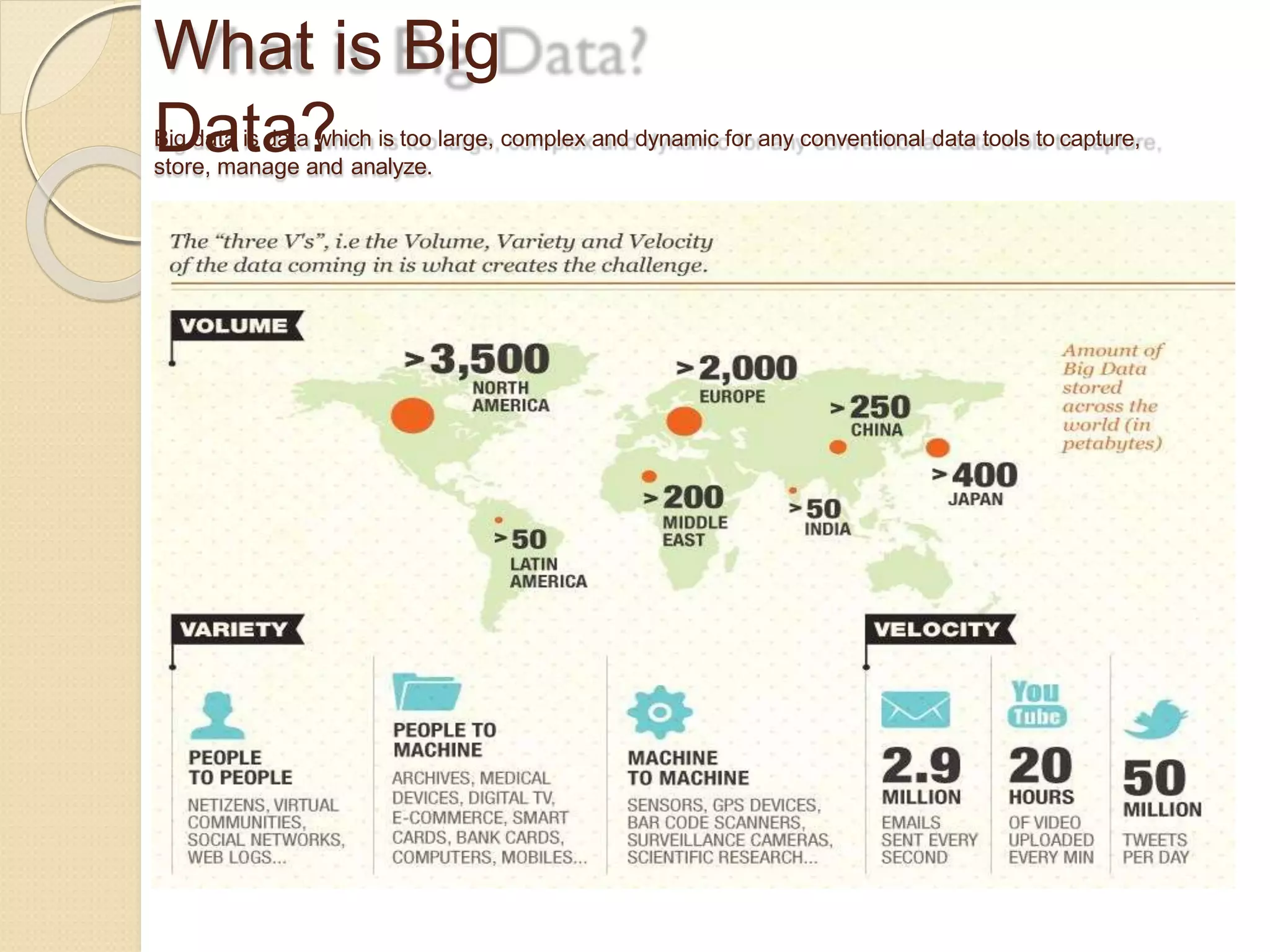
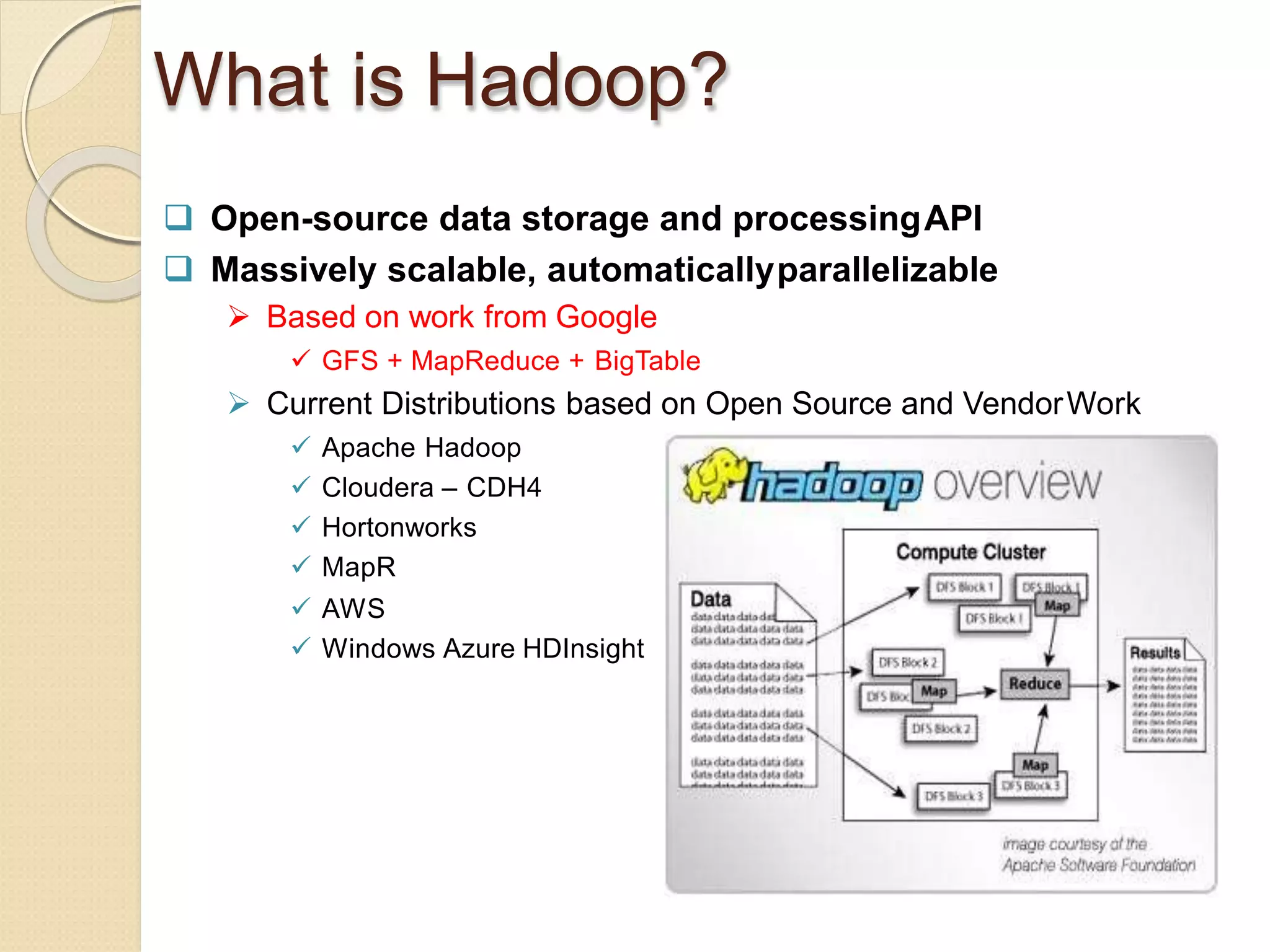
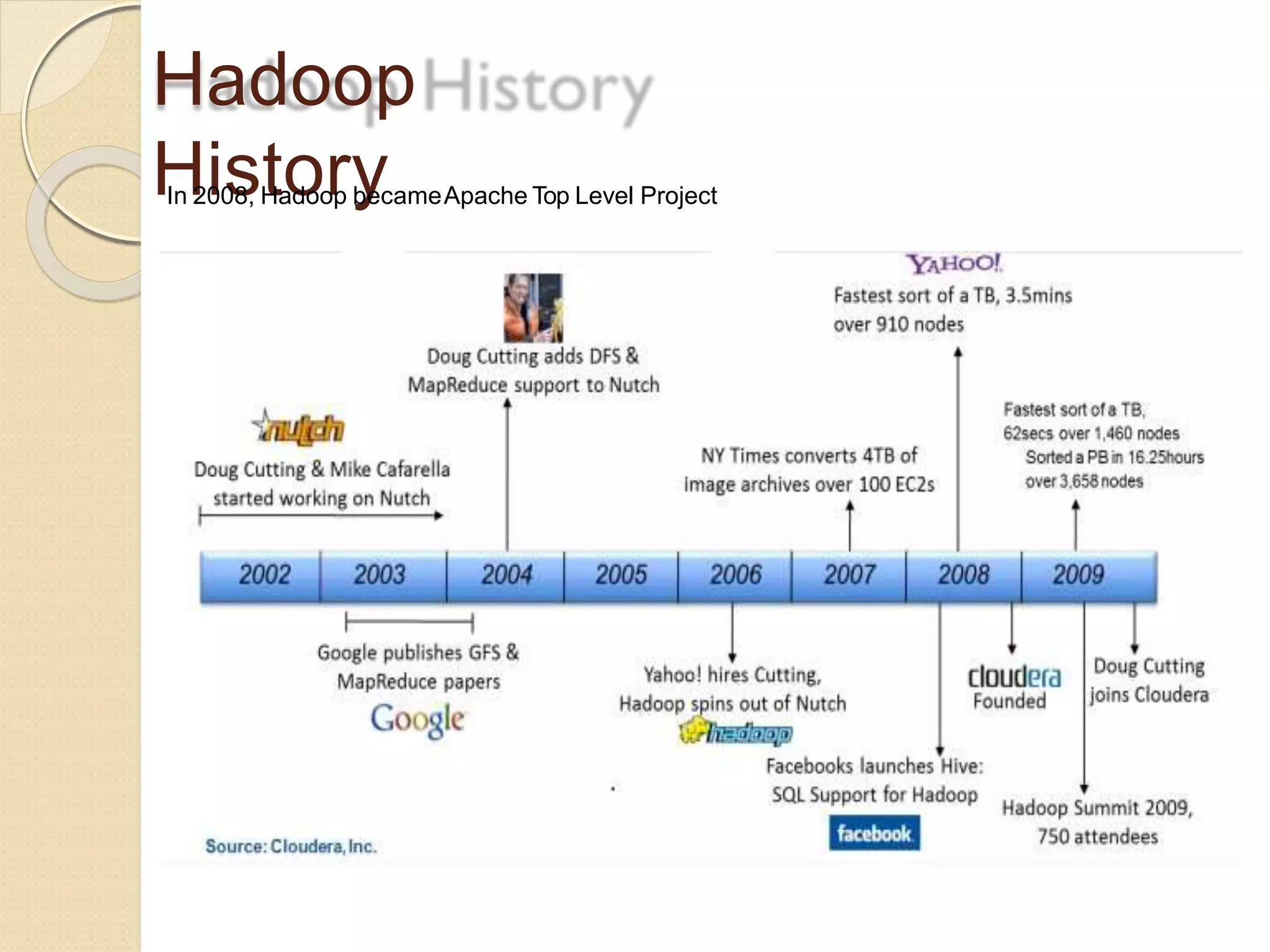
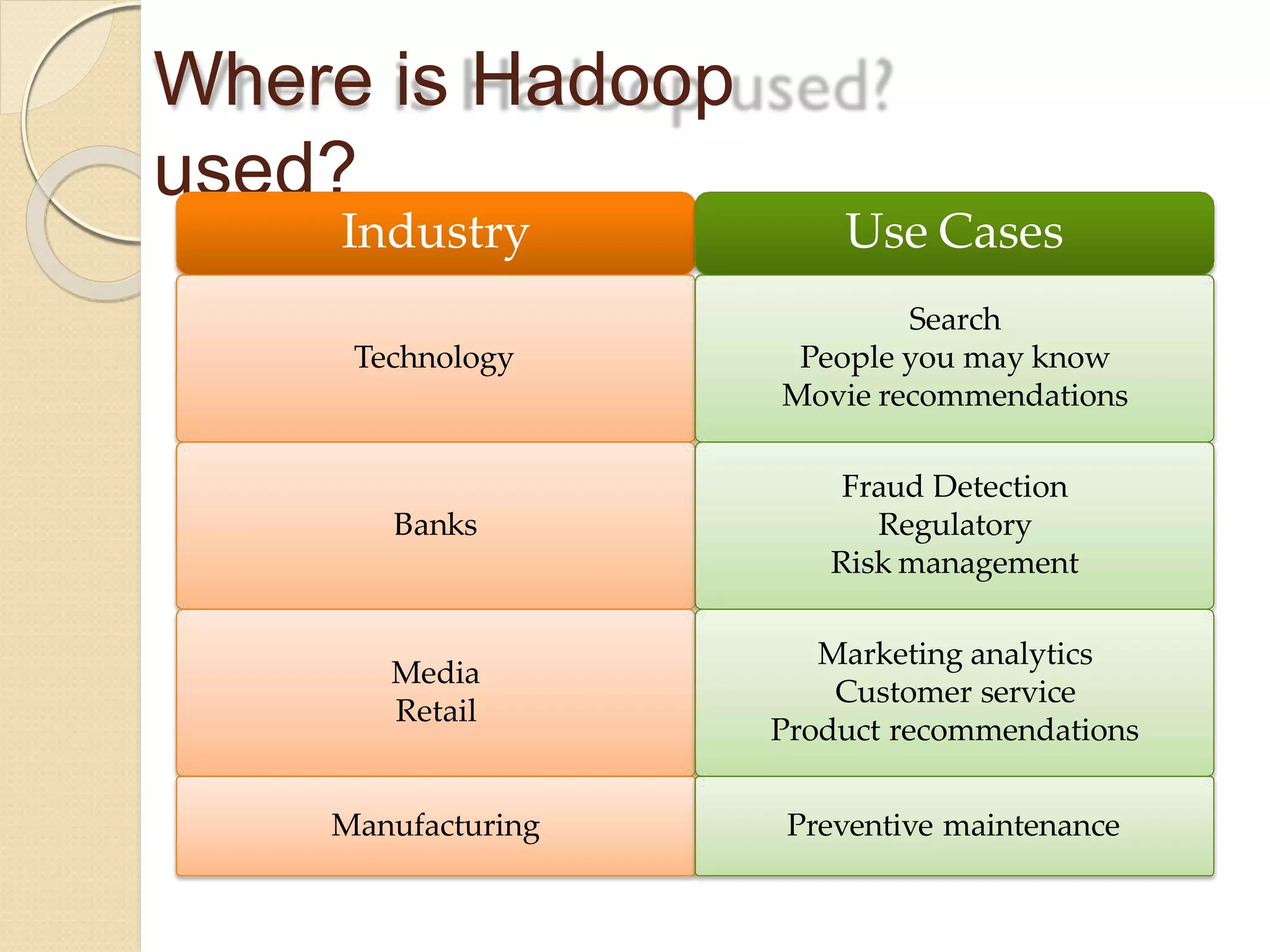
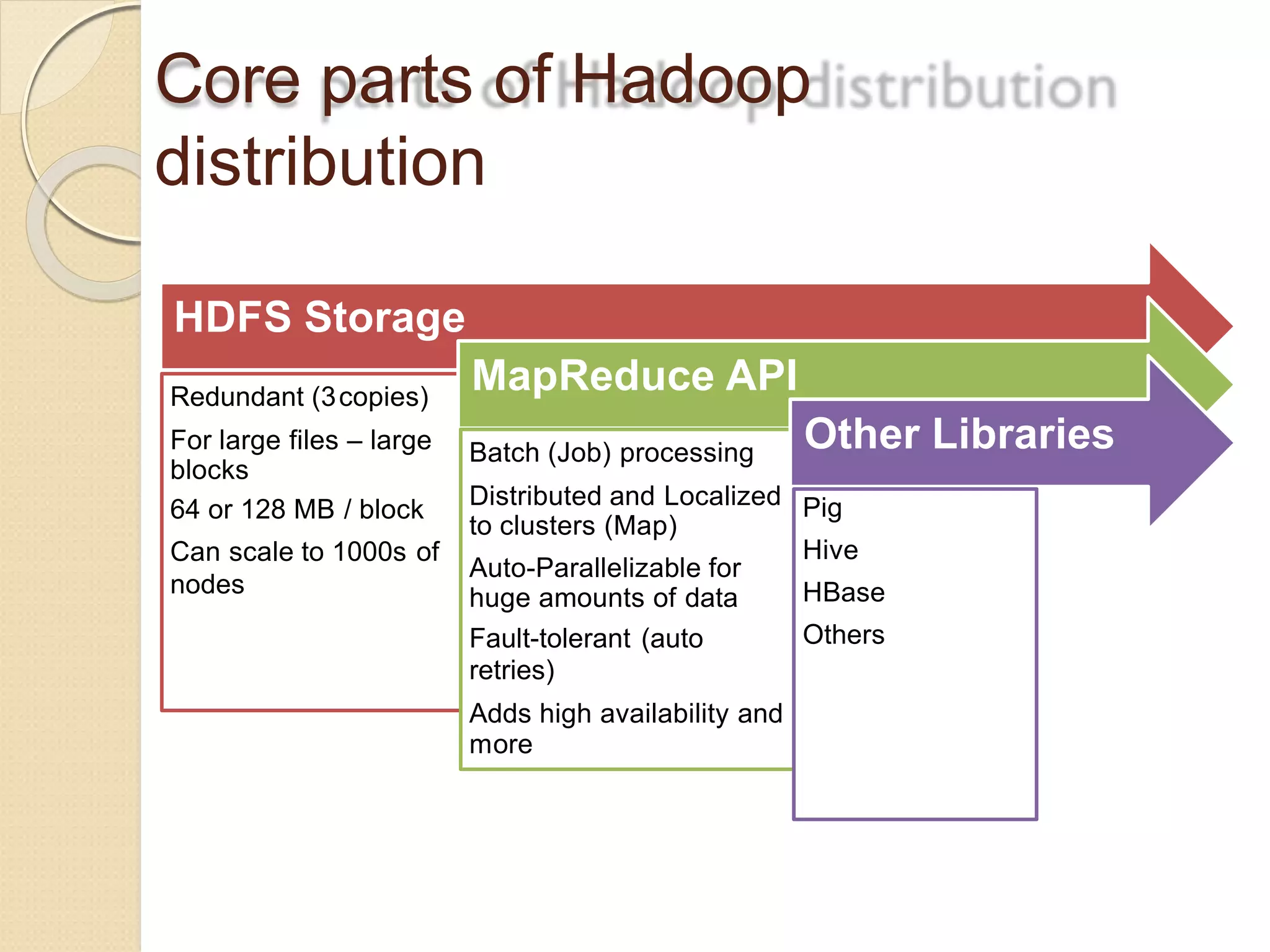
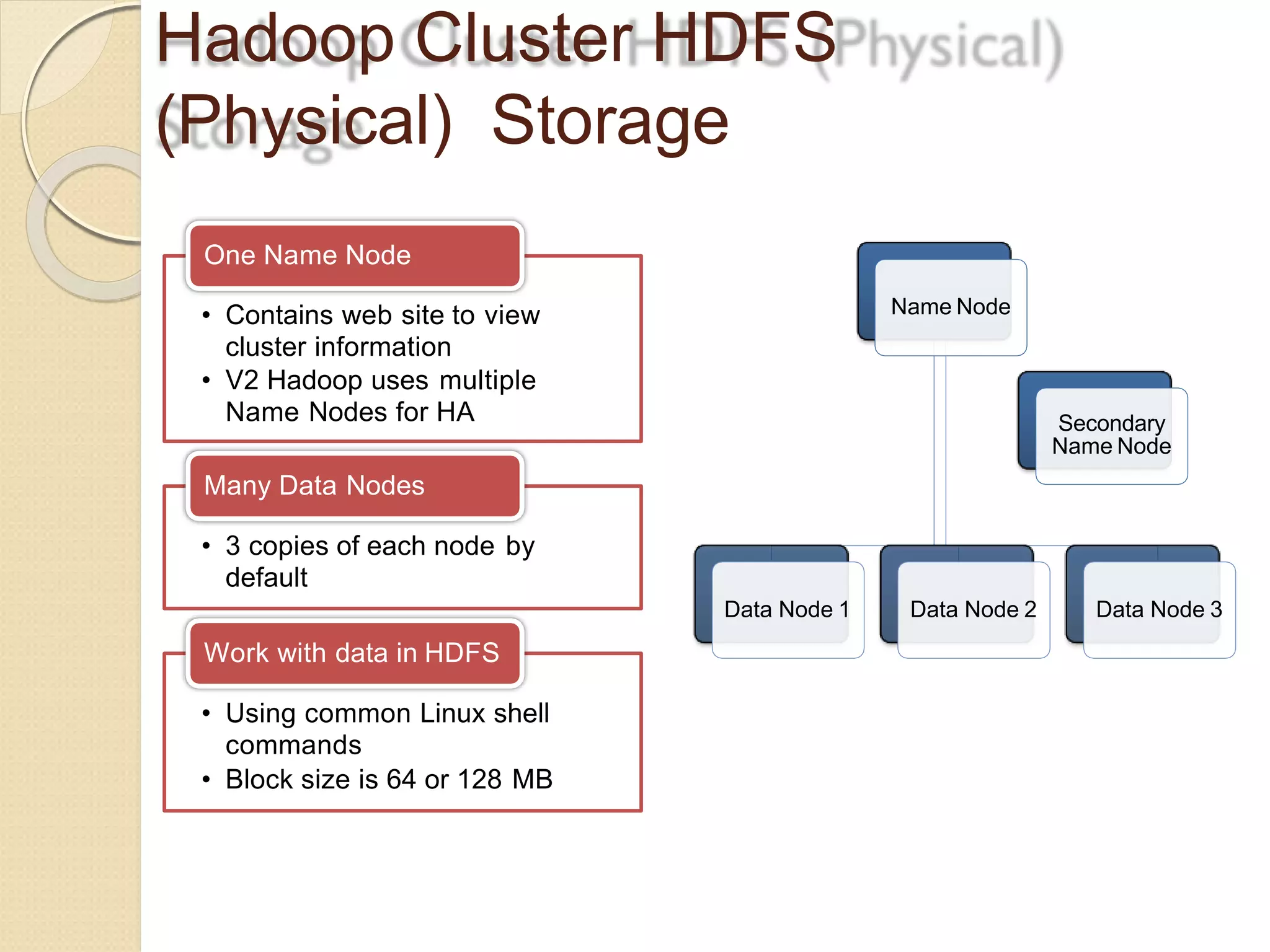
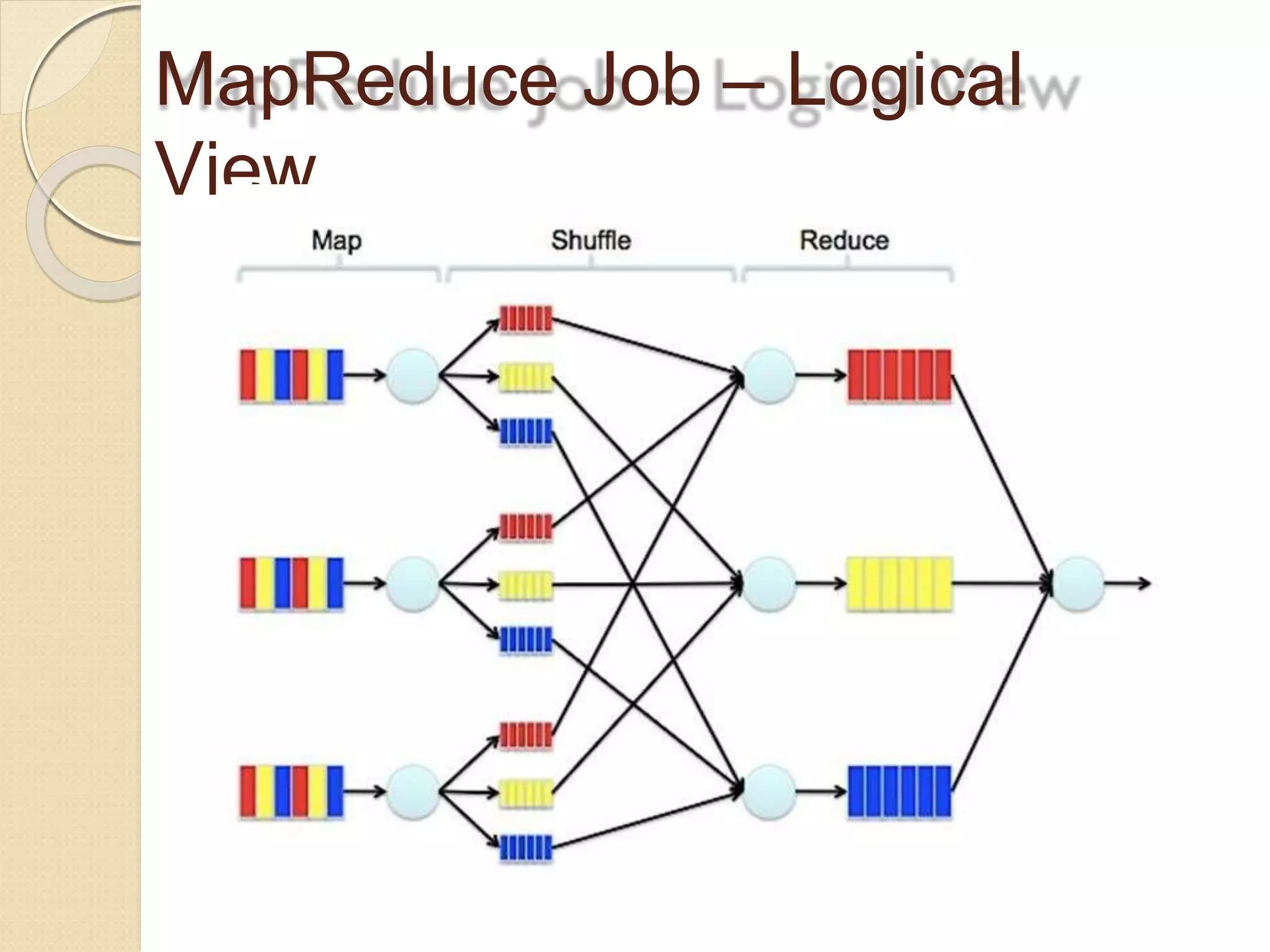
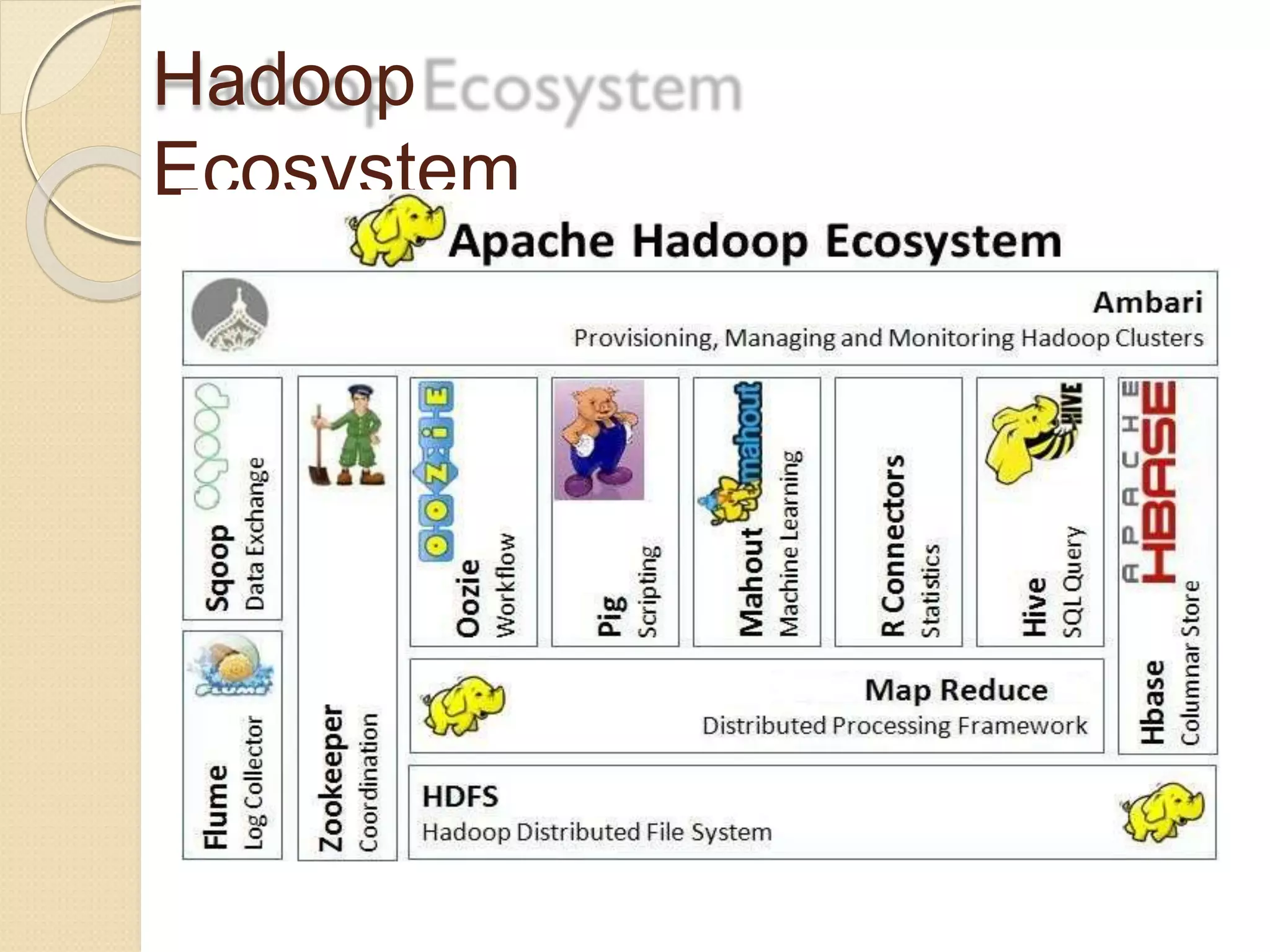
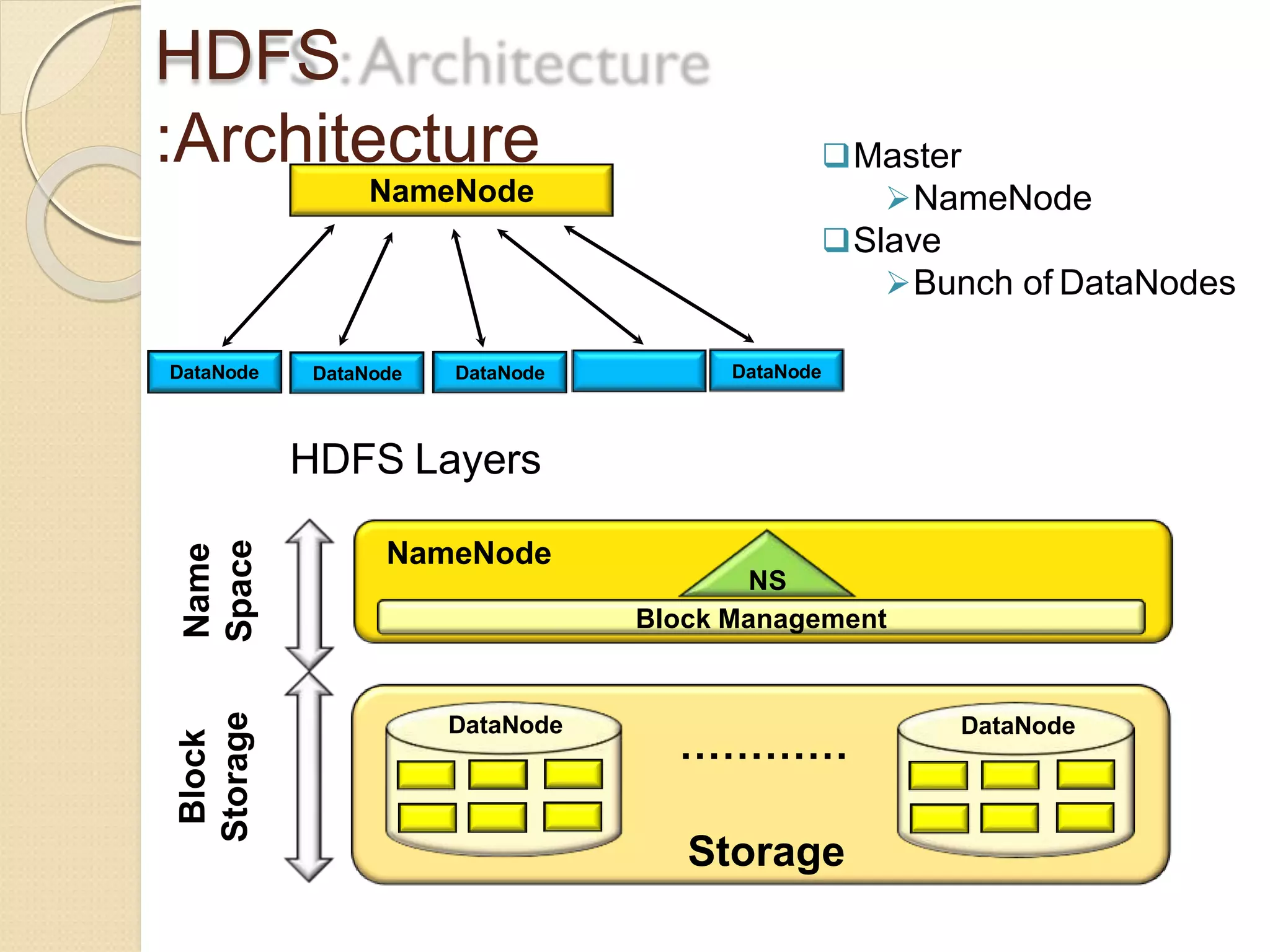
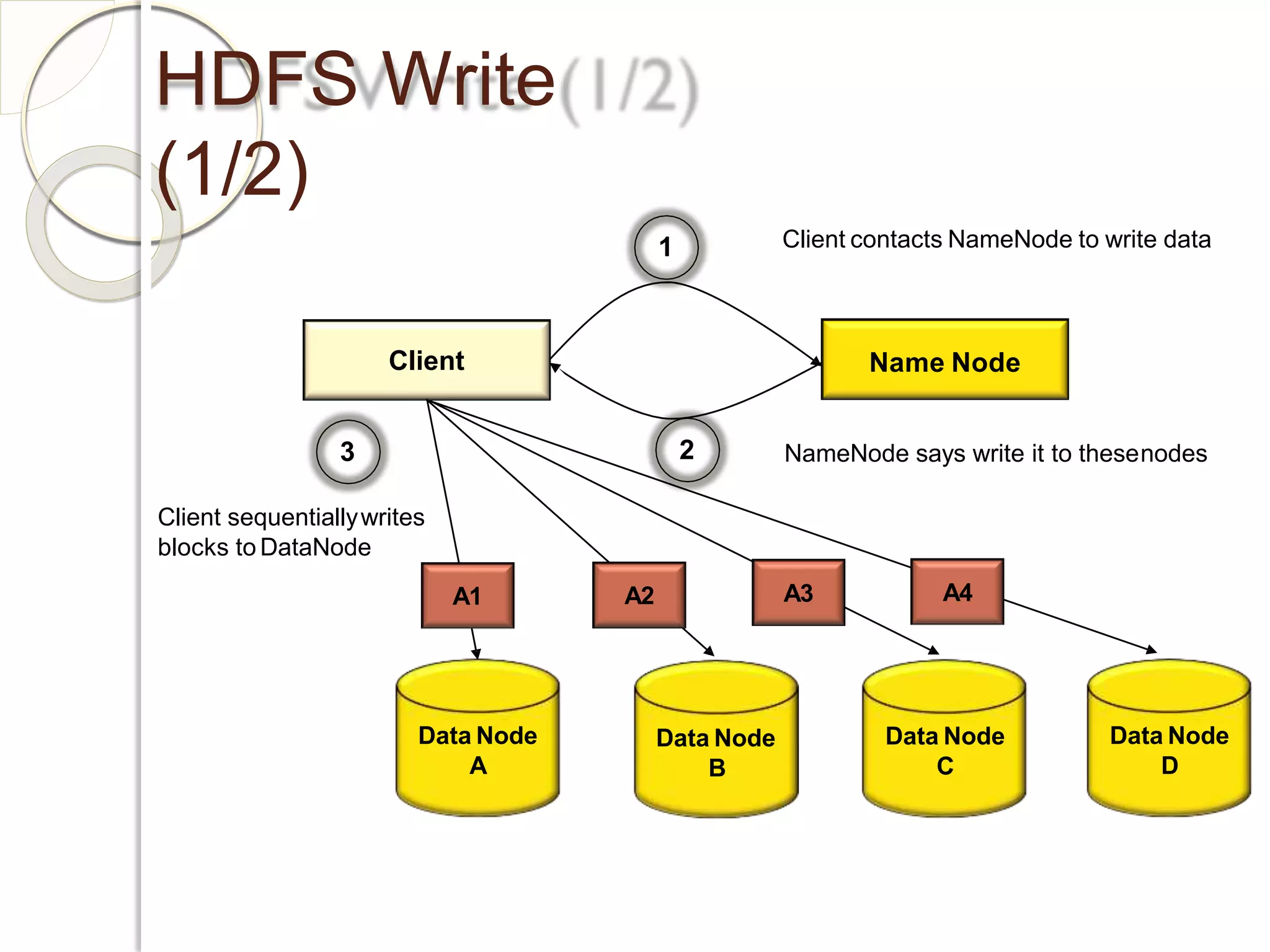
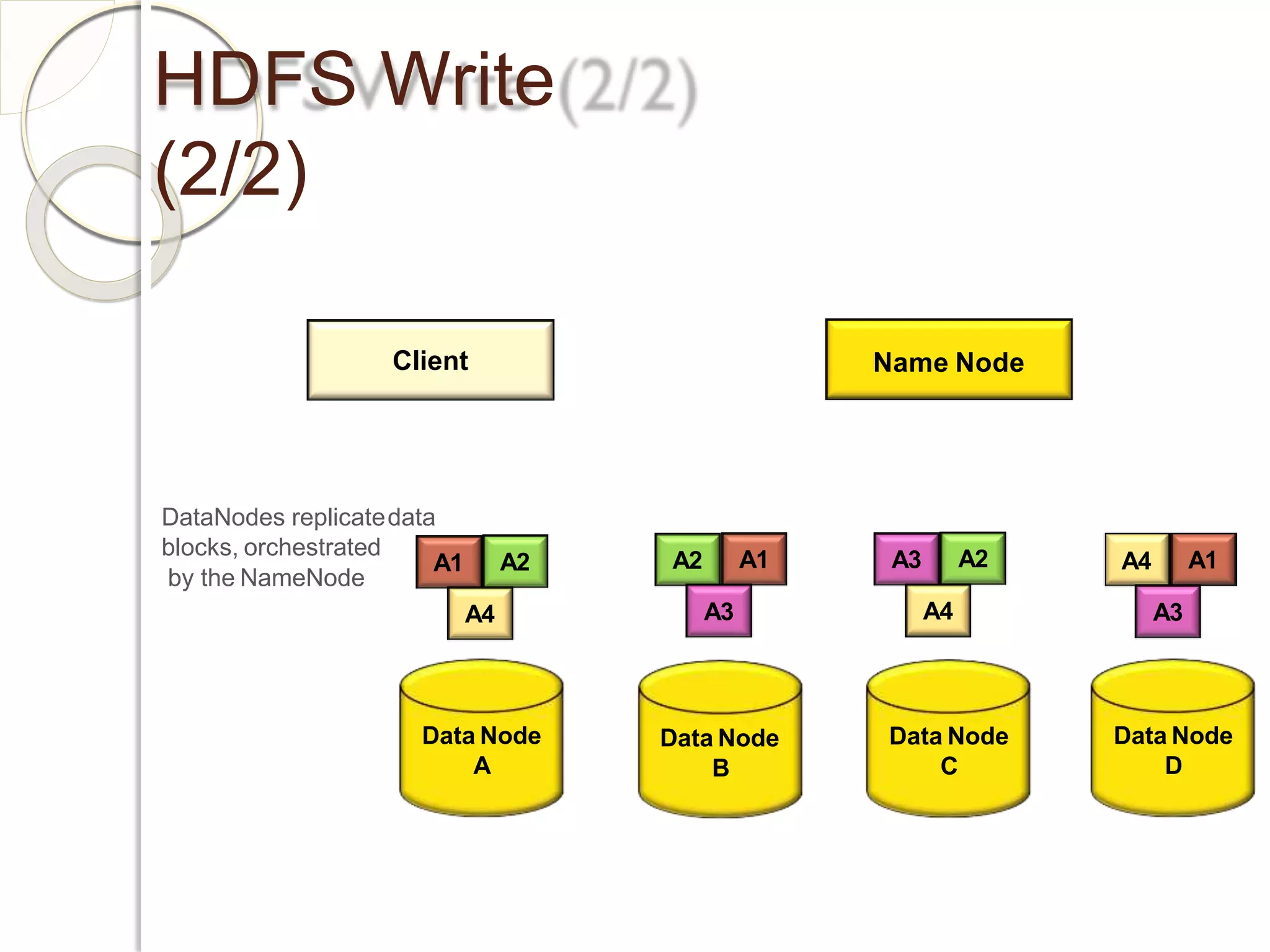
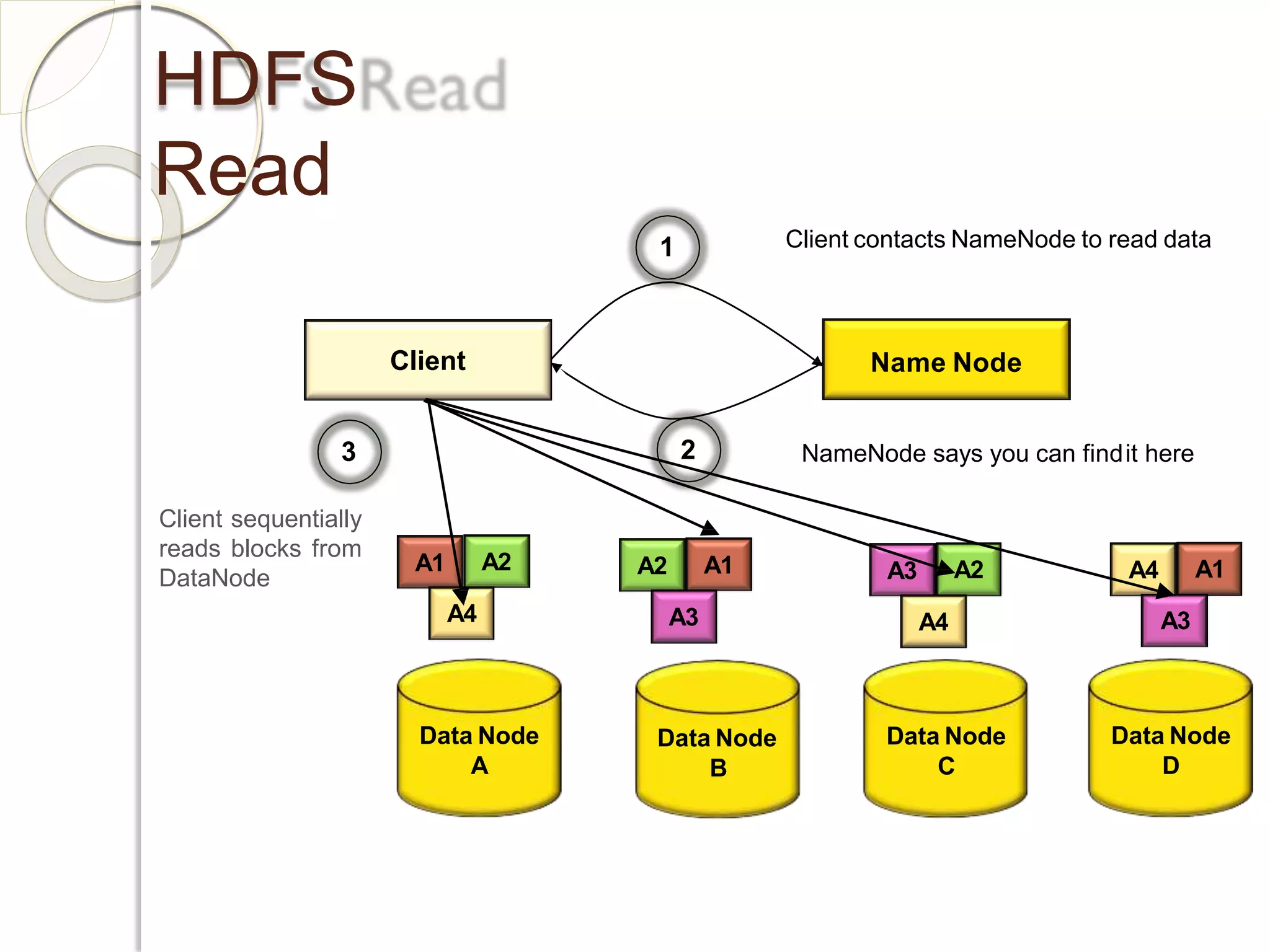
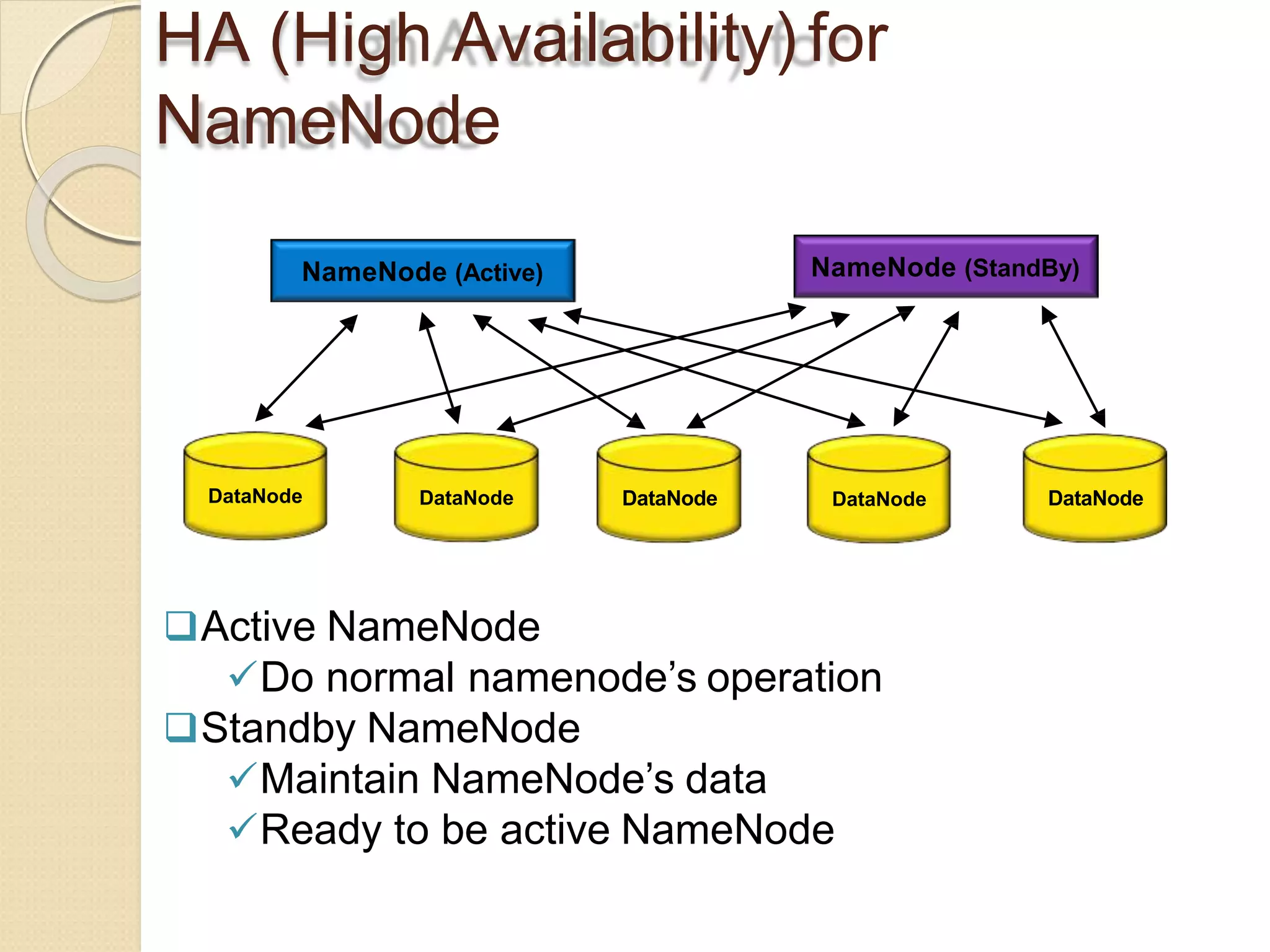
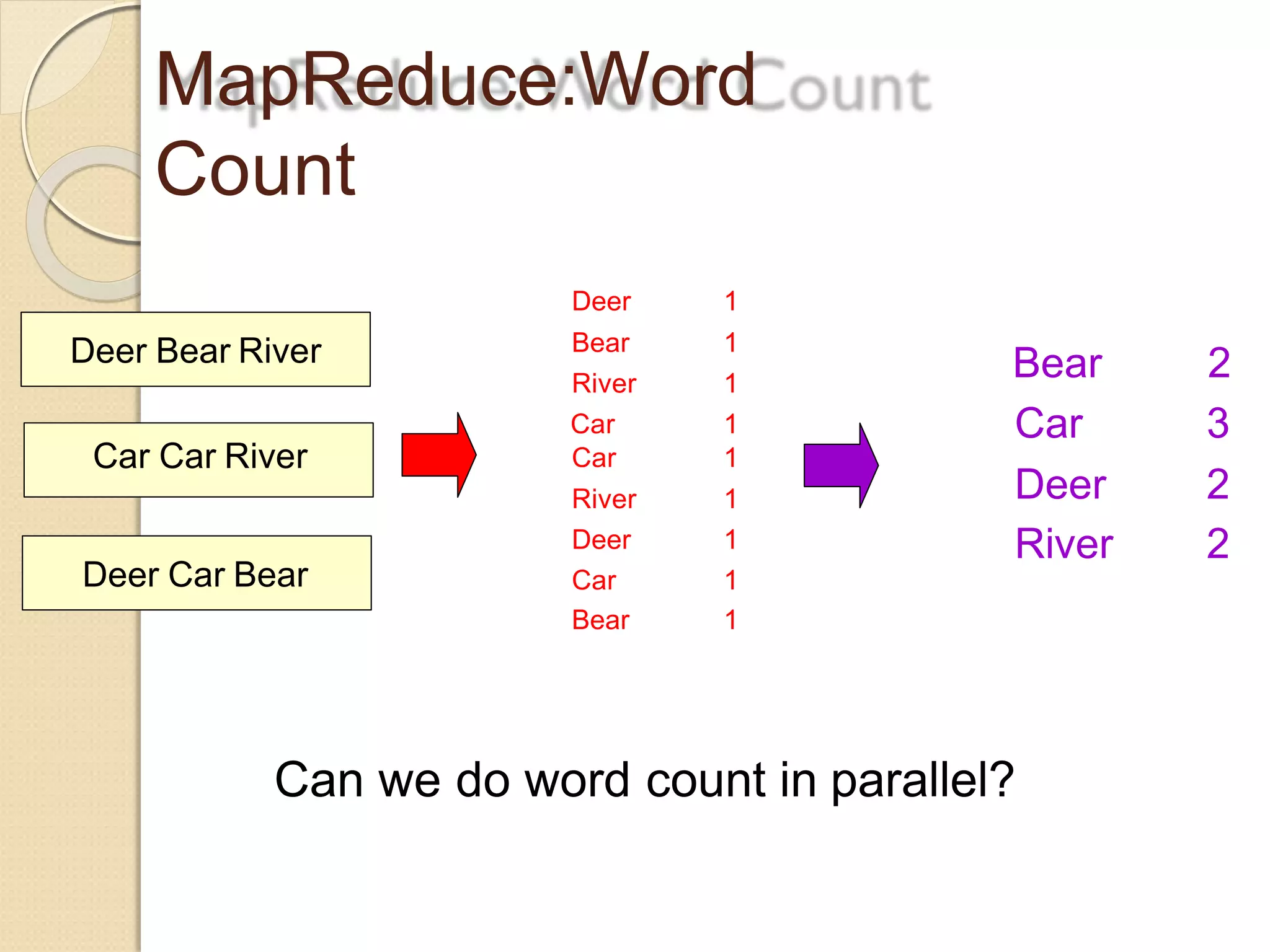
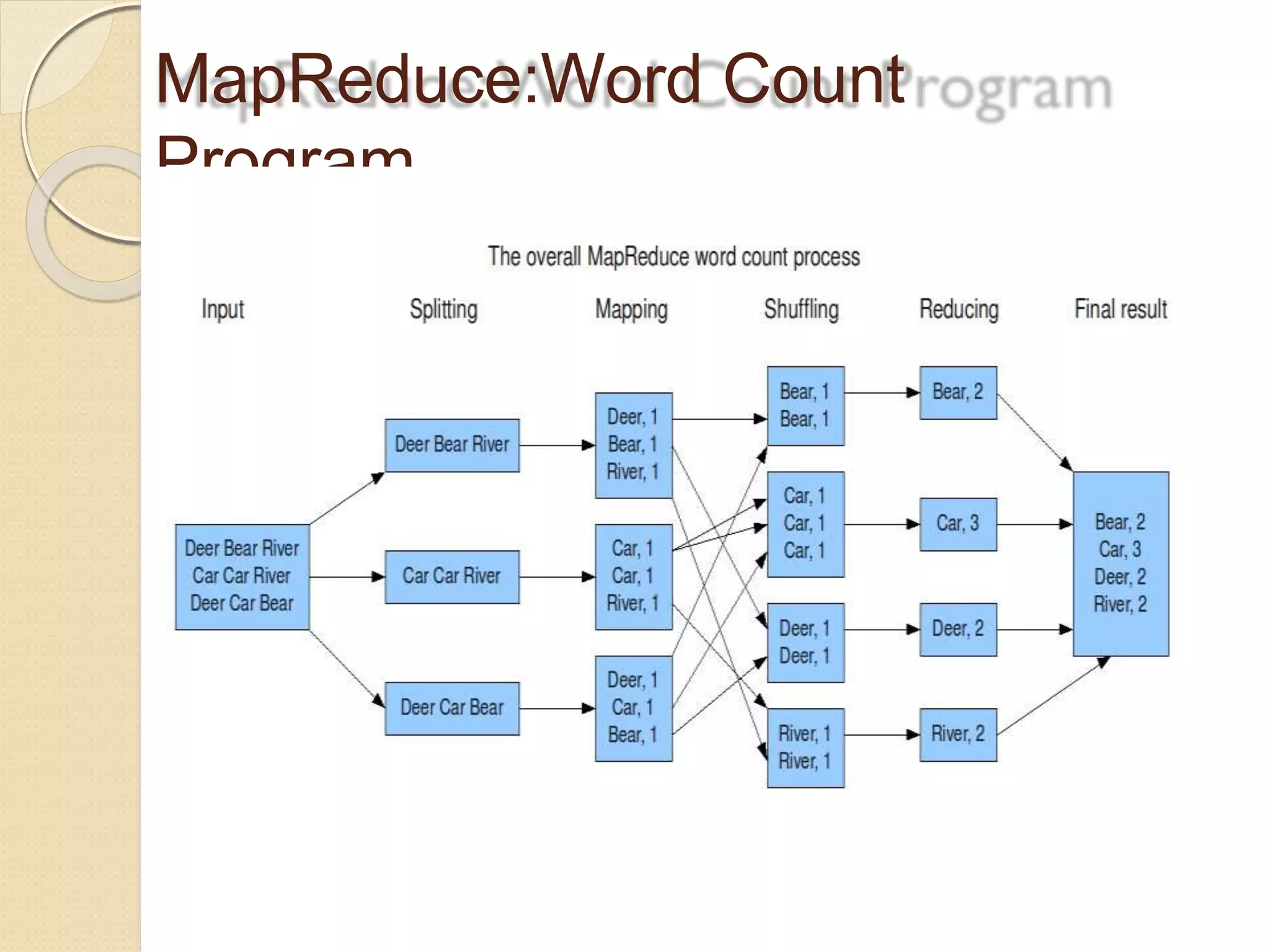
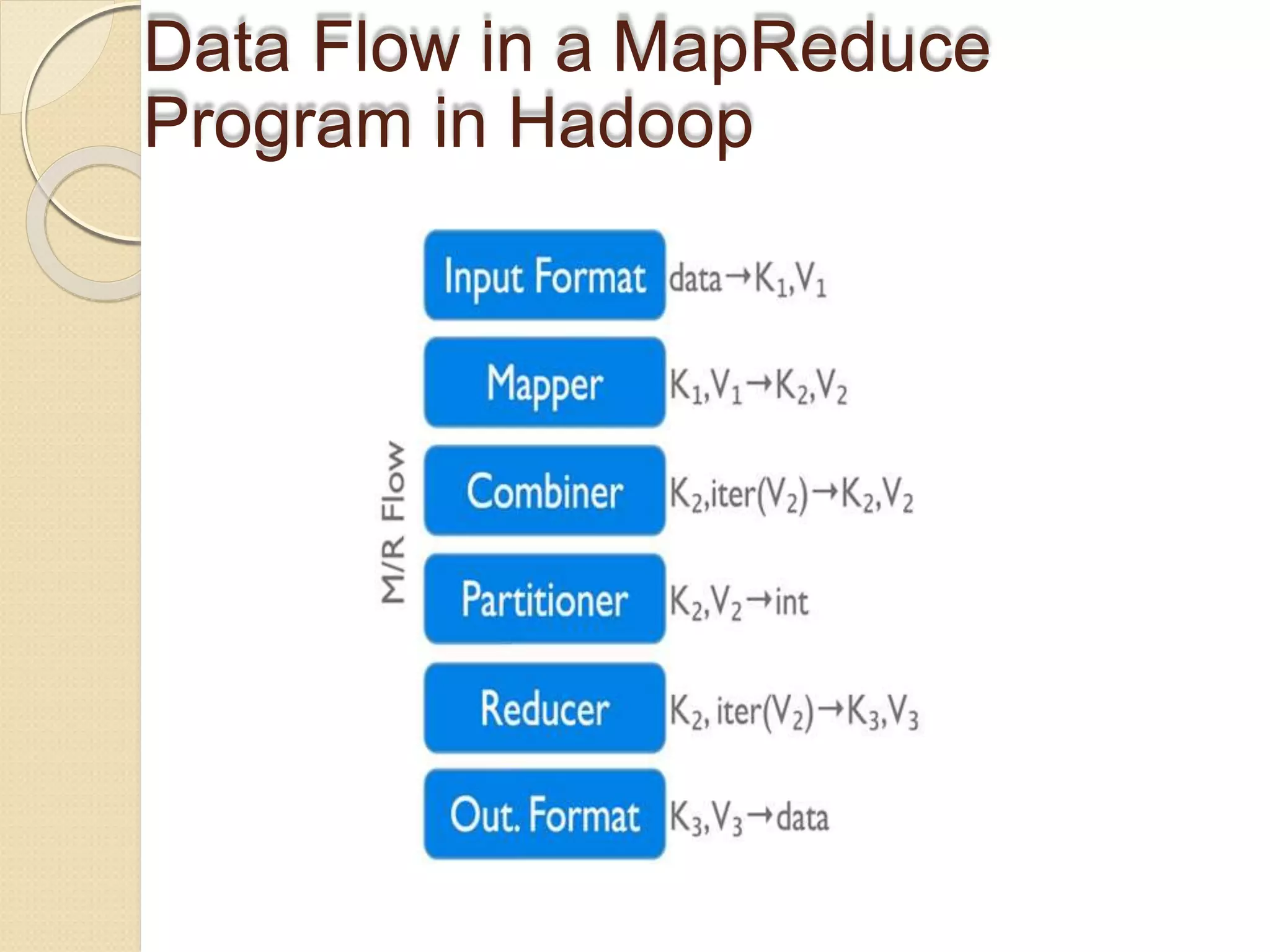
The document provides an overview of big data analytics and Hadoop. It defines big data and the challenges of working with large, complex datasets. It then discusses Hadoop as an open-source framework for distributed storage and processing of big data across clusters of commodity hardware. Key components of Hadoop include HDFS for storage, MapReduce for parallel processing, and other tools like Pig, Hive, HBase etc. The document provides examples of how Hadoop is used by many large companies and describes the architecture and basic functions of HDFS and MapReduce.












![Driver
Class
package ambuj.com.wc;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class WordCountDriver extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
Configuration conf = newConfiguration();
Job job = new Job(conf,"WordCount");
job.setJarByClass(WordCountDriver.class);
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
job.setInputFormatClass(TextInputFormat.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
return 0;
}
public static void main(String[] args) throws Exception {
ToolRunner.run(new WordCountDriver(), args);
}
}](https://image.slidesharecdn.com/basicsofbigdataanalyticshadoop-140823074204-phpapp01-190415164714/75/Basic-of-Big-Data-30-2048.jpg)