Downloaded 462 times





































![Dot product
● Dot product of two vectors A = [ a1, a2 , a3 ..] and B=
[b1,b2,b3 .. ] is
A.B = sum ( a1*b1 + a2*b2 + a3*b3)
● Two ways to implement in breeze
○ A.dot(B)
○ Transpose(A) * B)
● DotProductExample.scala](https://image.slidesharecdn.com/introductiontomachinelearningwithspark-150906063711-lva1-app6891/85/Introduction-to-Machine-Learning-with-Spark-41-320.jpg)

![Representing data as RDD[Vector]
● In Spark ML, each row is represented using vectors
● Representing row in vector allows us to easily
manipulate them using earlier discussed vector
manipulations
● We broadcast vector for efficiency
● We can manipulate partition at a time using represent
them as the matrices
● Manipulating as partition can give good performance
● RDDVectorExample.scala](https://image.slidesharecdn.com/introductiontomachinelearningwithspark-150906063711-lva1-app6891/85/Introduction-to-Machine-Learning-with-Spark-43-320.jpg)






![LR for housing data
● We are going to predict housing price using house size
● Size and price are in different scale
● Need to scale both of them to same scale
● We use StandardScaler to scale RDD[Vector]
● Scaled Data will be used for LinearRegression
● Ex : LRForHousingData.scala](https://image.slidesharecdn.com/introductiontomachinelearningwithspark-150906063711-lva1-app6891/85/Introduction-to-Machine-Learning-with-Spark-50-320.jpg)



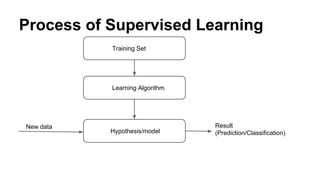
The document provides an introduction to machine learning with a focus on implementation in Spark, discussing the differences between traditional machine learning and big data applications. It covers essential concepts such as supervised and unsupervised learning, linear regression, and the importance of vector manipulation, while emphasizing Spark's optimizations for iterative computation to enhance machine learning performance. Additionally, it includes examples and references for further exploration of machine learning using Spark and related technologies.









































![[update] Introductory Parts of the Book "Dive into Deep Learning"](https://cdn.slidesharecdn.com/ss_thumbnails/d2lq1introbasicssimplemodels-190415080926-thumbnail.jpg?width=640&height=640&fit=bounds)




























![[DSC Europe 25] Elena Menshikova - AI-Powered Operational Excellence: Revolut...](https://cdn.slidesharecdn.com/ss_thumbnails/es6nholbqy3zaao2c2yd-2-elena-menshikova-data-ai-in-decision-making-260115093812-4fba8b38-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Ivan Lukovic & Marija Djukic - From Data to Value: Why Maturi...](https://cdn.slidesharecdn.com/ss_thumbnails/ahrfps8xr6knowwhacxh-1-ivan-marija-dsc-2025-ld-v1-presentation-260115093812-be21adfc-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Stefan Brankovic - #ResumeIsDead. AI-Powered Interviews and C...](https://cdn.slidesharecdn.com/ss_thumbnails/qnmbsv0xq3uysdrq3sev-2-stefan-brankovic-job-bolt-260114111931-a065aa3d-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Danilo Djukanovic - From Vibes to KPIs: Turning Culture Into ...](https://cdn.slidesharecdn.com/ss_thumbnails/inqestws5wf0cik2glgv-3-danilo-djukanovic-from-vibes-to-kpis-presentation-260114111931-dacff81f-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Ivica Milaric - The Future of Gaming and AI Tools.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/tijgzsmgse2kj2y5pzzp-5-ivica-milaric-the-future-of-gaming-x-ai-tools-260114111931-87c2b3ac-thumbnail.jpg?width=640&height=640&fit=bounds)