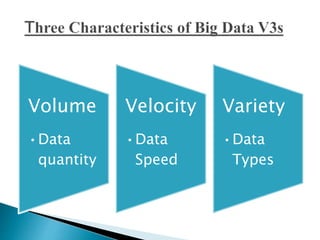
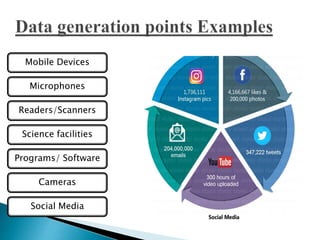
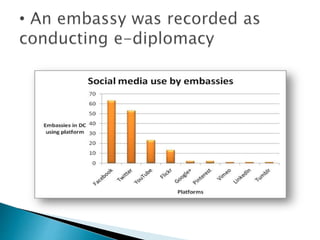
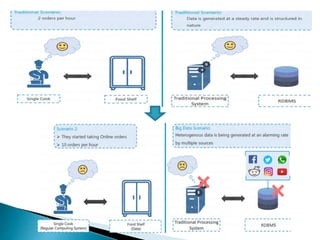
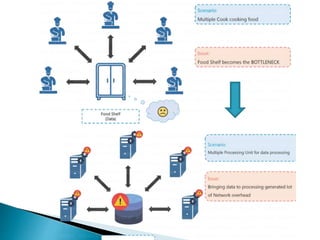
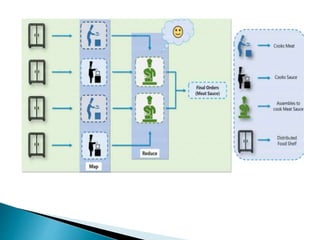
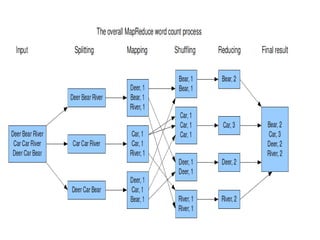
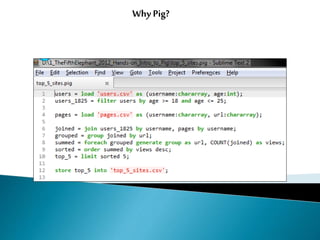
Big data refers to large volumes of diverse data that traditional data processing systems are unable to handle. Hadoop is an open-source software framework for distributed storage and processing of big data across clusters of commodity hardware. It allows for the reliable, scalable, and distributed processing of large data sets across clusters of commodity servers. Hadoop features include scalable and reliable data storage with HDFS and distributed processing of large data sets with MapReduce. Popular companies that use Hadoop include Google, Facebook, and Amazon for its abilities to process massive amounts of data in a cost-effective manner.