Downloaded 29 times




























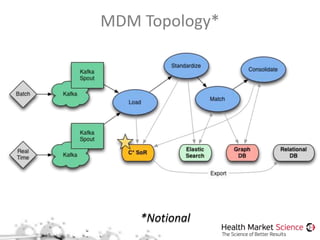

![Cassandra State (v0.4.0)
git@github.com:hmsonline/storm-cassandra.git
{tuple} <mapper> (ks, cf, row, k:v[])
Storm Cassandra](https://image.slidesharecdn.com/stormphillyjug05-140522103212-phpapp01/85/Phily-JUG-Web-Services-APIs-for-Real-time-Analytics-w-Storm-and-DropWizard-35-320.jpg)
![Trident Elastic Search (v0.3.1)
git@github.com:hmsonline/trident-elasticsearch.git
{tuple} <mapper> (idx, docid, k:v[])
Storm Elastic Search](https://image.slidesharecdn.com/stormphillyjug05-140522103212-phpapp01/85/Phily-JUG-Web-Services-APIs-for-Real-time-Analytics-w-Storm-and-DropWizard-36-320.jpg)






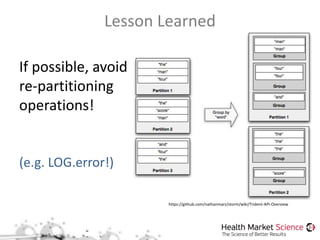























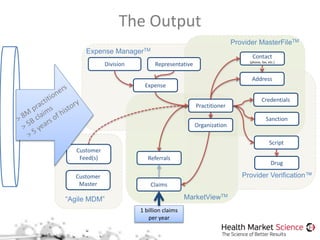
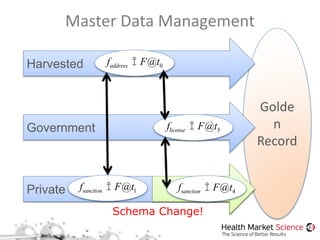
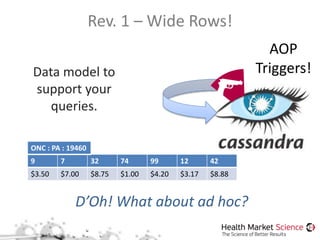
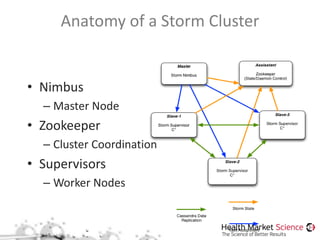
The document discusses the Storm framework for distributed real-time computation in healthcare data analysis, emphasizing its advantages over Hadoop. It provides insights into data pipelines, polyglot persistence, and the lambda architecture, detailing how Storm's components such as spouts and bolts facilitate efficient data processing. Additionally, it explores innovations in state management and querying within the context of big data and healthcare solutions.









































































