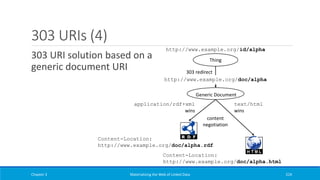
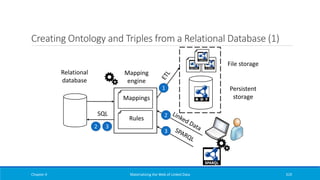
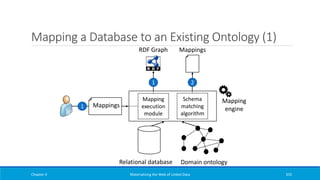
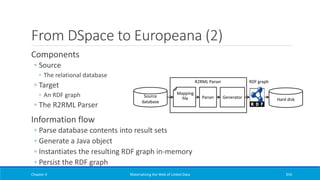
Downloaded 43 times






































































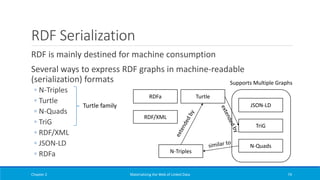
































































![R2RML Example (2)
An R2RML
triples map
Chapter 2 Materializing the Web of Linked Data 141
@prefix rr: <http://www.w3.org/ns/r2rml#>.
@prefix ex: <http://www.example.org/>.
@prefix dc: <http://purl.org/dc/terms/>.
<#TriplesMap1>
rr:logicalTable [ rr:tableName "FILM" ];
rr:subjectMap [
rr:template "http://data.example.org/film/{ID}";
rr:class ex:Movie;
];
rr:predicateObjectMap [
rr:predicate dc:title;
rr:objectMap [ rr:column "Title" ];
];
rr:predicateObjectMap [
rr:predicate ex:releasedIn;
rr:objectMap [ rr:column "Year";
rr:datatype xsd:gYear;];
].](https://image.slidesharecdn.com/mattheweboflindatfullbook-150710163854-lva1-app6891/85/Materializing-the-Web-of-Linked-Data-141-320.jpg)





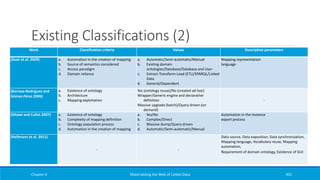
![Foreign Keys (1)
Add another predicate-
object map that operates
on the DIRECTOR relation
Specify the generation of
three RDF triples per row
of the DIRECTOR relation
Chapter 2 Materializing the Web of Linked Data 147
@prefix rr: <http://www.w3.org/ns/r2rml#>.
@prefix ex: <http://www.example.org/>.
@prefix foaf: <http://xmlns.com/foaf/0.1/>.
<#TriplesMap2>
rr:logicalTable [ rr:tableName "DIRECTOR" ];
rr:subjectMap [
rr:template "http://data.example.org/director/{ID}";
rr:class ex:Director;
];
rr:predicateObjectMap [
rr:predicate foaf:name;
rr:objectMap [ rr:column "Name" ];
];
rr:predicateObjectMap [
rr:predicate ex:bornIn;
rr:objectMap [ rr:column "BirthYear";
rr:datatype xsd:gYear;];
].](https://image.slidesharecdn.com/mattheweboflindatfullbook-150710163854-lva1-app6891/85/Materializing-the-Web-of-Linked-Data-147-320.jpg)
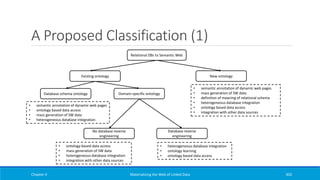
![Foreign Keys (2)
Add another predicate-object
map, the referencing object
map
Link entities described in
separate tables
Exploit the foreign key
relationship of FILM.Director
and DIRECTOR.ID
Chapter 2 Materializing the Web of Linked Data 148
<#TriplesMap1>
rr:logicalTable [ rr:tableName "FILM" ];
rr:subjectMap [
rr:template "http://data.example.org/film/{ID}";
rr:class ex:Movie;
];
rr:predicateObjectMap [
rr:predicate dc:title;
rr:objectMap [ rr:column "Title" ];
];
rr:predicateObjectMap [
rr:predicate ex:releasedIn;
rr:objectMap [ rr:column "Year";
rr:datatype xsd:gYear;];
rr:predicateObjectMap[
rr:predicate ex:directedBy;
rr:objectMap[
rr:parentTriplesMap <#TriplesMap2>;
rr:joinCondition[
rr:child "Director";
rr:parent "ID";
];
];
].](https://image.slidesharecdn.com/mattheweboflindatfullbook-150710163854-lva1-app6891/85/Materializing-the-Web-of-Linked-Data-148-320.jpg)


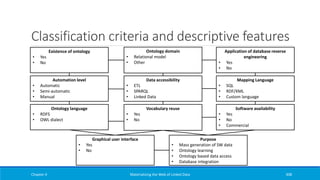
![Custom Views (1)
R2RML view defined via the
rr:sqlQuery property
Used just as the native logical
tables
Could also have been defined as
an SQL view in the underlying
database system
◦ Not always feasible/desirable
Produced result set must not
contain columns with the same
name
Chapter 2 Materializing the Web of Linked Data 151
@prefix rr: <http://www.w3.org/ns/r2rml#>.
@prefix ex: <http://www.example.org/>.
@prefix dc: <http://purl.org/dc/terms/>.
<#TriplesMap3>
rr:logicalTable [ rr:sqlQuery """
SELECT ACTOR.ID AS ActorId, ACTOR.Name AS
ActorName, ACTOR.BirthYear AS ActorBirth, FILM.ID AS FilmId FROM
ACTOR, FILM, FILM2ACTOR WHERE FILM.ID=FILM2ACTOR.FilmID AND
ACTOR.ID=FILM2ACTOR.ActorID; """];
rr:subjectMap [
rr:template "http://data.example.org/actor/{ActorId}";
rr:class ex:Actor;
];
rr:predicateObjectMap [
rr:predicate foaf:name;
rr:objectMap [ rr:column "ActorName" ];
];
rr:predicateObjectMap [
rr:predicate ex:bornIn;
rr:objectMap [ rr:column "ActorBirth";
rr:datatype xsd:gYear;];
].
rr:predicateObjectMap [
rr:predicate ex:starsIn;
rr:objectMap [ rr:template
"http://data.example.org/film/{ID}";
];
].](https://image.slidesharecdn.com/mattheweboflindatfullbook-150710163854-lva1-app6891/85/Materializing-the-Web-of-Linked-Data-151-320.jpg)




































































































































































![The Basic Approach (2)
Rules:
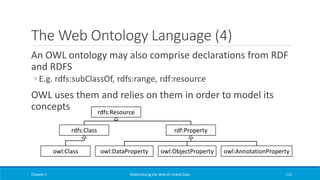
(a) Every relation R maps to an RDFS class C(R)
(b) Every tuple of a relation R maps to an RDF node of type C(R)
(c) Every attribute att of a relation maps to an RDF property P(att)
(d) For every tuple R[t], the value of an attribute att maps to a
value of the property P(att) for the node corresponding to the
tuple R[t]
Chapter 4 Materializing the Web of Linked Data 322](https://image.slidesharecdn.com/mattheweboflindatfullbook-150710163854-lva1-app6891/85/Materializing-the-Web-of-Linked-Data-322-320.jpg)





























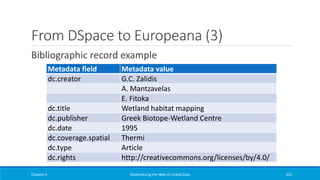

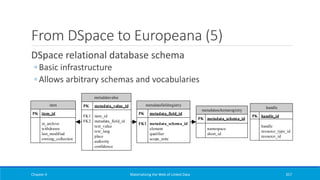

![From DSpace to Europeana (7)
Chapter 4 Materializing the Web of Linked Data 359
map:dc-coverage-spatial
rr:logicalTable <#dc-coverage-spatial-view>;
rr:subjectMap [
rr:template
'http://www.example.org/handle/{"handle"}';
];
rr:predicateObjectMap [
rr:predicate dcterms:spatial;
rr:objectMap [
rr:template
'http://www.example.org/spatial_terms#{"text_value"}';
rr:termType rr:IRI
];
].
<#dc-coverage-spatial-view>
rr:sqlQuery """
SELECT h.handle AS handle, mv.text_value AS
text_value
FROM handle AS h, item AS i, metadatavalue AS mv,
metadataschemaregistry AS msr, metadatafieldregistry
AS mfr WHERE
i.in_archive=TRUE AND h.resource_id=i.item_id AND
h.resource_type_id=2 AND
msr.metadata_schema_id=mfr.metadata_schema_id AND
mfr.metadata_field_id=mv.metadata_field_id AND
mv.text_value is not null AND i.item_id=mv.item_id
AND
msr.namespace='http://dublincore.org/documents/dcmi-
terms/'
AND mfr.element='coverage' AND
mfr.qualifier='spatial'
""".
R2RML mapping](https://image.slidesharecdn.com/mattheweboflindatfullbook-150710163854-lva1-app6891/85/Materializing-the-Web-of-Linked-Data-359-320.jpg)
























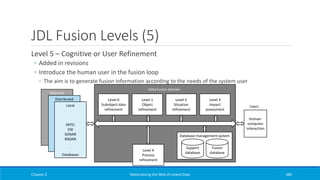

































![Rule-based Reasoning in Jena (2)
Forward chain rules (body → head)
◦ When the body is true, then the head is also true
Built-in rule files of the form:
Symmetric and transitive properties in OWL:
Chapter 5 Materializing the Web of Linked Data 418
[symmetricProperty1: (?P rdf:type owl:SymmetricProperty), (?X ?P ?Y) -> (?Y ?P ?X)]
[transitivePropery1: (?P rdf:type owl:TransitiveProperty), (?A ?P ?B), (?B ?P ?C) -> (?A ?P ?C)]
[rdfs5a: (?a rdfs:subPropertyOf ?b), (?b rdfs:subPropertyOf ?c) -> (?a rdfs:subPropertyOf ?c)]](https://image.slidesharecdn.com/mattheweboflindatfullbook-150710163854-lva1-app6891/85/Materializing-the-Web-of-Linked-Data-418-320.jpg)














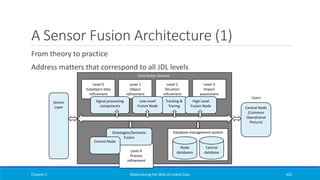














































The book 'Materializing the Web of Linked Data' by Nikolaos Konstantinou and Dimitrios-Emmanuel Spanos explores the interconnectedness and methodologies of linked data within the semantic web framework. It discusses the importance of semantics for improving information management, data integration, and interoperability across diverse systems. The content covers technical backgrounds, tools for deploying linked data, and methodologies for generating linked data from various sources, emphasizing the creation and use of ontologies.





























































































