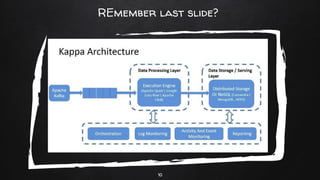
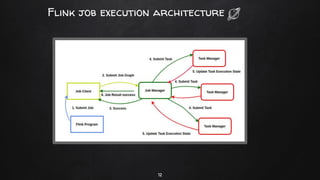
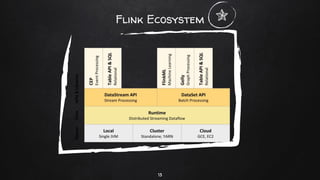
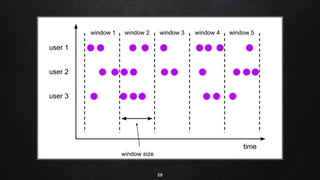
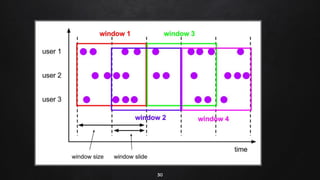
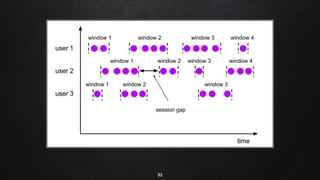
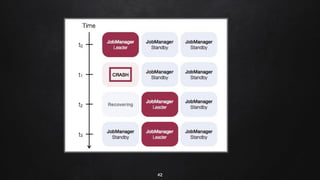
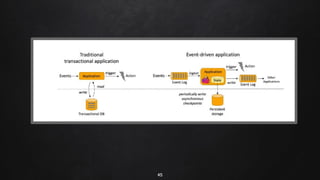
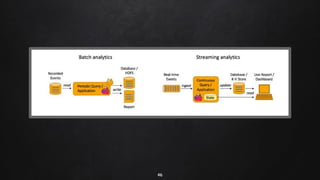
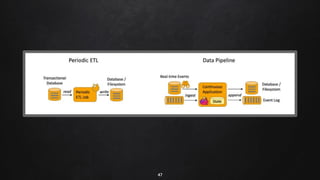
Apache Flink is a distributed stream processing framework designed for handling large volumes of real-time data. It supports both batch and stream processing, offering features like low latency, high throughput, and fault tolerance through checkpointing. Flink's ecosystem comprises various data sources and sinks, and it enables users to perform complex operations on continuous data streams using APIs for dataset and datastream.