Download to read offline








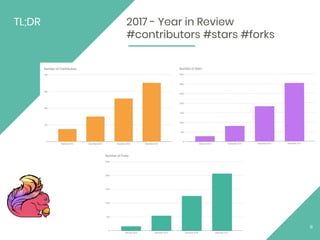
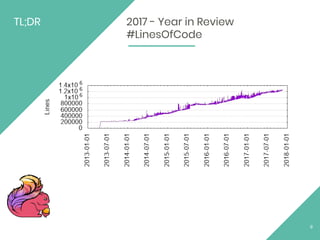









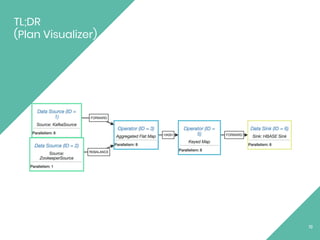
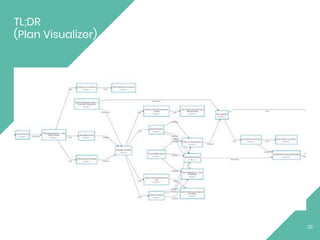


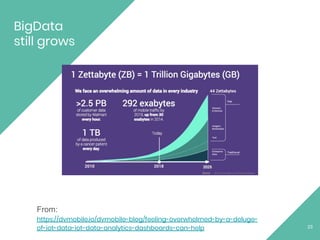
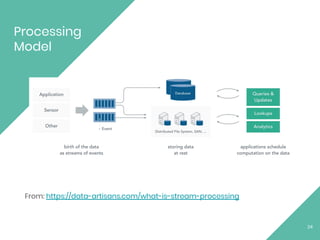
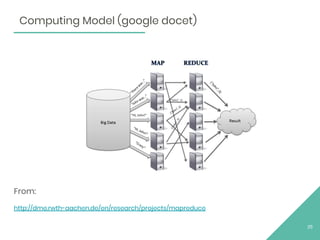
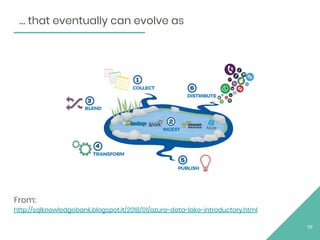
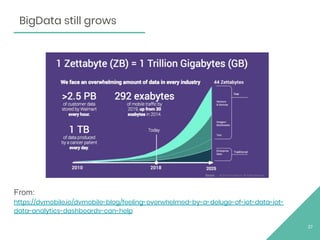



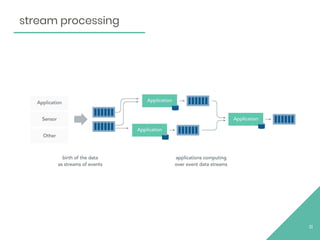
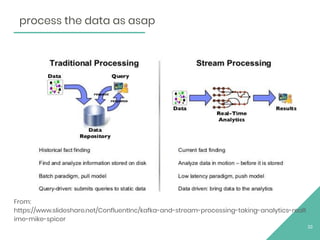



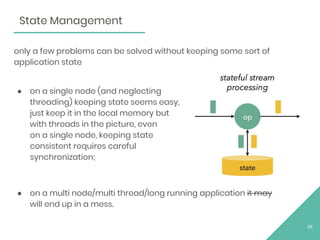
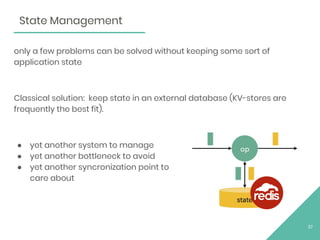
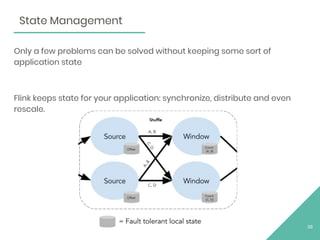
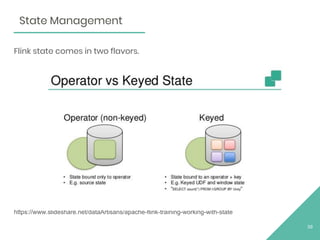


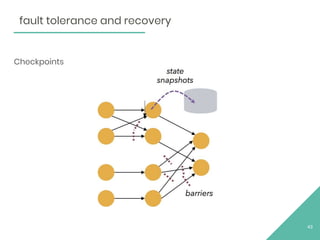


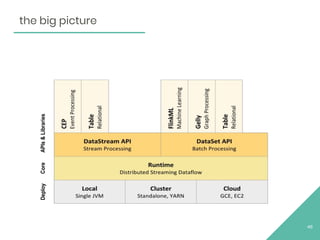




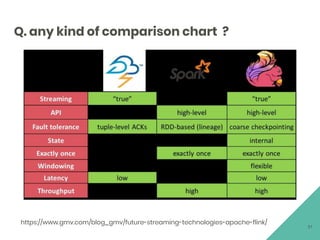

The document discusses Apache Flink, an open source stream processing framework. It provides an overview of Flink, including that its core is a distributed streaming dataflow engine written in Java and Scala. Code snippets are provided to demonstrate how to set up a Flink streaming job that reads from Kafka, connects to Zookeeper, performs transformations, and writes outputs. Use cases for Flink in domains like telecommunications, automotive, finance, and healthcare are also briefly mentioned.





















































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)











