






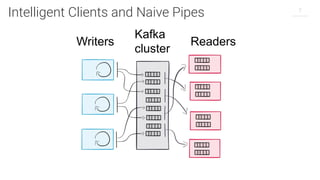


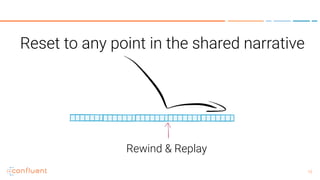

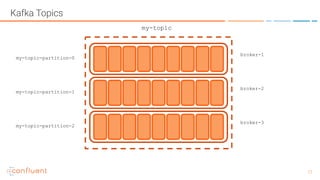
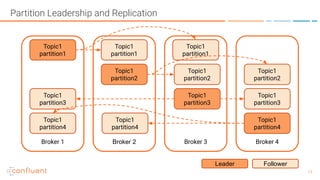




This document summarizes a presentation about Apache Kafka. It introduces Apache Kafka as a modern, distributed platform for data streams made up of distributed, immutable, append-only commit logs. It describes Kafka's scalability similar to a filesystem and guarantees similar to a database, with the ability to rewind and replay data. The document discusses Kafka topics and partitions, partition leadership and replication, and provides resources for further information.






















































































