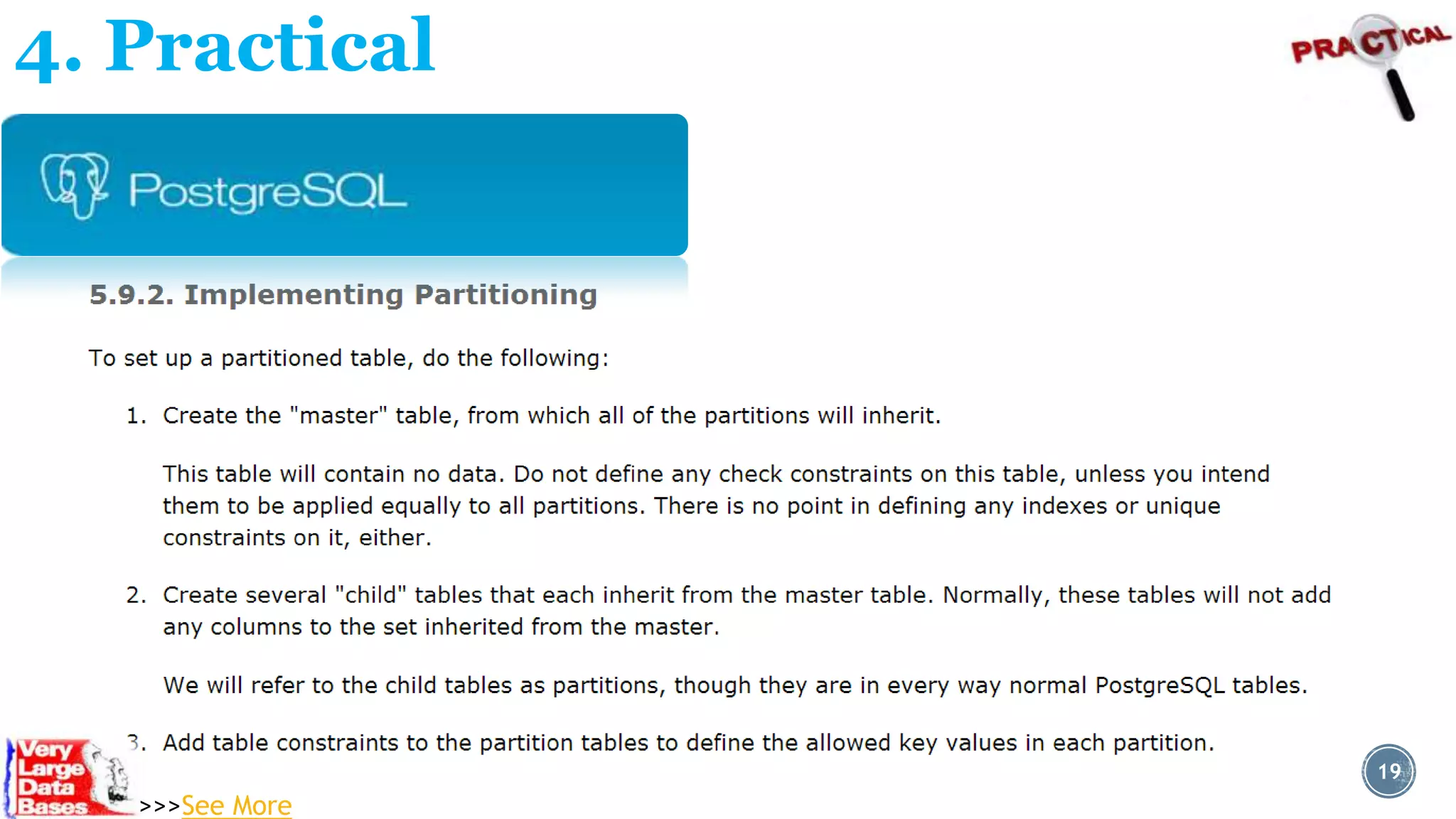
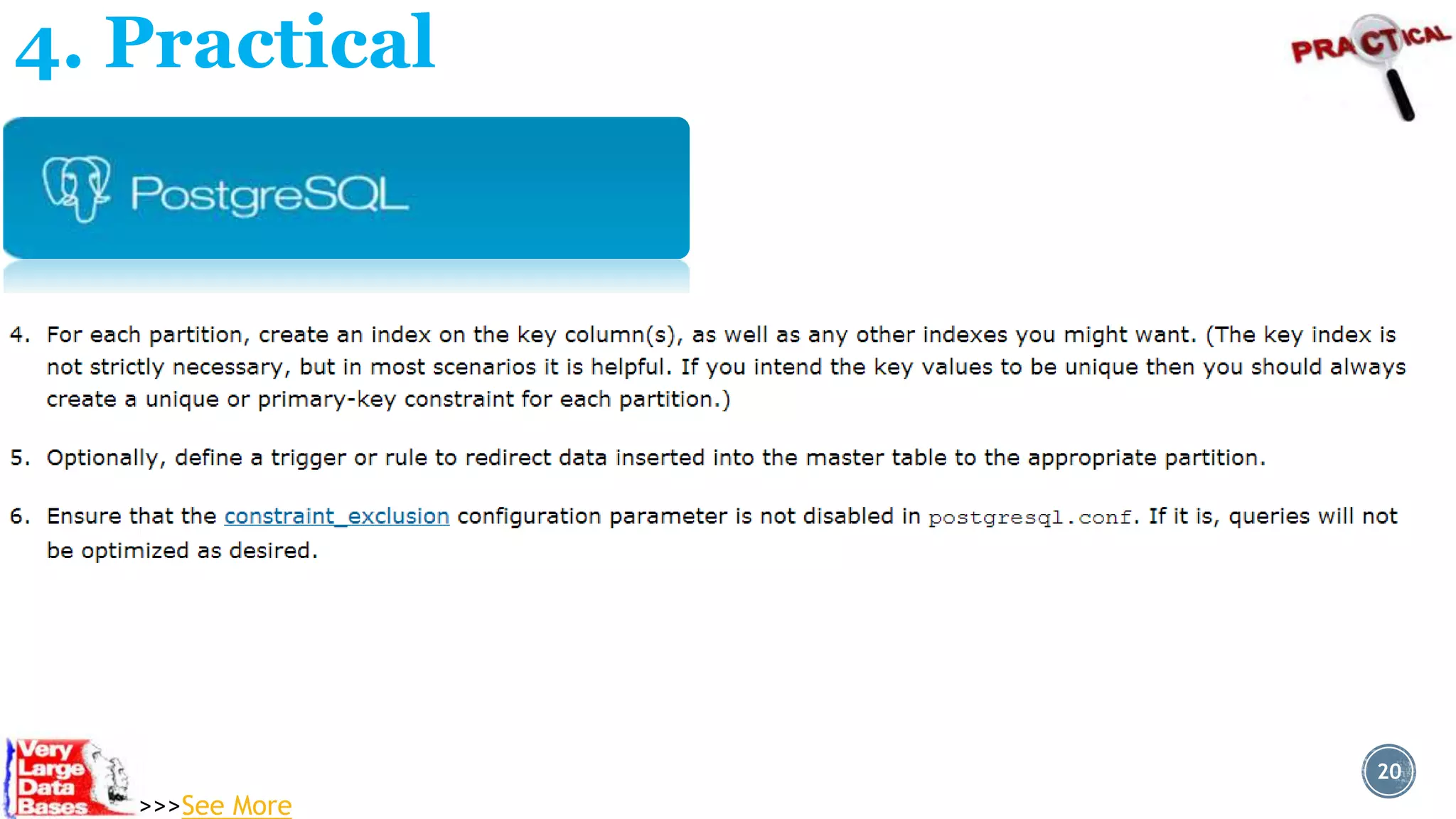
Downloaded 18 times






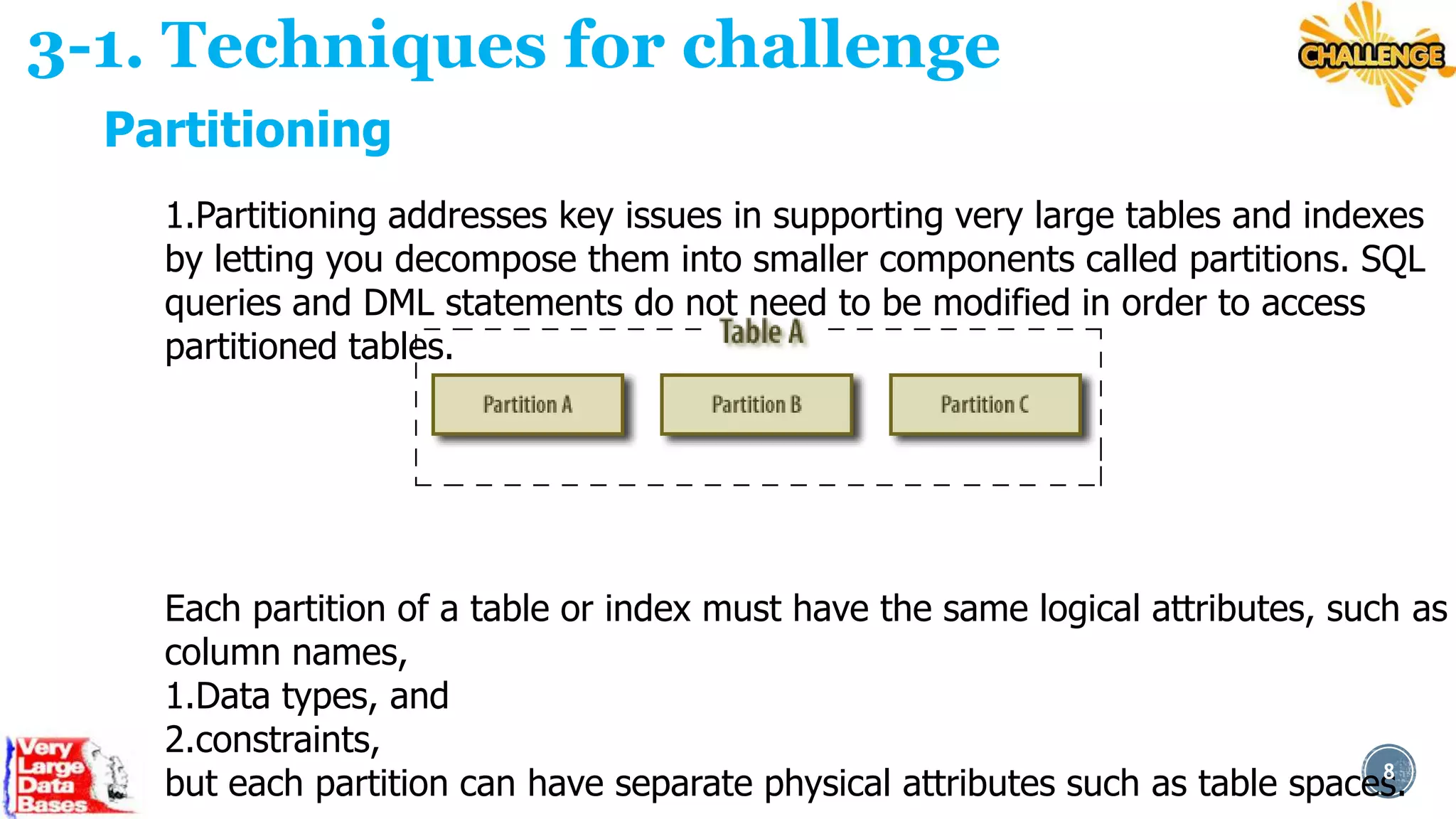



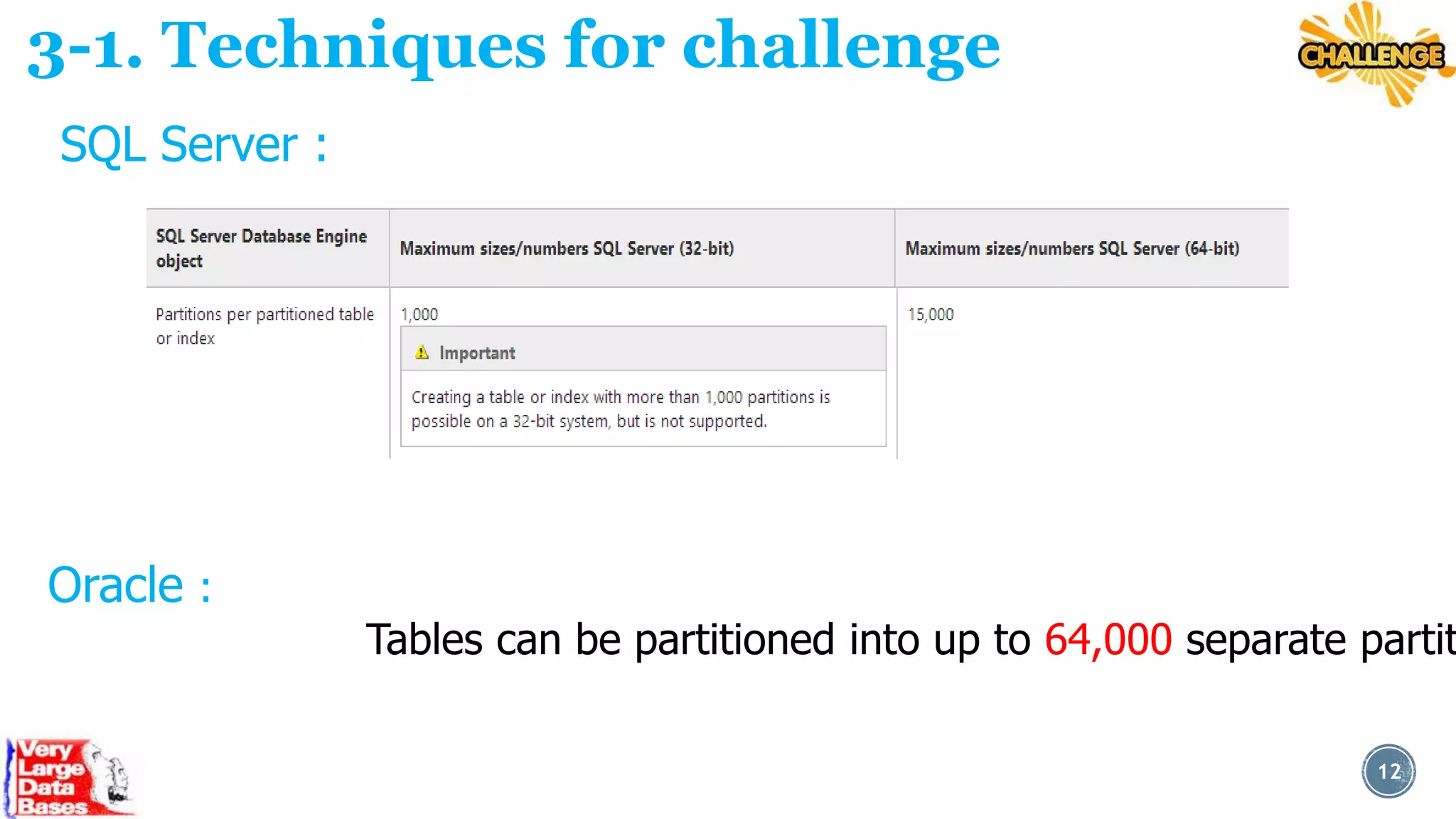



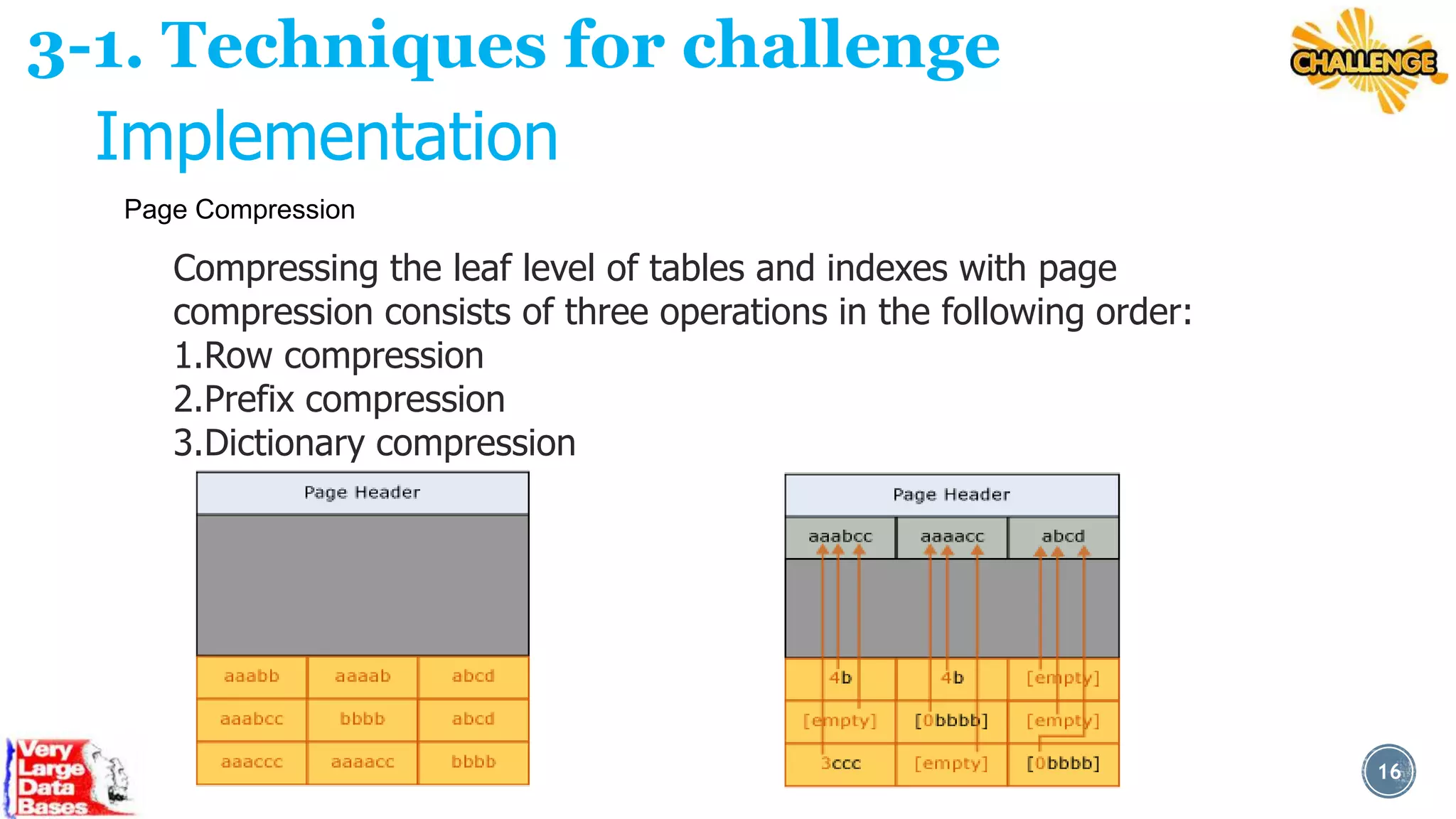




This document discusses techniques for managing very large databases (VLDBs). It begins by defining what constitutes a VLDB and how that definition changes over time as database sizes increase. It then discusses some of the challenges of working with VLDBs, such as long load, update, and indexing times. The document proposes techniques for addressing these challenges, including database partitioning, which breaks large tables into smaller, more manageable partitions, and data compression techniques to reduce the physical size of databases. It provides examples of how partitioning and compression can be implemented in popular database systems like SQL Server and Oracle. The overall aim is to discuss strategies for optimizing performance and maintenance of extremely large databases.






































![Kb 40 kevin_klineukug_reading20070717[1]](https://cdn.slidesharecdn.com/ss_thumbnails/kb40kevinklineukugreading200707171-101026100915-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)




























