Download as PDF, PPTX

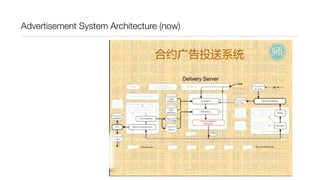
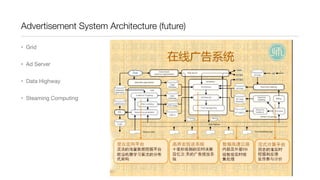
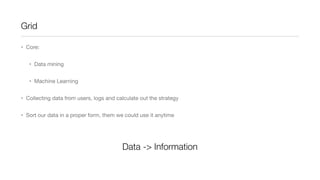
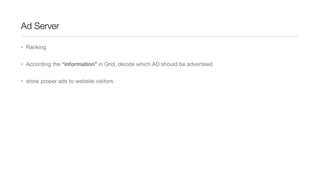


![Functional “map/reduce”
• map()/reduce() in Python
• map(function(elem), list) -> list
• reduce(function(elem1, elem2), list) -> single result
• e.g.
• map(lambda x: x*2, [1,2,3,4]) => [2,4,6,8]
• reduce(lambda x,y: x+y, [1,2,3,4]) => 10](https://image.slidesharecdn.com/introductiontomapreducehadoop-131016041940-phpapp01/85/Introduction-to-MapReduce-hadoop-11-320.jpg)
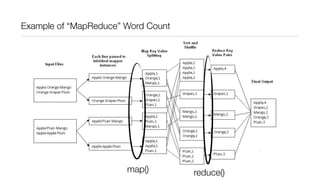
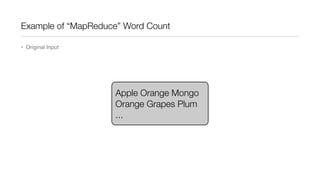
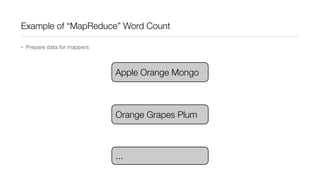
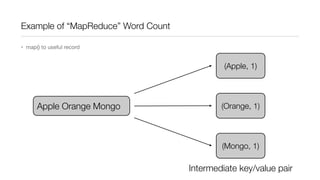
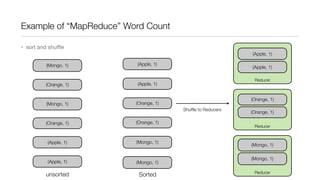
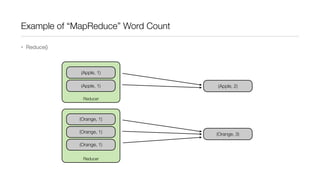
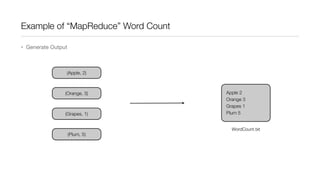
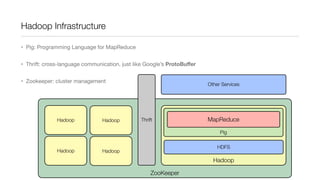

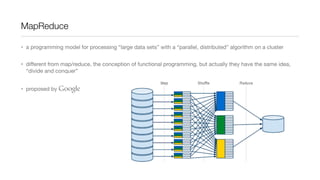
This document provides an introduction to Hadoop and MapReduce. It describes how Hadoop is composed of MapReduce and HDFS. MapReduce is a programming model that allows processing of large datasets in a distributed, parallel manner. It works by breaking the processing into mappers that perform filtering and sorting, and reducers that perform summarization. HDFS provides a distributed file system that stores data across clusters of machines. An example of word count using MapReduce is described to illustrate how it works.
























































![[Harvard CS264] 08b - MapReduce and Hadoop (Zak Stone, Harvard)](https://cdn.slidesharecdn.com/ss_thumbnails/cs264hadooplecture2011-110322172329-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
















































