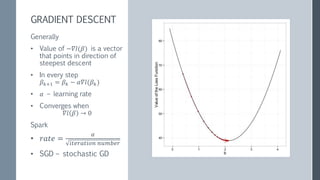
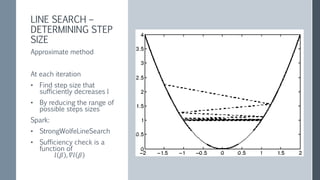
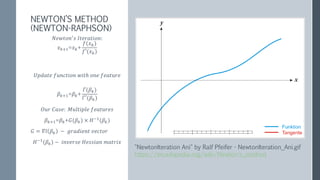
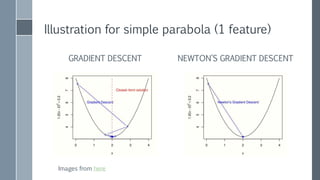
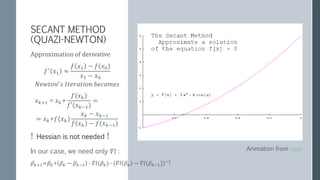
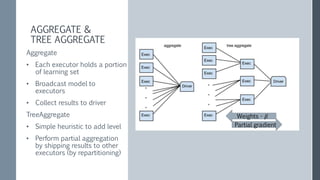
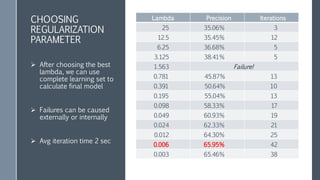
This document discusses scaling out logistic regression with Apache Spark. It describes the need to classify a large number of websites using machine learning. Several approaches to logistic regression were tried, including a single machine Java implementation and moving to Spark for better scalability. Spark's L-BFGS algorithm was chosen for its out of the box distributed logistic regression solution. Challenges implementing logistic regression at large scale are discussed, such as overfitting and regularization. Methods used to address these challenges include L2 regularization, cross-validation to select the regularization parameter, and extensions made to Spark's LBFGS implementation.




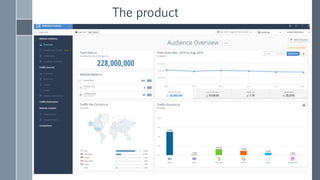

























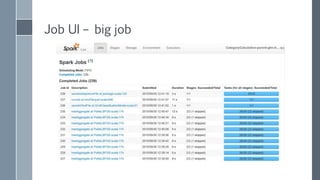






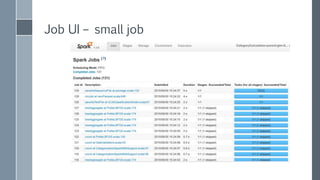



![Could you guess the reason for difference?
run Phase name
real time
[sec]
iteration time
[sec]
iterations
1 parent-glm-AVTags 29101 153.2 190
2 parent-glm-AVTags 15226 82.3 185
3 parent-glm-AVTags 2863 18.8 152
• OK, I admit, cluster was very loaded in first run
• What about the second ?
• org.apache.spark.shuffle.MetadataFetchFailedException:
Missing an output location for shuffle
• Increase spark.shuffle.memoryFraction=0.5](https://image.slidesharecdn.com/scalingoutlogisticregression-151008103242-lva1-app6892/85/Scaling-out-logistic-regression-with-Spark-51-320.jpg)














































































