Download as PDF, PPTX

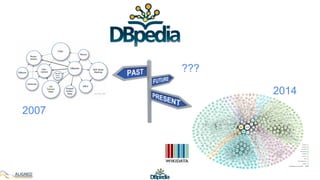


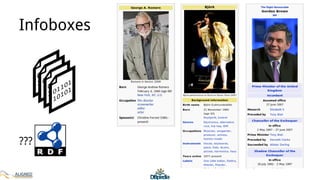





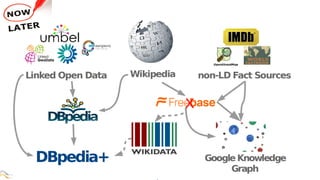
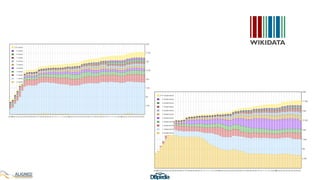

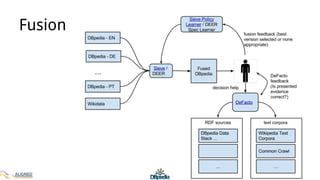








The document discusses the development of DBpedia, detailing its origins, milestones, and the collaborative efforts that led to its evolution. It highlights the extraction of structured data from Wikipedia, the growth in entities and triples over the years, and the need for DBpedia to adapt and integrate with enterprise knowledge. Additionally, it mentions ongoing projects and acknowledges contributors to the presentation.























































![[Data Meetup] Data Science in Finance - Factor Models in Finance](https://cdn.slidesharecdn.com/ss_thumbnails/factormodelsinfinance-metodinikolov-191009091837-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Data Meetup] Data Science in Finance - Building a Quant ML pipeline](https://cdn.slidesharecdn.com/ss_thumbnails/buildingaquantmlpipeline-191009091209-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Data Meetup] Data Science in Journalism - Tanbih, QCRI and MIT](https://cdn.slidesharecdn.com/ss_thumbnails/dsspreslavnakov2019-08-222-190901181352-thumbnail.jpg?width=640&height=640&fit=bounds)


















![[DSC Europe 25] Dragan Jerosimovic - The Anatomy of a Narrative Simulation.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/vzputuprdqr6zwbrwdcw-1-dragan-jerosimovic-the-anatomy-of-a-narrative-simulation-260114111931-9d04fba2-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Danilo Djukanovic - From Vibes to KPIs: Turning Culture Into ...](https://cdn.slidesharecdn.com/ss_thumbnails/inqestws5wf0cik2glgv-3-danilo-djukanovic-from-vibes-to-kpis-presentation-260114111931-dacff81f-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Ivica Milaric - The Future of Gaming and AI Tools.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/tijgzsmgse2kj2y5pzzp-5-ivica-milaric-the-future-of-gaming-x-ai-tools-260114111931-87c2b3ac-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Stefan Brankovic - #ResumeIsDead. AI-Powered Interviews and C...](https://cdn.slidesharecdn.com/ss_thumbnails/qnmbsv0xq3uysdrq3sev-2-stefan-brankovic-job-bolt-260114111931-a065aa3d-thumbnail.jpg?width=640&height=640&fit=bounds)










![[DSC Europe 25] Elena Menshikova - AI-Powered Operational Excellence: Revolut...](https://cdn.slidesharecdn.com/ss_thumbnails/es6nholbqy3zaao2c2yd-2-elena-menshikova-data-ai-in-decision-making-260115093812-4fba8b38-thumbnail.jpg?width=640&height=640&fit=bounds)

