Downloaded 156 times













![The DataStream API
19
case class Event(location: Location, numVehicles: Long)
val stream: DataStream[Event] = …;
stream
.filter { evt => isIntersection(evt.location) }](https://image.slidesharecdn.com/flink-madridmeetupupload-160226092638/85/Data-Stream-Processing-with-Apache-Flink-19-320.jpg)
![The DataStream API
20
case class Event(location: Location, numVehicles: Long)
val stream: DataStream[Event] = …;
stream
.filter { evt => isIntersection(evt.location) }
.keyBy("location")
.timeWindow(Time.minutes(15), Time.minutes(5))
.sum("numVehicles")](https://image.slidesharecdn.com/flink-madridmeetupupload-160226092638/85/Data-Stream-Processing-with-Apache-Flink-20-320.jpg)
![The DataStream API
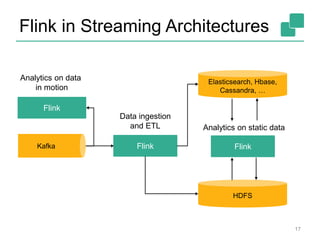
21
case class Event(location: Location, numVehicles: Long)
val stream: DataStream[Event] = …;
stream
.filter { evt => isIntersection(evt.location) }
.keyBy("location")
.timeWindow(Time.minutes(15), Time.minutes(5))
.sum("numVehicles")
.keyBy("location")
.mapWithState { (evt, state: Option[Model]) => {
val model = state.orElse(new Model())
(model.classify(evt), Some(model.update(evt)))
}}](https://image.slidesharecdn.com/flink-madridmeetupupload-160226092638/85/Data-Stream-Processing-with-Apache-Flink-21-320.jpg)


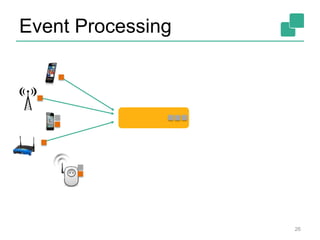
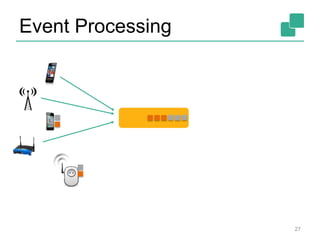
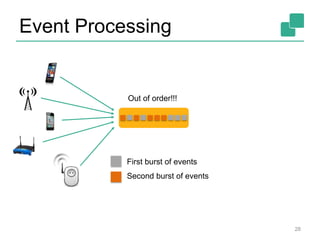
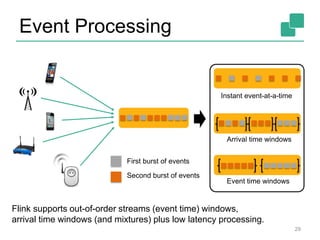




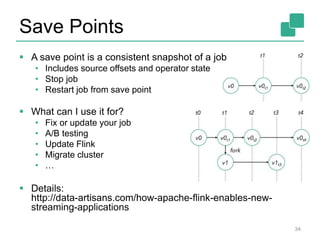
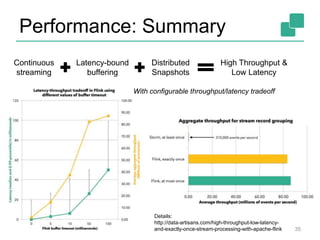








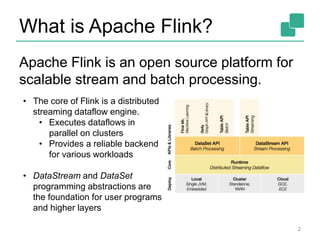
Apache Flink is an open-source platform designed for scalable stream and batch processing, offering low latency, high throughput, and exactly-once consistency. It supports complex event processing and handles out-of-order streams, providing an intuitive API similar to batch processing. With a vibrant community and robust operational features, Flink aims to simplify data infrastructure and enhance real-time analytics.































































![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)
![20260201 [FOSDEM] gomodjail - library sandboxing for Go modules.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/20260201fosdemgomodjail-librarysandboxingforgomodules-260201225659-76609ec4-thumbnail.jpg?width=640&height=640&fit=bounds)














