Downloaded 82 times




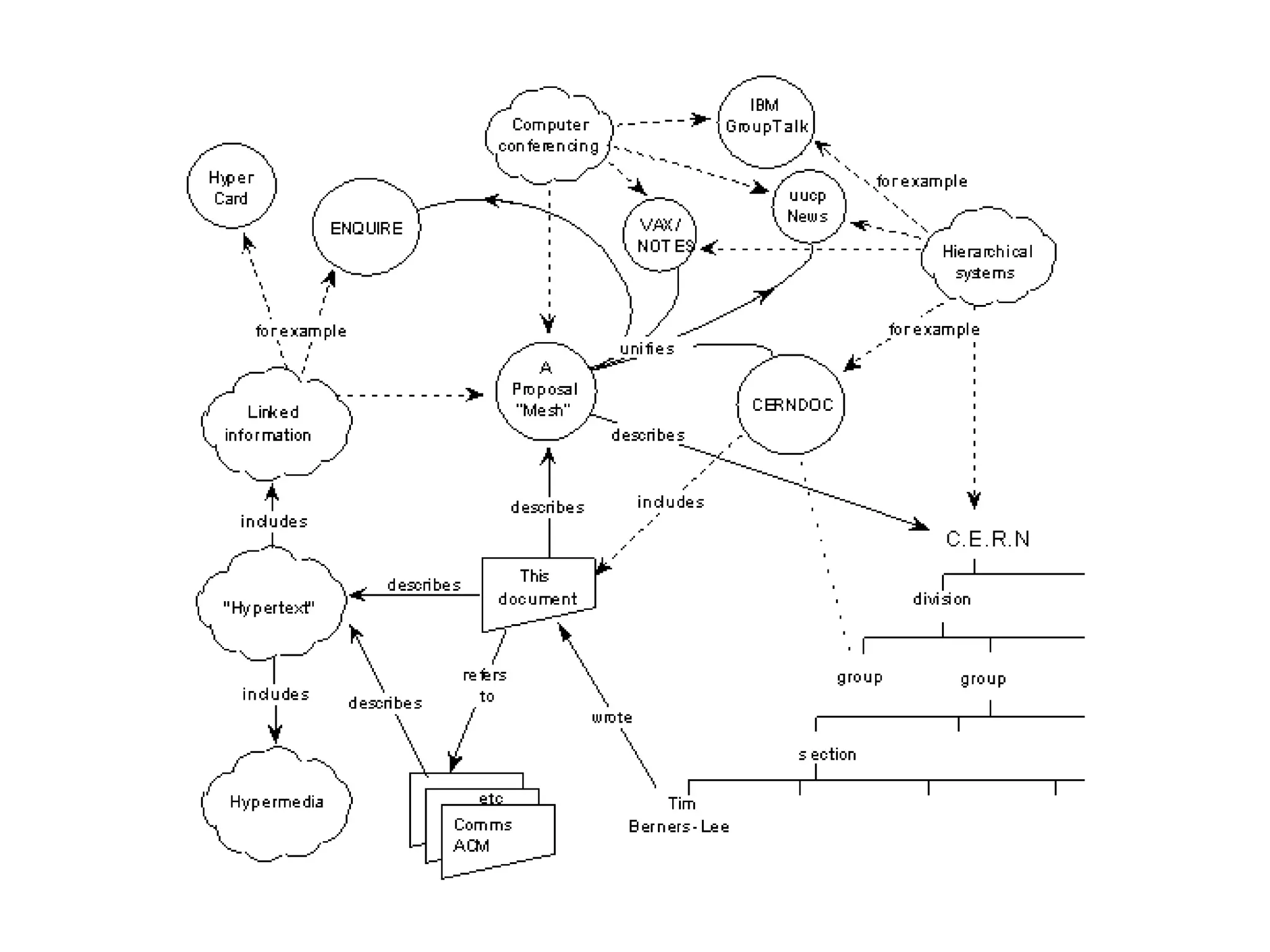
![What is the Web?“… the Web, is a system of interlinked hypertext documents accessed via the Internet. With a web browser, one can view web pages that may contain text, images […] and navigate between them via hyperlinks”http://en.wikipedia.org/wiki/World_Wide_Web](https://image.slidesharecdn.com/01-linked-data-intro-110606101406-phpapp02/75/Introduction-to-Linked-Data-1-5-6-2048.jpg)





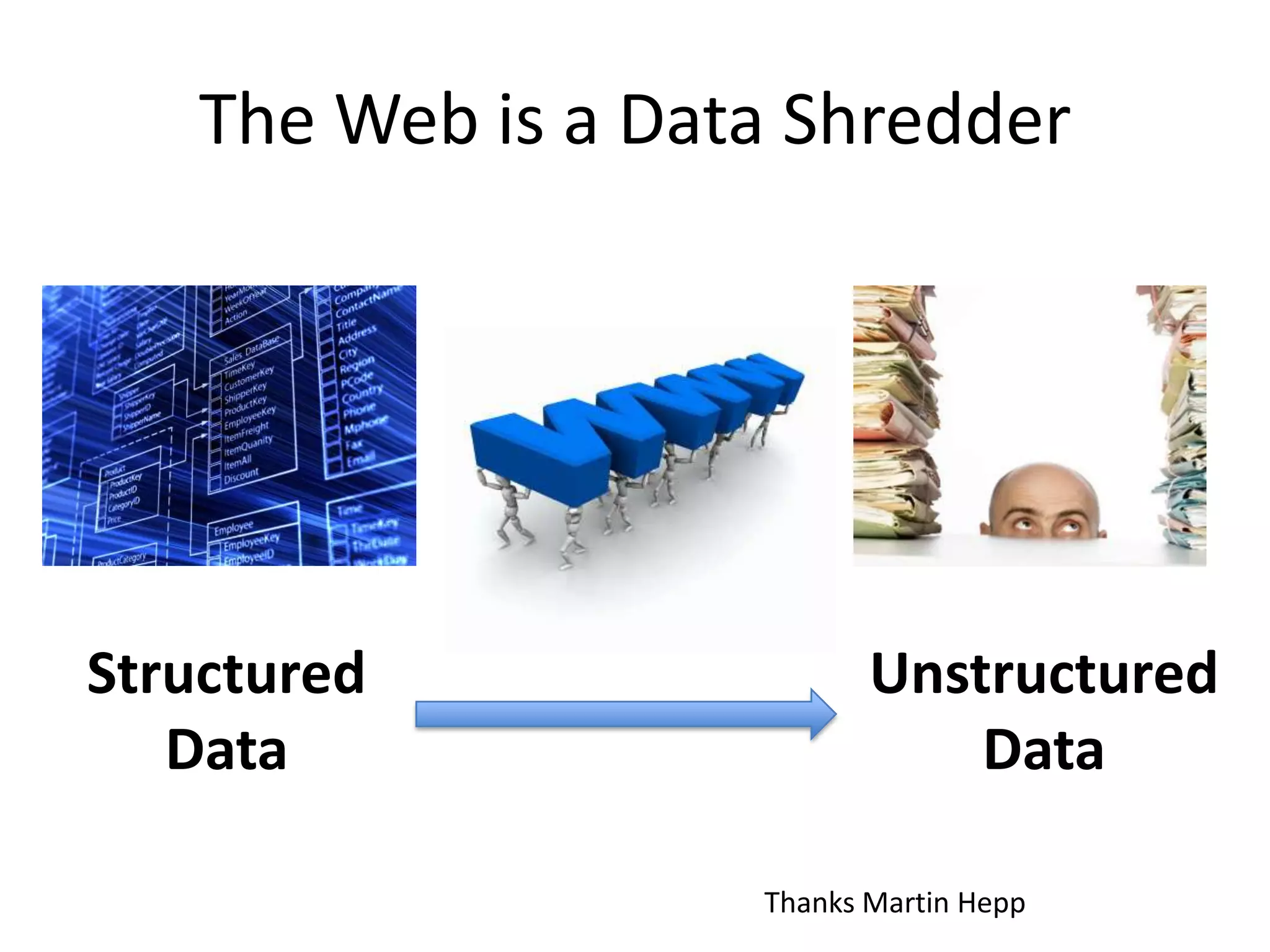

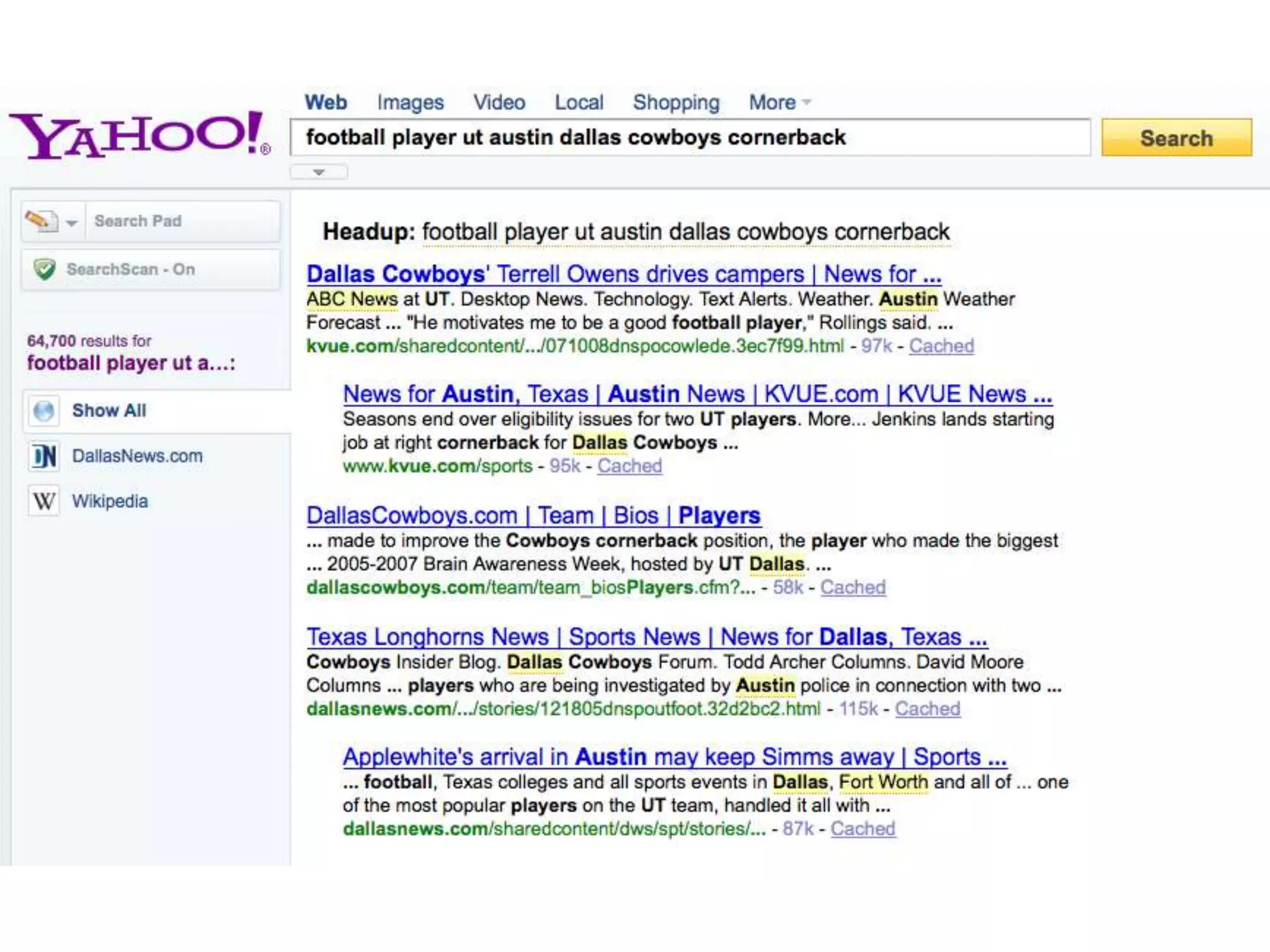

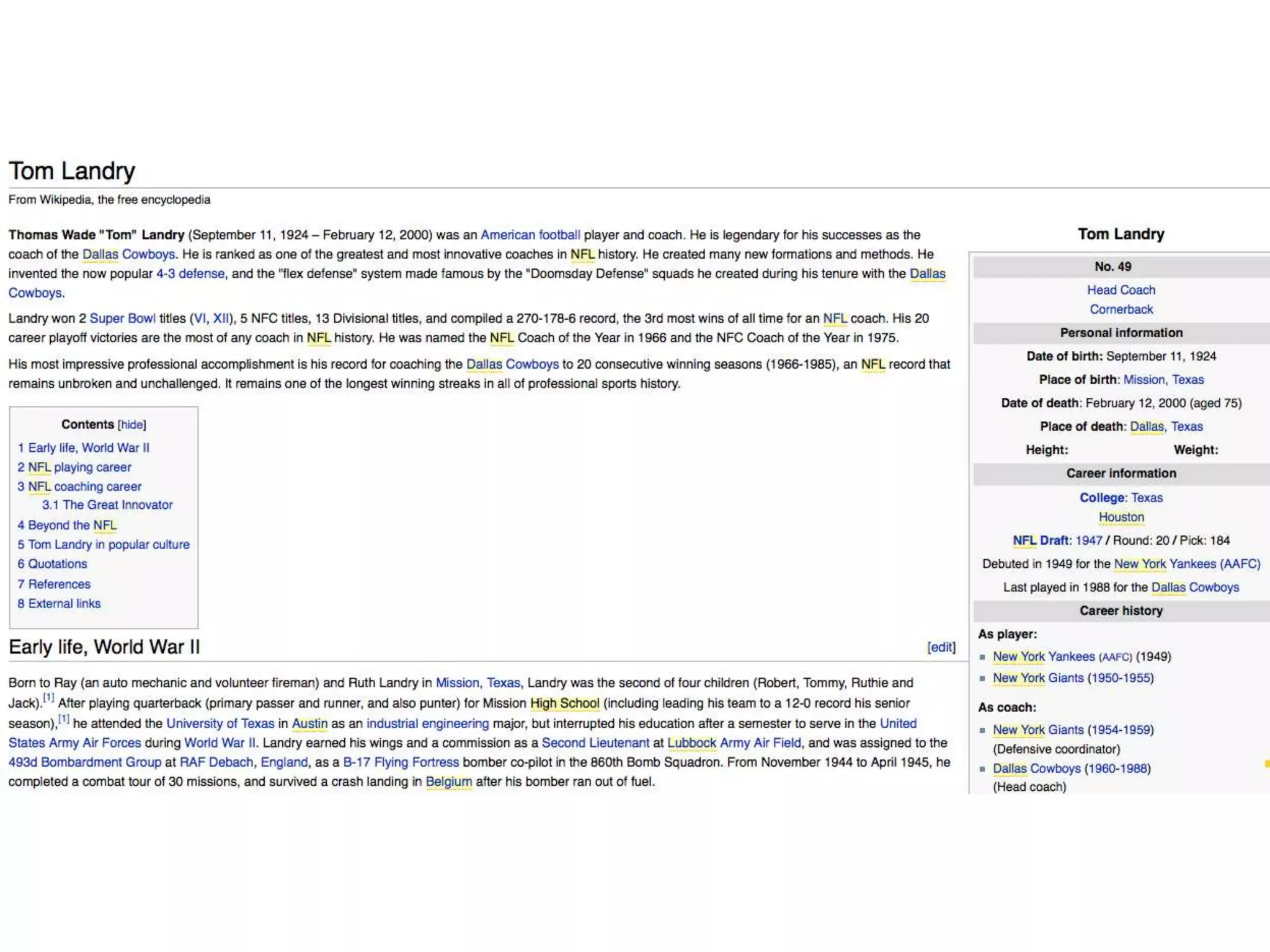
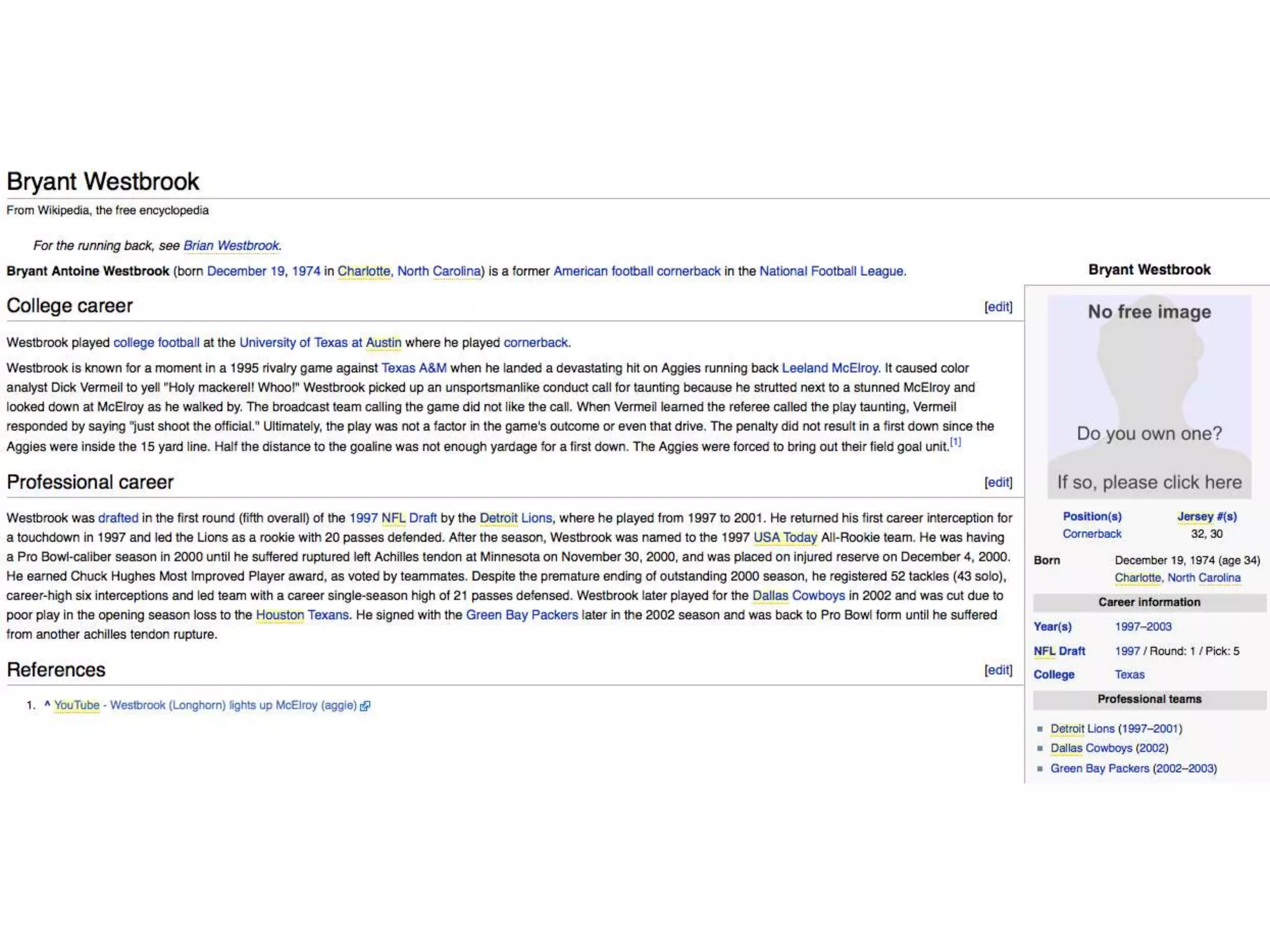










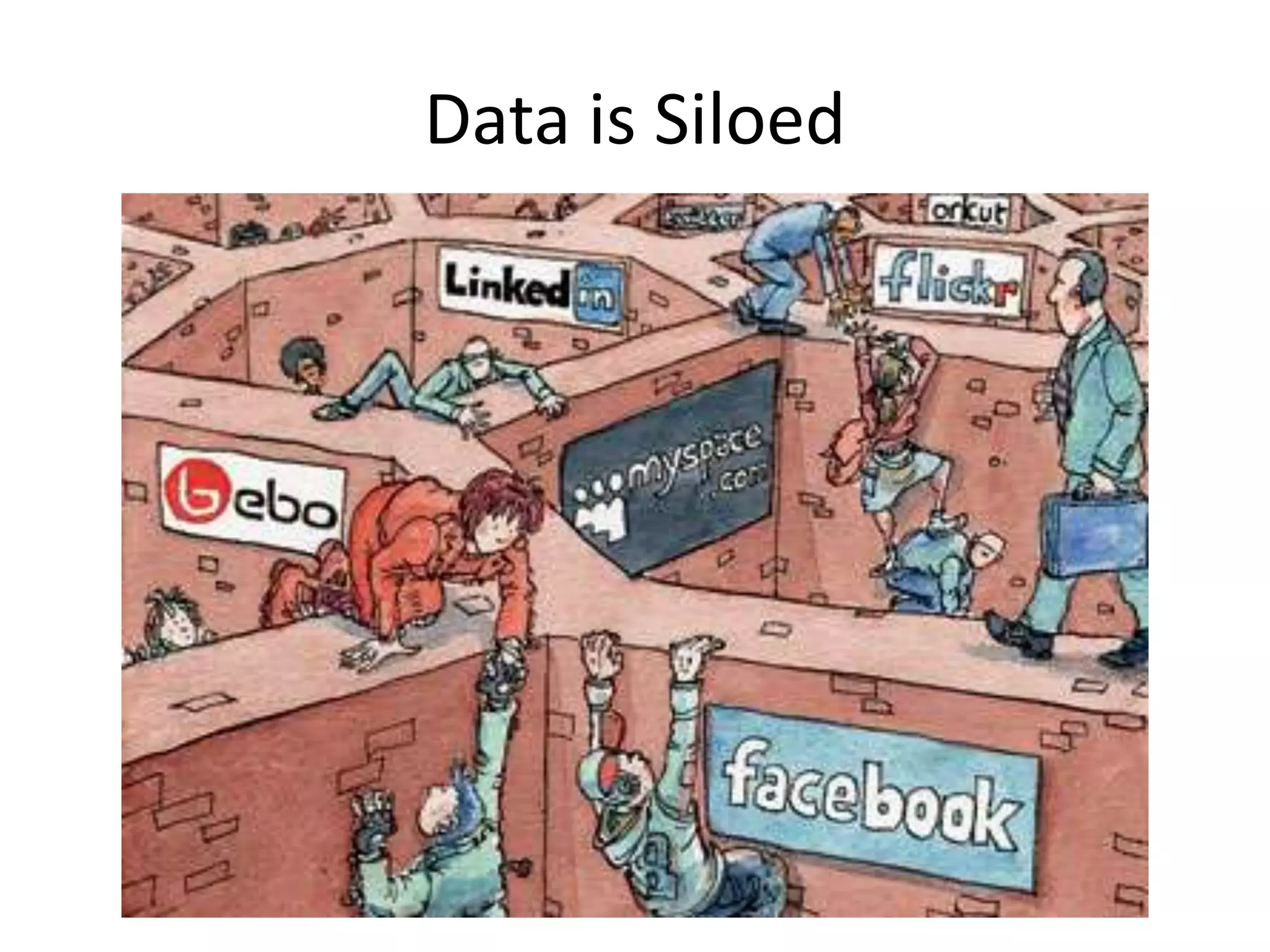











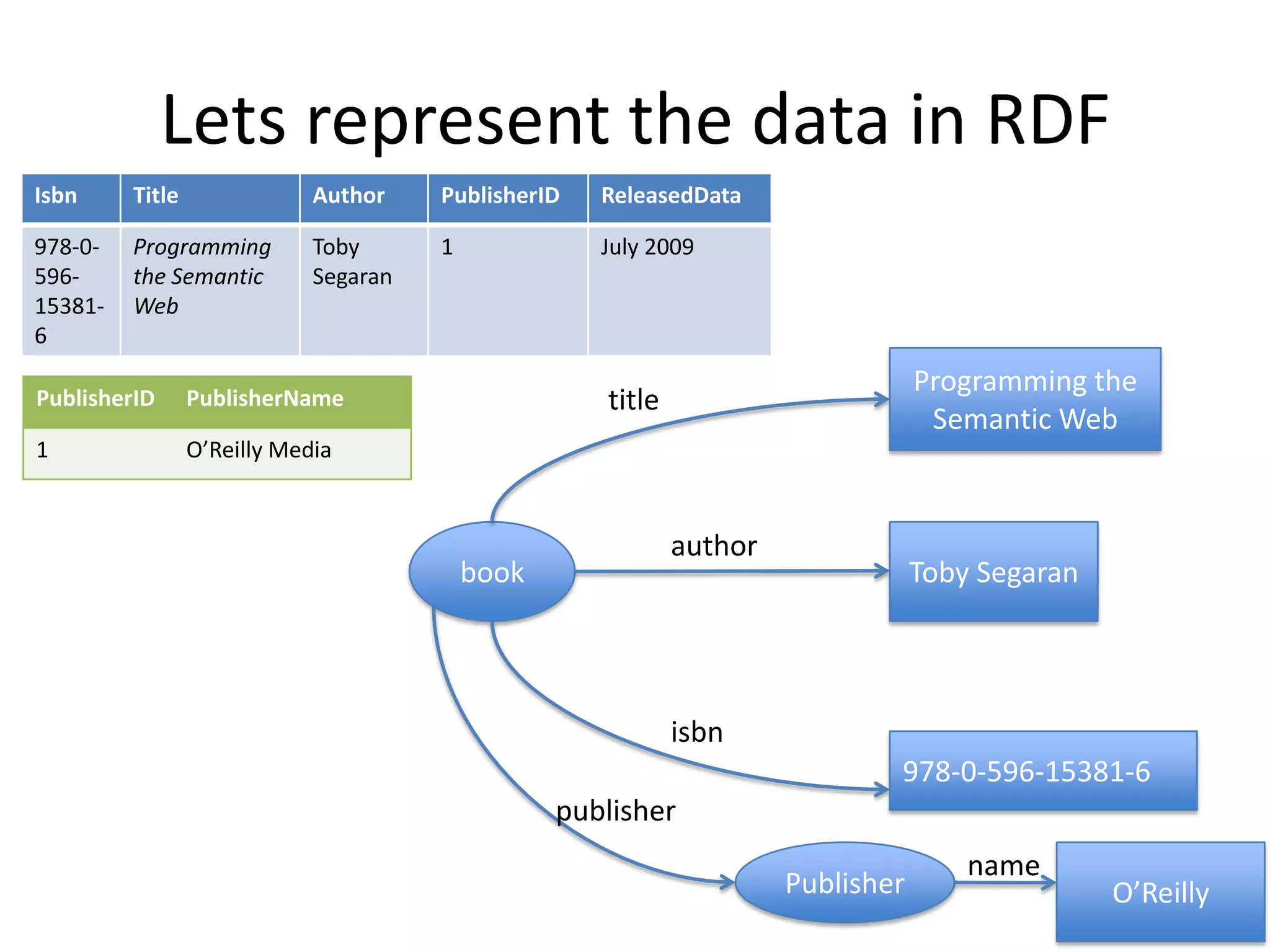

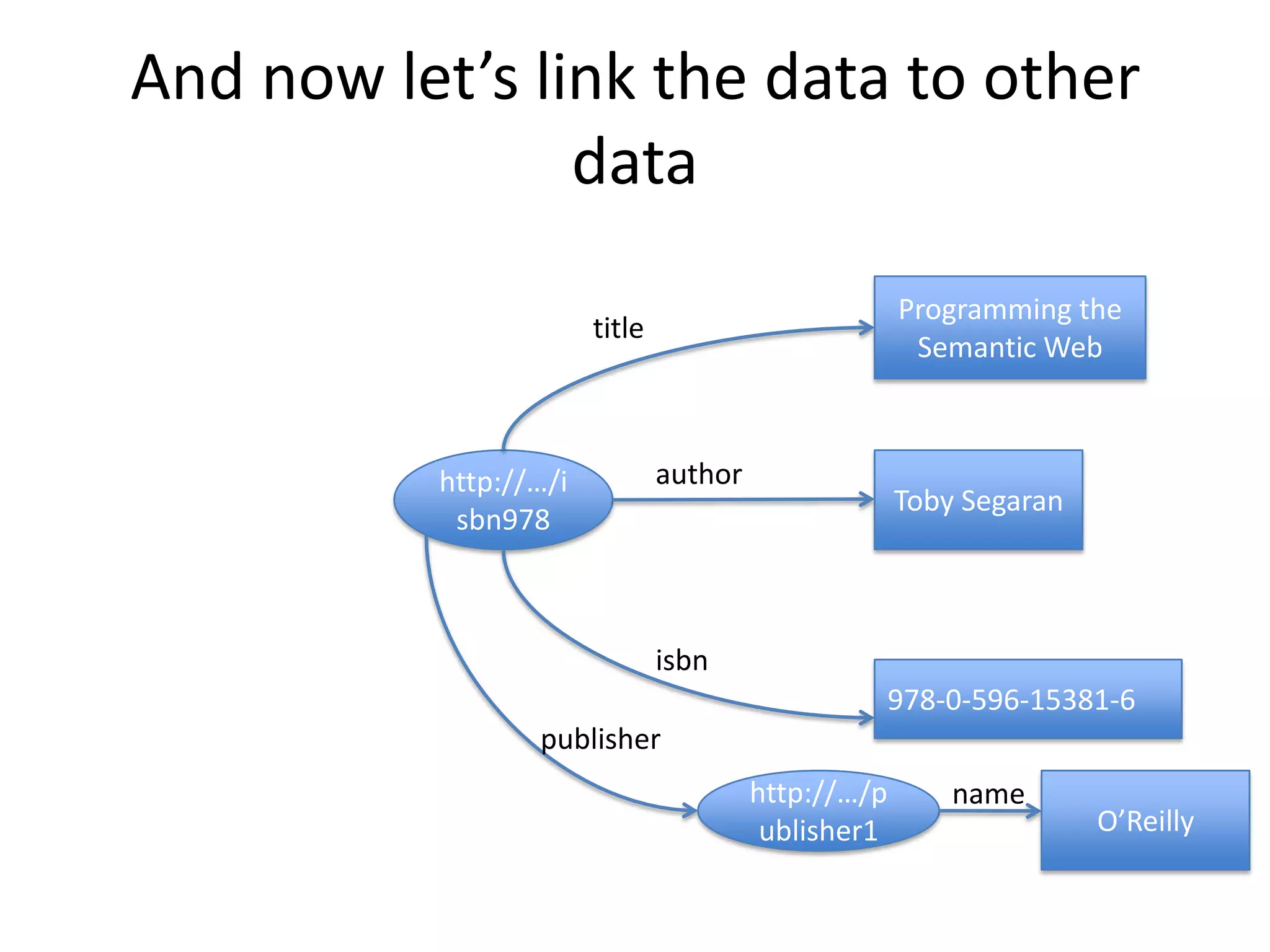
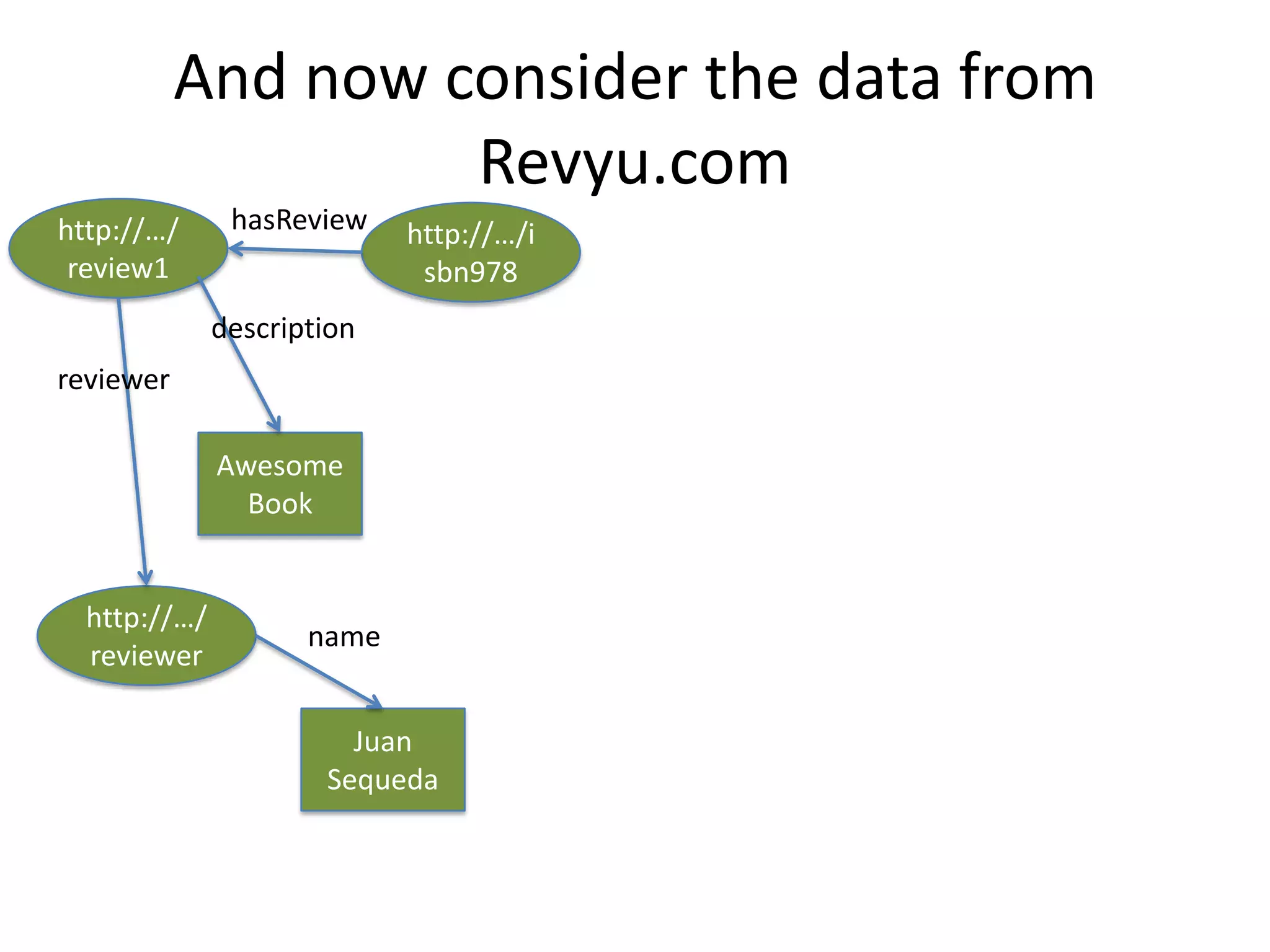
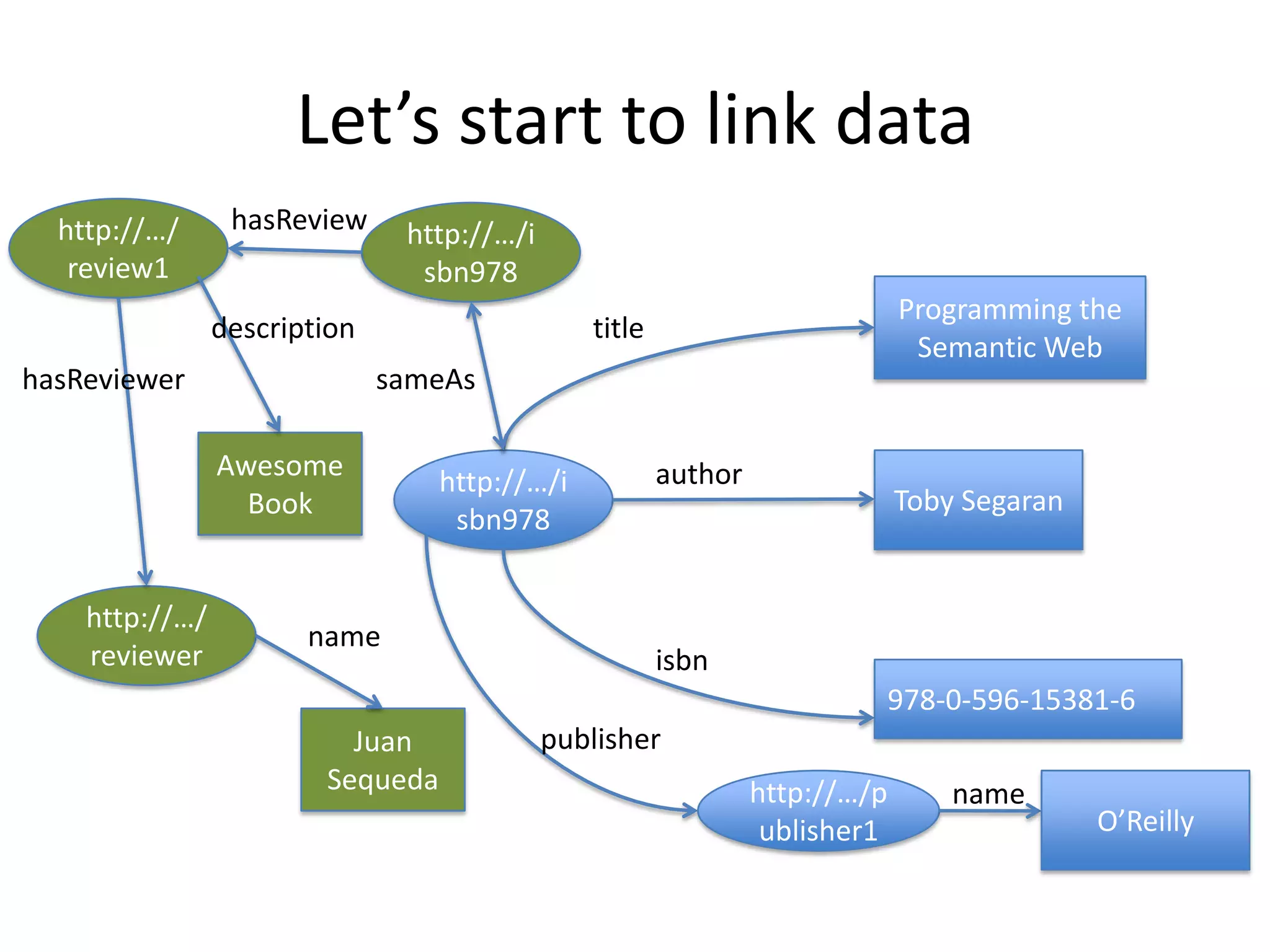

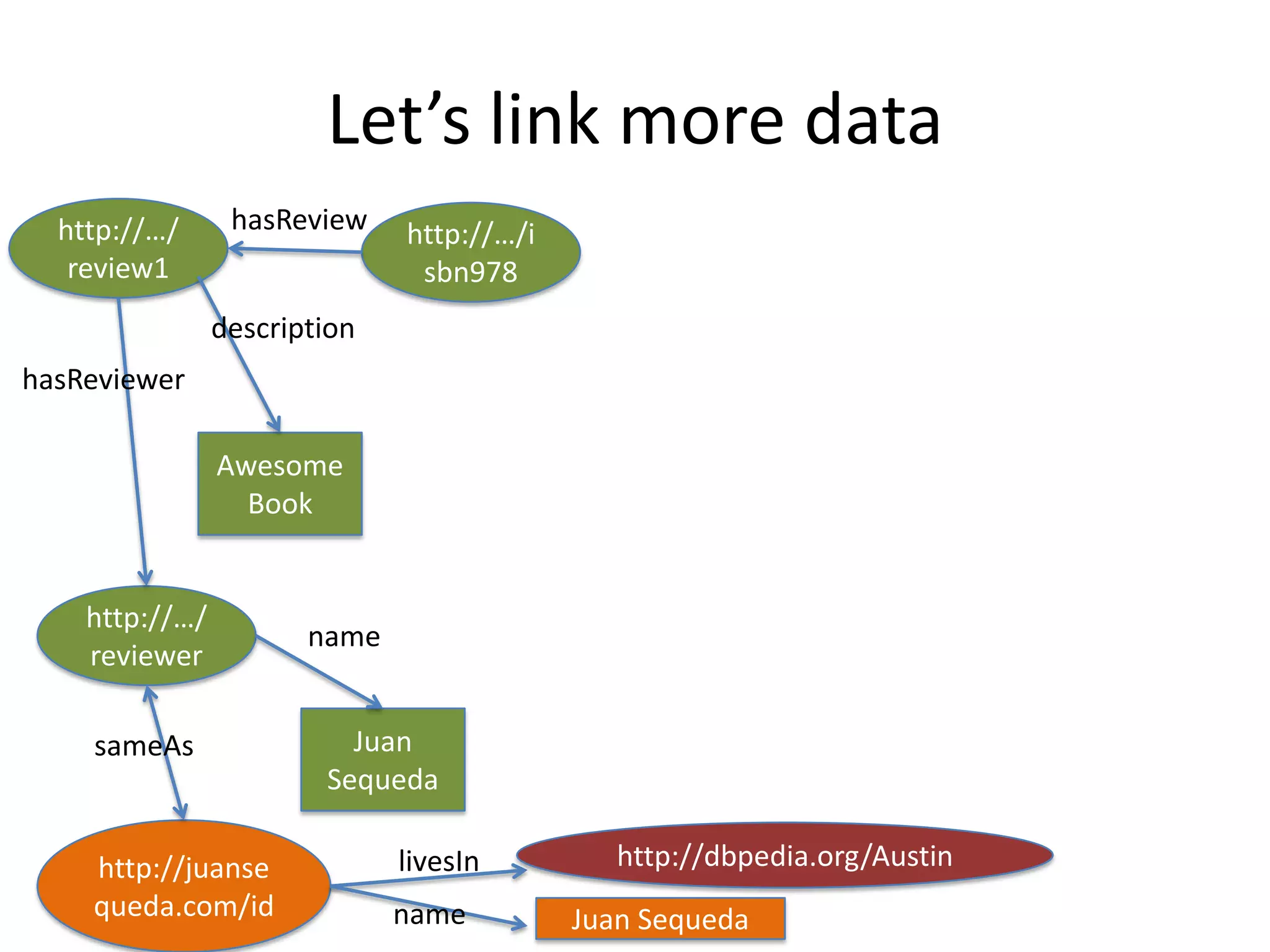
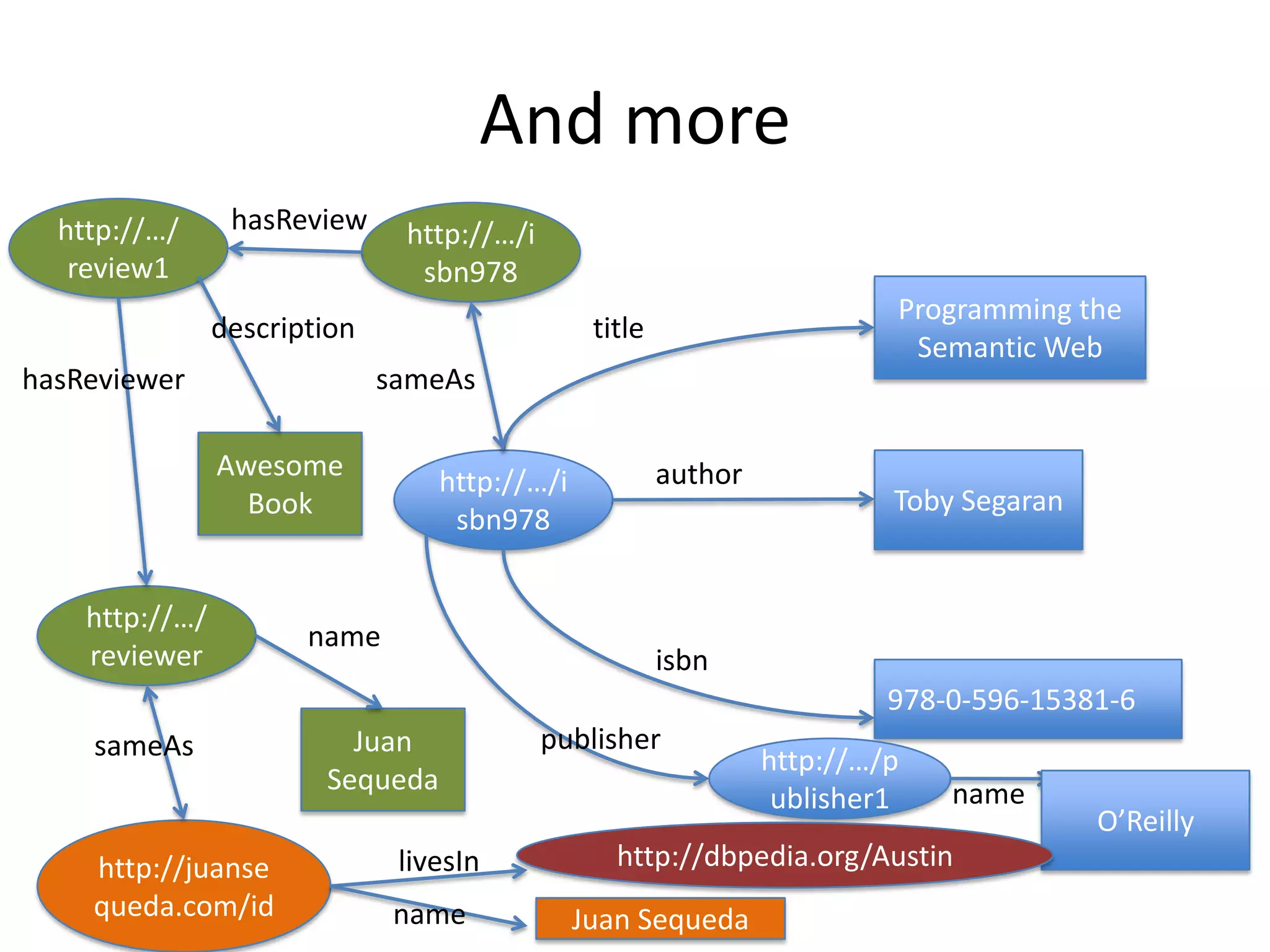







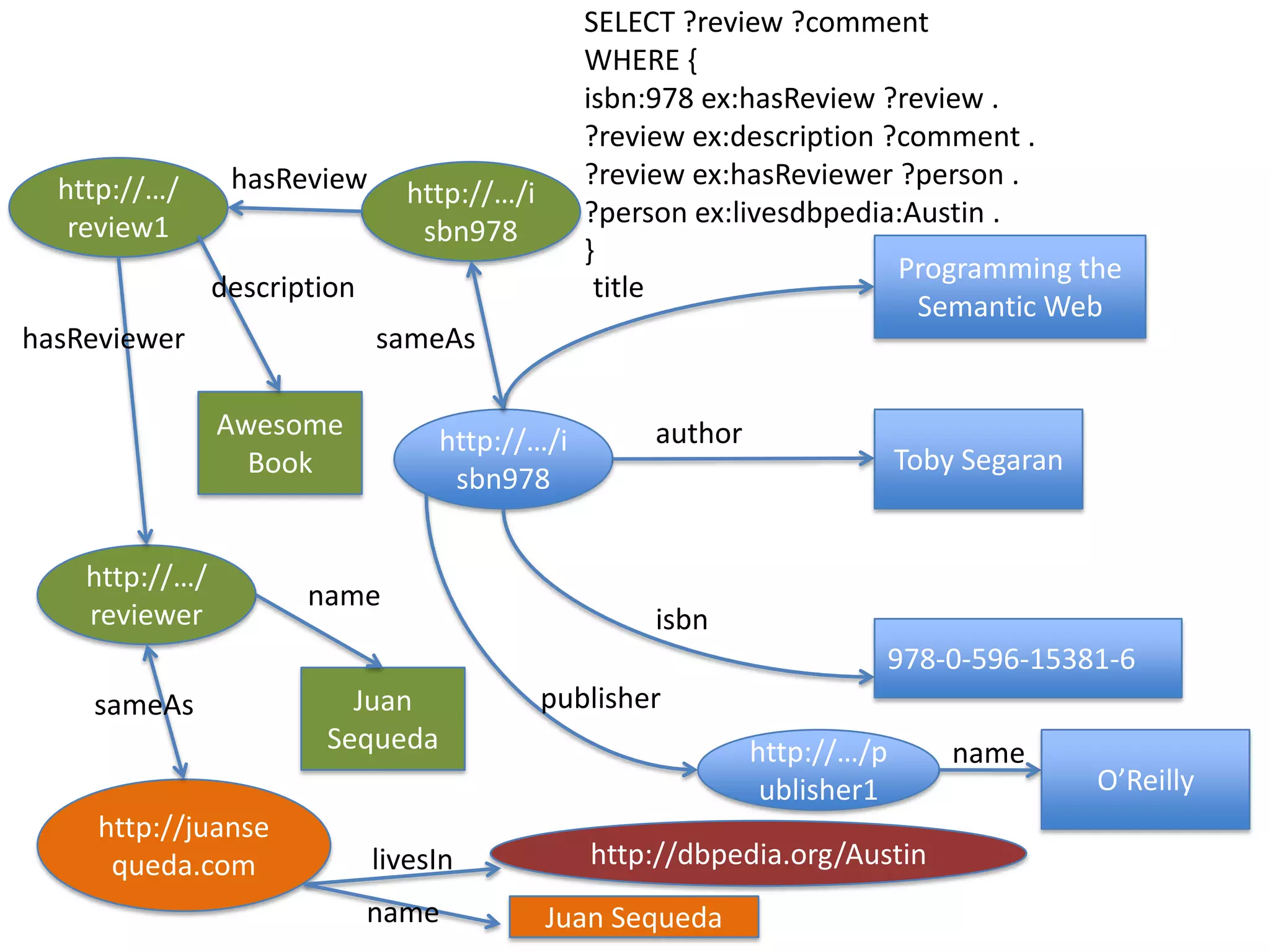






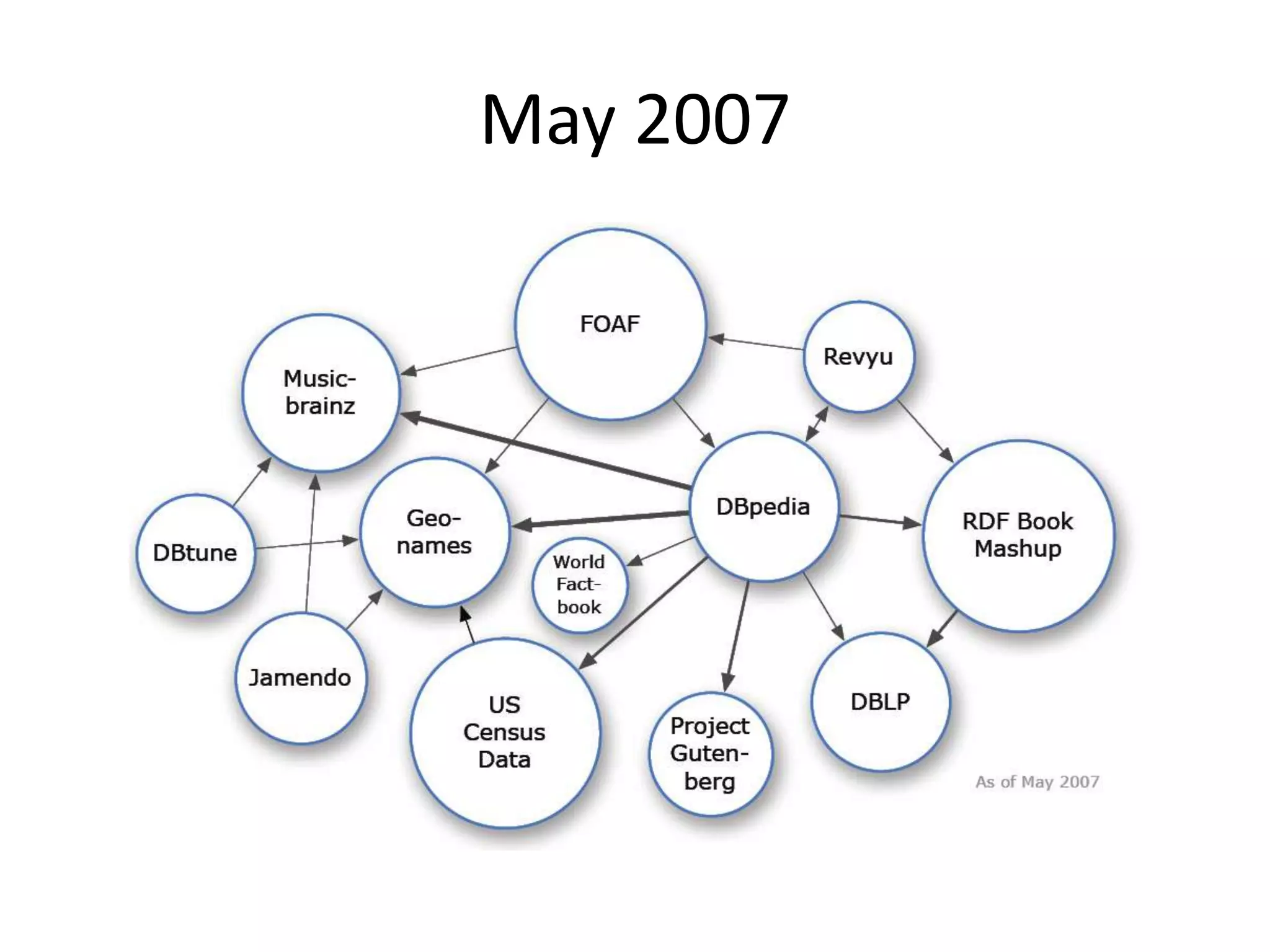
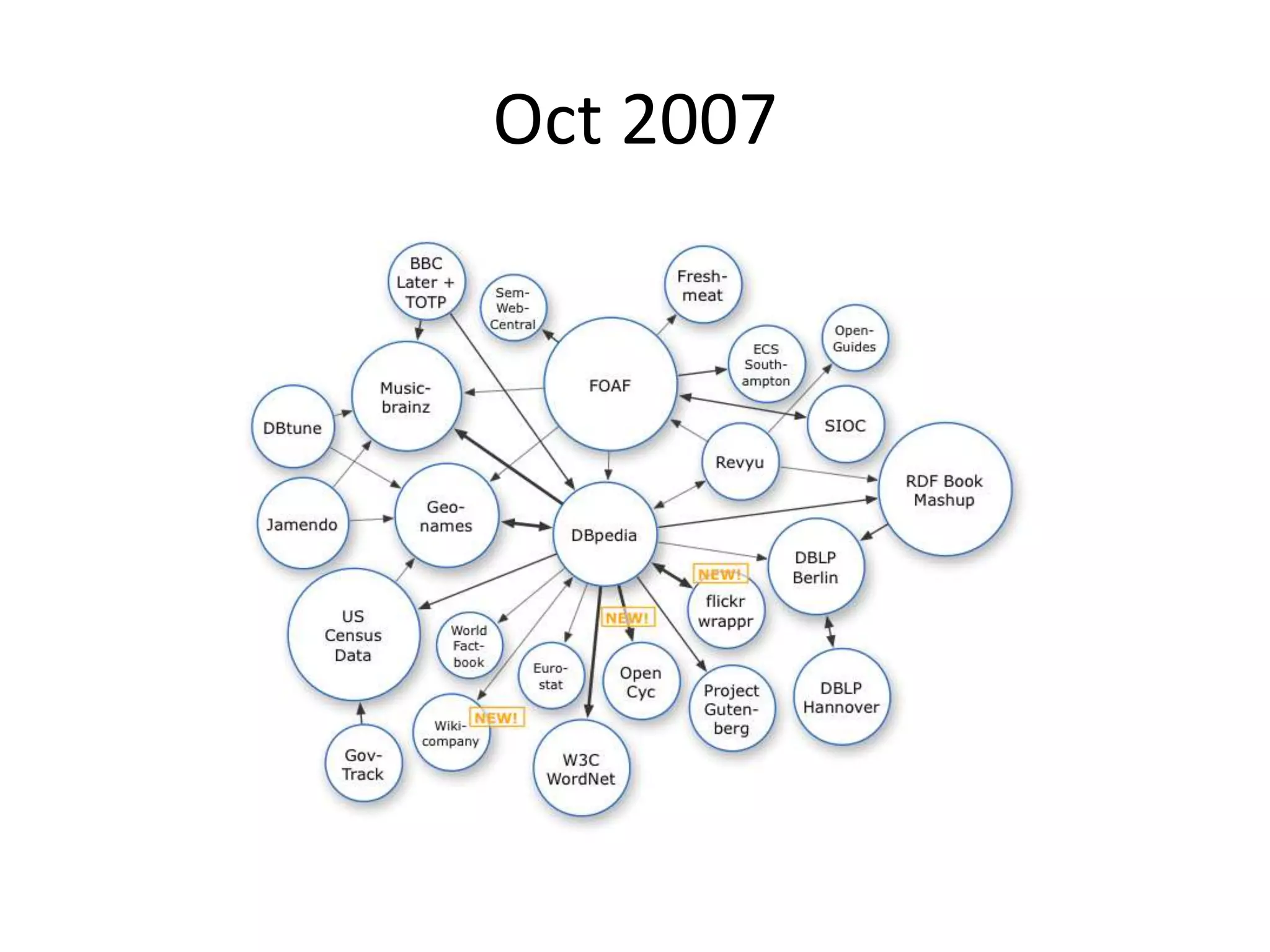
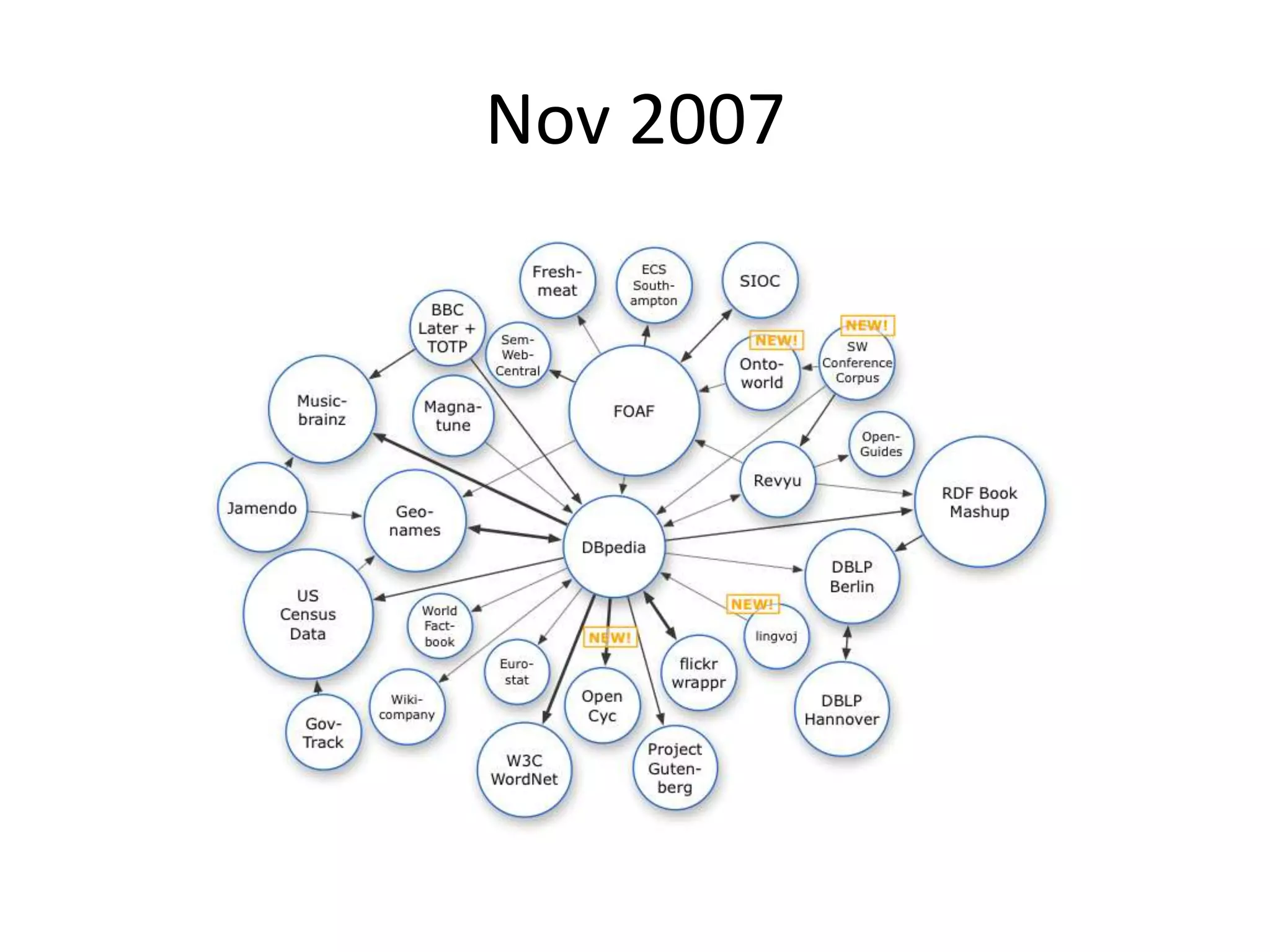
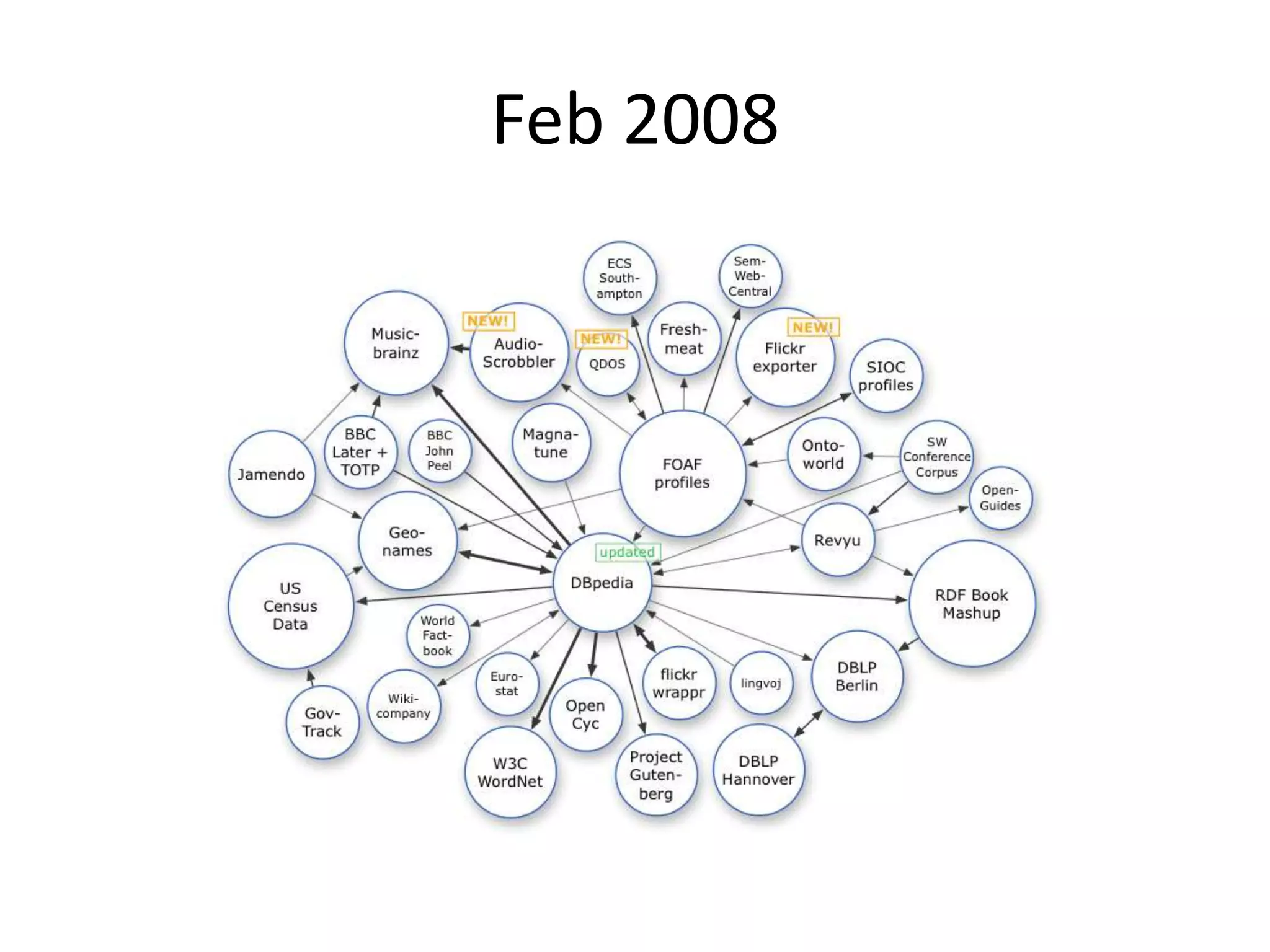
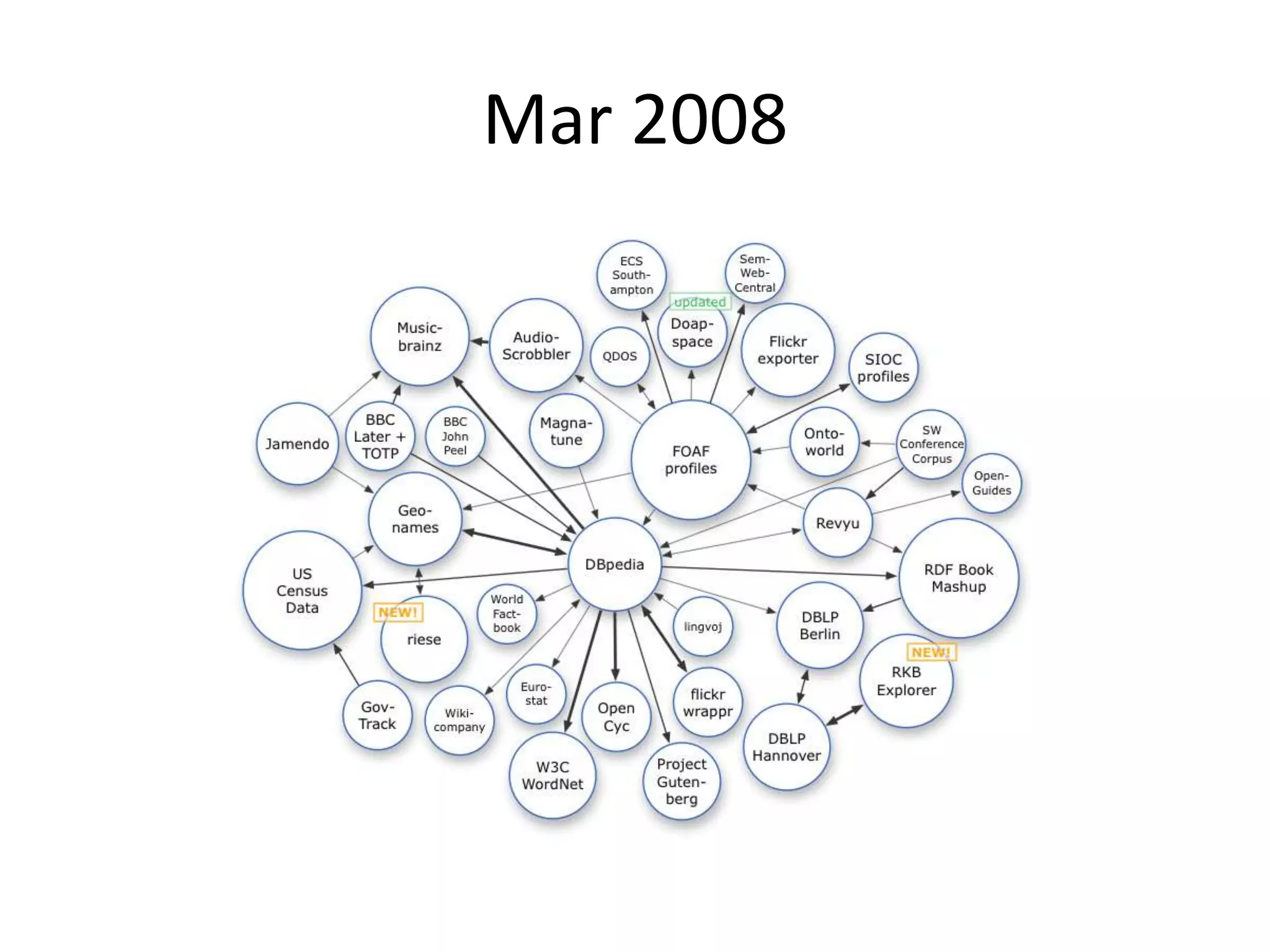
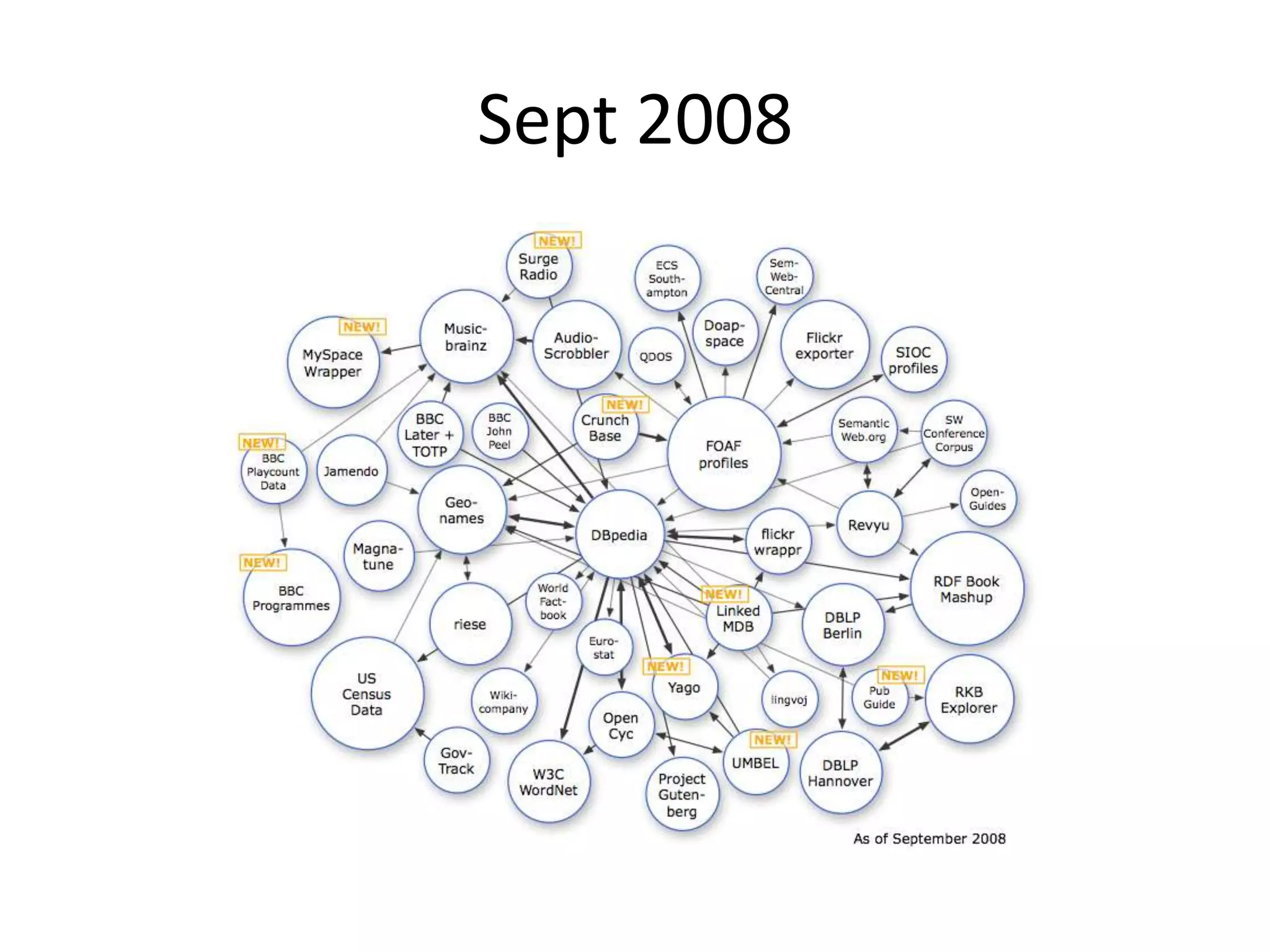

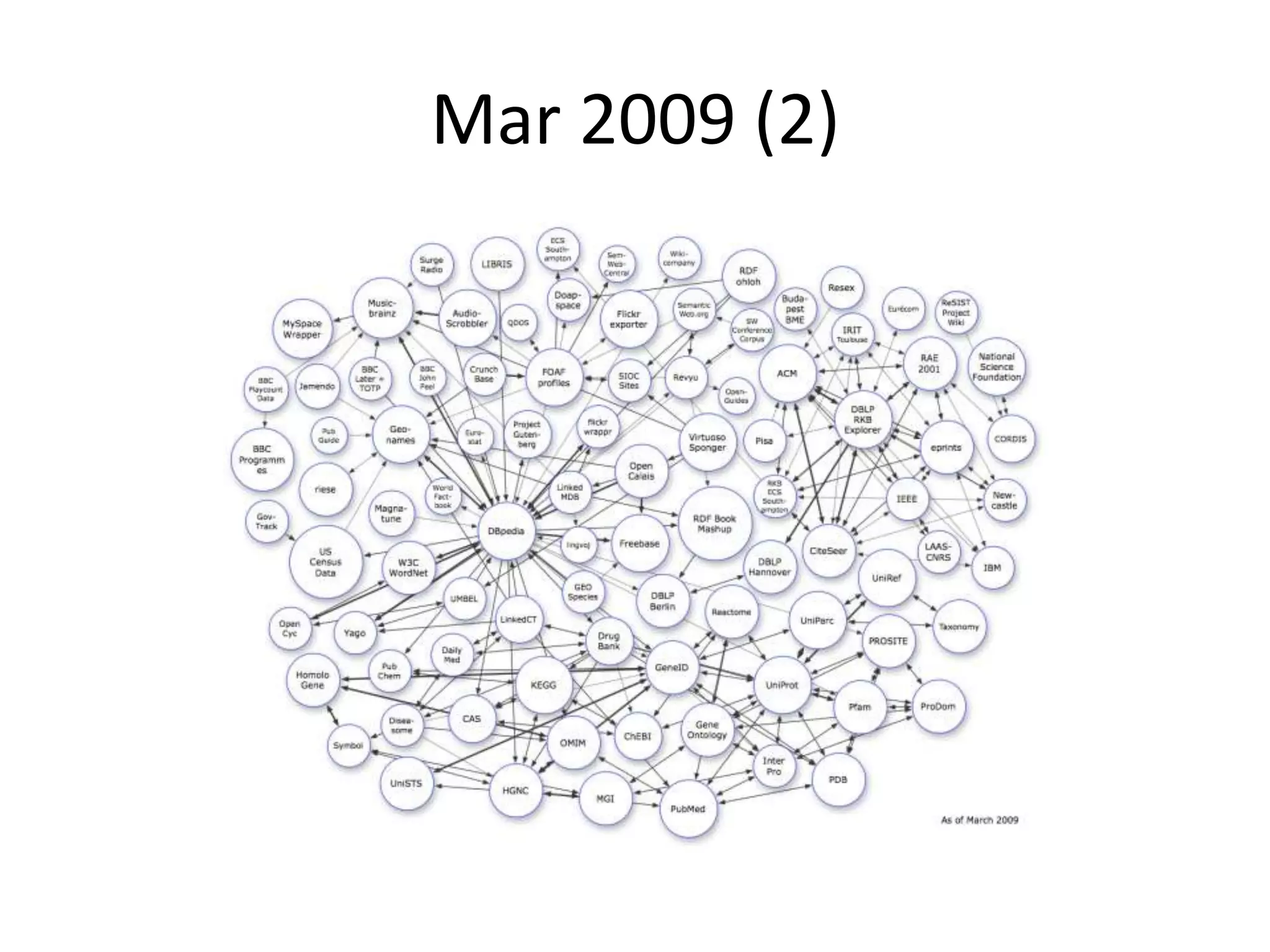

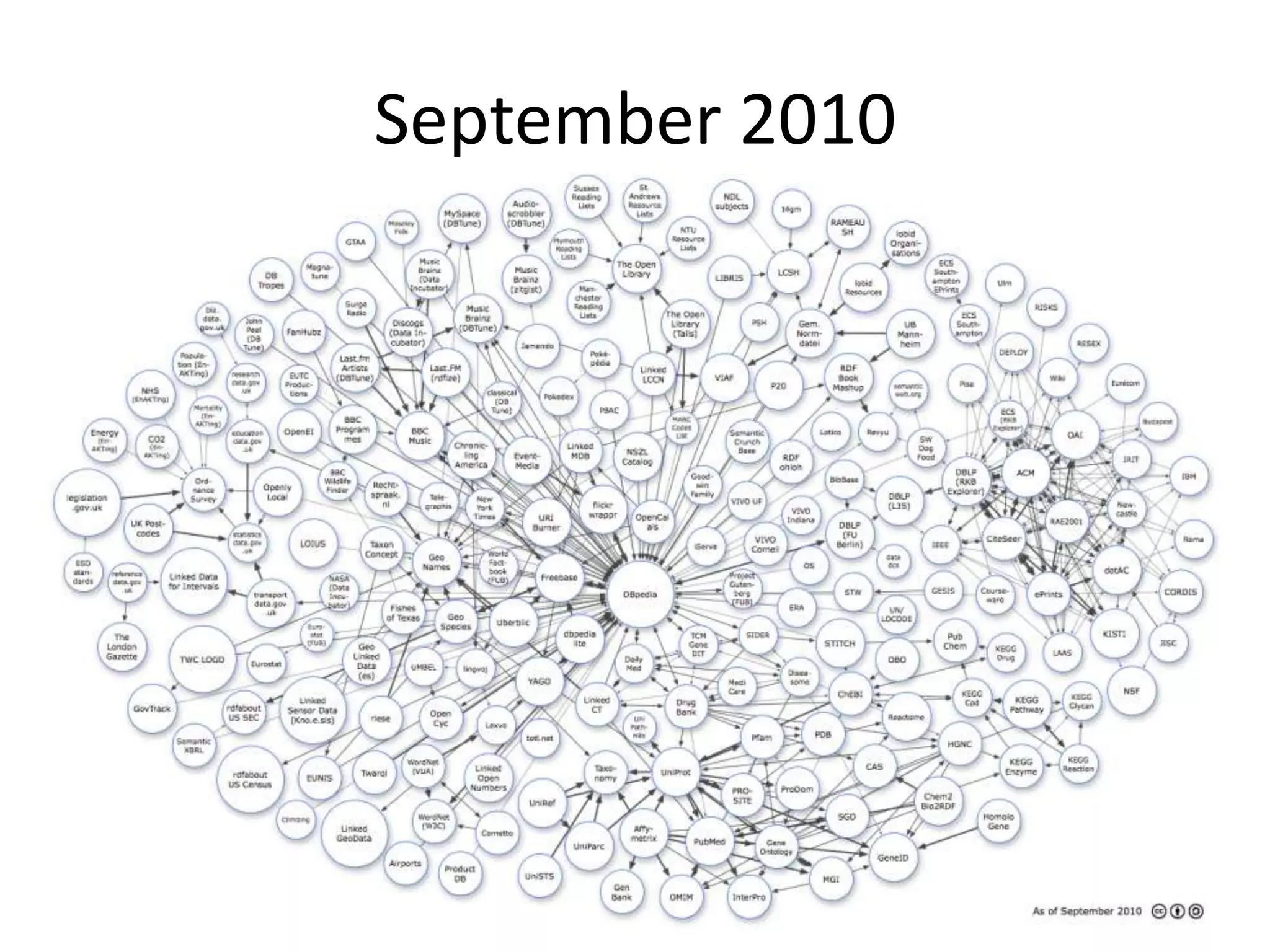



This document provides an introduction to linked data and the semantic web. It discusses how the current web contains documents that are difficult for computers to understand, but linked data publishes structured data on the web using common standards like RDF and URIs. This allows data to be interlinked and queried using SPARQL. Publishing data as linked data makes the web appear as one huge global database. There are now many incentives for organizations to publish their data as linked data, as it enables data sharing and integration in addition to potential benefits like semantic search engine optimization. Linked data is a growing trend with many large organizations and governments now publishing data.










































































































