Downloaded 51 times


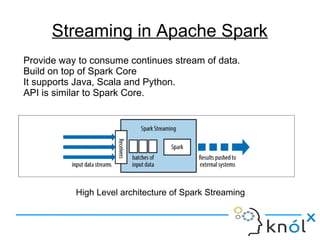
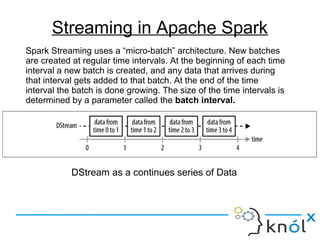


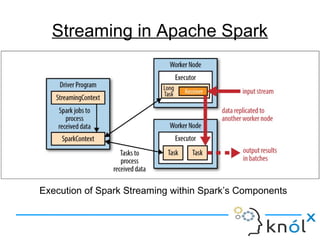


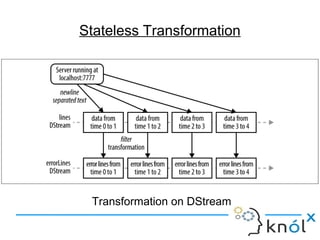


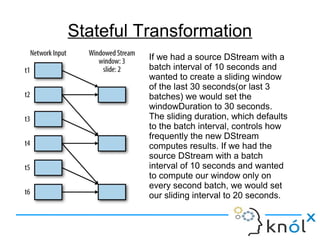








The document introduces Apache Spark Streaming, which enables the processing of continuous data streams using a micro-batch architecture with discretized streams (DStreams). It covers key concepts such as transformations (stateless and stateful), actions, and performance tuning for efficient stream processing. Additionally, it discusses the significance of checkpointing for state management and recovery of lost data.











































































































