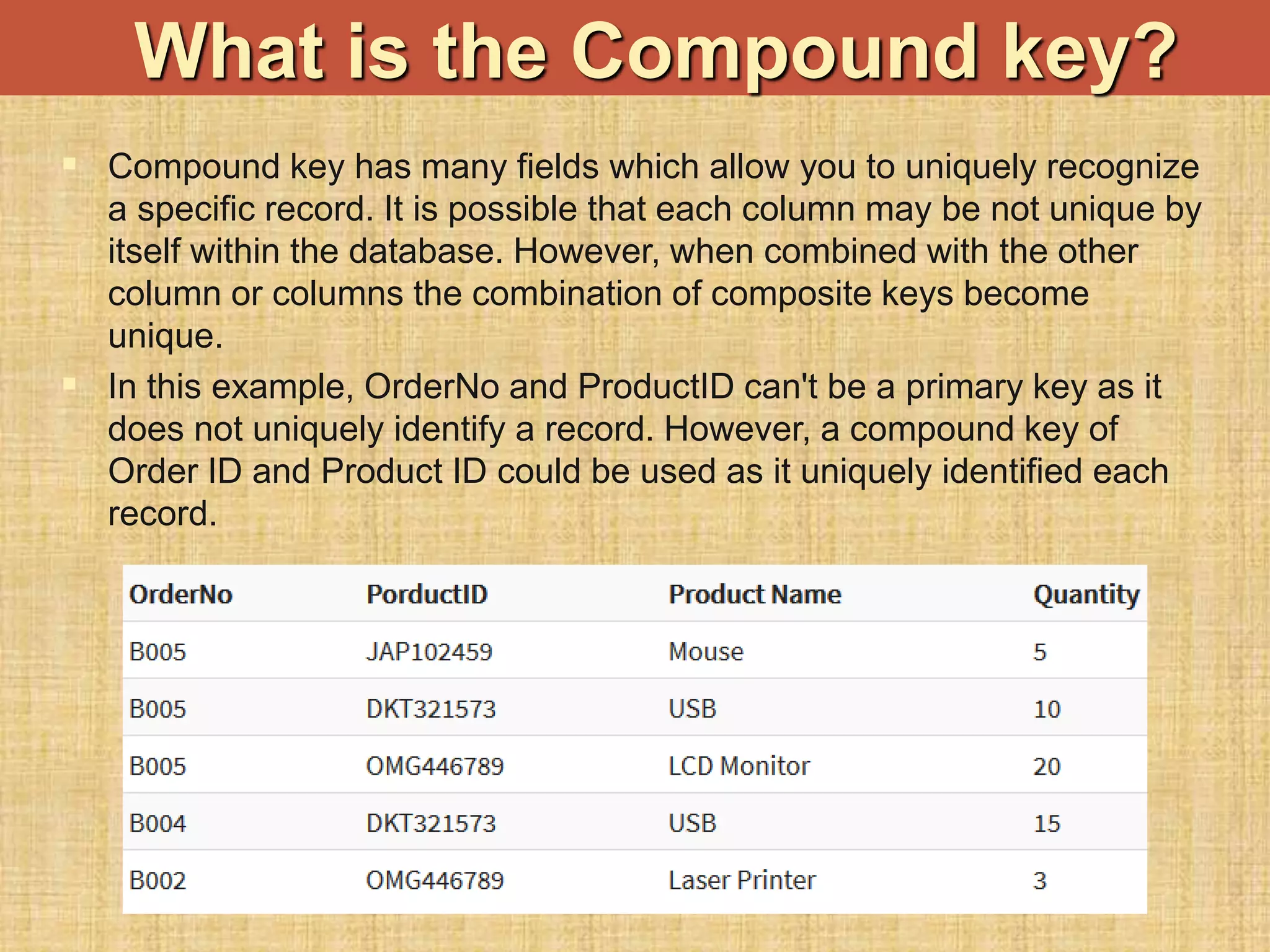
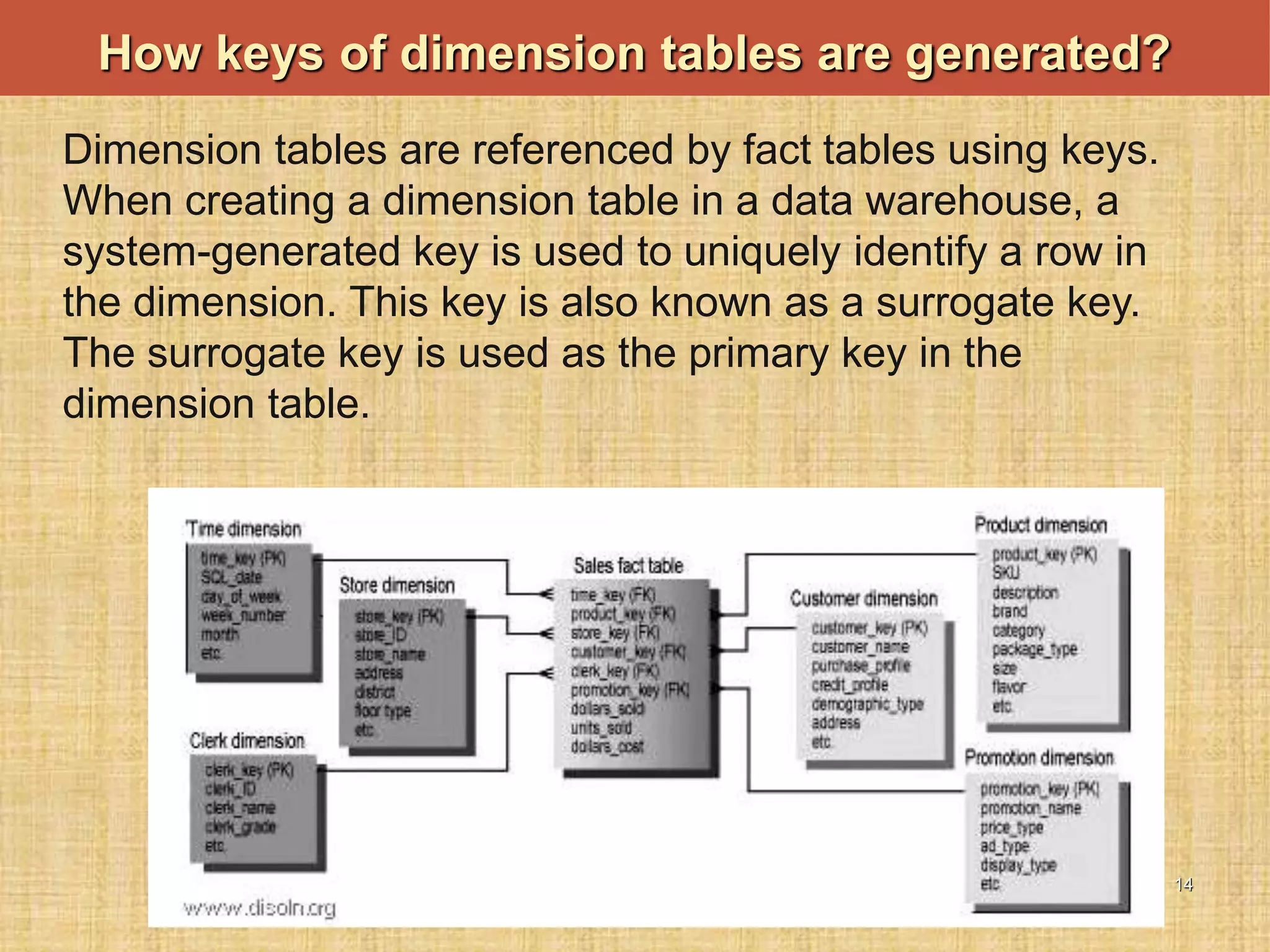
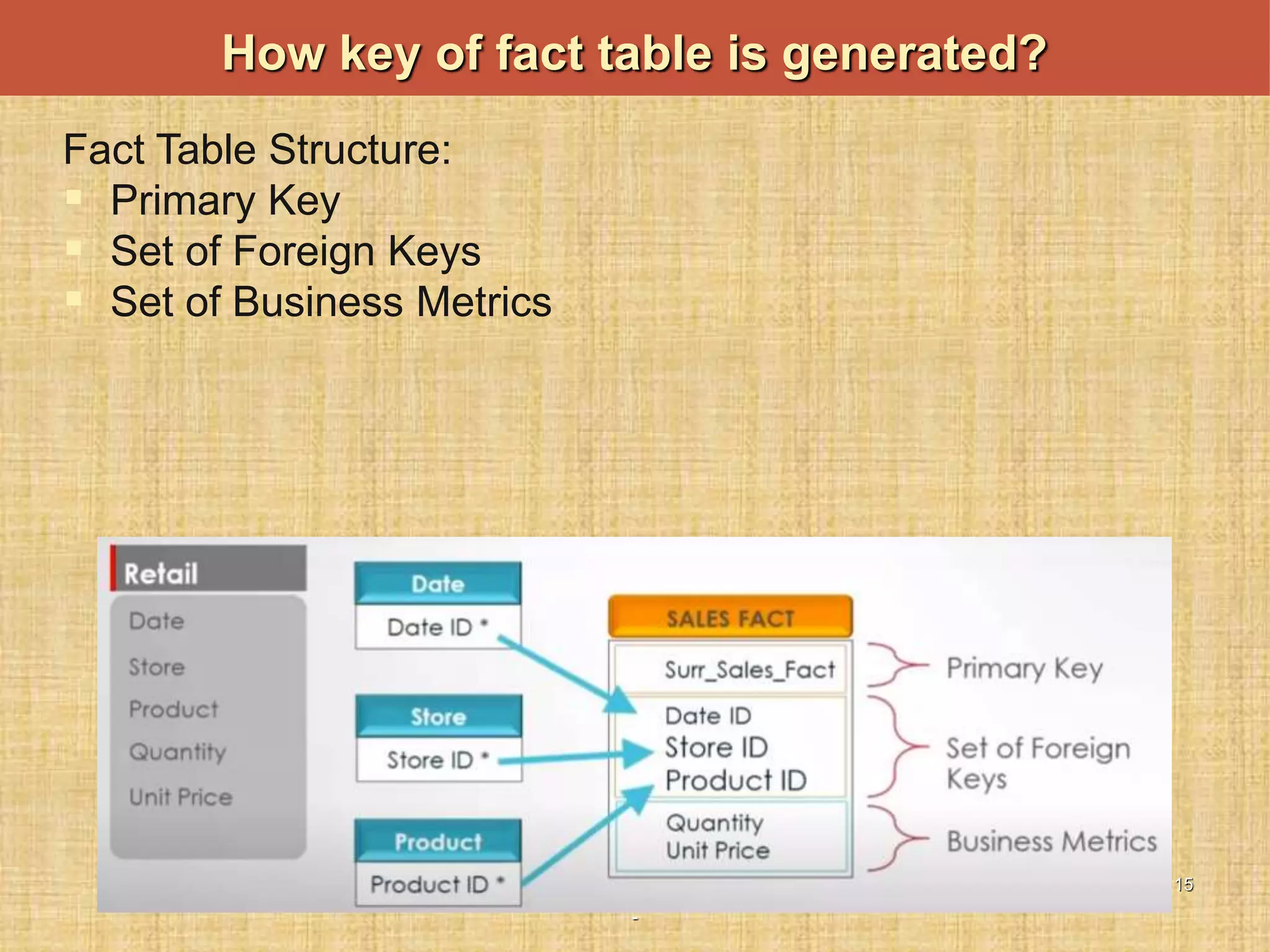
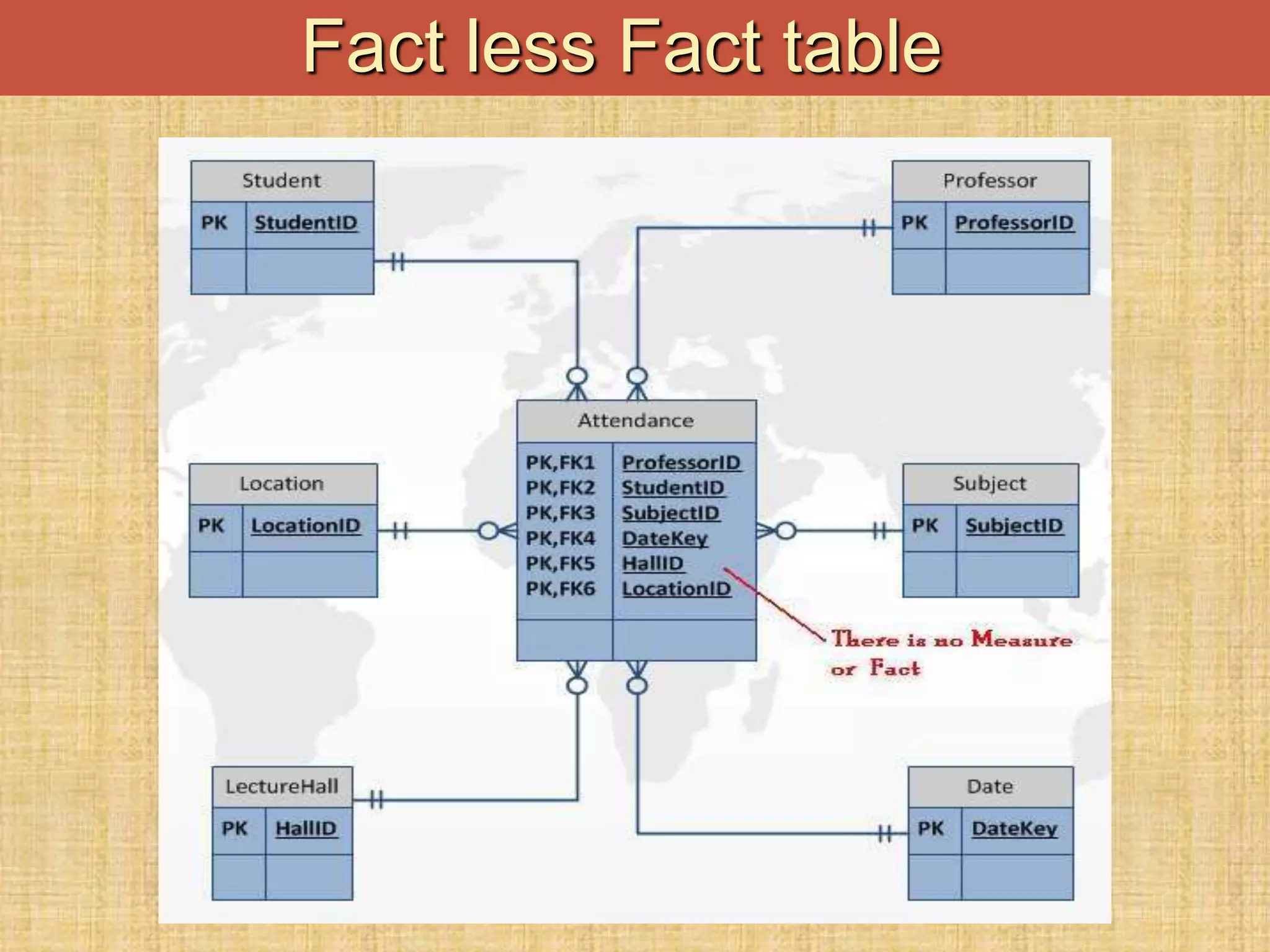
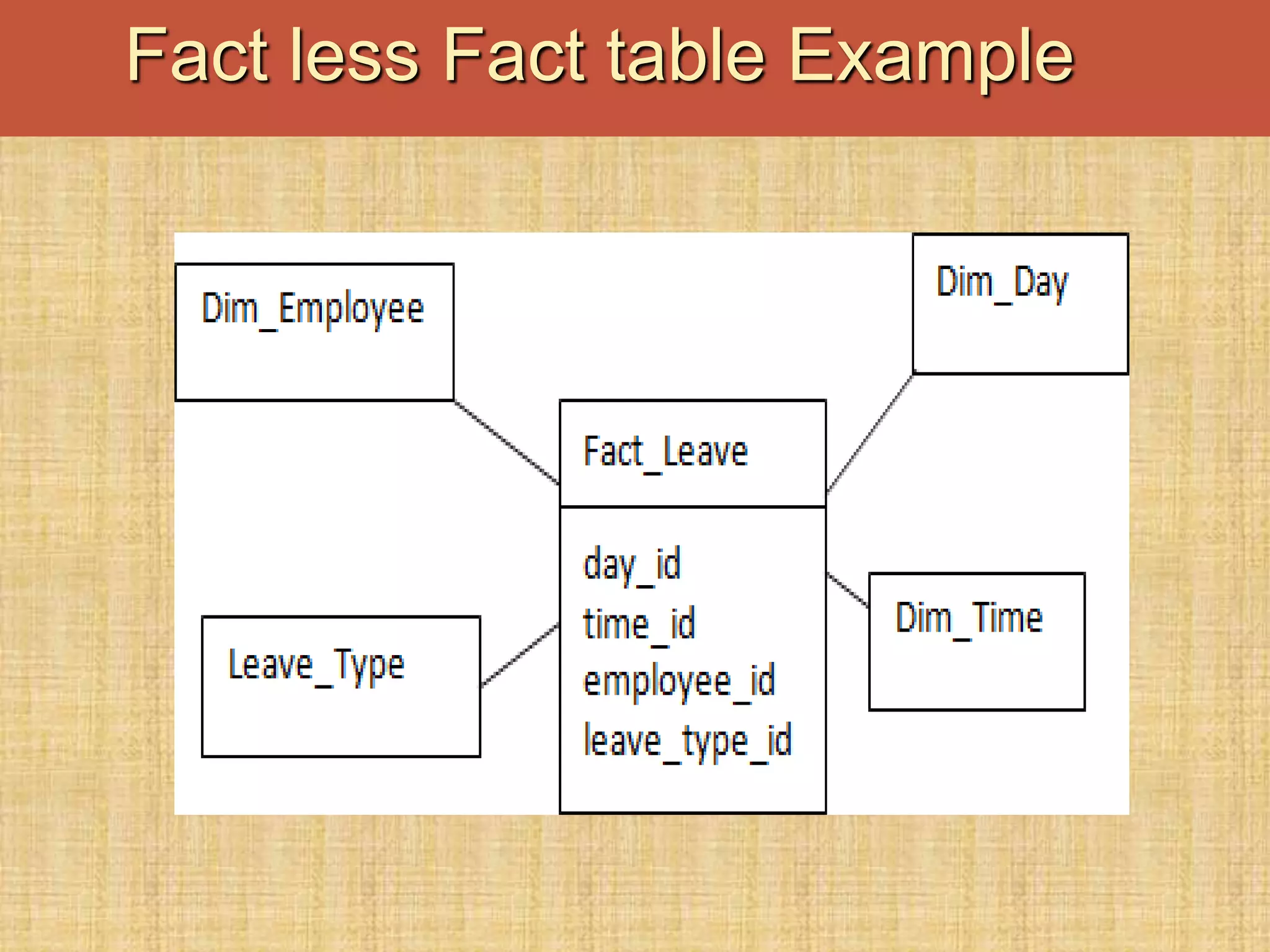
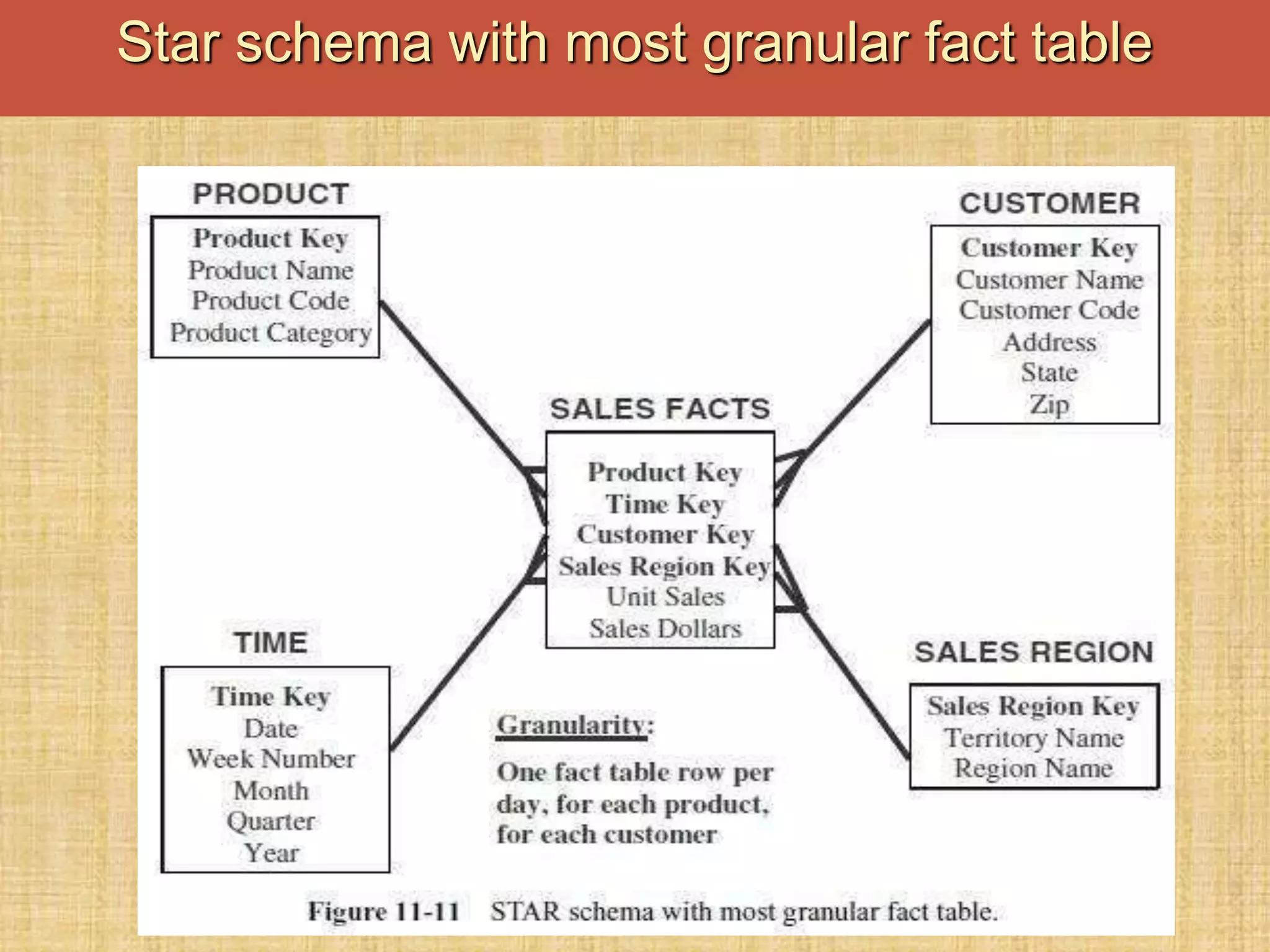
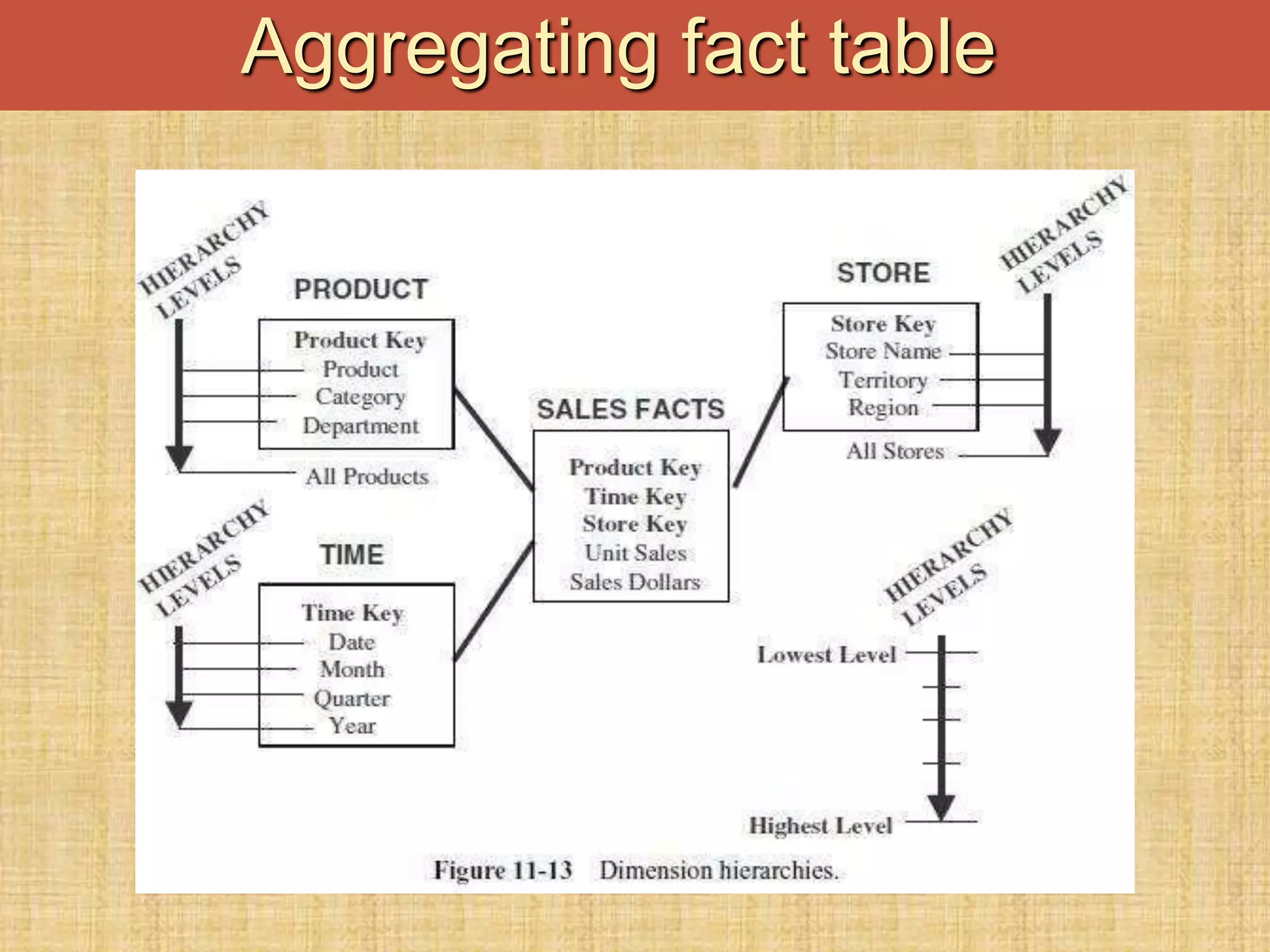
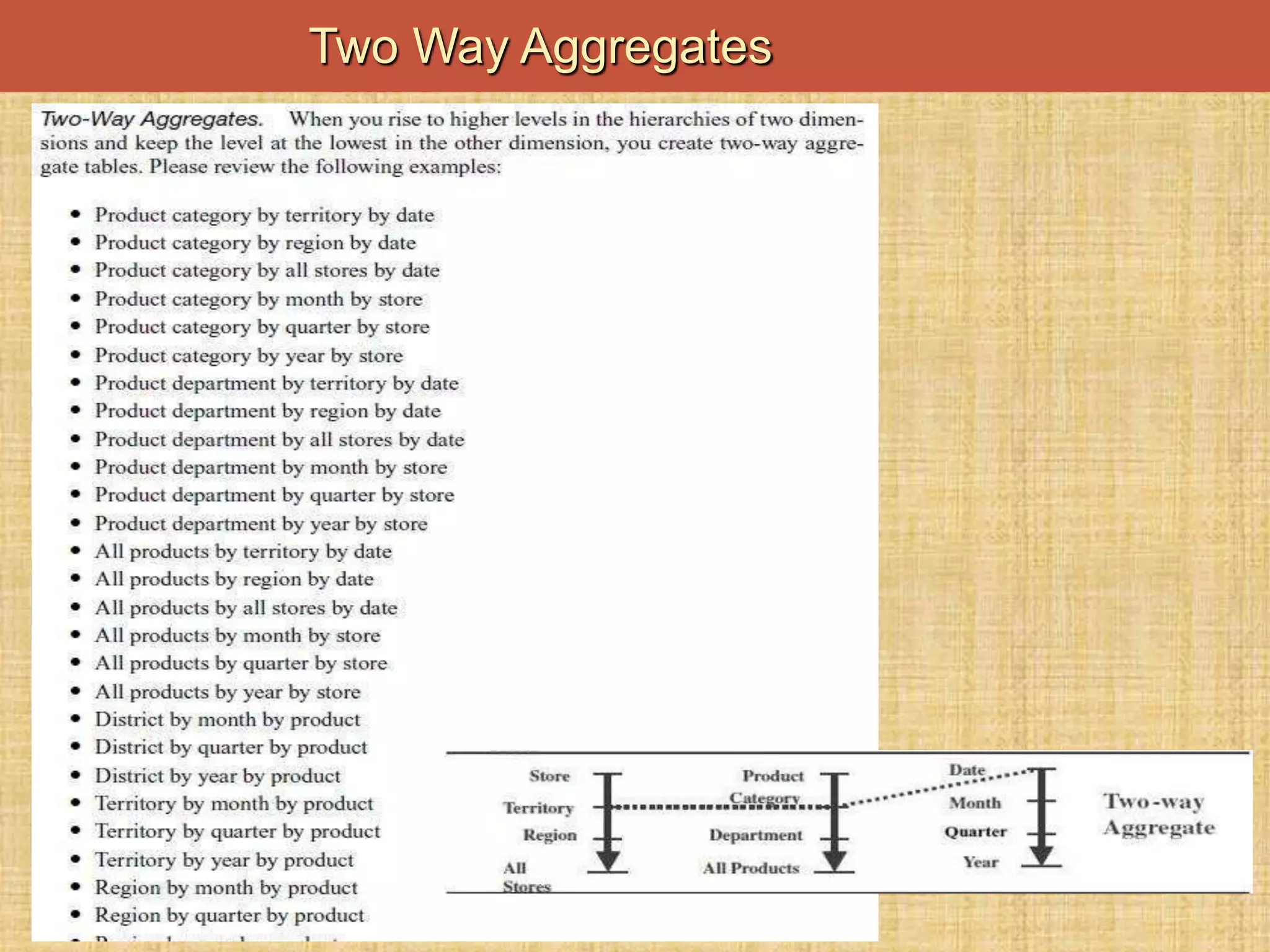
The document discusses database keys critical for identifying rows in tables within data warehousing, including super keys, primary keys, candidate keys, foreign keys, and surrogate keys. It emphasizes the importance of these keys in maintaining data integrity, establishing relationships between tables, and supporting the structure of fact and dimension tables in a data warehouse. Additionally, it introduces concepts like factless fact tables and different types of aggregations used in reporting and forecasting.