Download to read offline








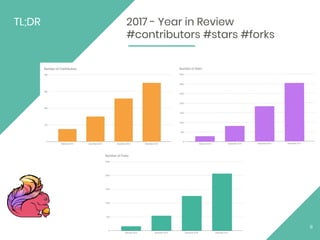
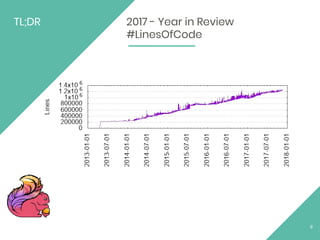









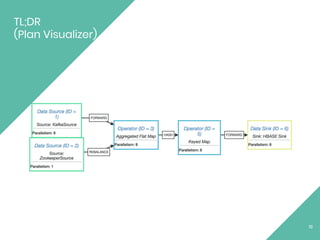
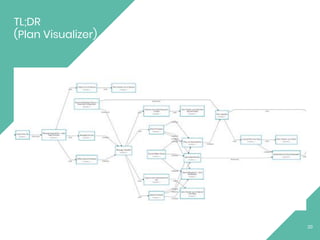


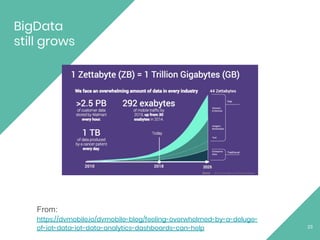
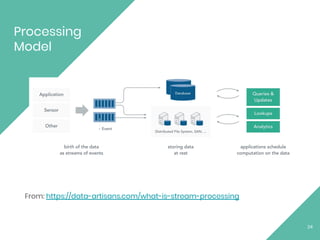
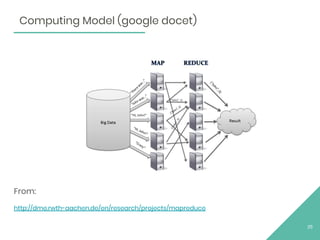
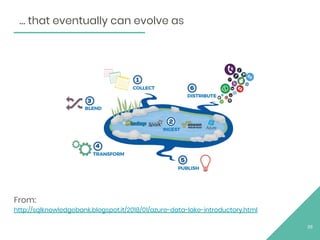
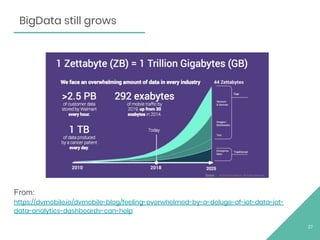



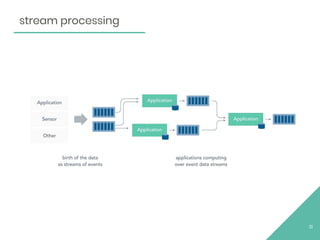
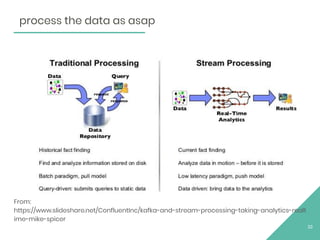



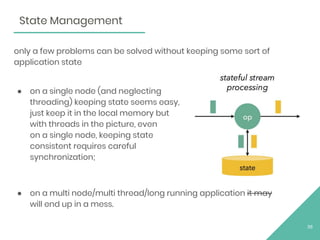
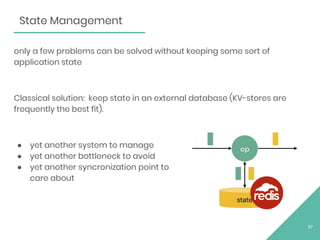
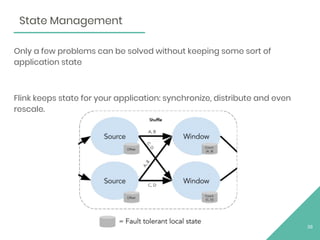
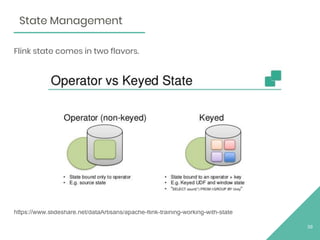


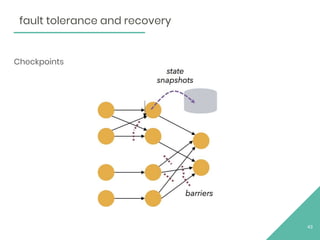


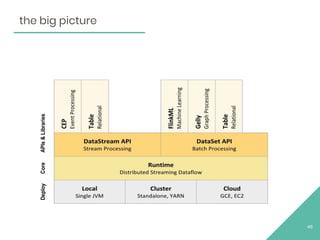




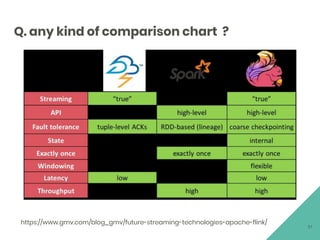

This document provides an overview of Apache Flink, an open source stream processing framework. It discusses Flink's core streaming dataflow engine, written in Java and Scala. It also covers some of Flink's main features, including native stream processing, low latency, high throughput, stateful computations, exactly-once guarantees, and distributed and scalable execution across a cluster. The document includes code snippets demonstrating how to set up a Flink streaming job topology that reads from Kafka and Zookeeper and writes output to HBase.




















































































