Downloaded 101 times




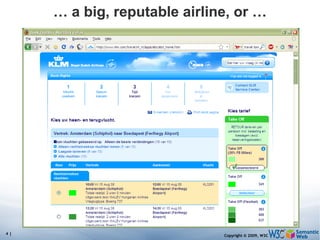


























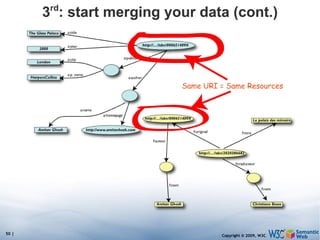




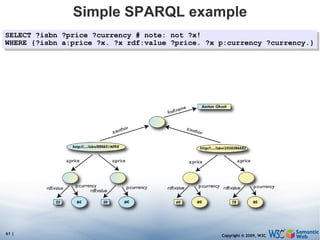
![Simple SPARQL example Returns: [[<..49X>,33,£], [<..49X>,50,€], [<..6682>,60,€], [<..6682>,78,$]] SELECT ?isbn ?price ?currency # note: not ?x! WHERE {?isbn a:price ?x. ?x rdf:value ?price. ?x p:currency ?currency.}](https://image.slidesharecdn.com/swintroslides-090330063220-phpapp01/85/Semantic-Web-Introduction-62-320.jpg)
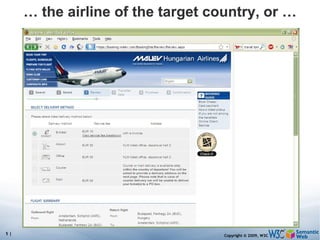
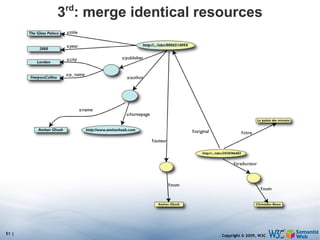
![Pattern constraints SELECT ?isbn ?price ?currency # note: not ?x! WHERE { ?isbn a:price ?x. ?x rdf:value ?price. ?x p:currency ?currency. FILTER(?currency == € } Returns: [[<..409X>,50,€], [<..6682>,60,€]]](https://image.slidesharecdn.com/swintroslides-090330063220-phpapp01/85/Semantic-Web-Introduction-63-320.jpg)













![Thanks! http://www.pleso.net/ [email_address] Credits: * 2009-01-15, What is the Semantic Web? (in 15 minutes), Ivan Herman, ISOC New Years Reception in Amsterdam, the Netherlands * 2008-09-24, Introduction to the Semantic Web (tutorial) Ivan Herman, 2nd European Semantic Technology Conference in Vienna, Austria * ReadWriteWeb - Web Technology Trends for 2008 and Beyond (http://www.readwriteweb.com/), 10 best semantic applications * Microformats (http://microformats.org/)](https://image.slidesharecdn.com/swintroslides-090330063220-phpapp01/85/Semantic-Web-Introduction-84-320.jpg)

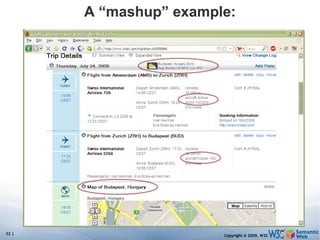
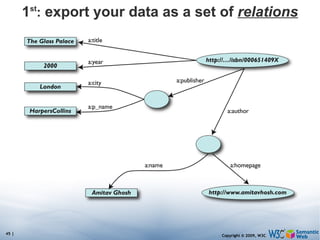
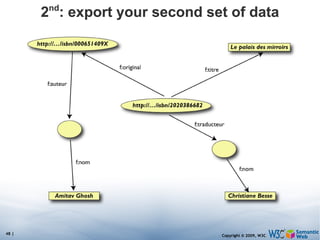
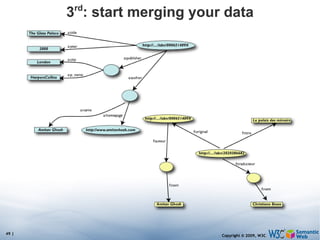
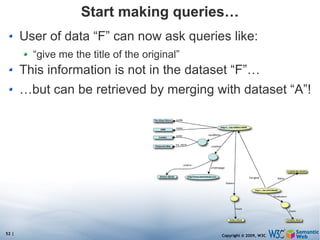
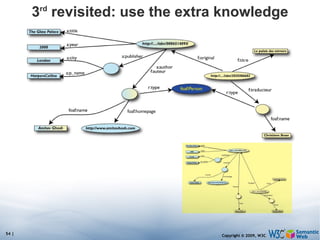
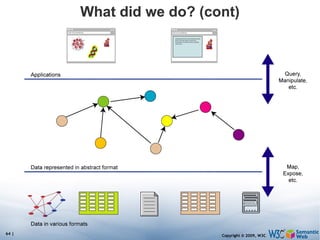
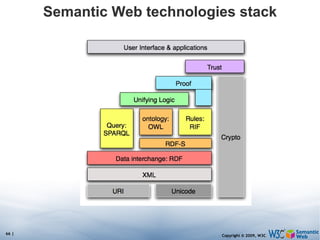
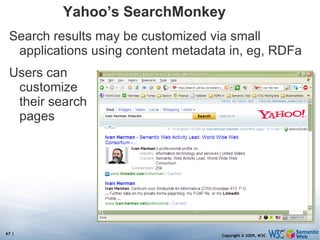
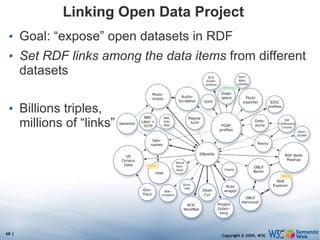
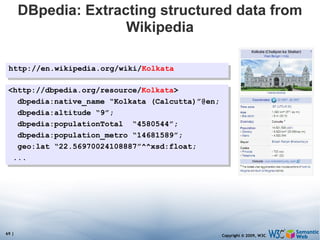
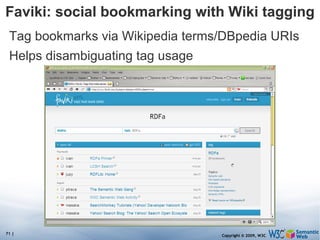
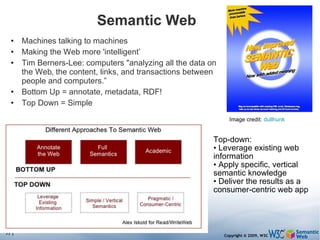
The document discusses the Semantic Web and its potential to make web data more accessible and useful for machines. It describes how the Semantic Web aims to standardize how data is published and linked on the web so that machines can more easily interpret and combine data from different sources. Examples are given of early applications that demonstrate aspects of this vision, like semantic search engines, linked open data projects, and microformats for annotating web pages.

















































































