Download as PDF, PPTX

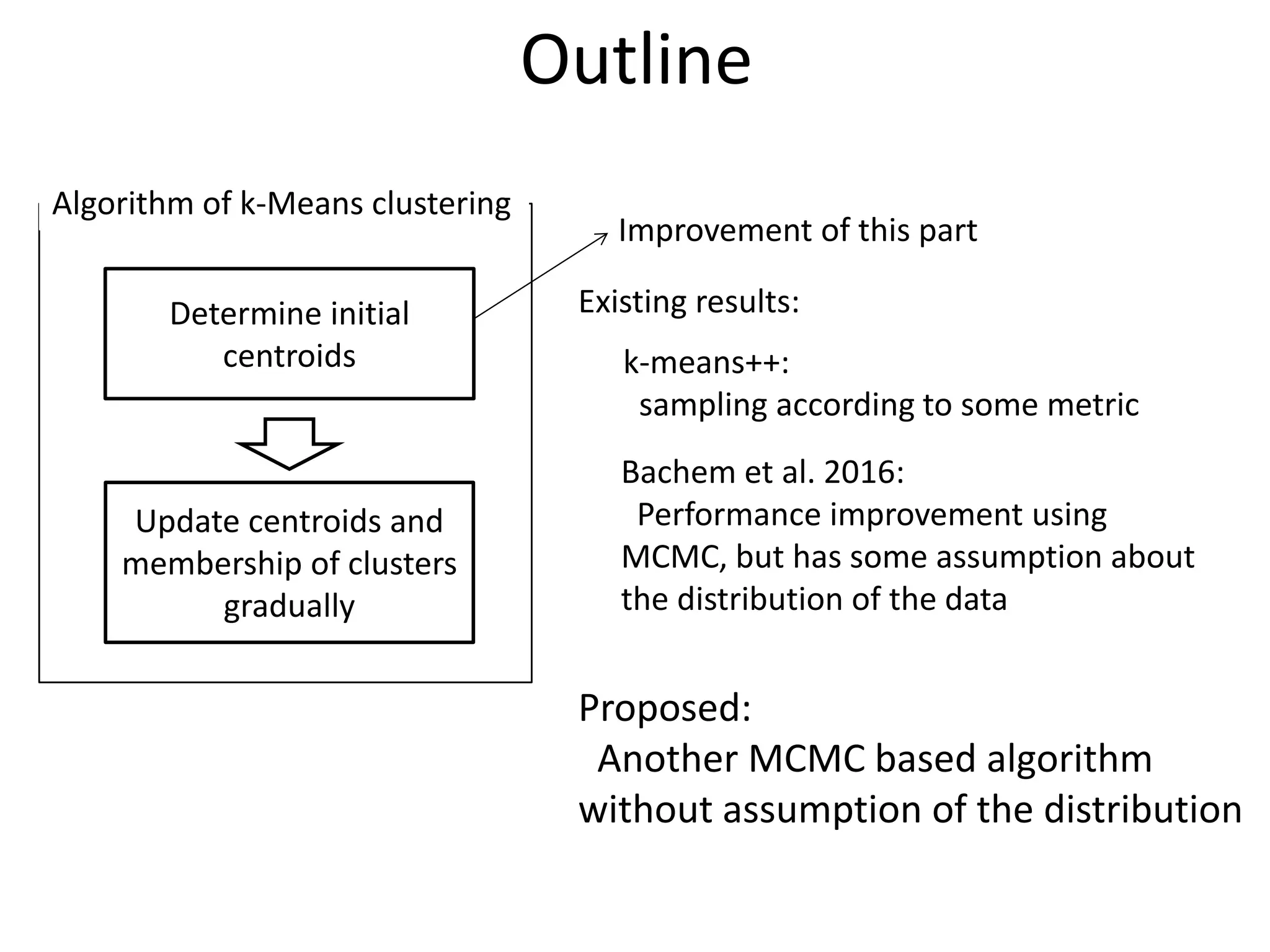


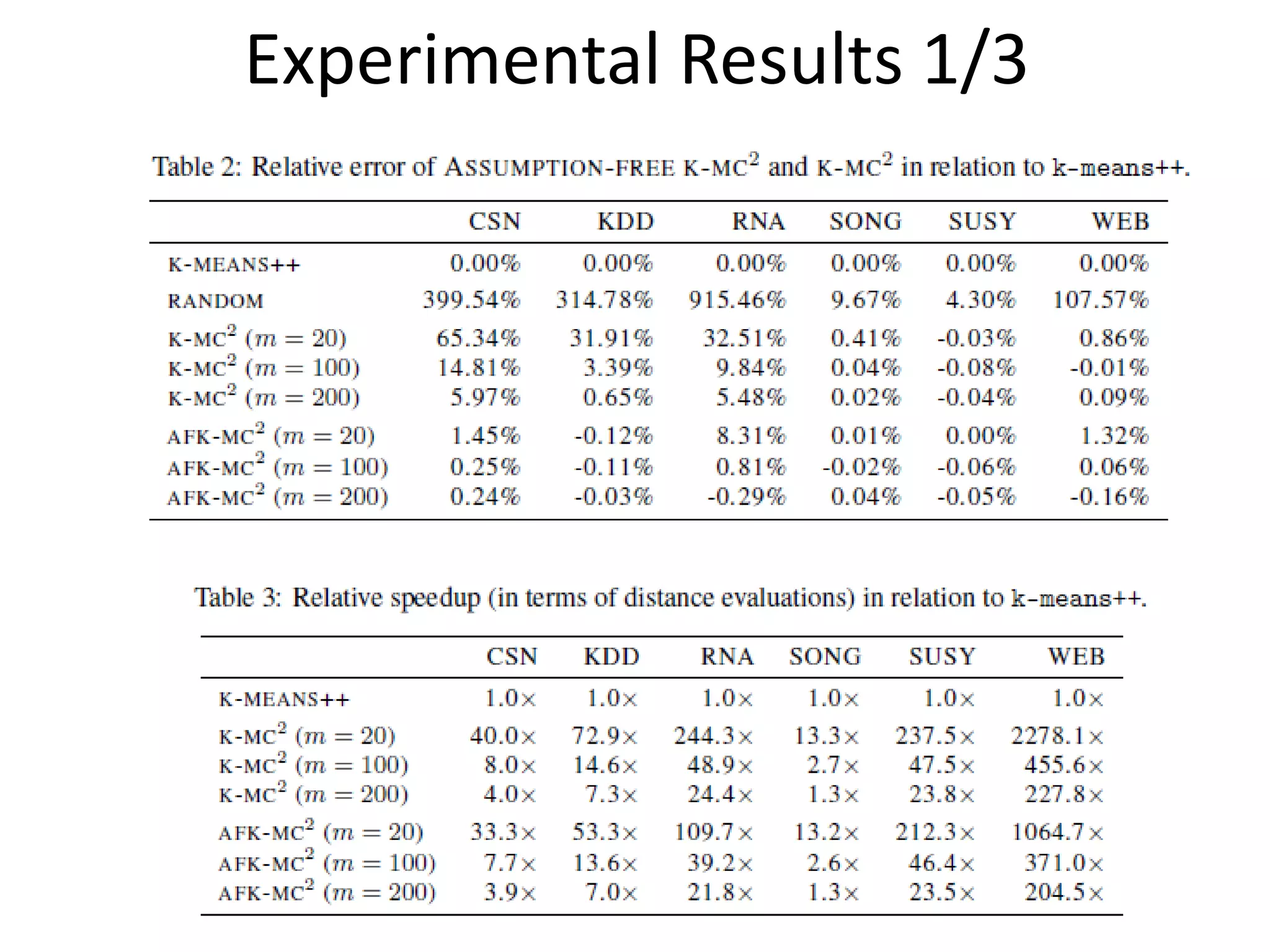
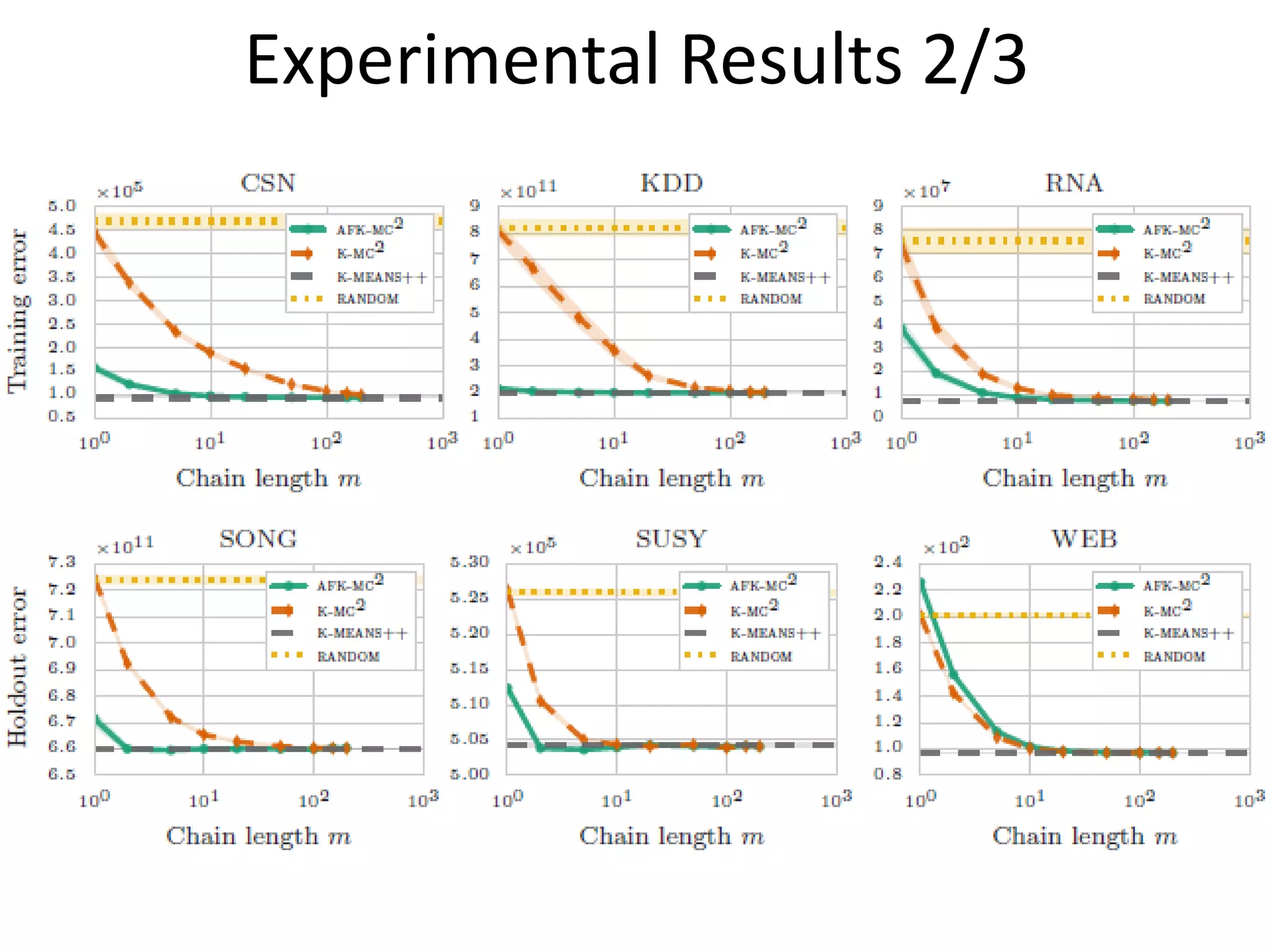
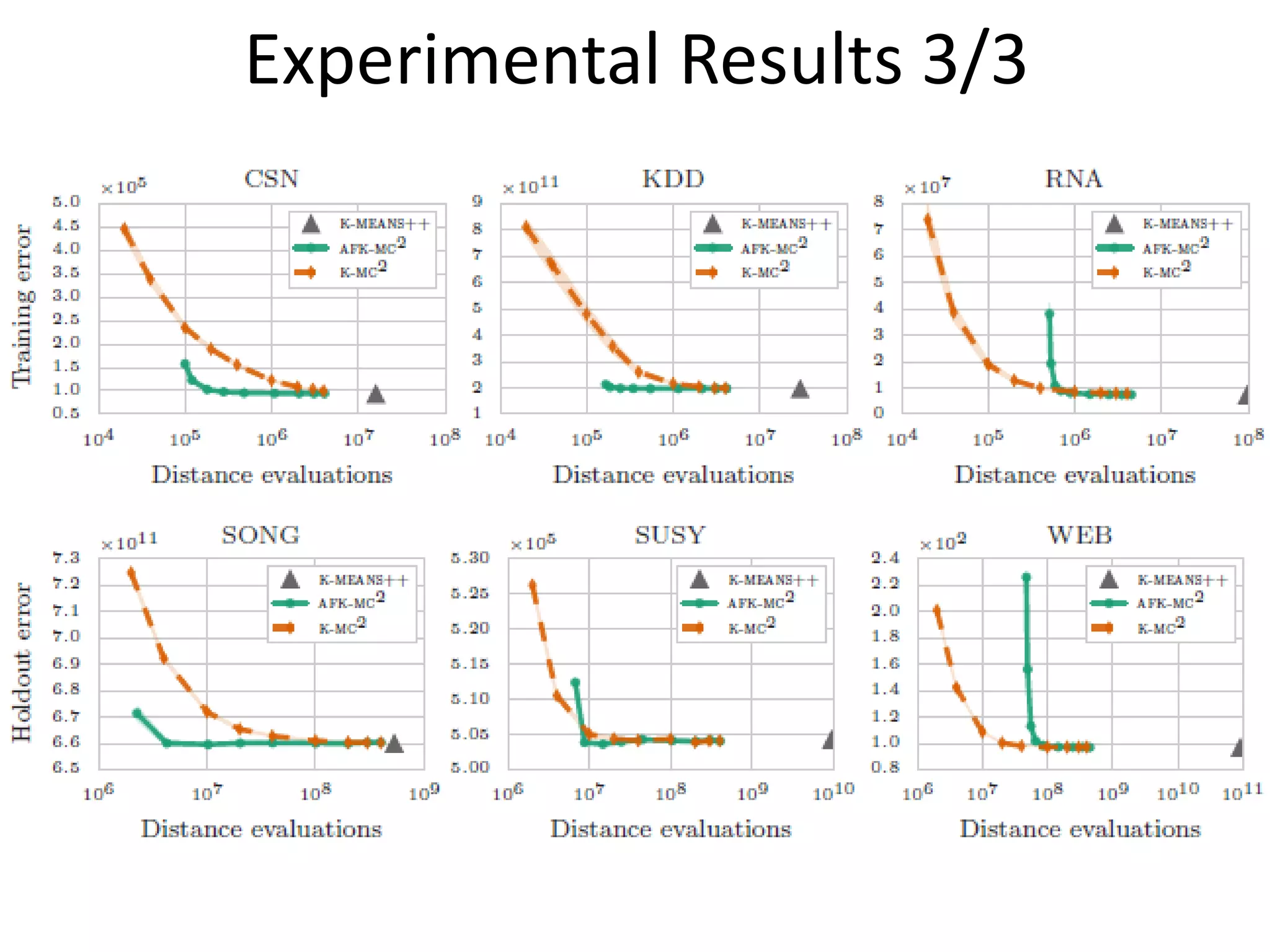


The document proposes a new MCMC-based algorithm for initializing centroids in k-means clustering that does not assume a specific distribution of the input data, unlike previous work. It uses rejection sampling to emulate the distribution and select initial centroids that are widely scattered. The algorithm is proven mathematically to converge. Experimental results on synthetic and real-world datasets show it performs well with a good trade-off of accuracy and speed compared to existing techniques.




















![Differential privacy without sensitivity [NIPS2016読み会資料]](https://cdn.slidesharecdn.com/ss_thumbnails/nipsyomi2016slideshare-170122091905-thumbnail.jpg?width=640&height=640&fit=bounds)










![[DL輪読会]Convolutional Sequence to Sequence Learning](https://cdn.slidesharecdn.com/ss_thumbnails/dl0519-170519005603-thumbnail.jpg?width=640&height=640&fit=bounds)





























































