









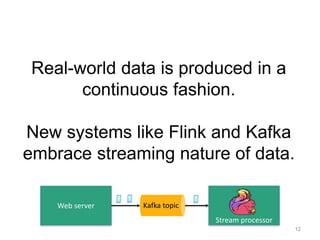
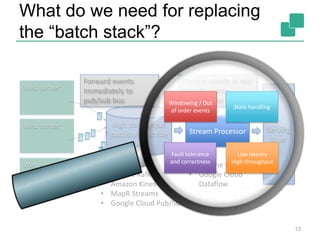
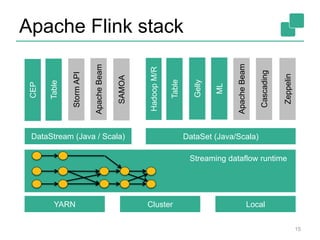
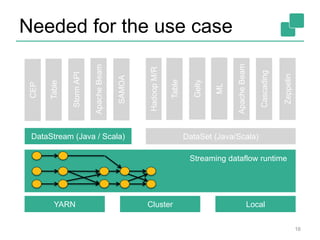

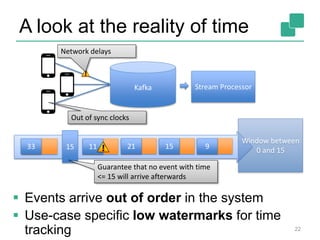


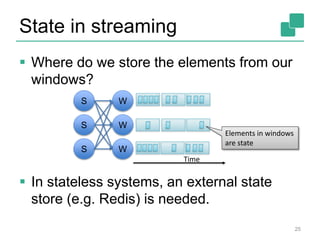
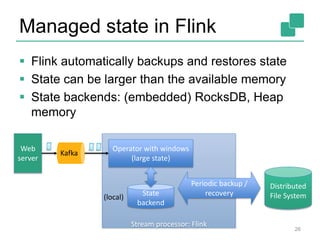
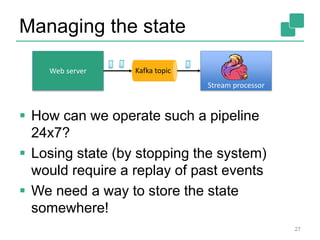








![Yahoo’s Results
“Storm […] and Flink […] show sub-second
latencies at relatively high throughputs with
Storm having the lowest 99th percentile
latency. Spark streaming 1.5.1 supports high
throughputs, but at a relatively higher
latency.”
(Quote from the blog post’s executive summary)
37
Full Yahoo! article: https://yahooeng.tumblr.com/post/135321837876/benchmarking-streaming-
computation-engines-at](https://image.slidesharecdn.com/untitled-160411110253/85/Stream-Processing-with-Apache-Flink-38-320.jpg)

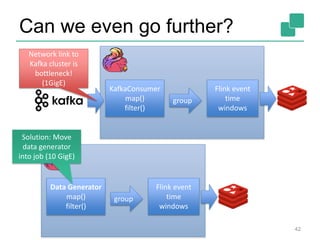
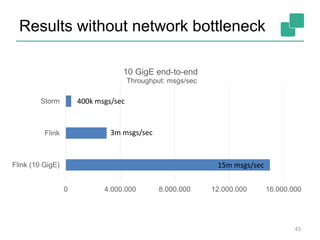




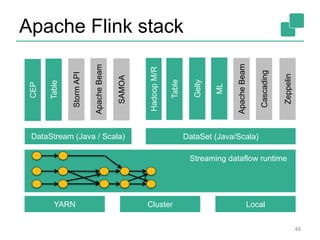



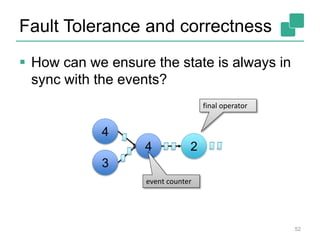
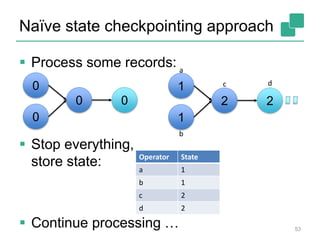
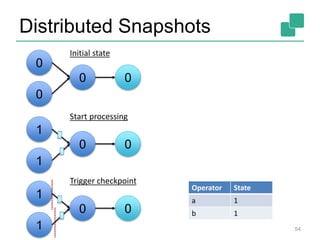
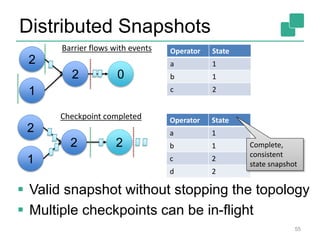

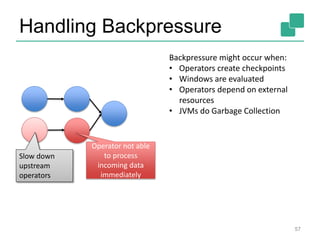
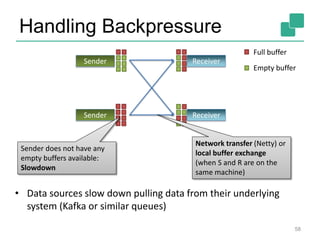
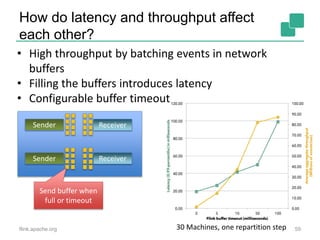
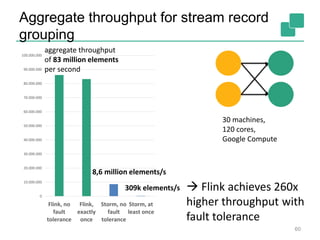
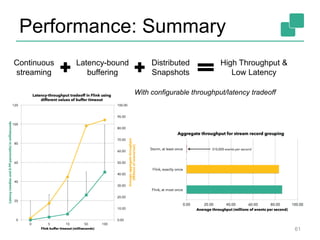
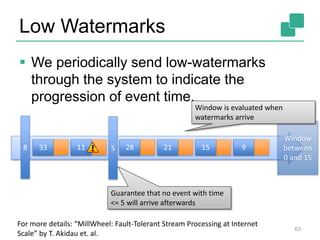
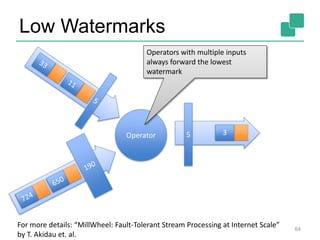

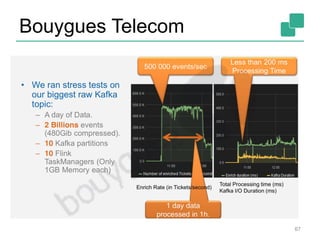
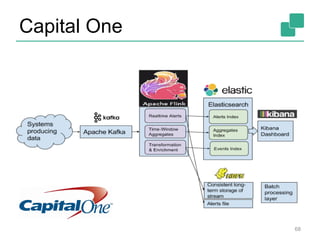
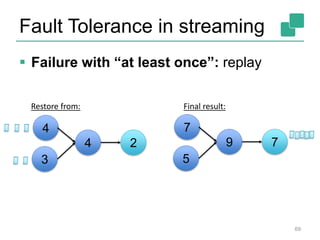
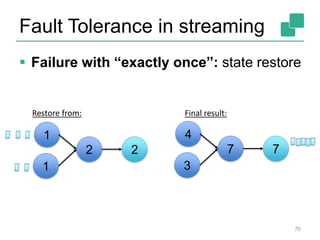
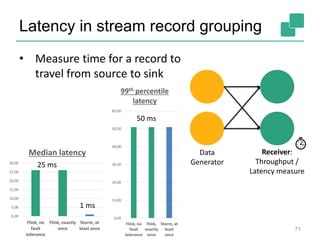

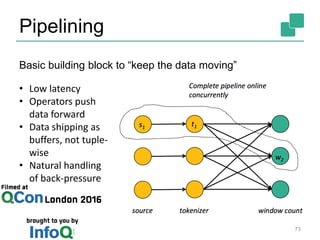


The document discusses stream processing using Apache Flink, emphasizing its low latency, high throughput, and stateful processing capabilities. It contrasts traditional batch processing with stream processing, highlighting the advantages of real-time data analysis and various architectural components involved in Flink. The presentation details performance benchmarks, fault tolerance mechanisms, windowing strategies, and the overall benefits of adopting stream processing in modern data infrastructures.























































































