Download as PDF, PPTX



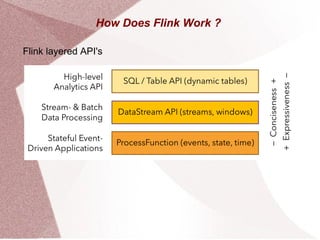



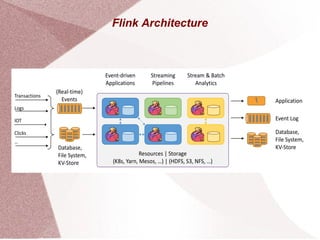

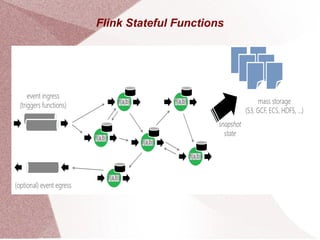

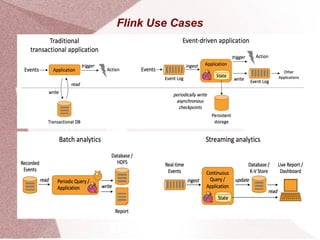
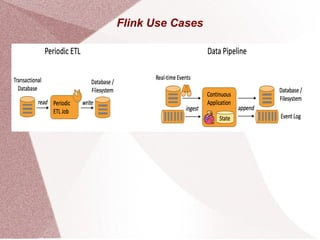



Apache Flink is an open-source stream processing framework designed for high-volume, low-latency batch and stream processing, written in Java and Scala. It supports multiple data sources and provides powerful APIs for event processing, state management, and analytics, along with libraries for complex event processing and graph analysis. Flink is deployable on various cluster managers and is tailored for applications such as fraud detection, data analytics, and real-time data pipelines.






















































































