The document presents a paper titled "Blazing the Trails Before Beating the Path: Sample-Efficient Monte-Carlo Planning" which details a nested Monte-Carlo planning algorithm for Markov Decision Processes (MDP). It aims to efficiently estimate the value of states while minimizing calls to a generative model, addressing the trade-off between the number of actions and acceptable estimation error. The paper also discusses theoretical guarantees and the sample complexity performance of the proposed algorithm.


![AIM
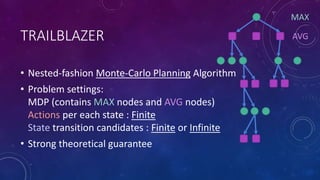
• Input : an MDP (Markov Decision Process)
(discount factor 𝛾, maximum number of valid actions 𝐾),
𝜀 (> 0), 𝛿 (0 < 𝛿 < 1)
• Output : estimated value 𝜇 𝜀,𝛿 of current state 𝑠0
• Aim : Get good estimation of real value 𝒱[𝑠0] of current state
such as
ℙ 𝜇 𝜀,𝛿 − 𝒱 𝑠0 > 𝜀 ≤ 𝛿
( ℙ ∙ means probability of ∙ )
with the minimum number of calls to the generative model (state transition function)](https://image.slidesharecdn.com/trailblazerohto-170123022135/85/Introduction-of-TrailBlazer-algorithm-4-320.jpg)









![Differential privacy without sensitivity [NIPS2016読み会資料]](https://cdn.slidesharecdn.com/ss_thumbnails/nipsyomi2016slideshare-170122091905-thumbnail.jpg?width=640&height=640&fit=bounds)





























![[DL輪読会]Convolutional Sequence to Sequence Learning](https://cdn.slidesharecdn.com/ss_thumbnails/dl0519-170519005603-thumbnail.jpg?width=640&height=640&fit=bounds)




















































