Download as PDF, PPTX








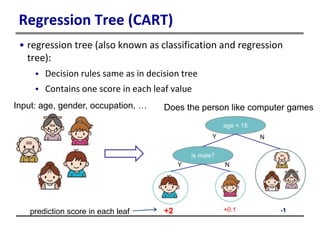
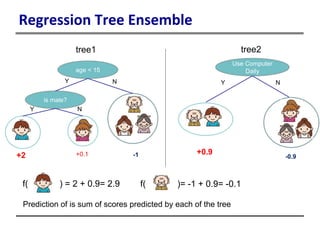


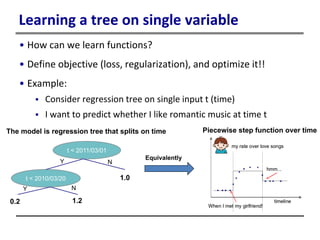
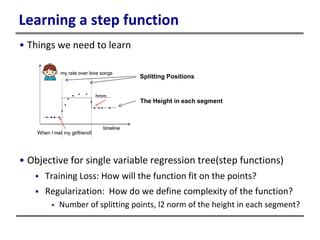
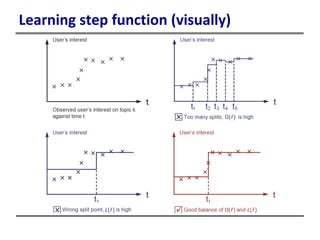









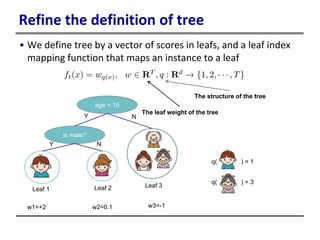
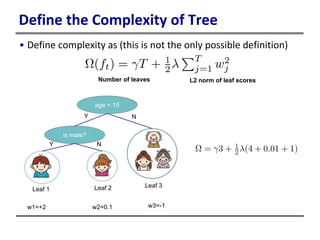

















This document provides an introduction to boosted trees. It reviews key concepts in supervised learning such as loss functions, regularization, and the bias-variance tradeoff. Regression trees are described as a model that partitions data and assigns a prediction score to each partition. Gradient boosting is presented as a method for learning an ensemble of regression trees additively to minimize a given loss function. The learning process is formulated as optimizing an objective function that balances training loss and model complexity.























































































