Downloaded 11 times






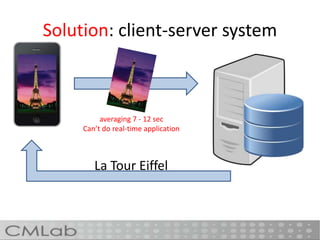
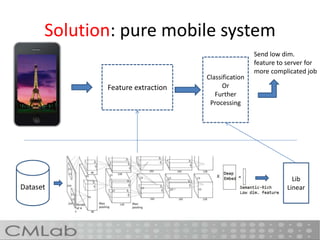




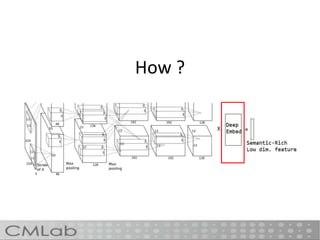





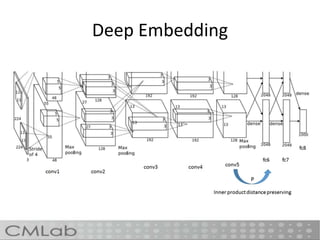
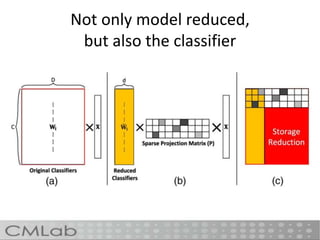

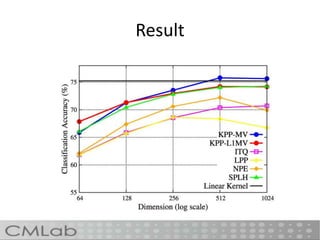

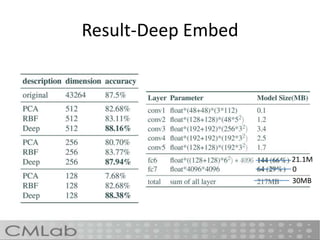



This document proposes a method called deep embedding to perform scalable image recognition on mobile and IoT devices. Deep neural networks achieve high performance but require too many parameters to run on limited devices. The method uses kernel preserving projection to project features from a pretrained DNN into a lower dimensional space, reducing parameters by 86% while only dropping accuracy 1.12%. This allows image classification to be done directly on mobile and IoT devices using a small, efficient model encoded with high-level semantic information from DNNs.








![[Impl] neural machine translation](https://cdn.slidesharecdn.com/ss_thumbnails/implneuralmachinetranslation-191030053355-thumbnail.jpg?width=640&height=640&fit=bounds)

































































