Download as PDF, PPTX






















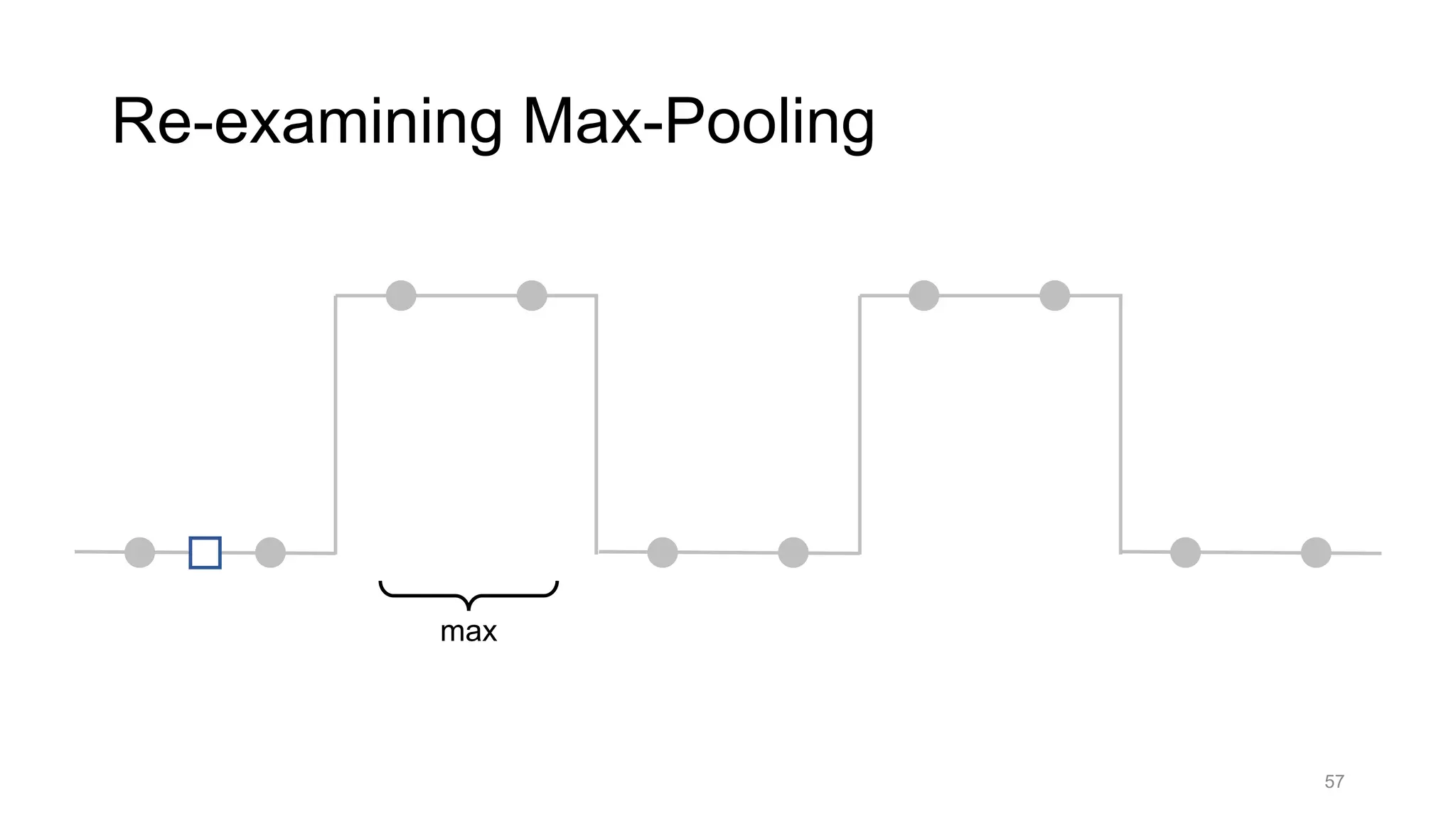
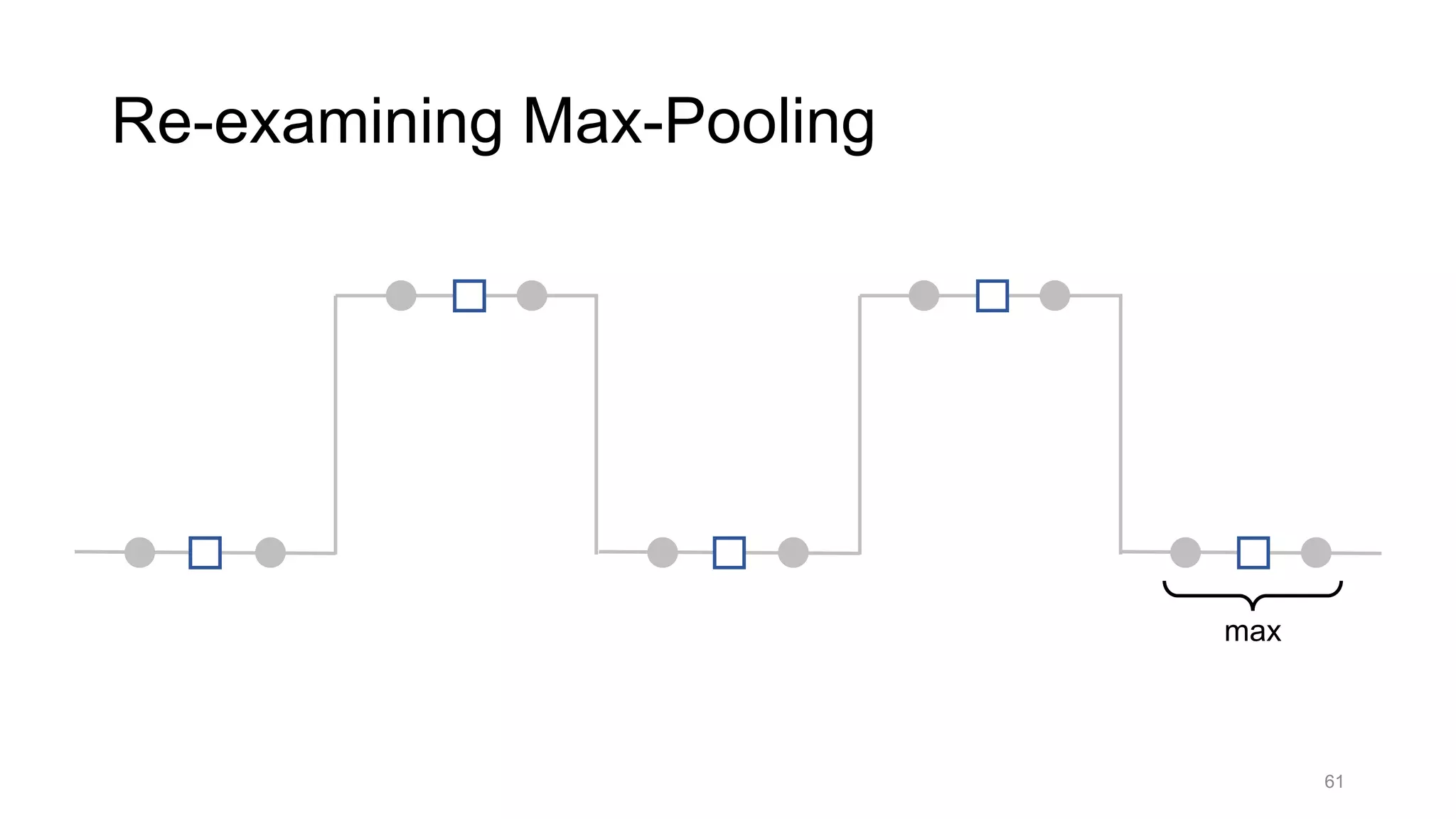
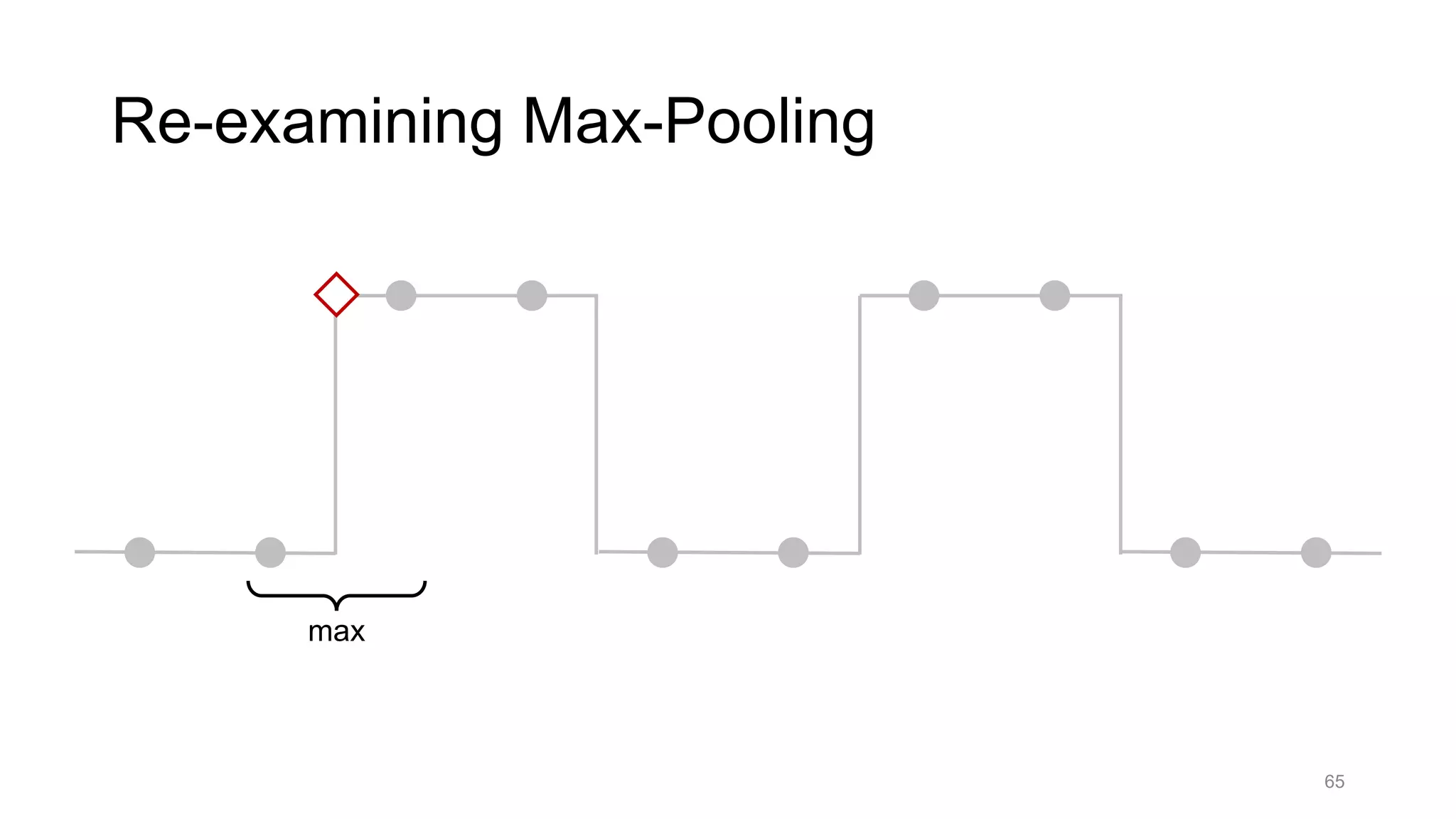
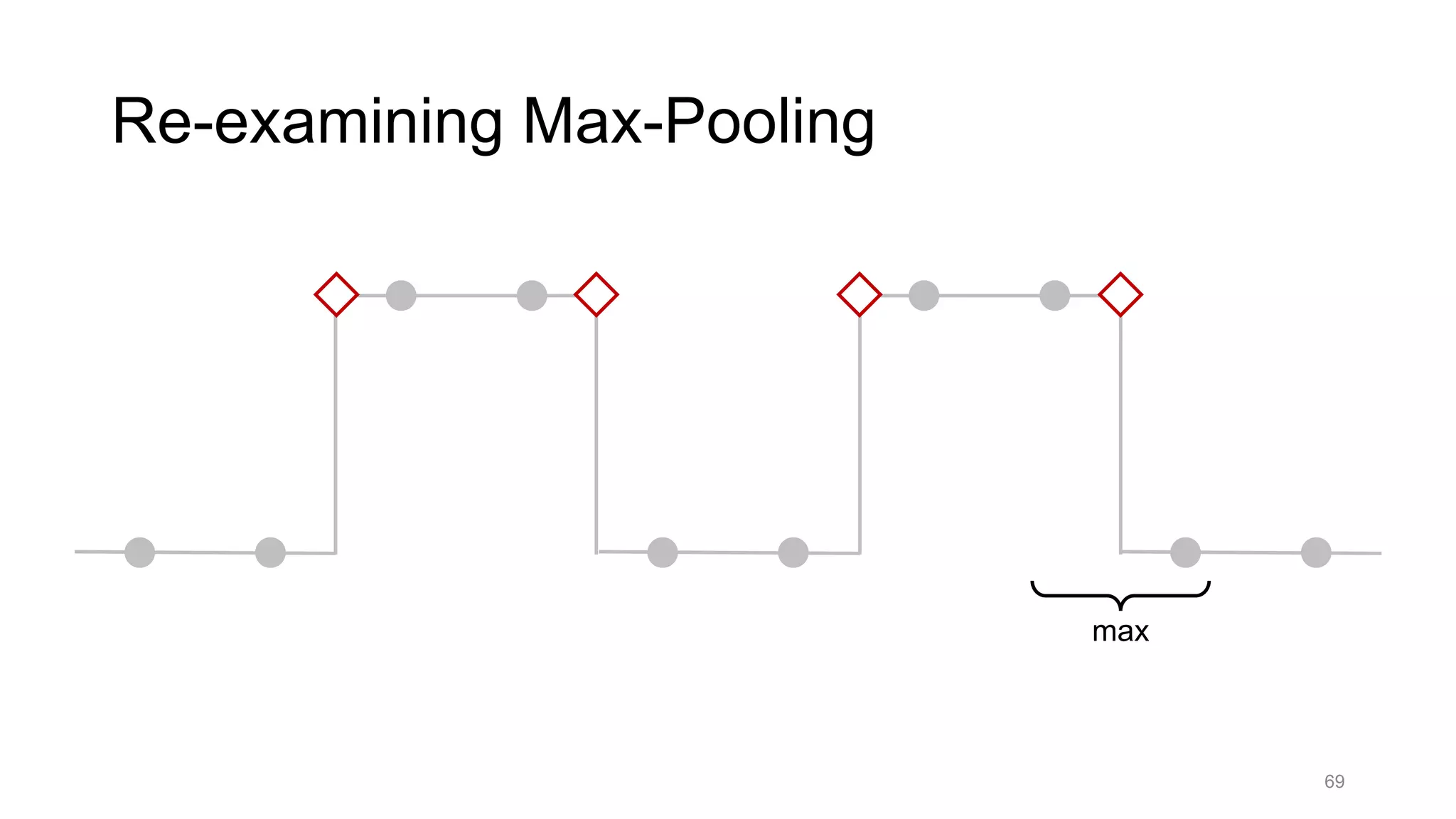


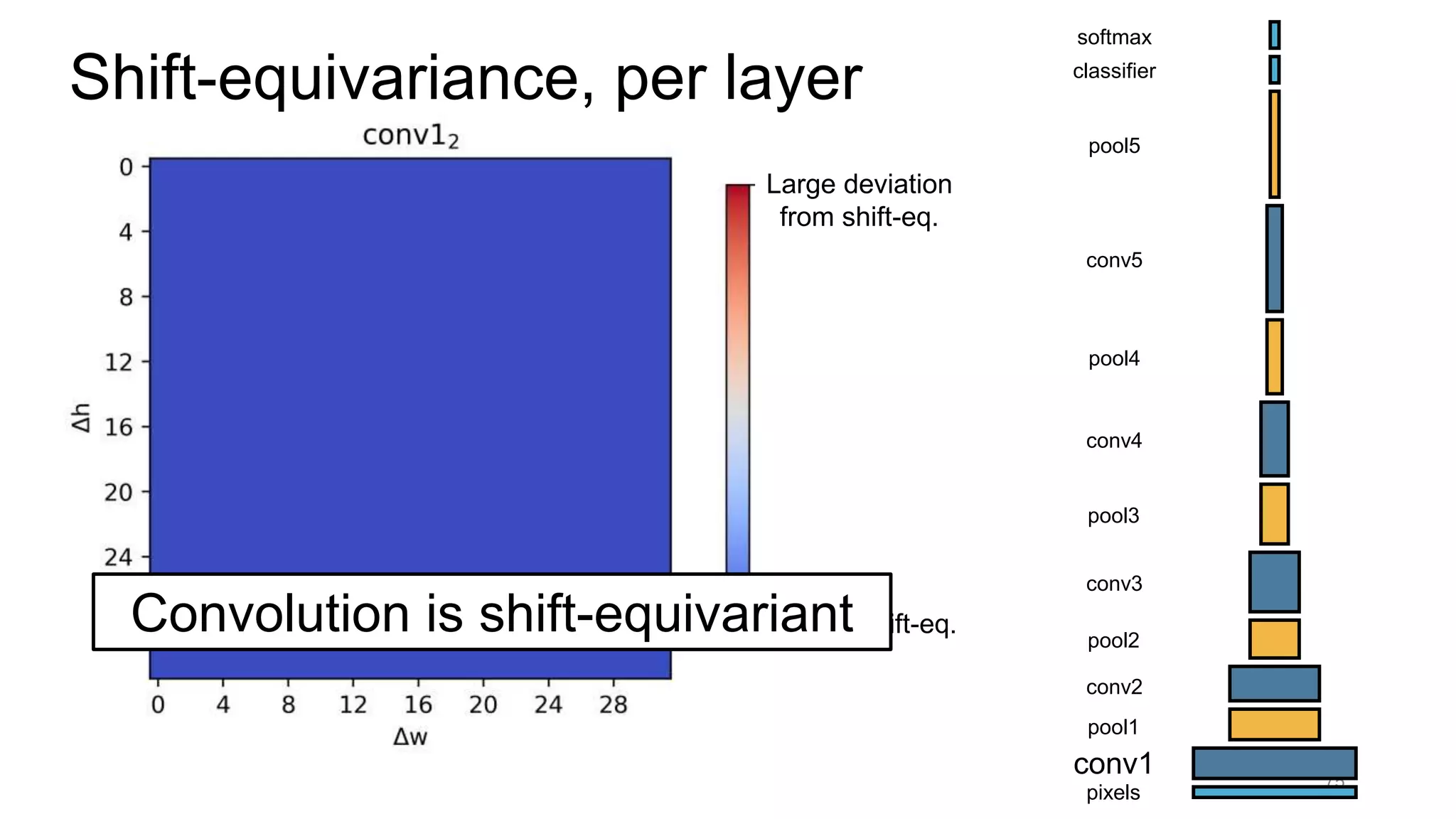
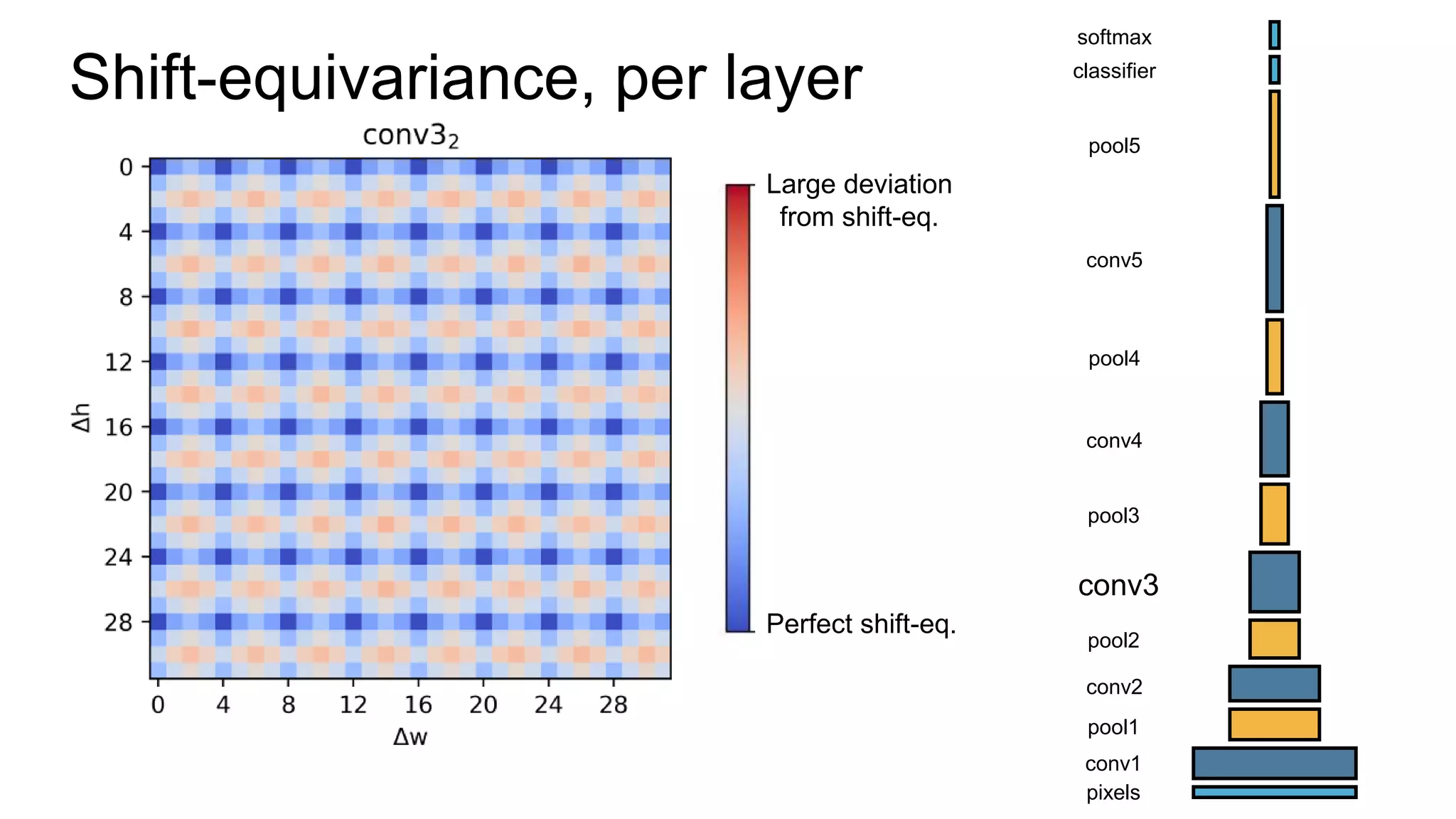
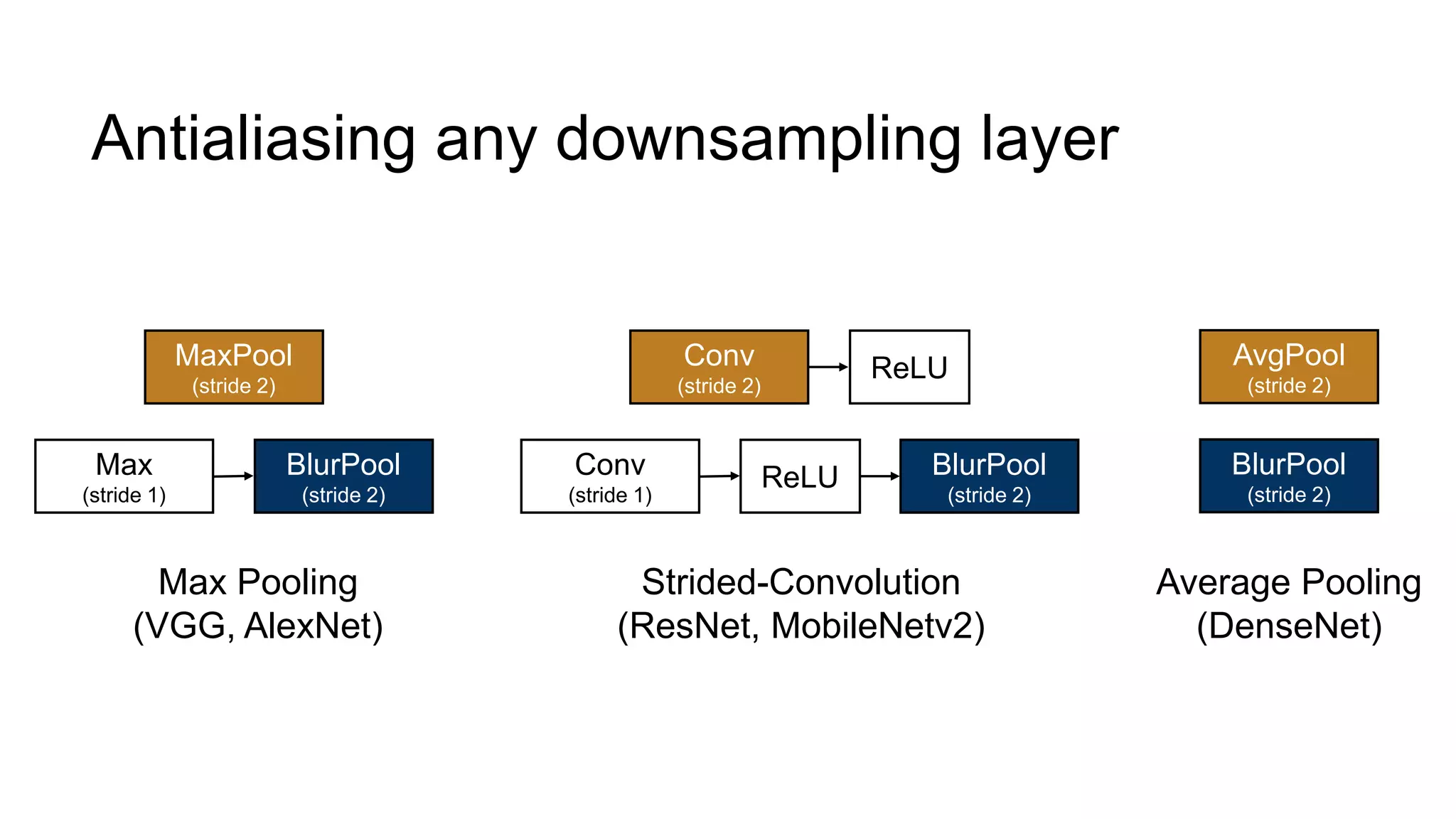
![Alternative downsampling methods
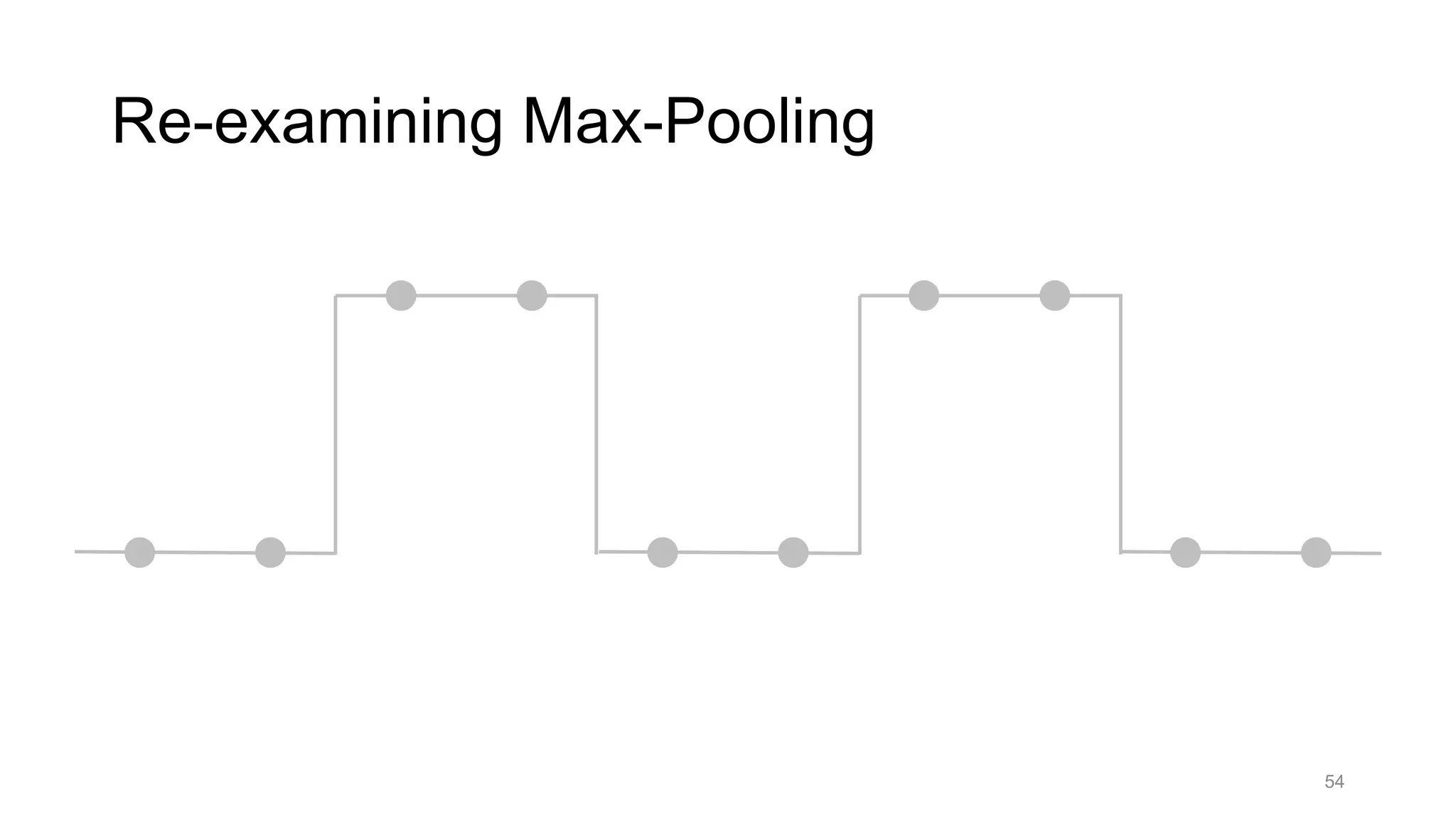
• Blur+subsample
• Antialiasing in signal processing; image processing; graphics
• Max-pooling
• Performs better in deep learning applications [Scherer 2010]
88](https://image.slidesharecdn.com/modelingperceptualsimilarityandshift-invarianceindeepnetworks-191121045001/75/Modeling-perceptual-similarity-and-shift-invariance-in-deep-networks-77-2048.jpg)
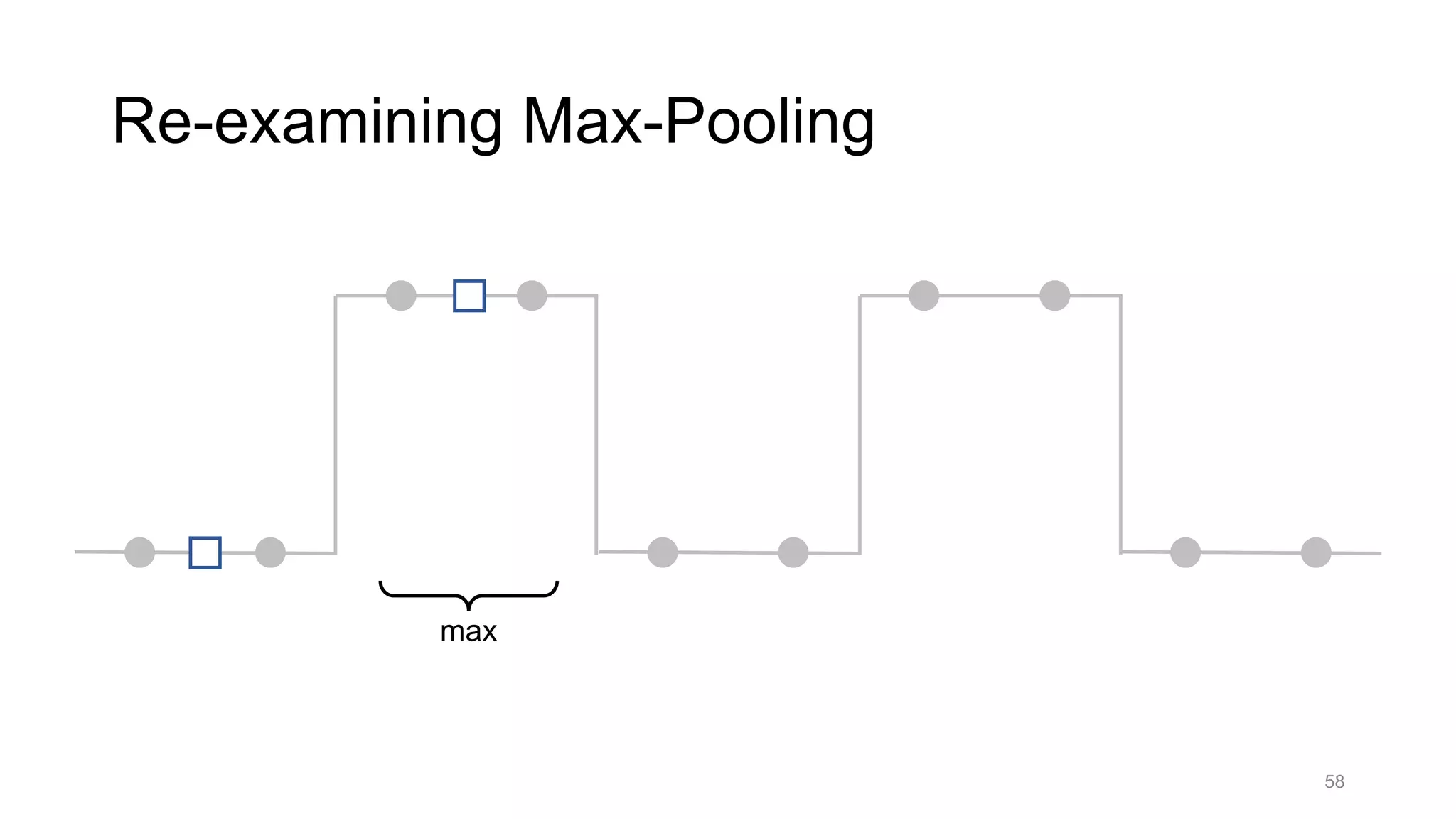
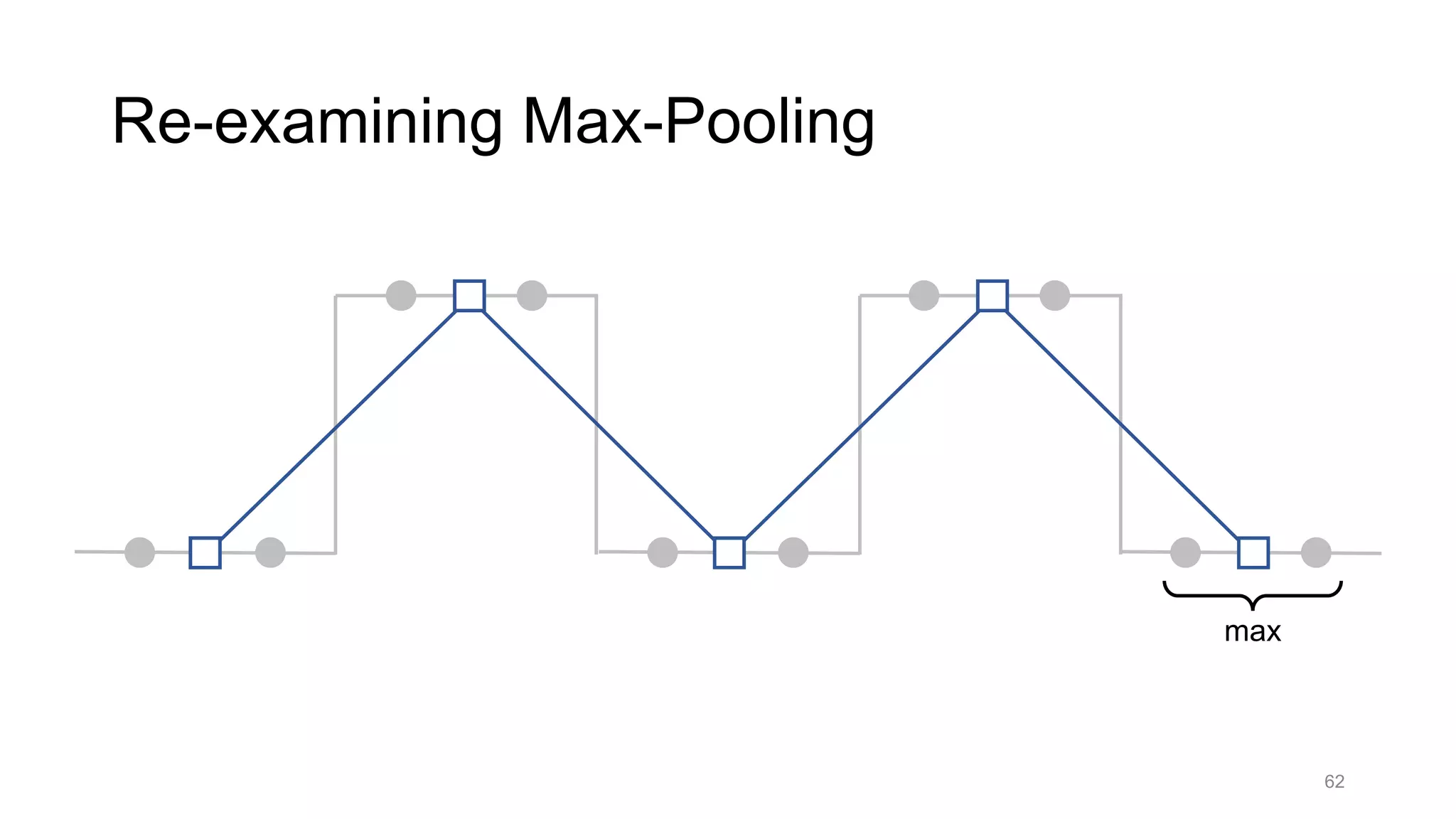
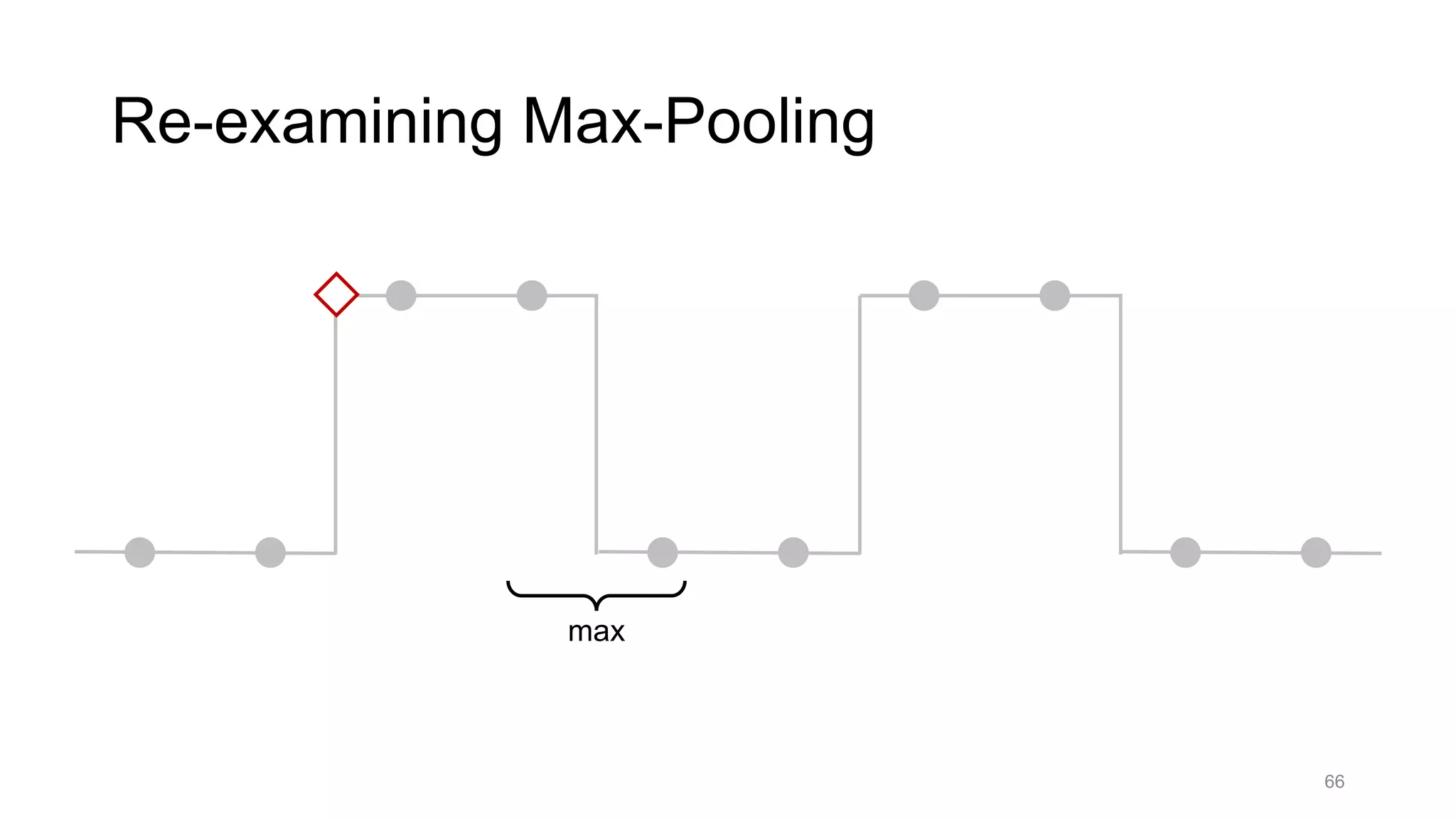
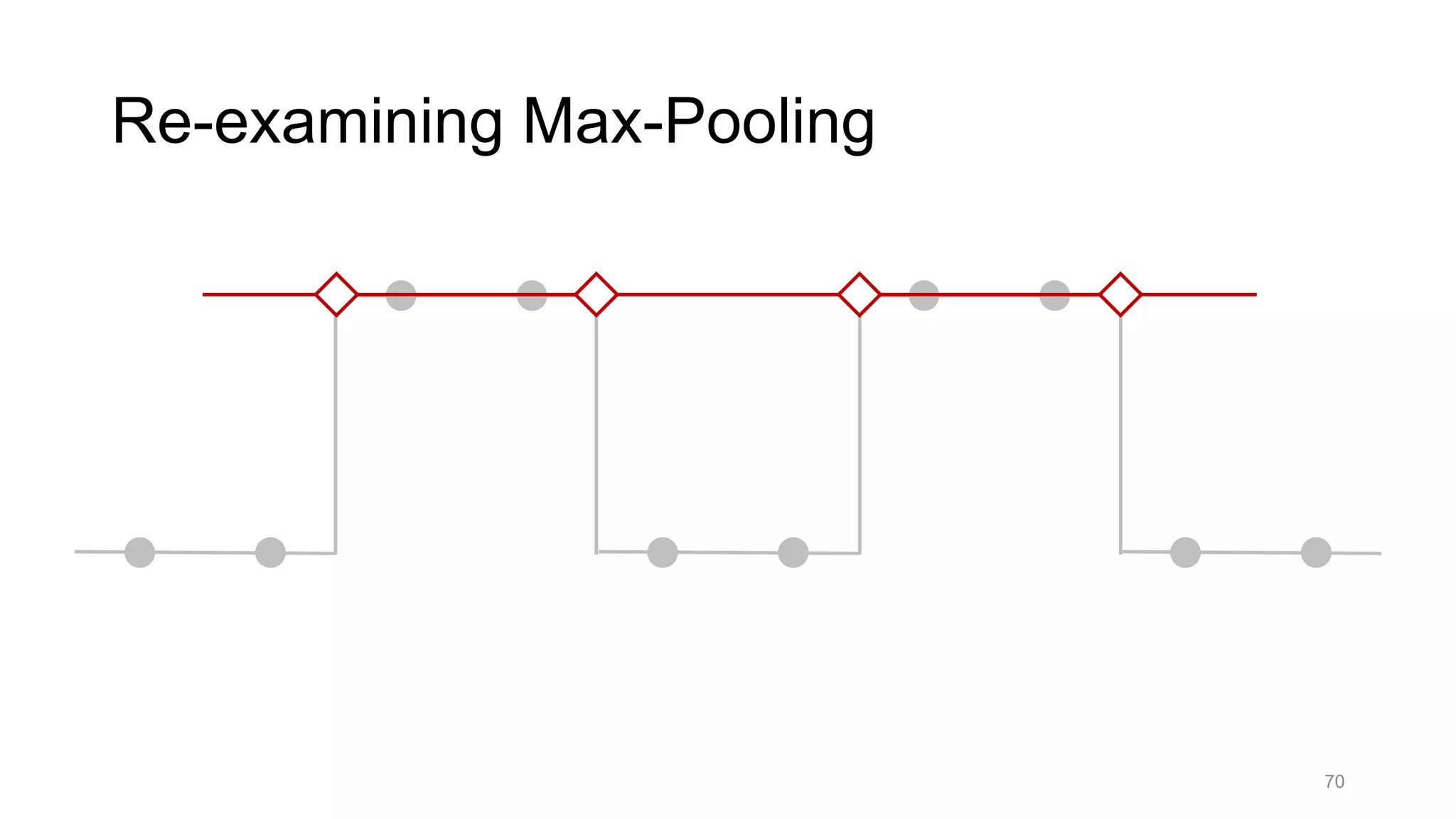
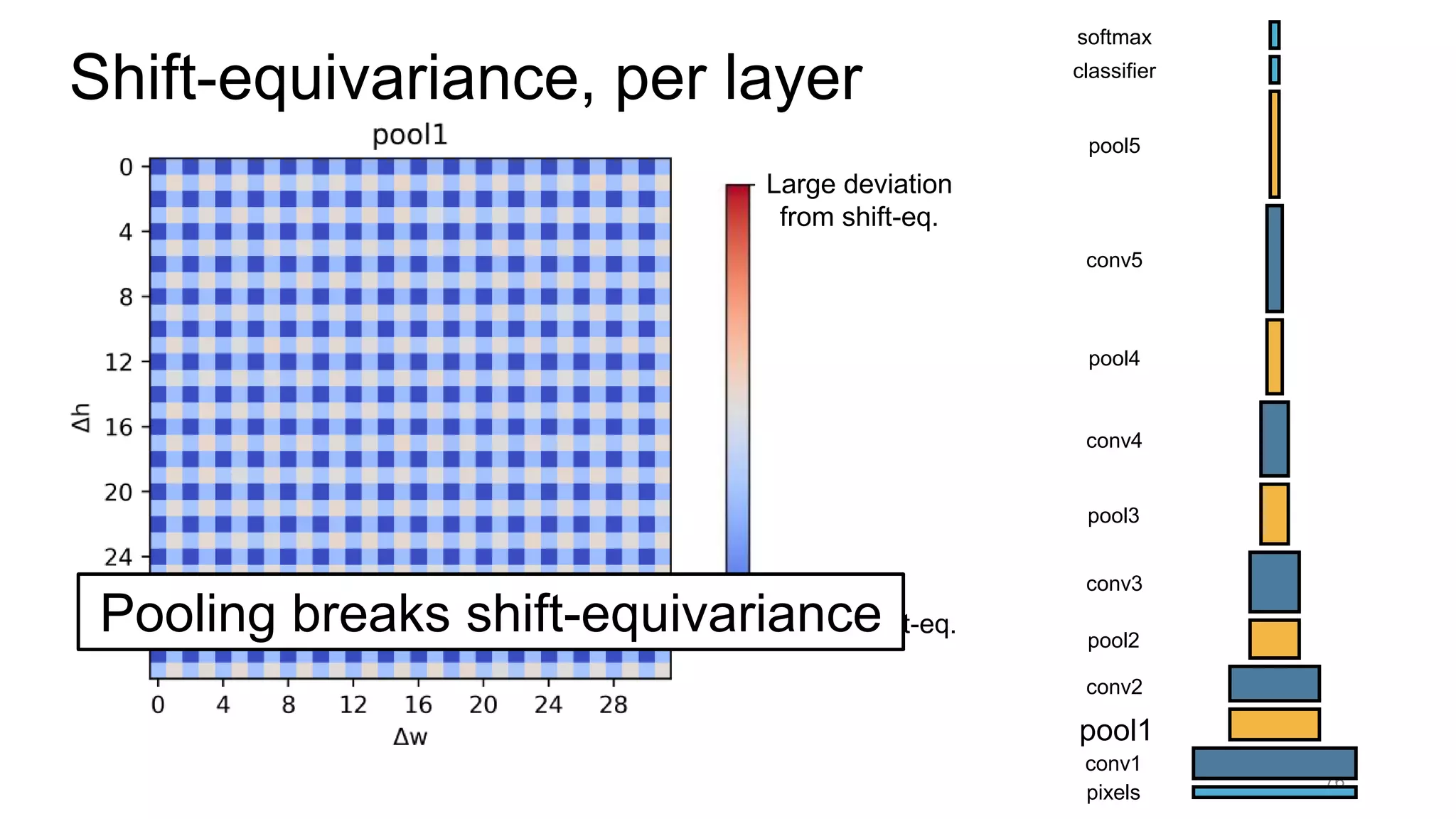
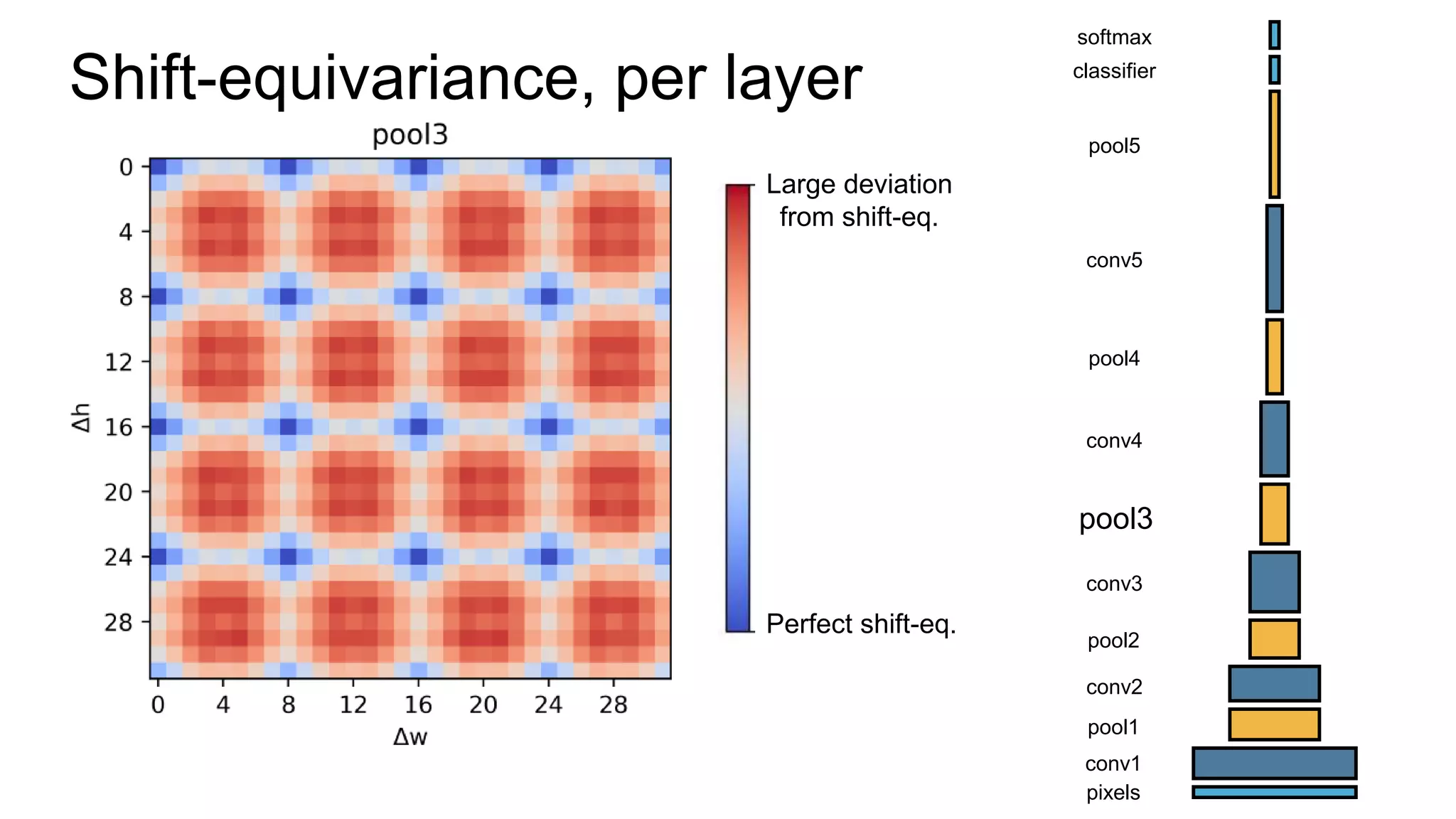
![Alternative downsampling methods
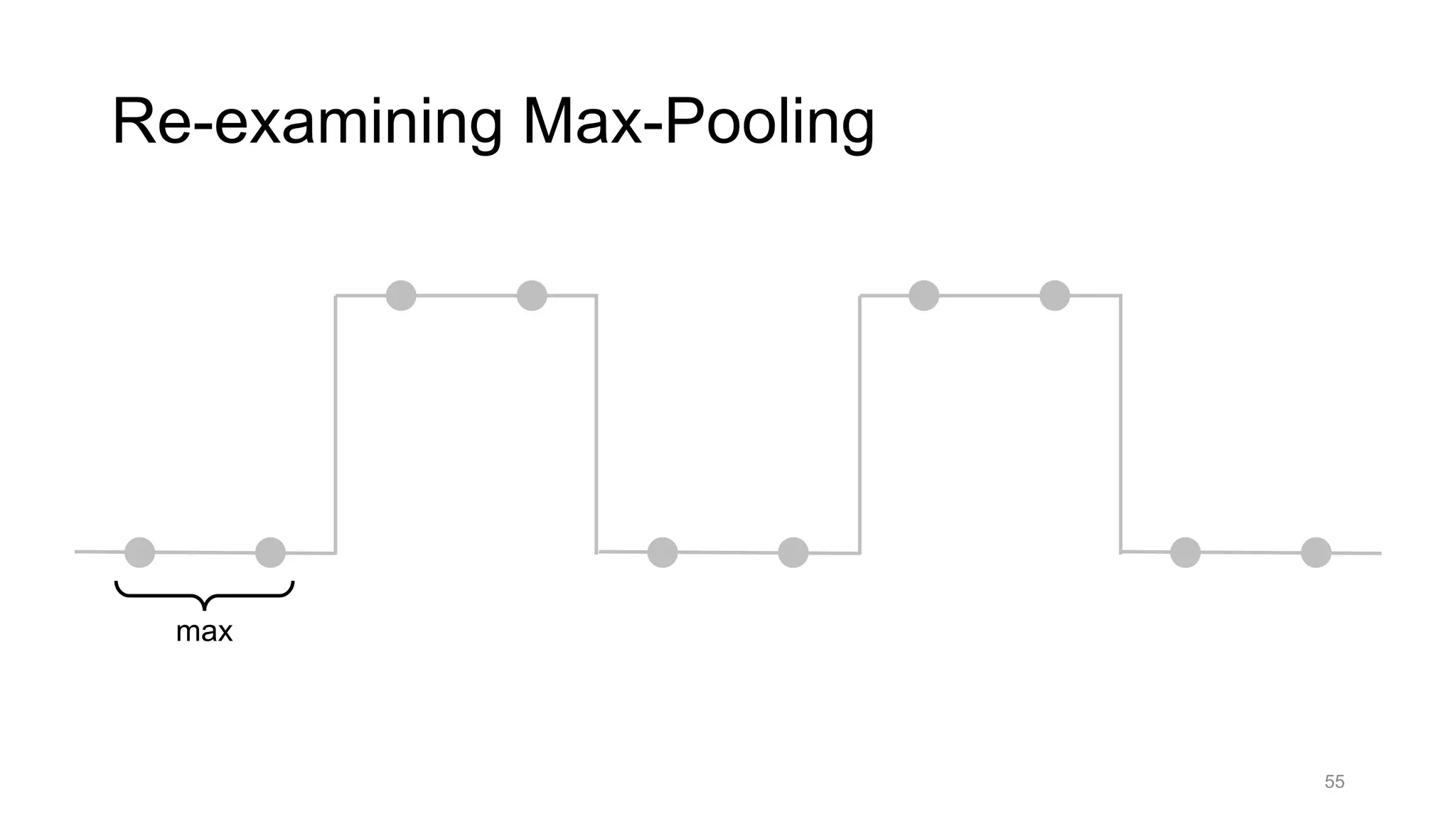
• Blur+subsample
• Antialiasing in signal processing; image processing; graphics
• Max-pooling
• Performs better for deep learning [Scherer 2010]
89](https://image.slidesharecdn.com/modelingperceptualsimilarityandshift-invarianceindeepnetworks-191121045001/75/Modeling-perceptual-similarity-and-shift-invariance-in-deep-networks-78-2048.jpg)
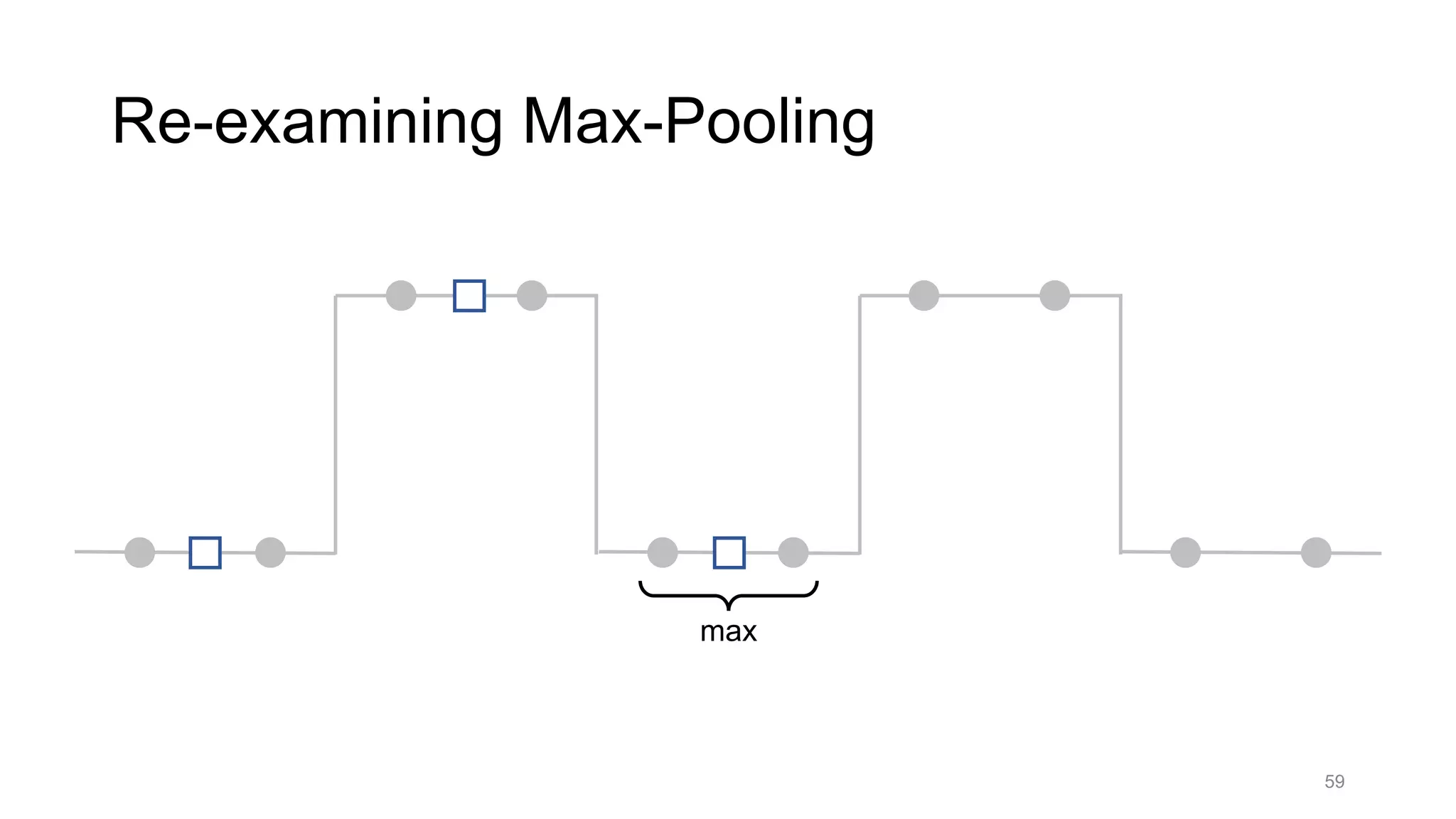
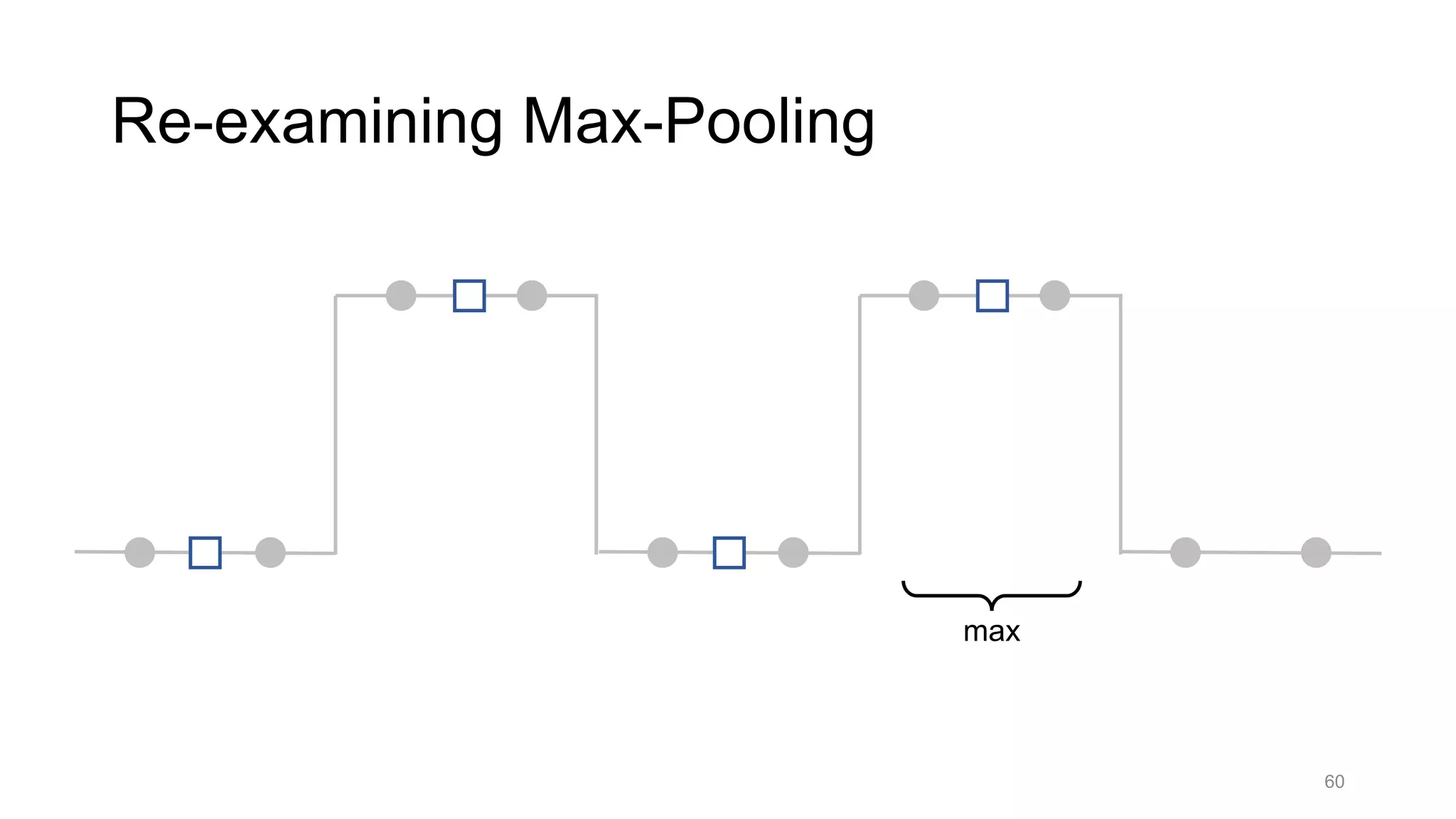
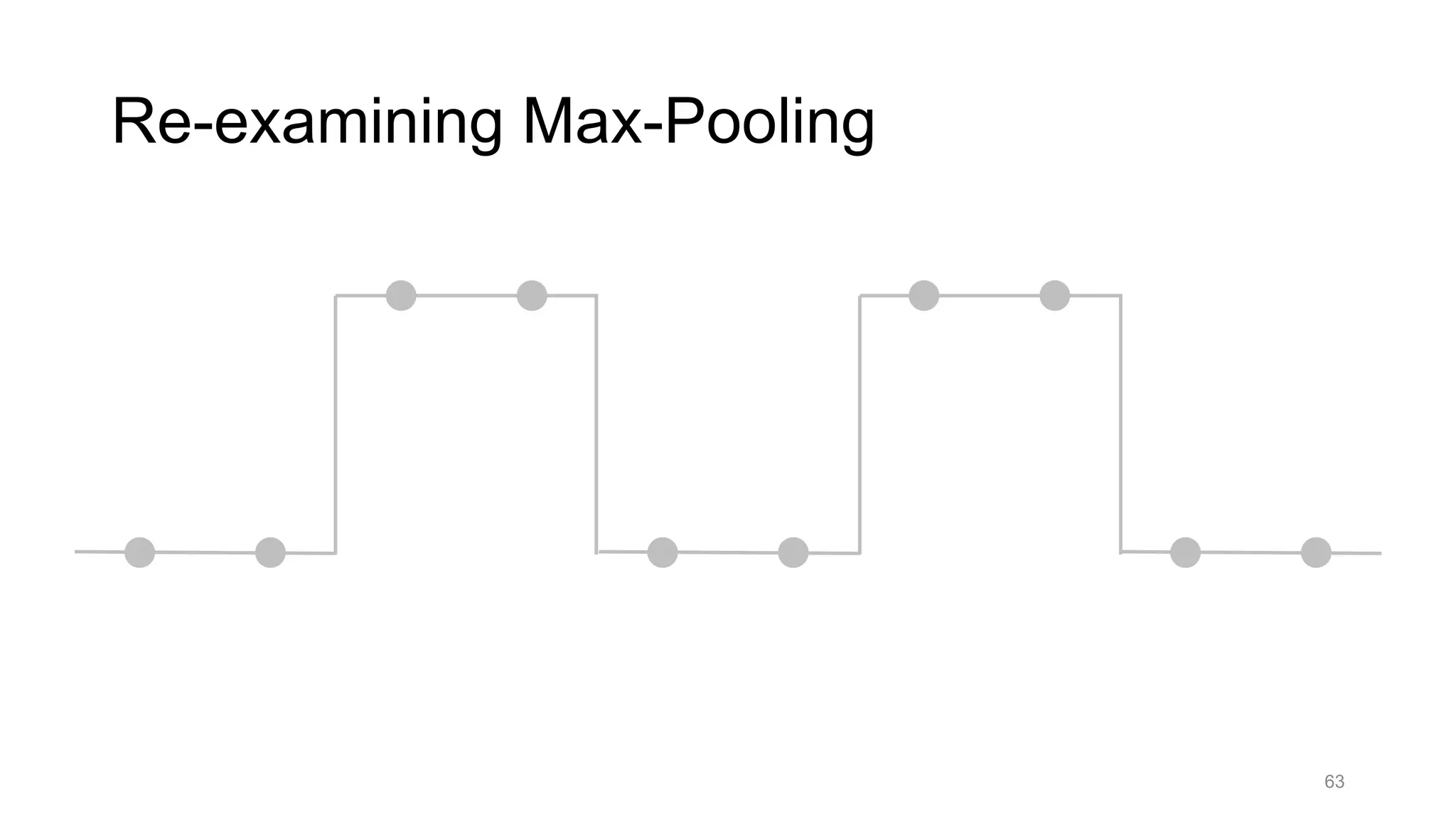
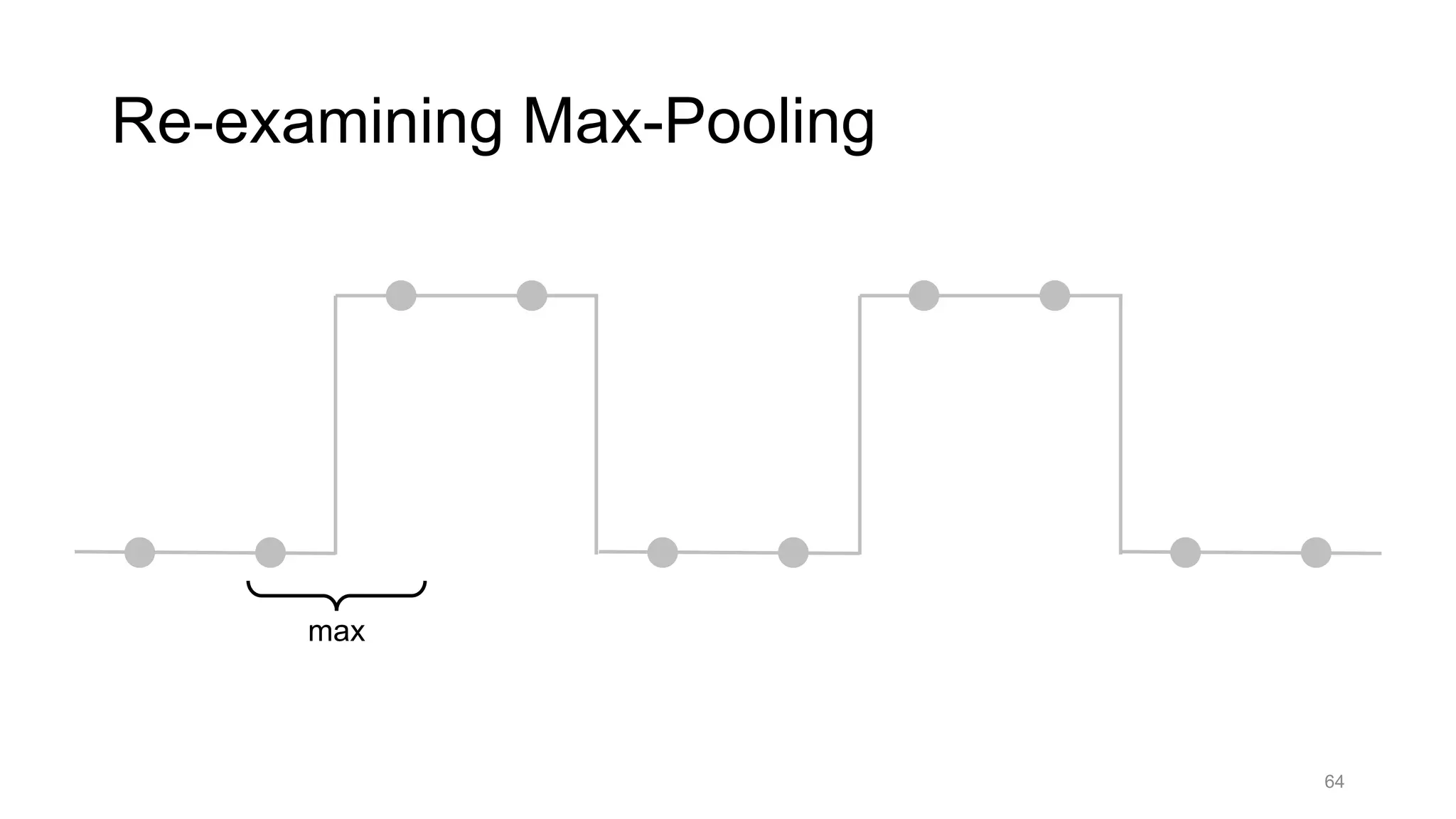
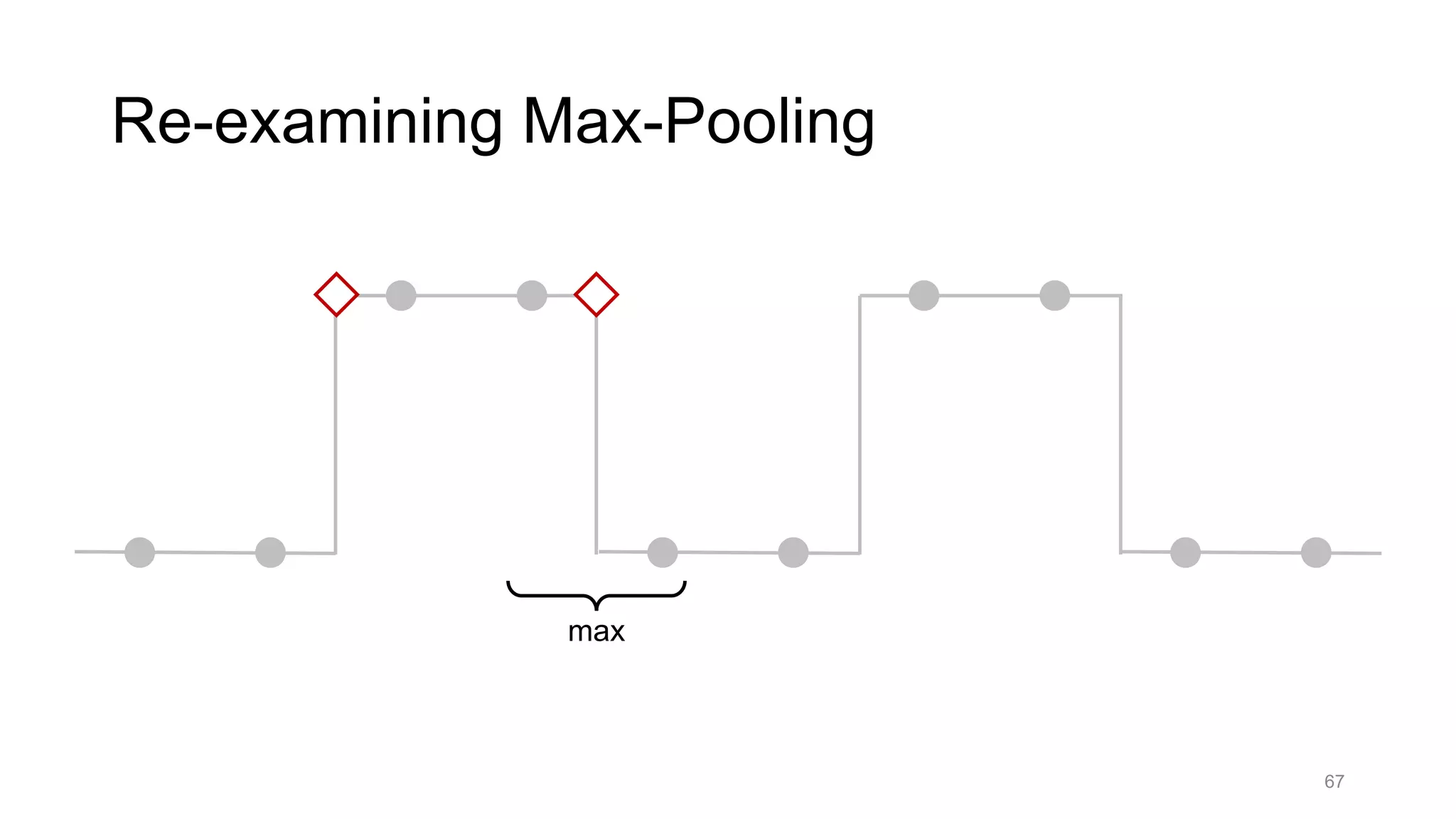
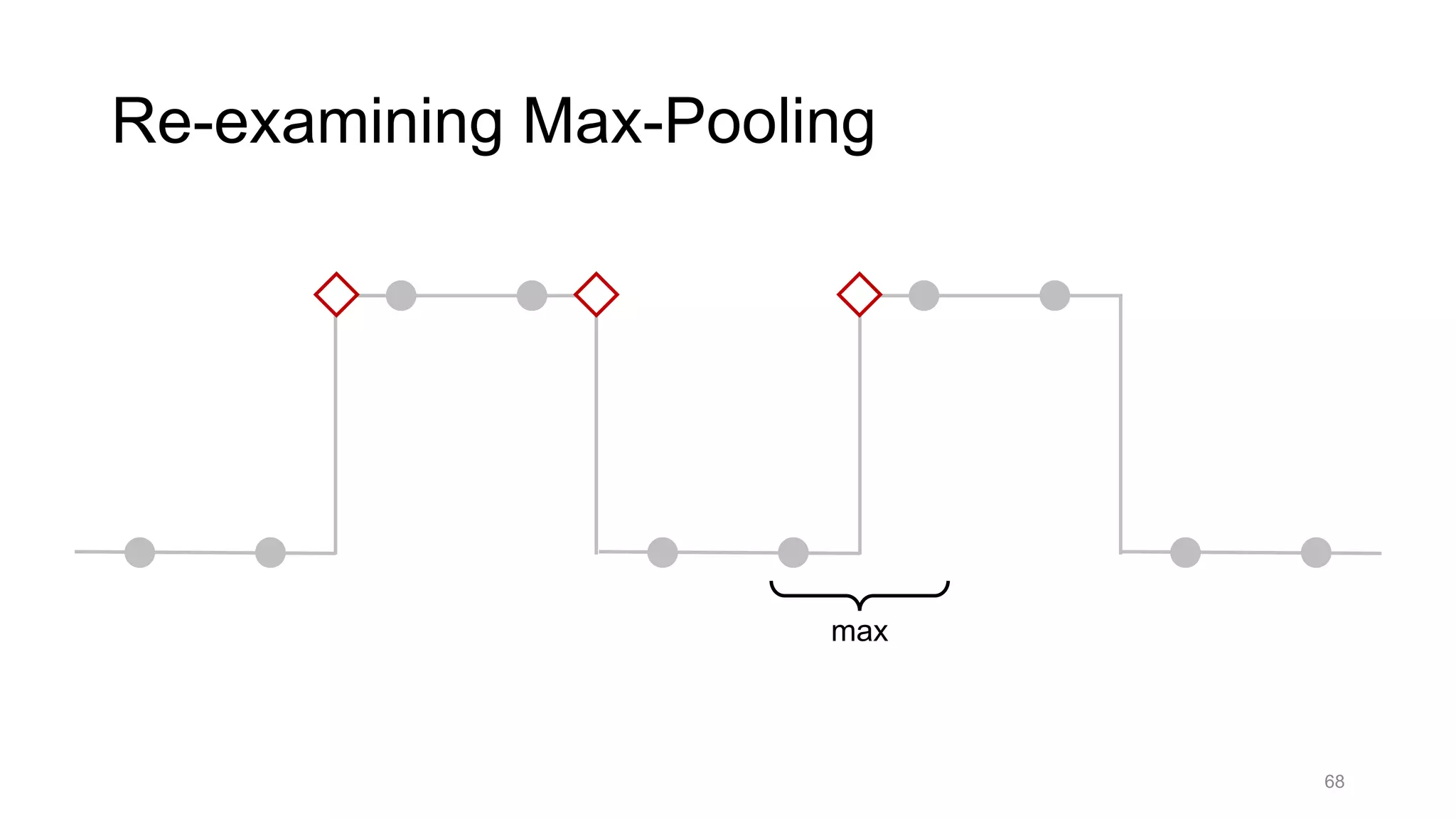
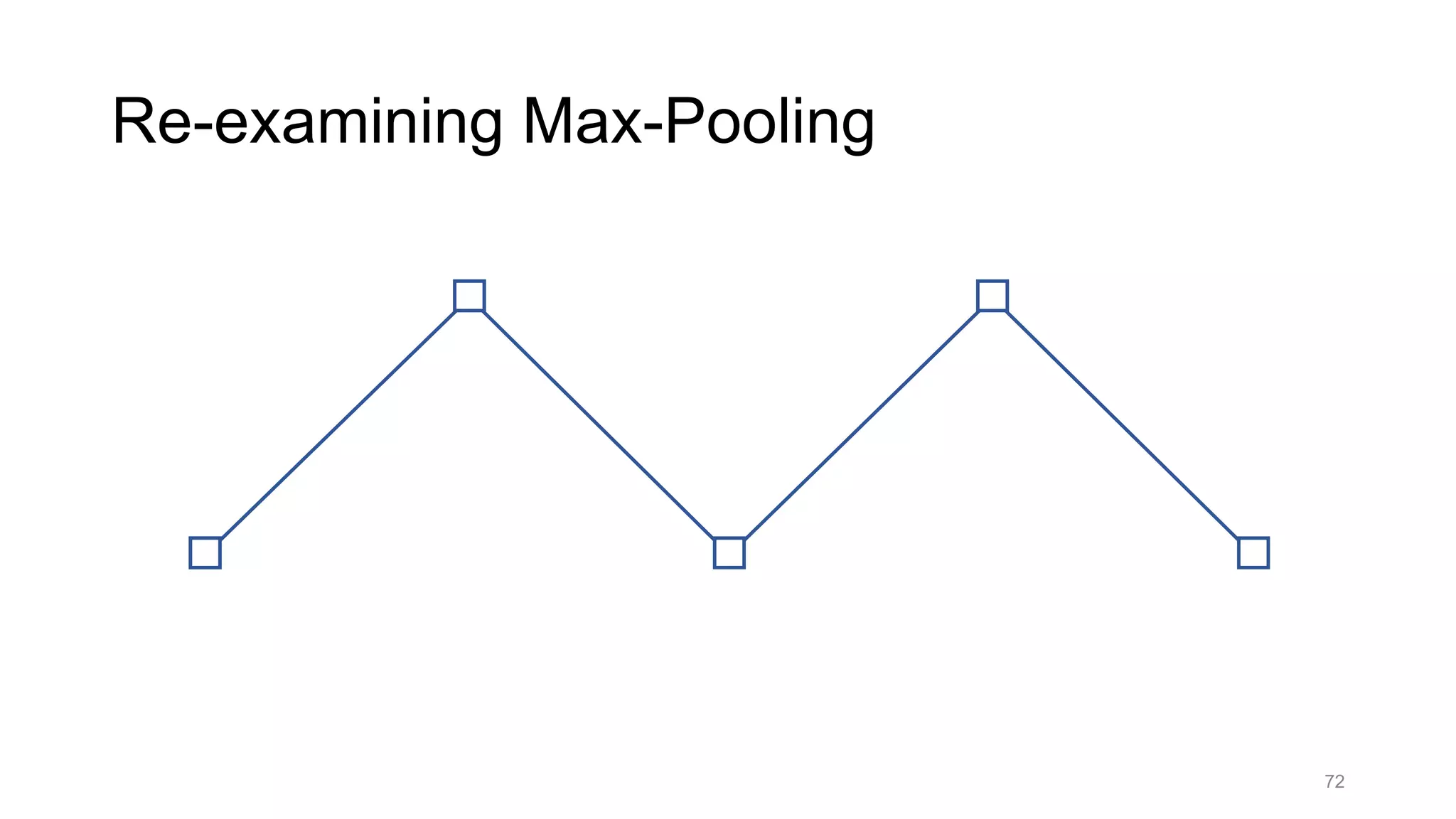
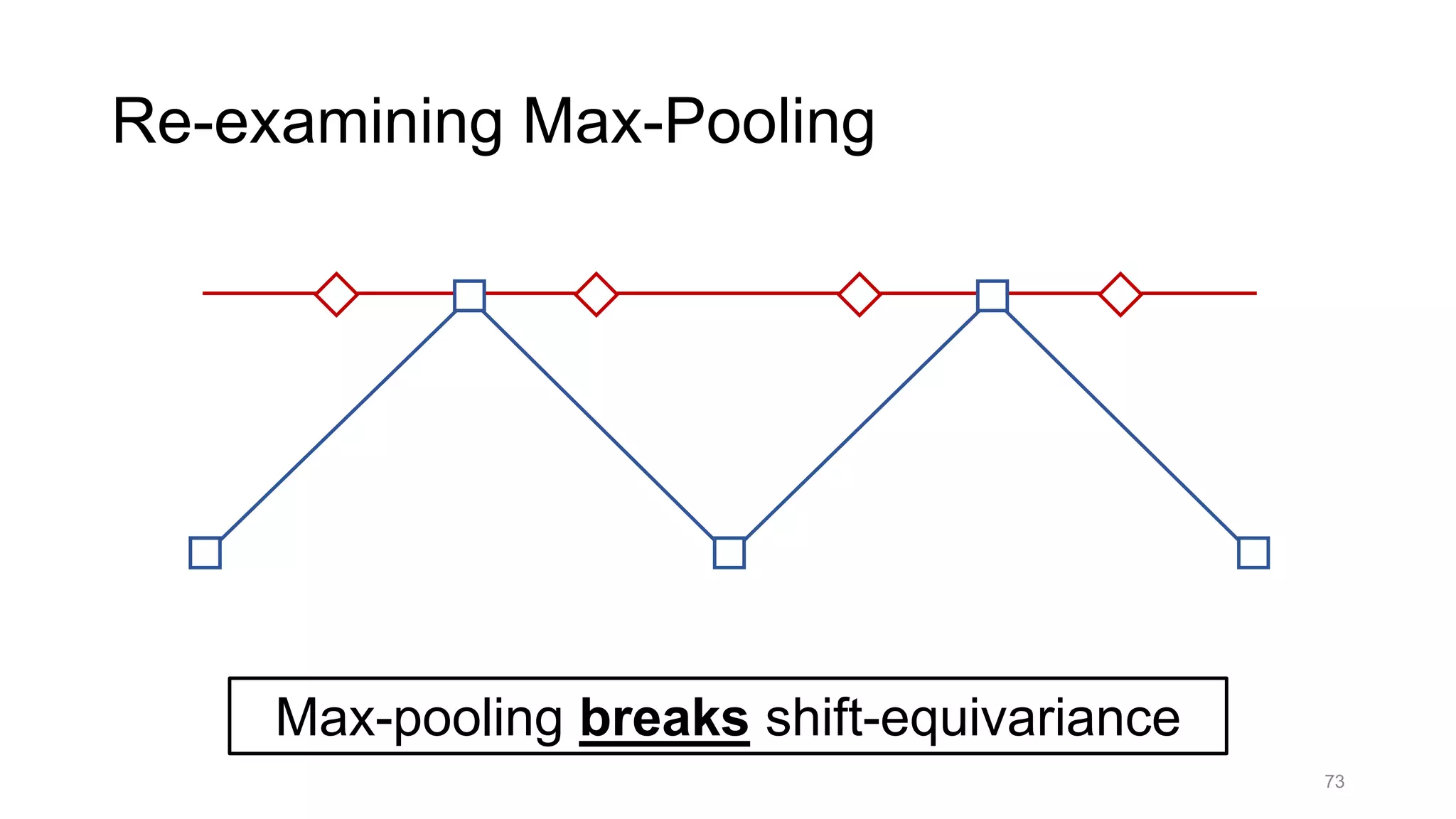
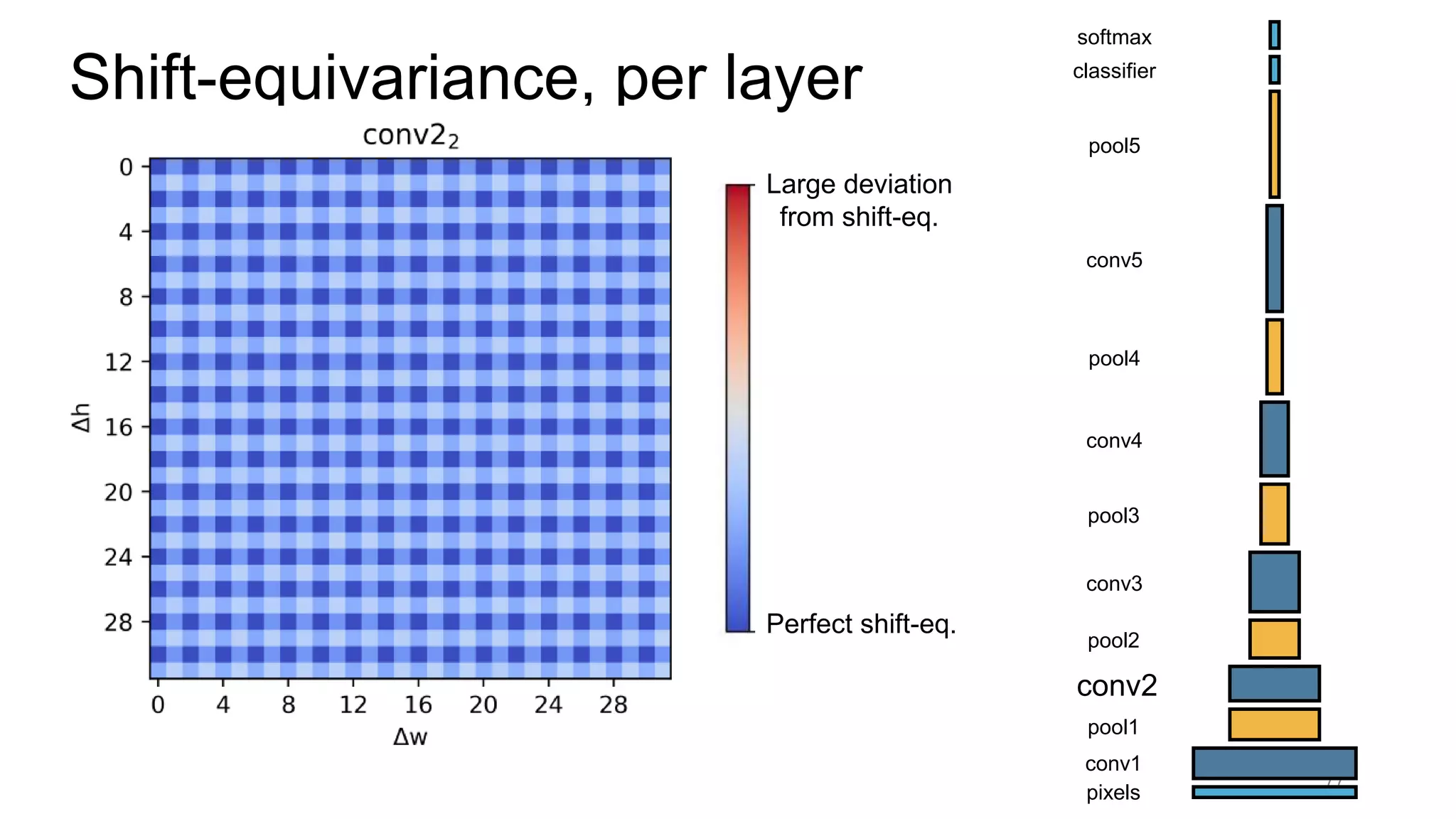
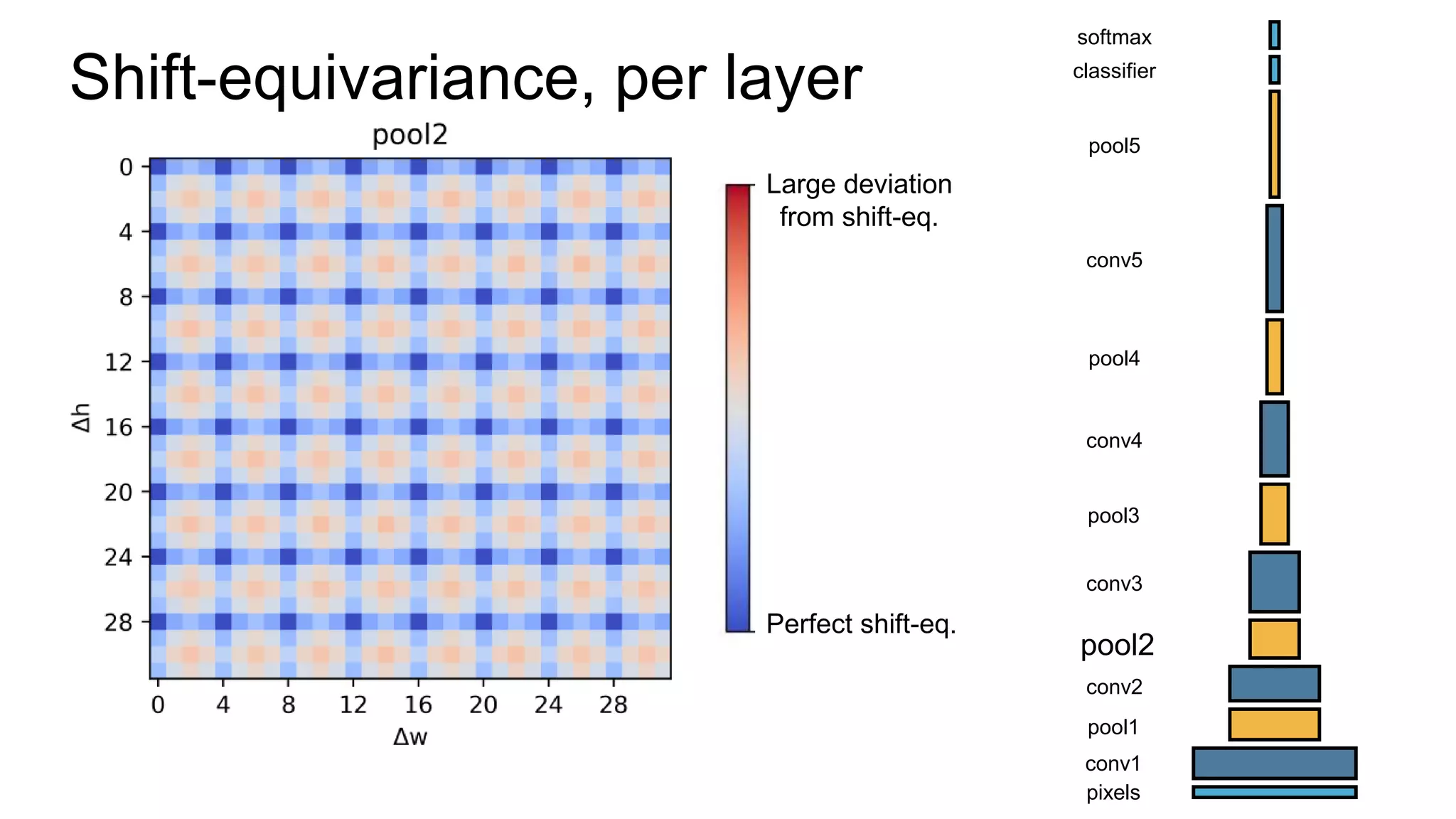
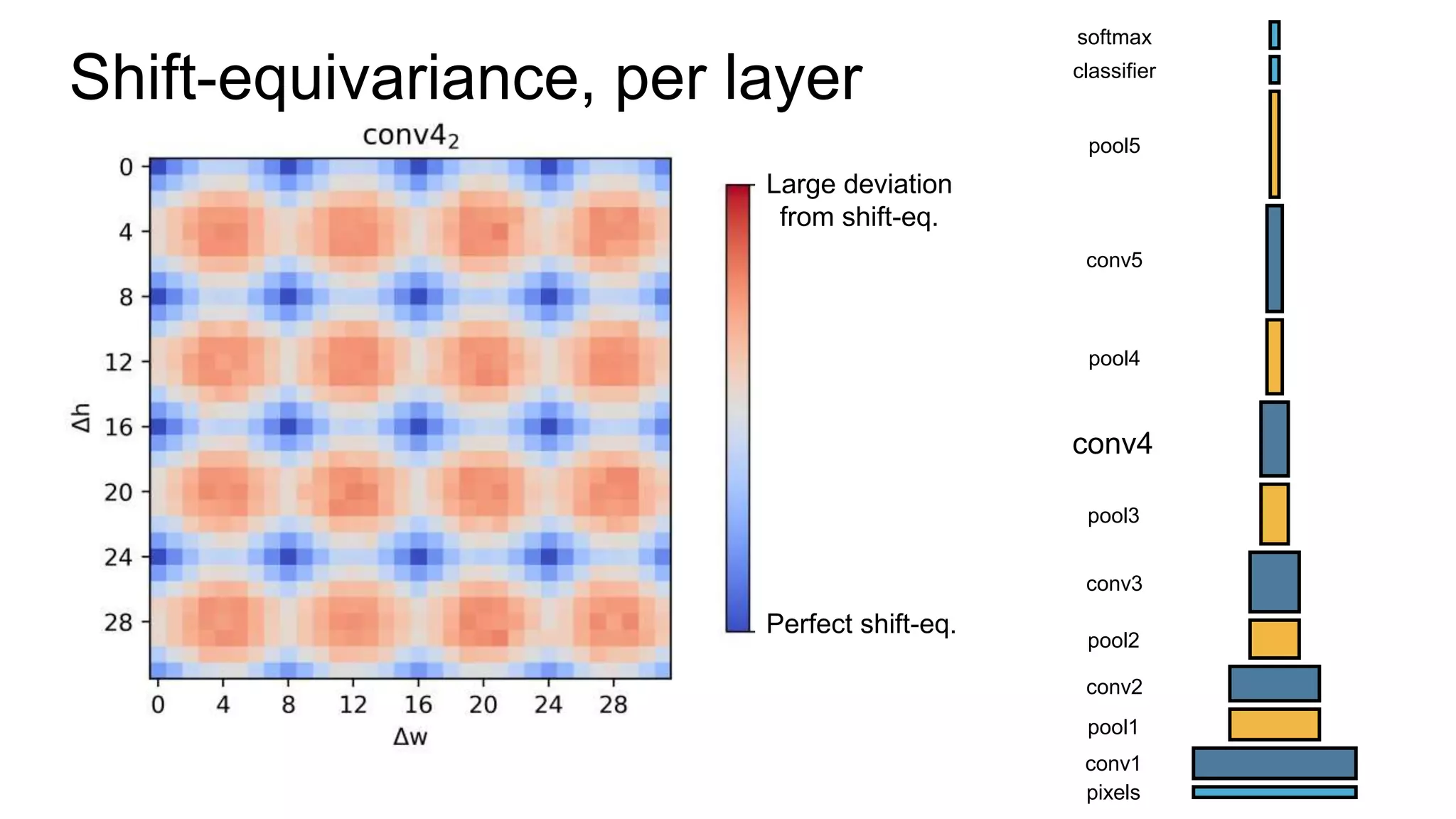
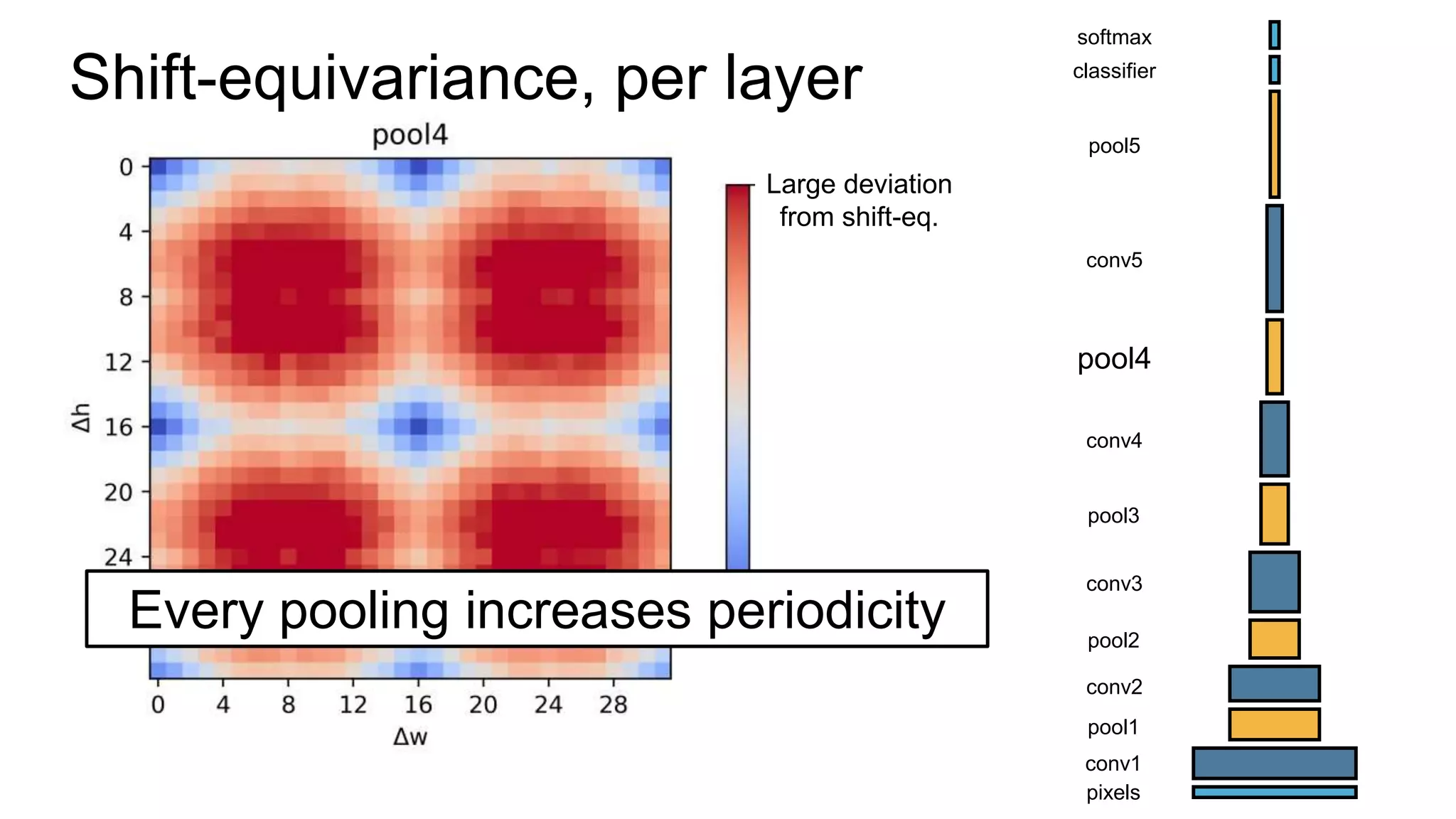
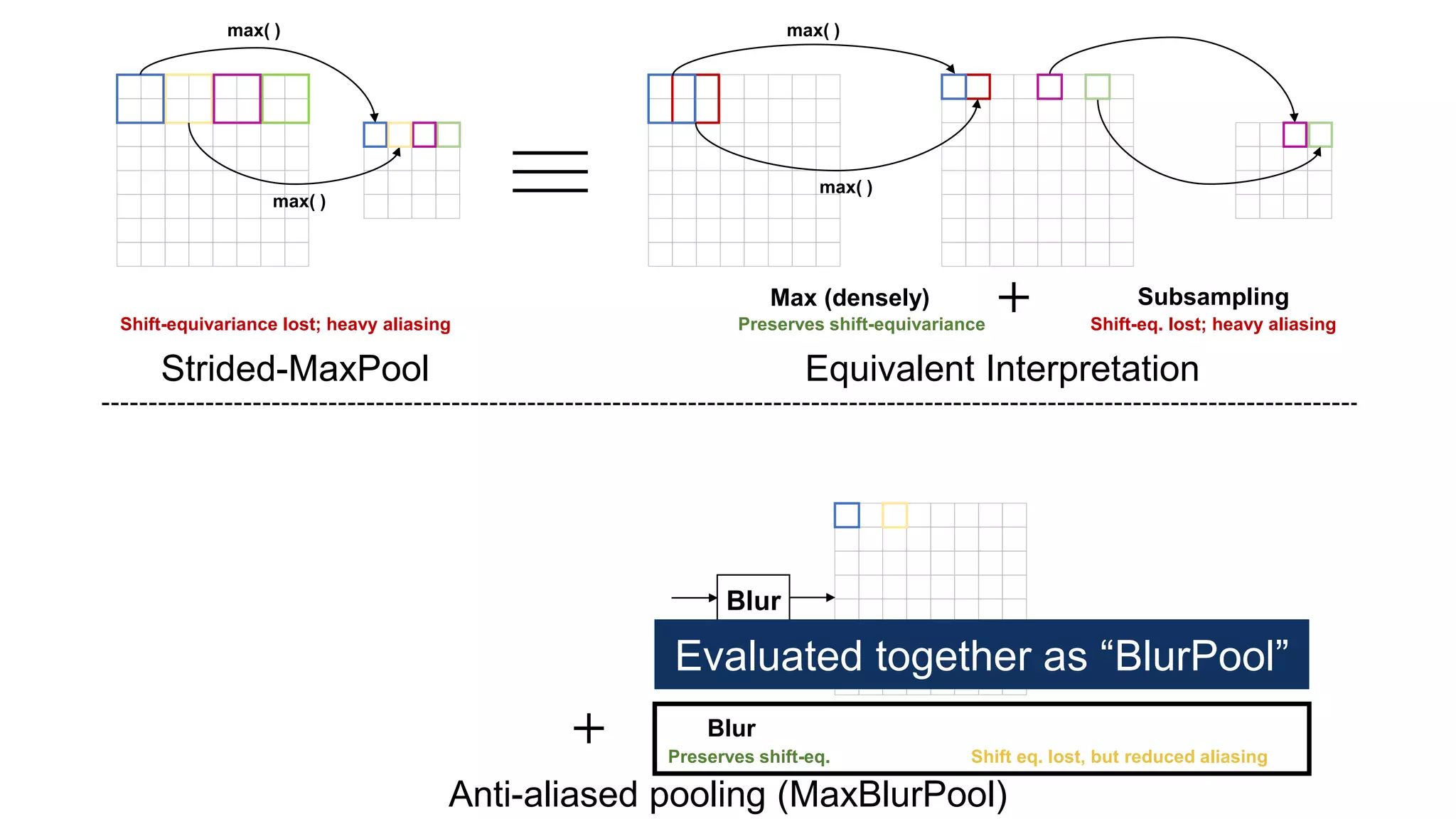
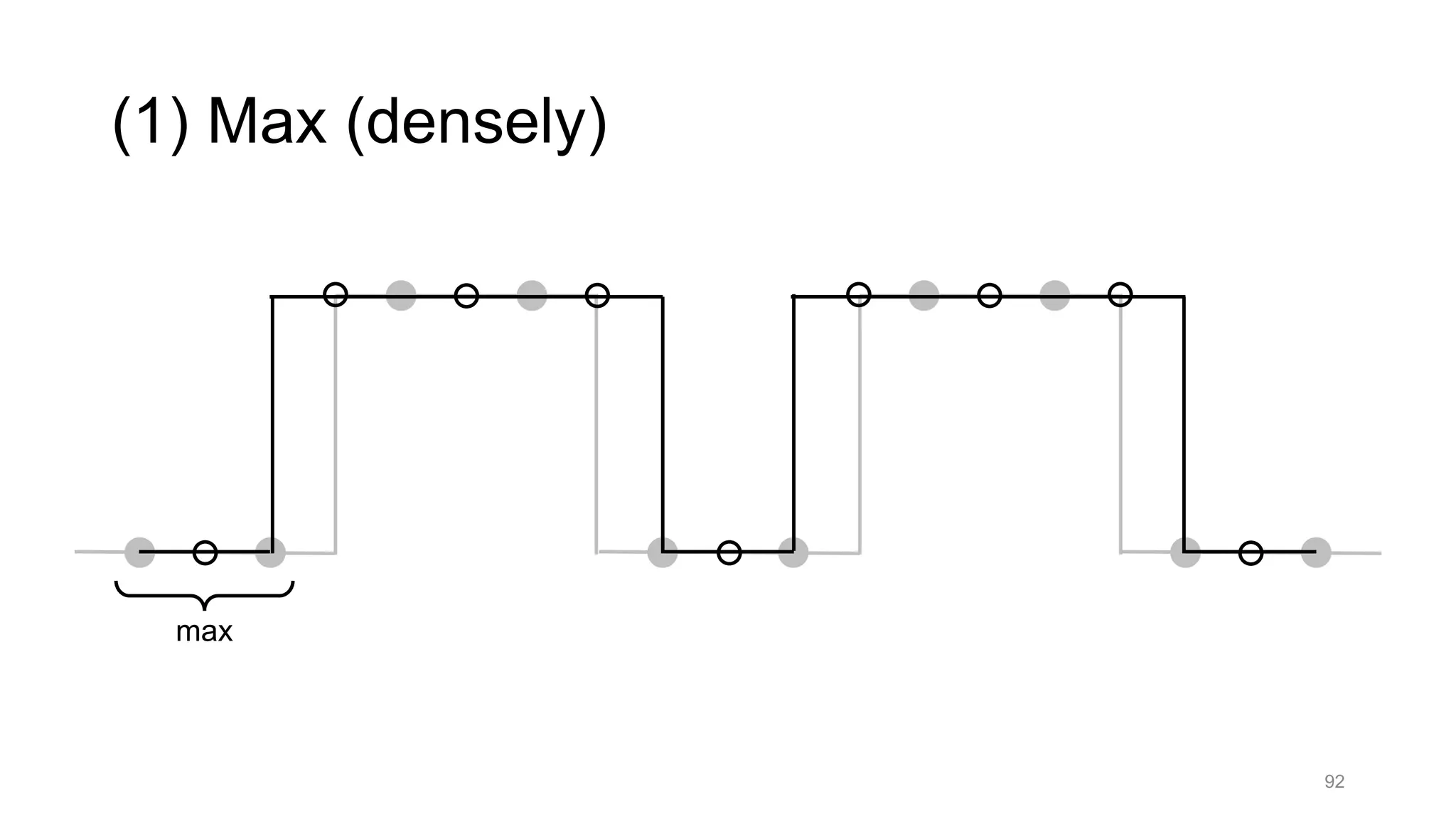
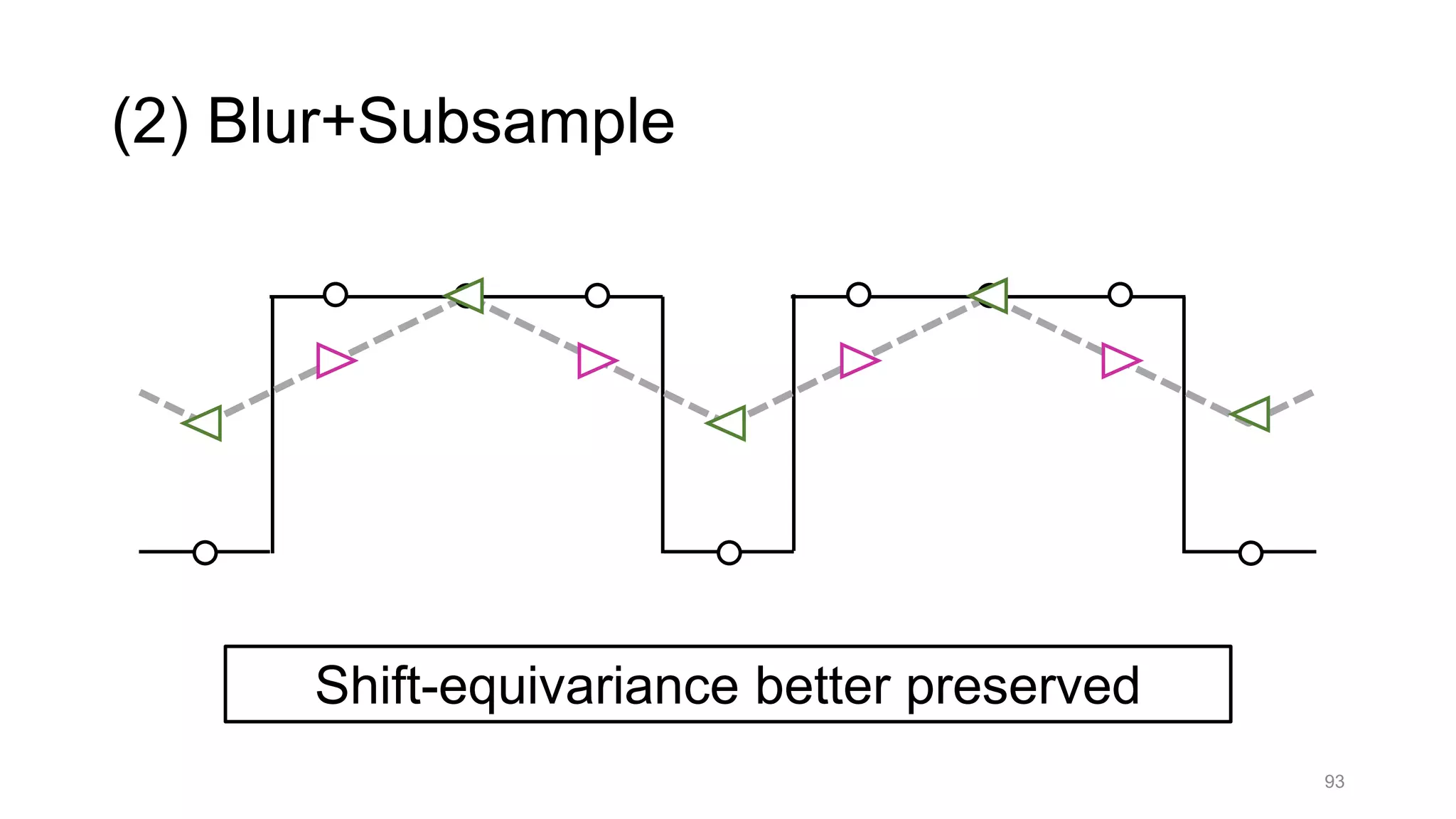
![Alternative downsampling methods
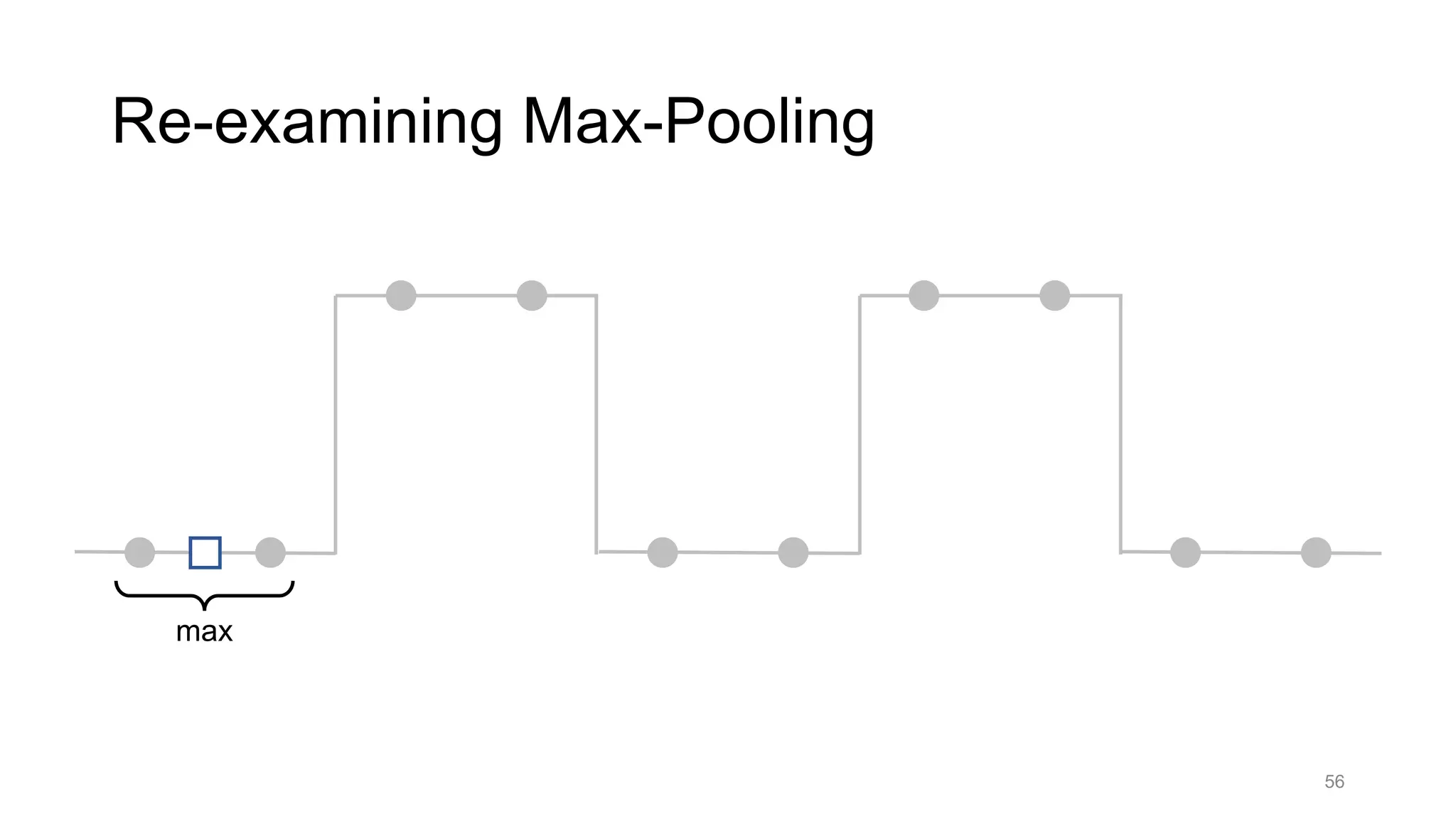
• Blur+subsample
• Antialiasing in signal processing; image processing; graphics
• Max-pooling
• Performs better for deep learning [Scherer 2010]
90
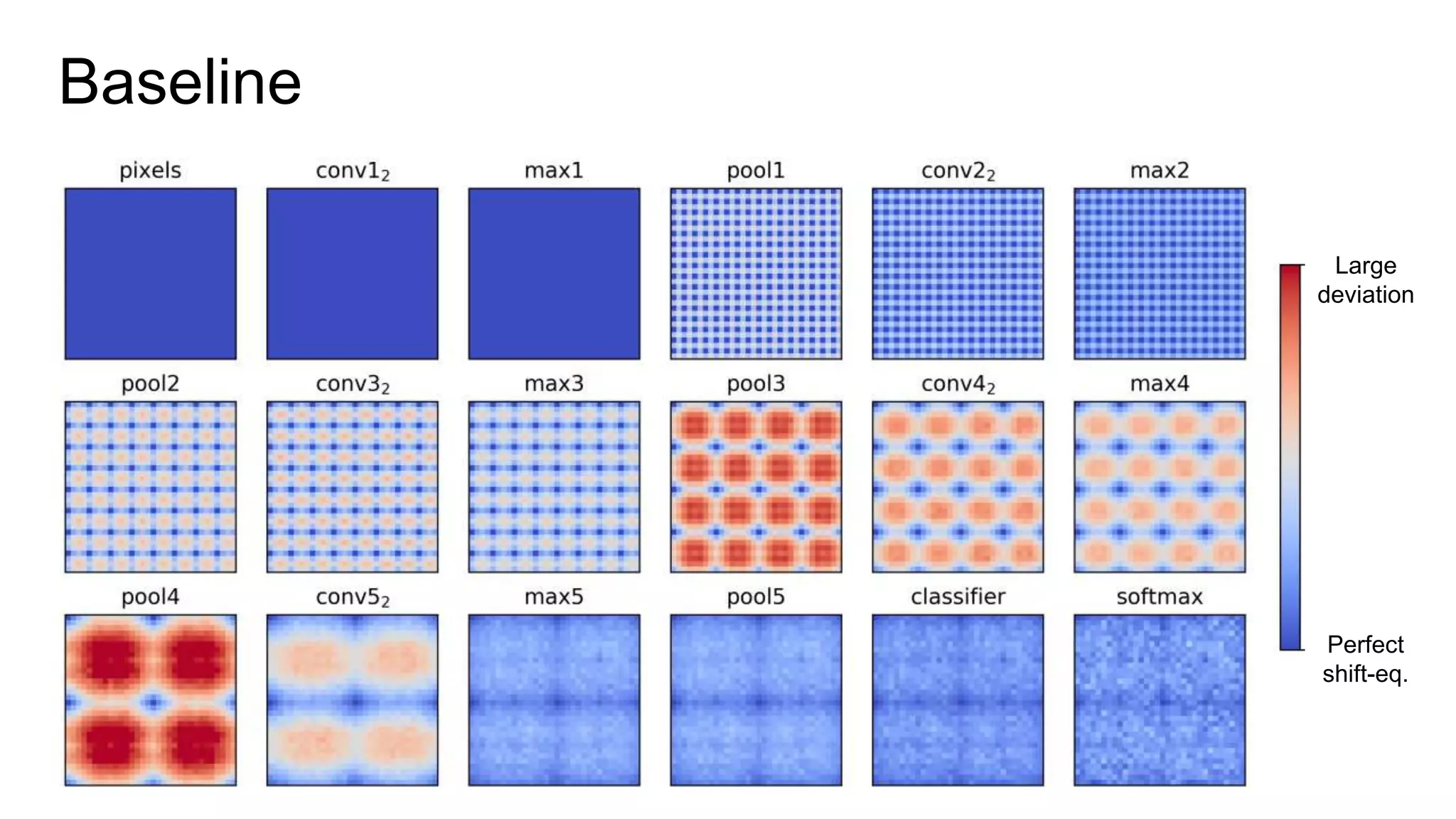
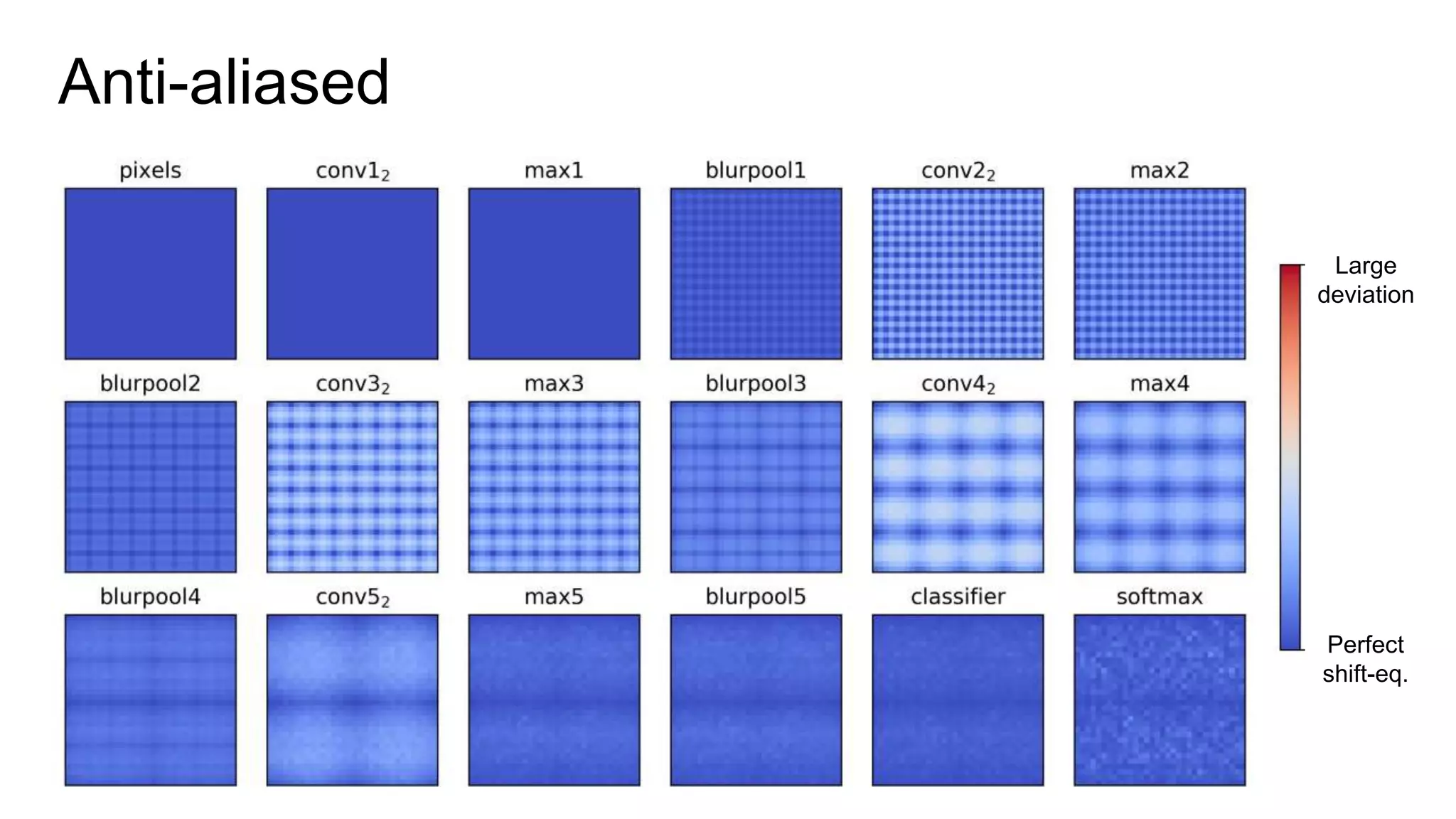
Reconcile antialiasing with max-pooling](https://image.slidesharecdn.com/modelingperceptualsimilarityandshift-invarianceindeepnetworks-191121045001/75/Modeling-perceptual-similarity-and-shift-invariance-in-deep-networks-79-2048.jpg)
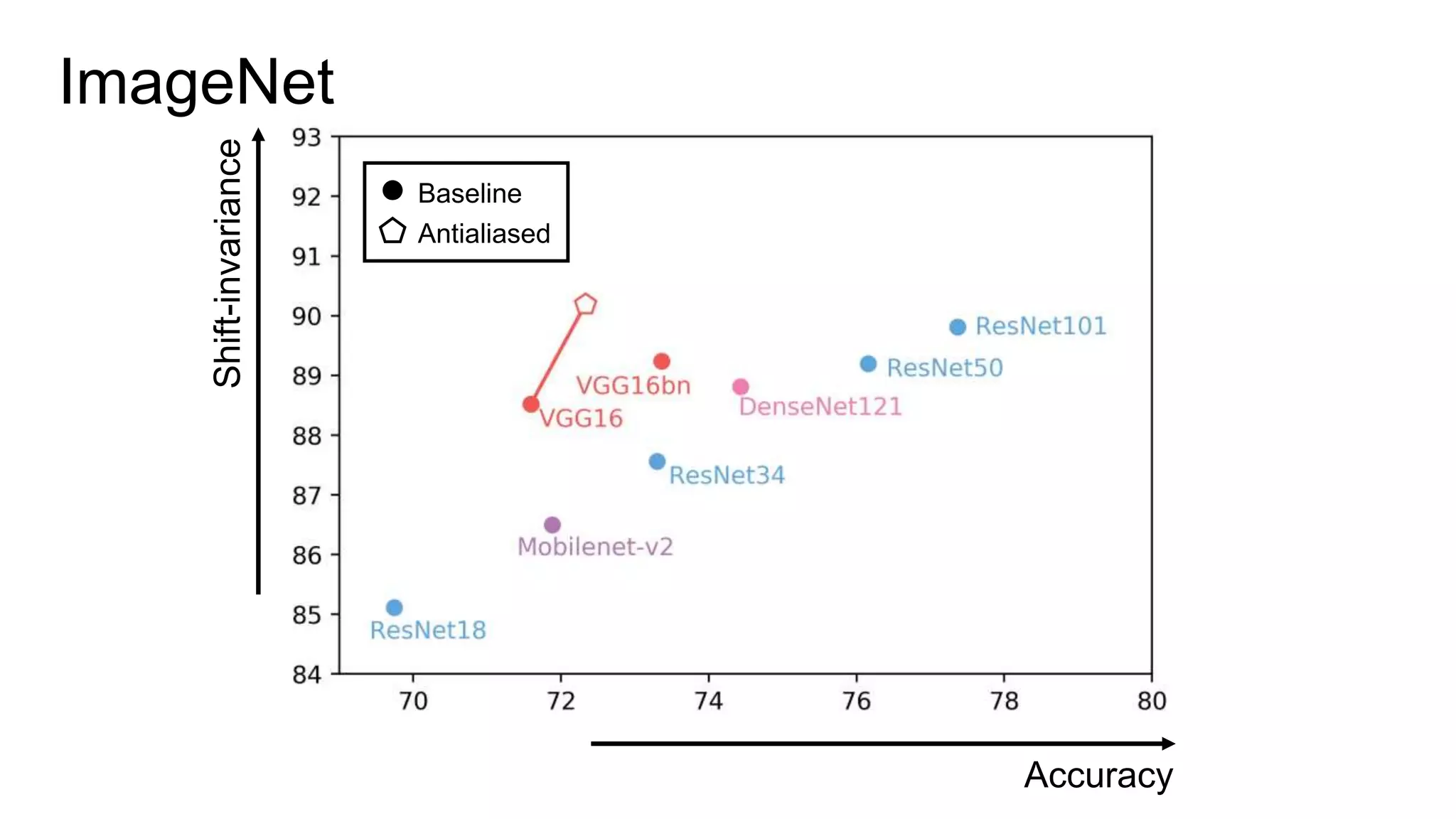
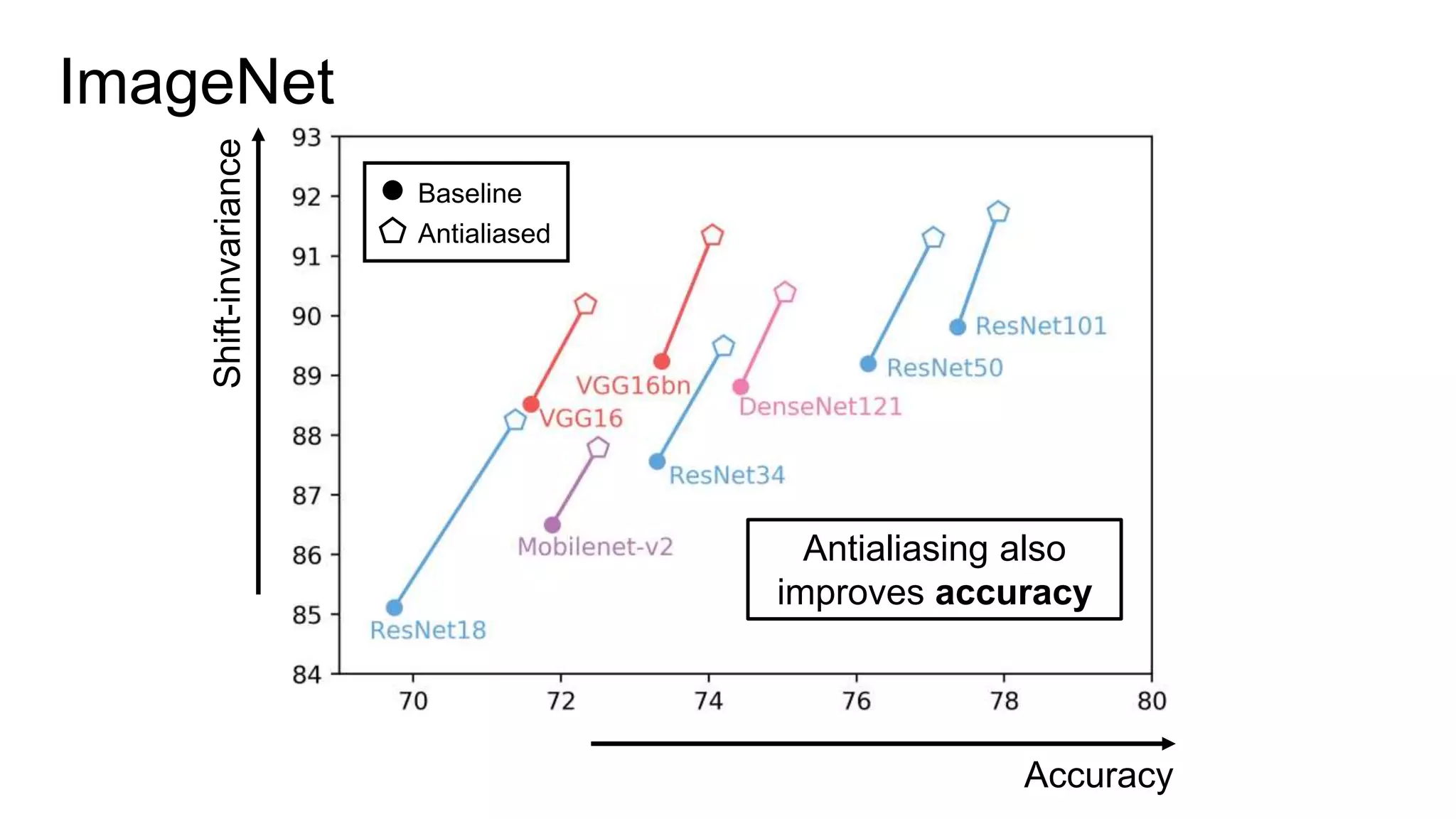

![Image-to-Image Translation
103
Input Baseline Antialias [1 1] Antialias [1 2 1]
Isola et al. Pix2pix. CVPR 2017.](https://image.slidesharecdn.com/modelingperceptualsimilarityandshift-invarianceindeepnetworks-191121045001/75/Modeling-perceptual-similarity-and-shift-invariance-in-deep-networks-91-2048.jpg)

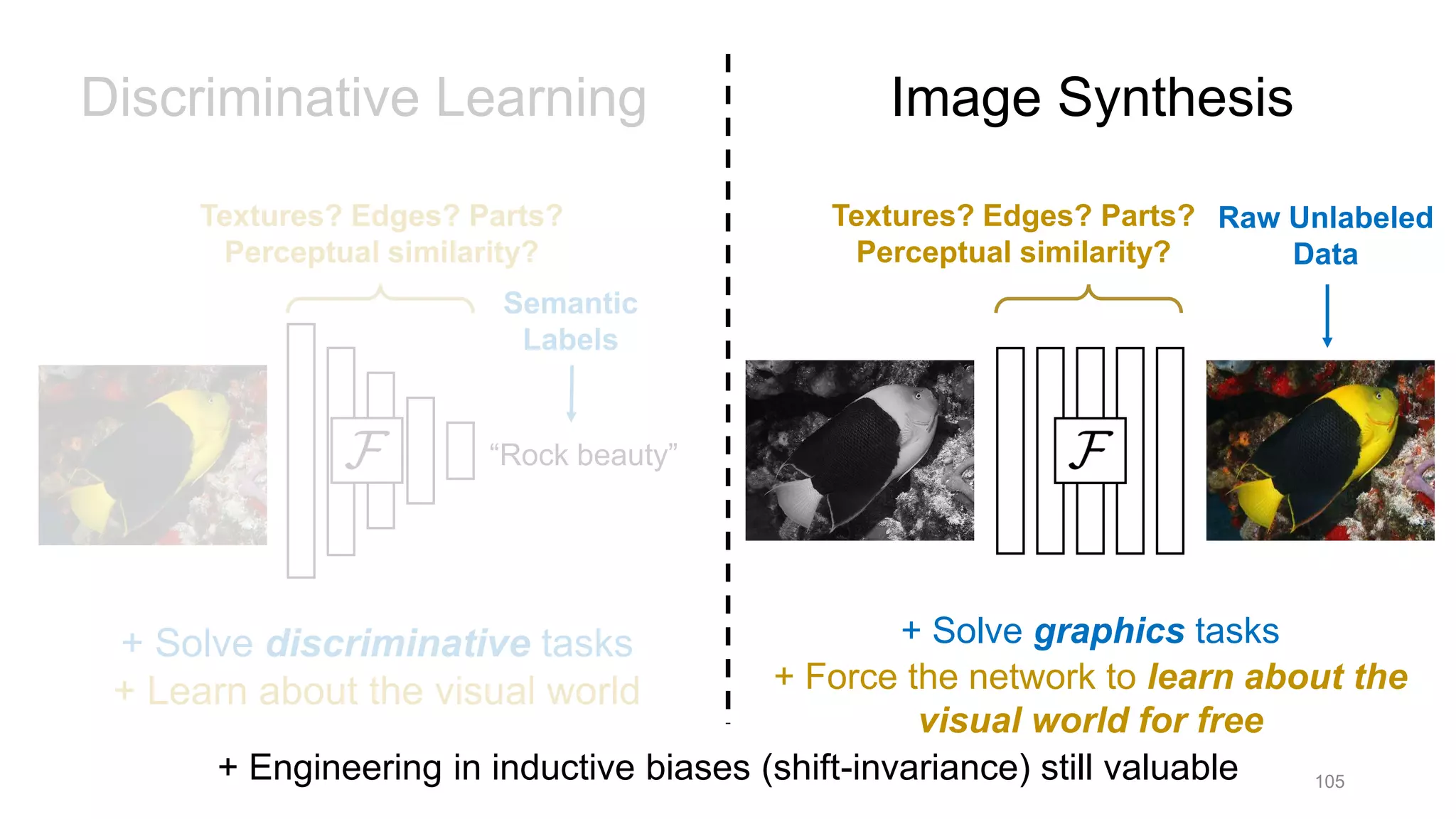



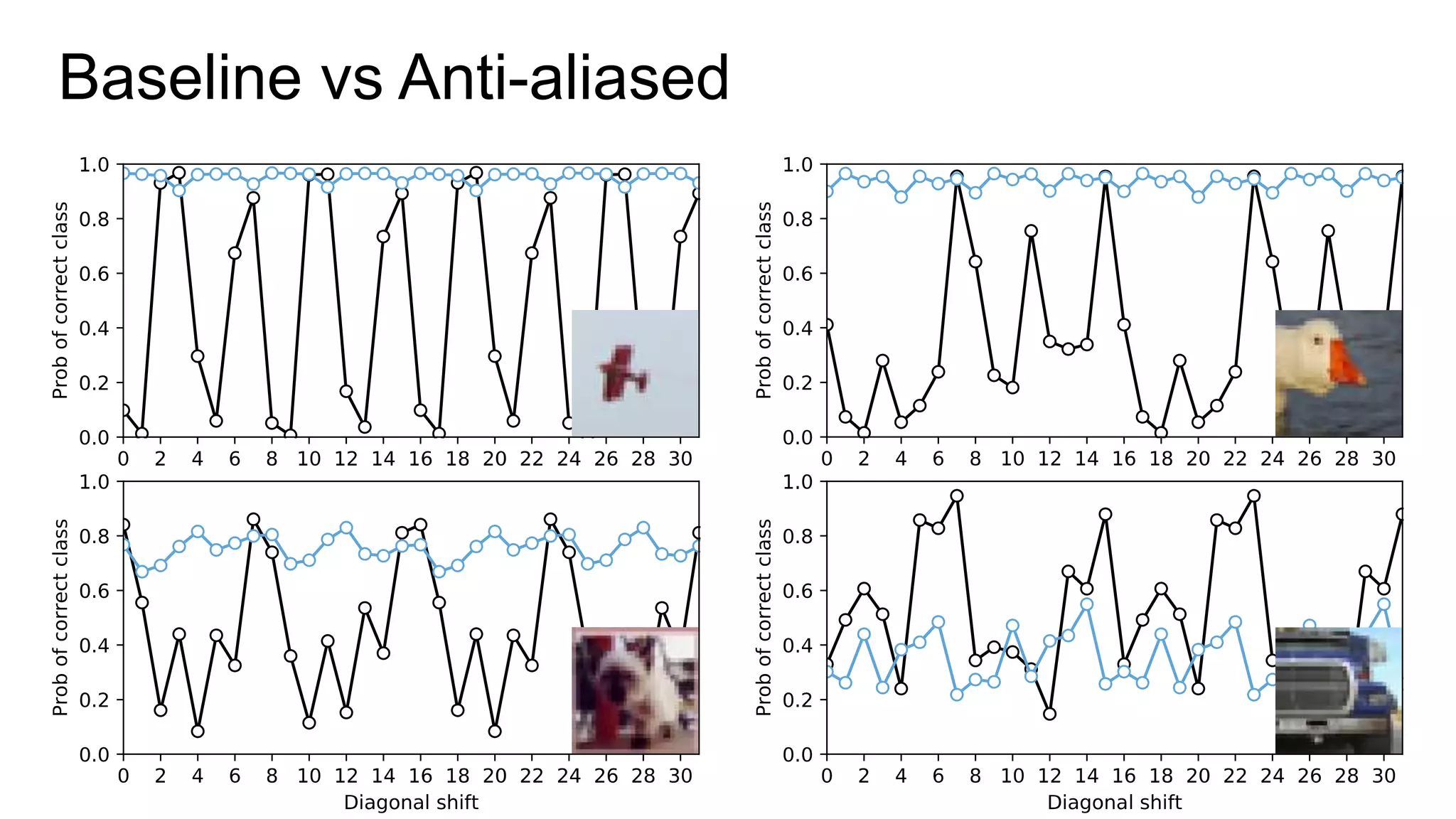
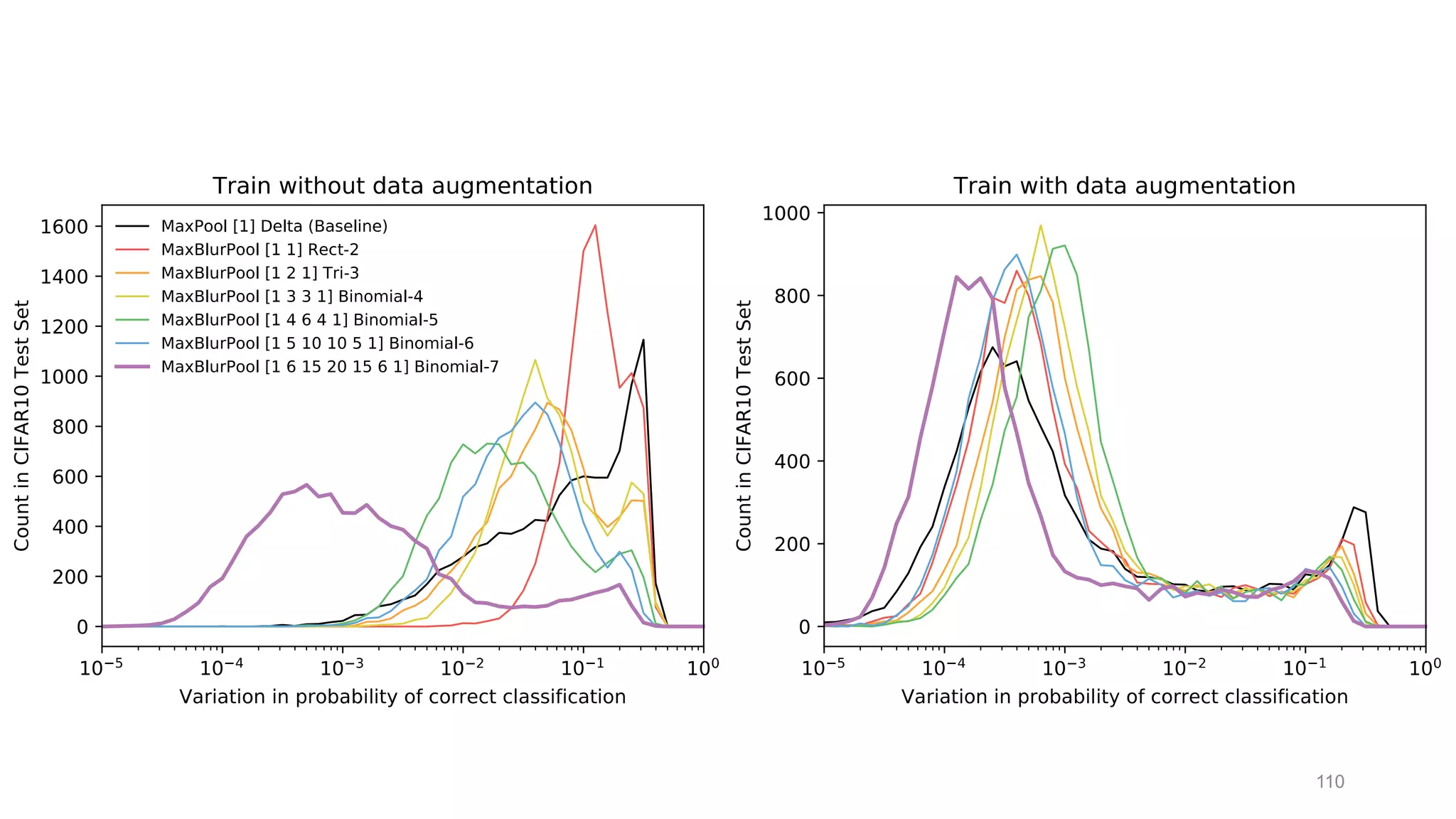
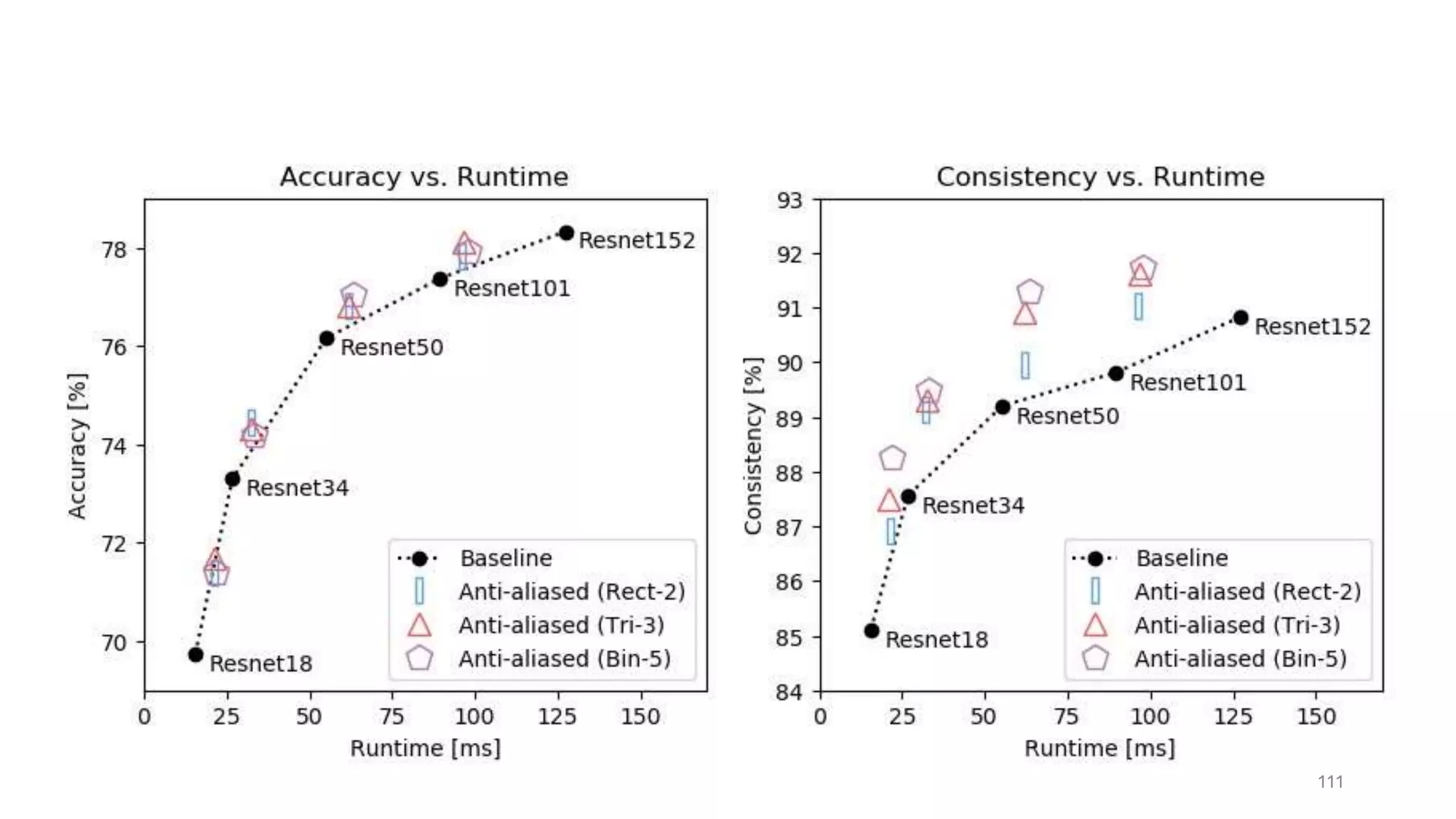
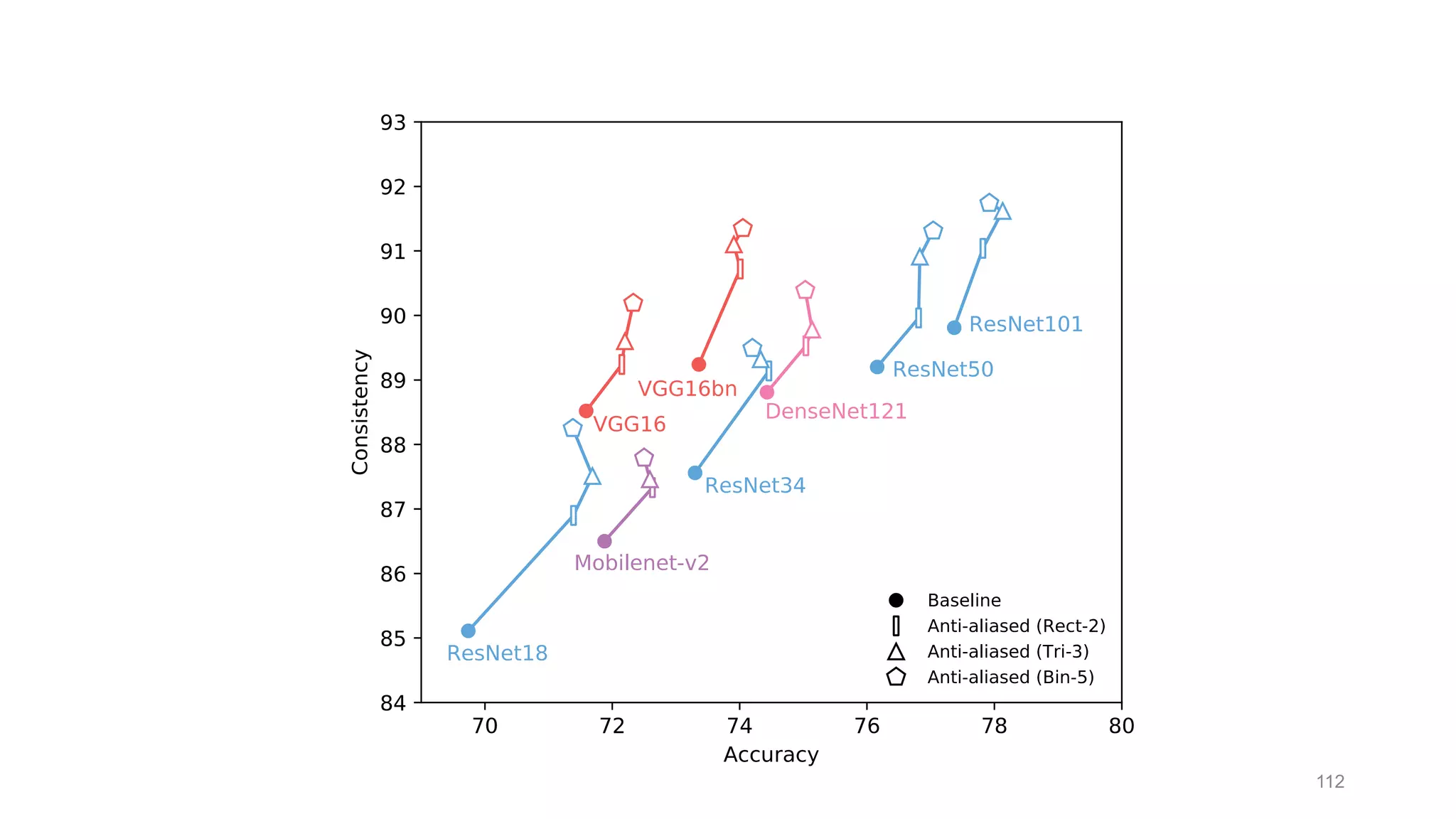
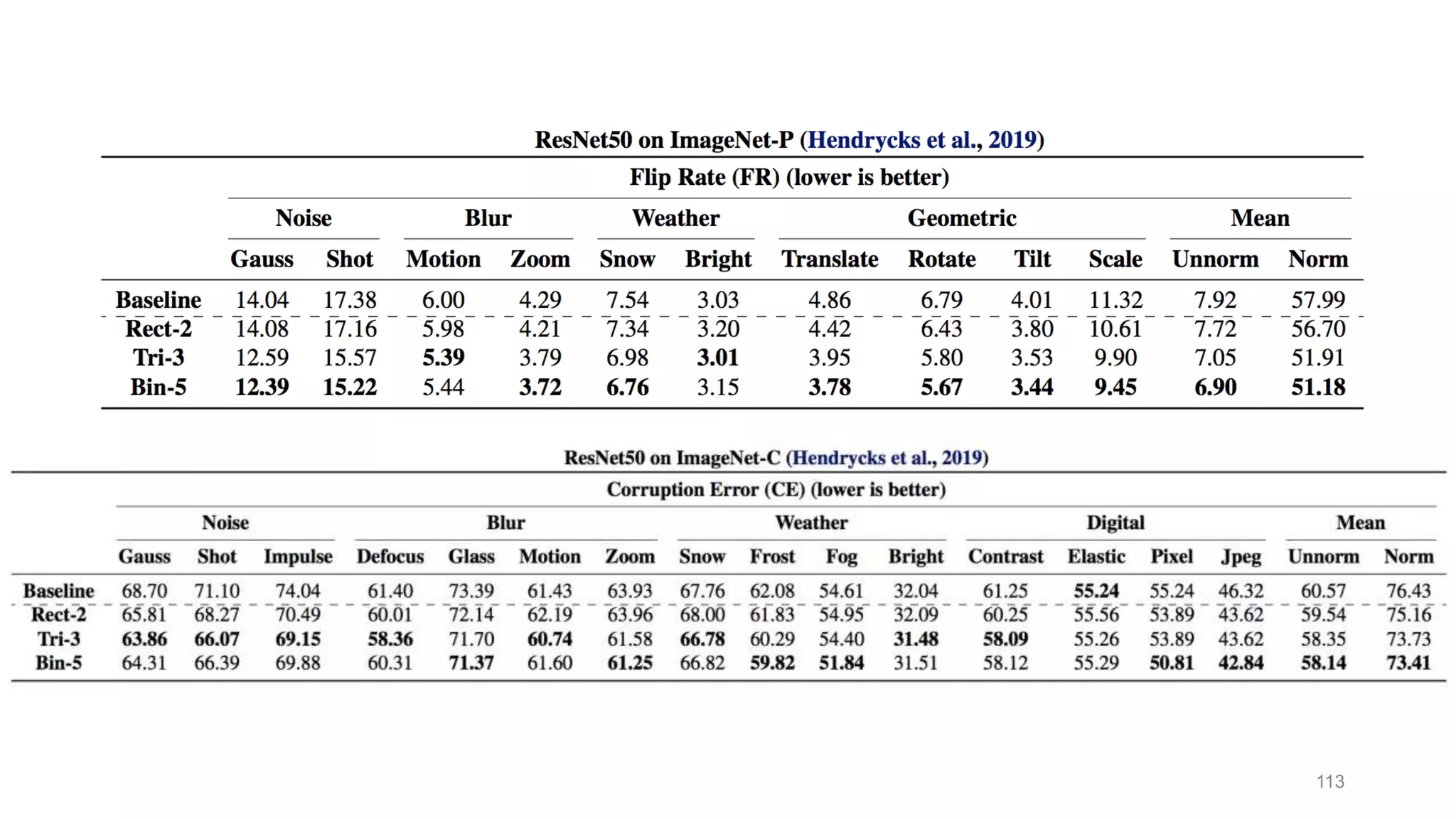
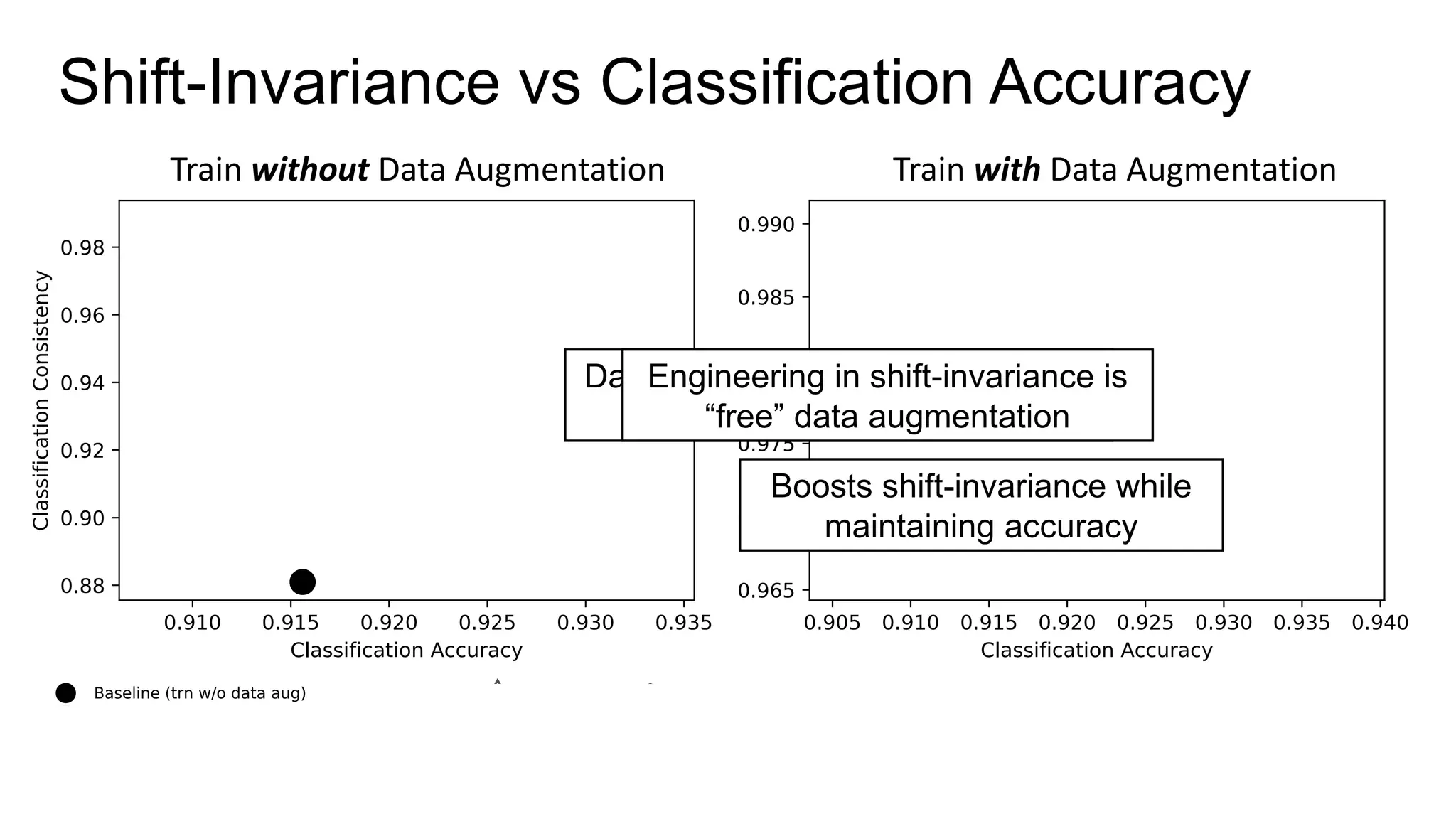
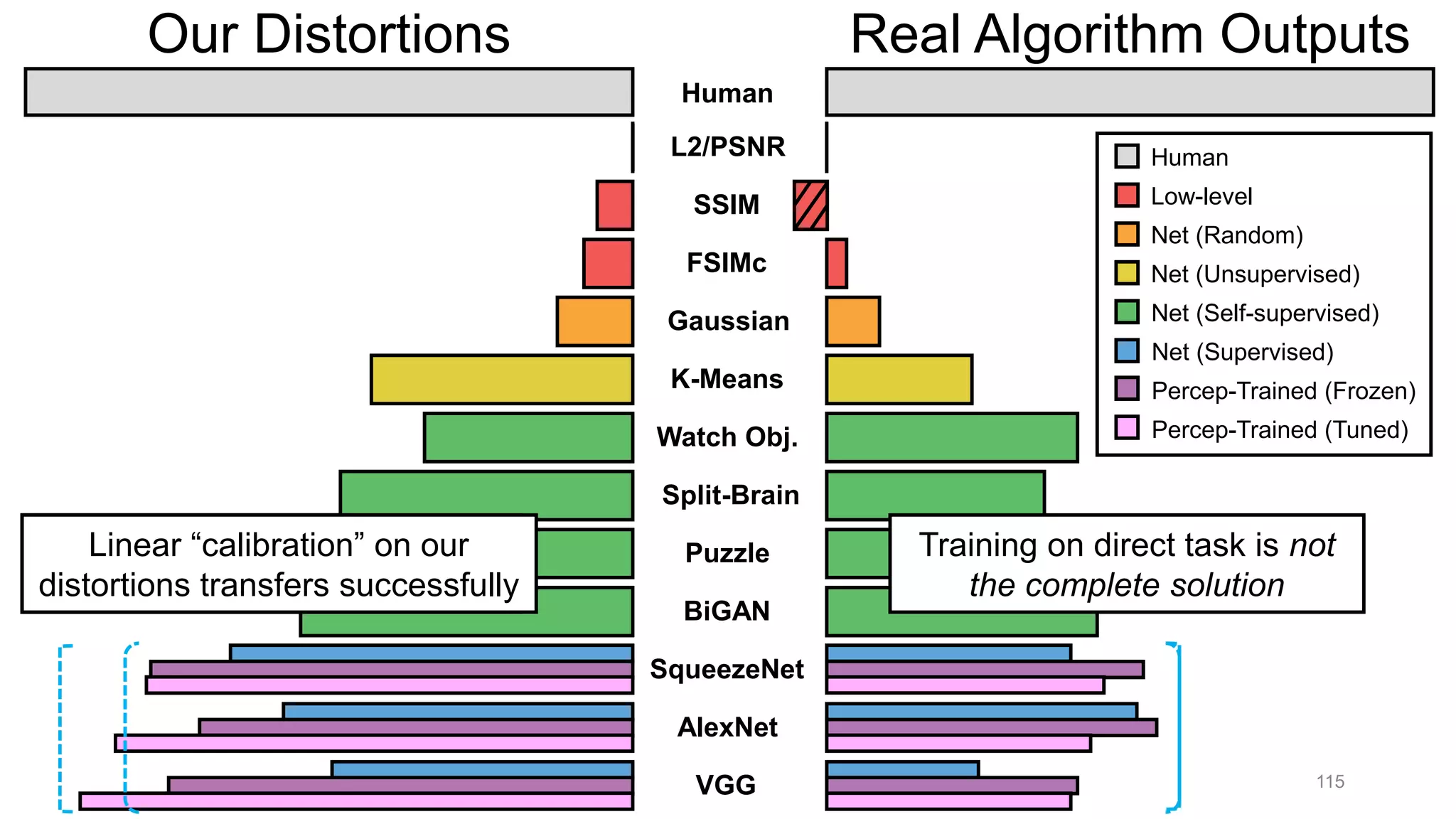







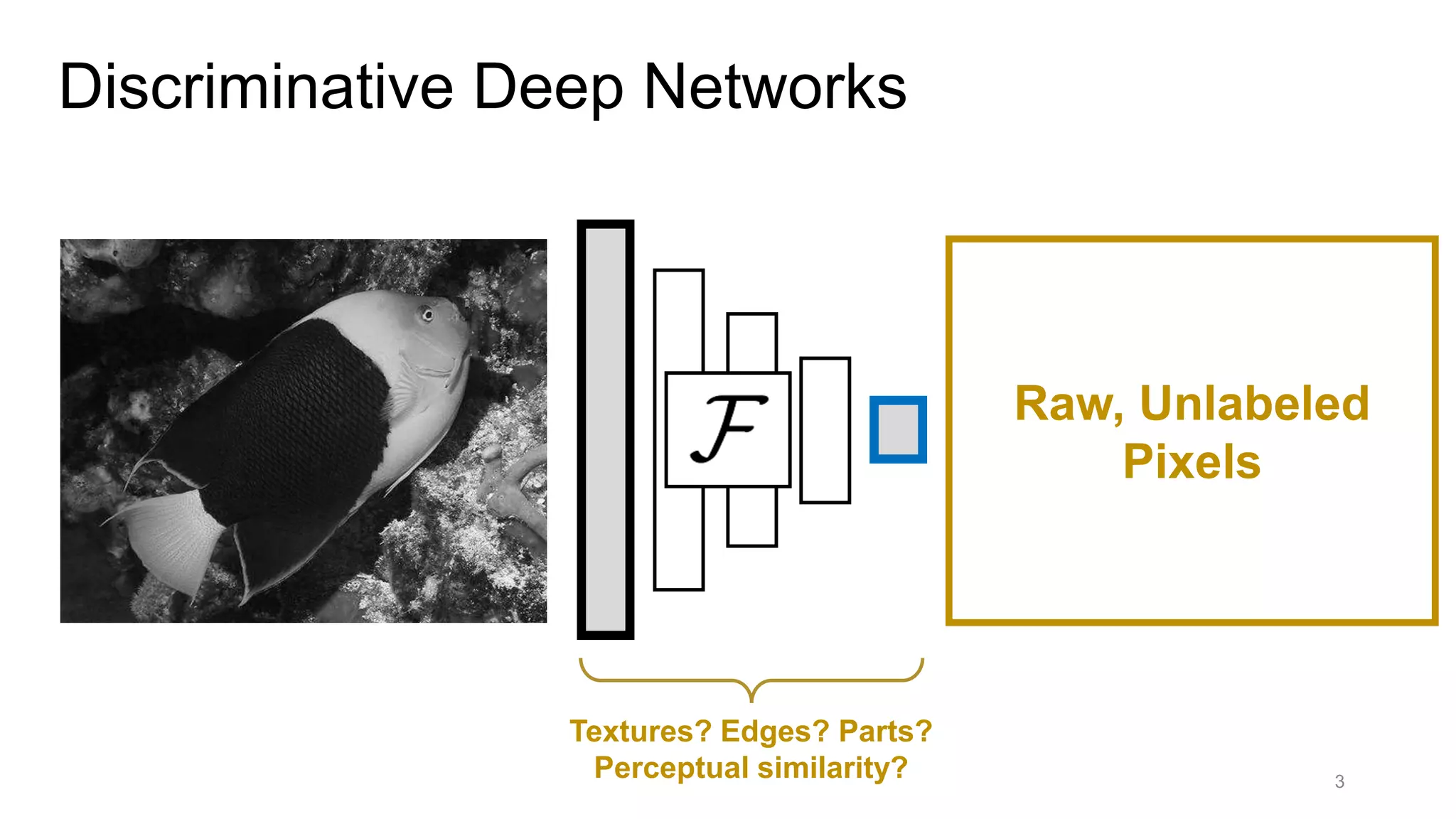
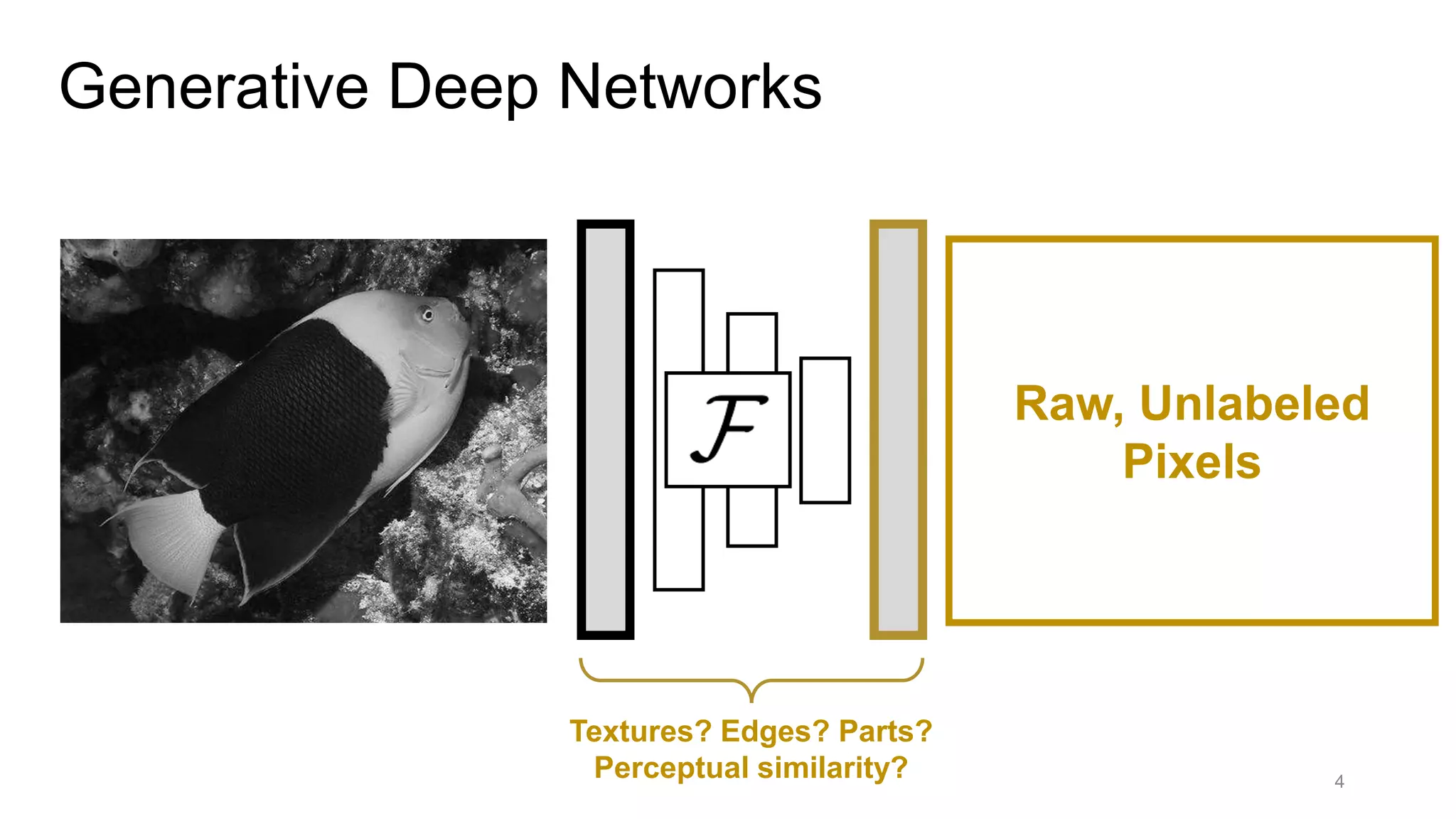
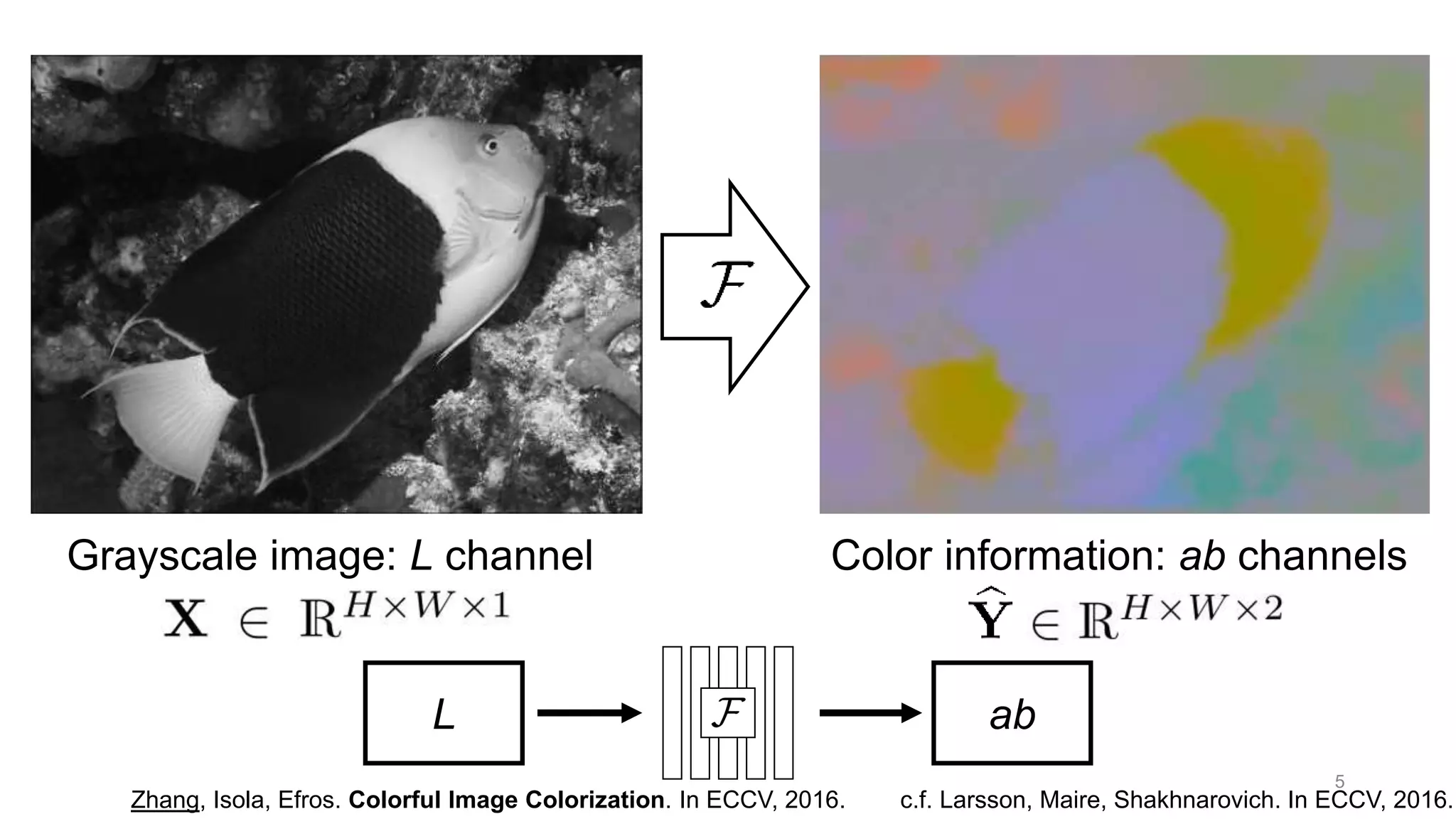
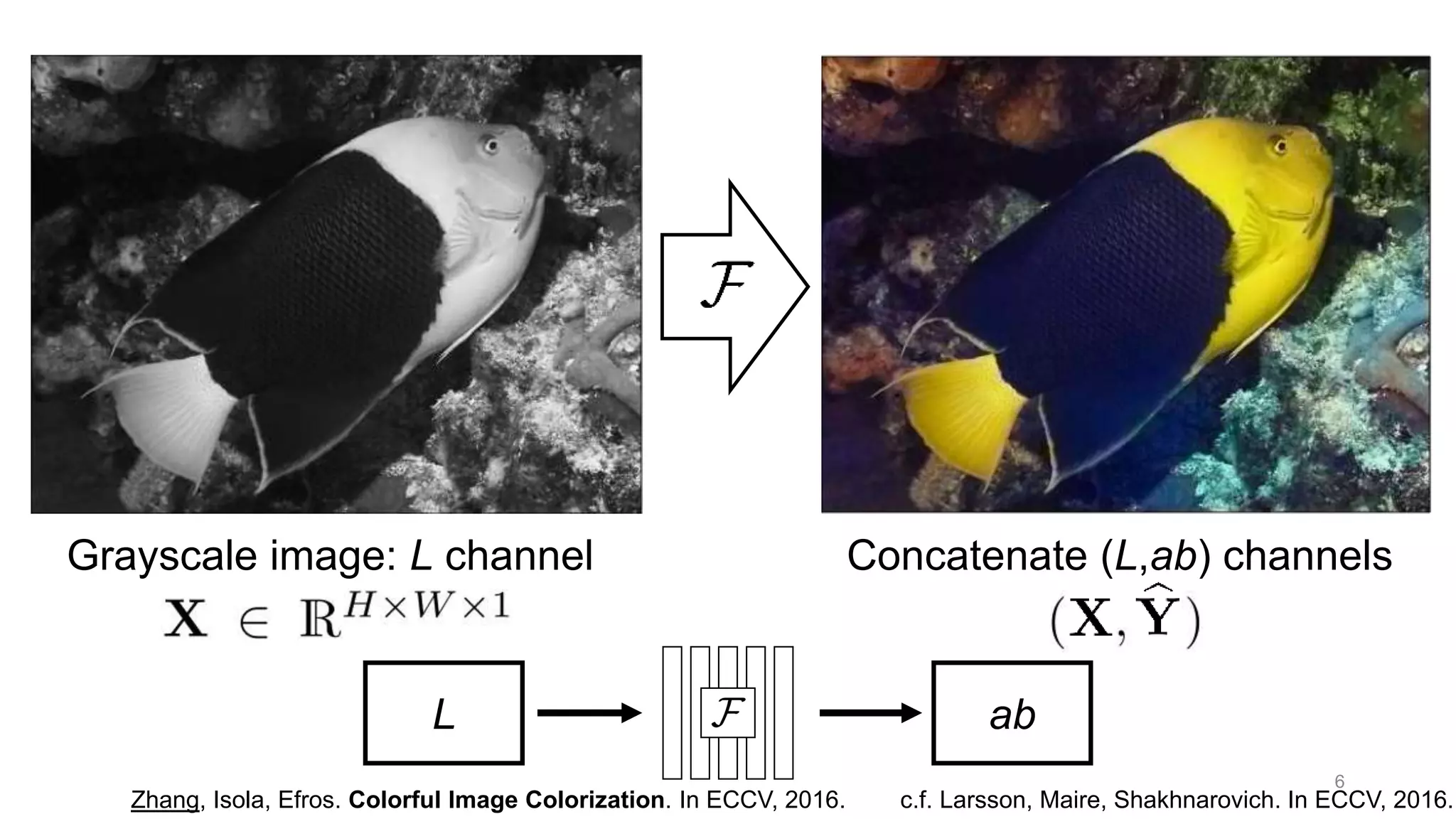
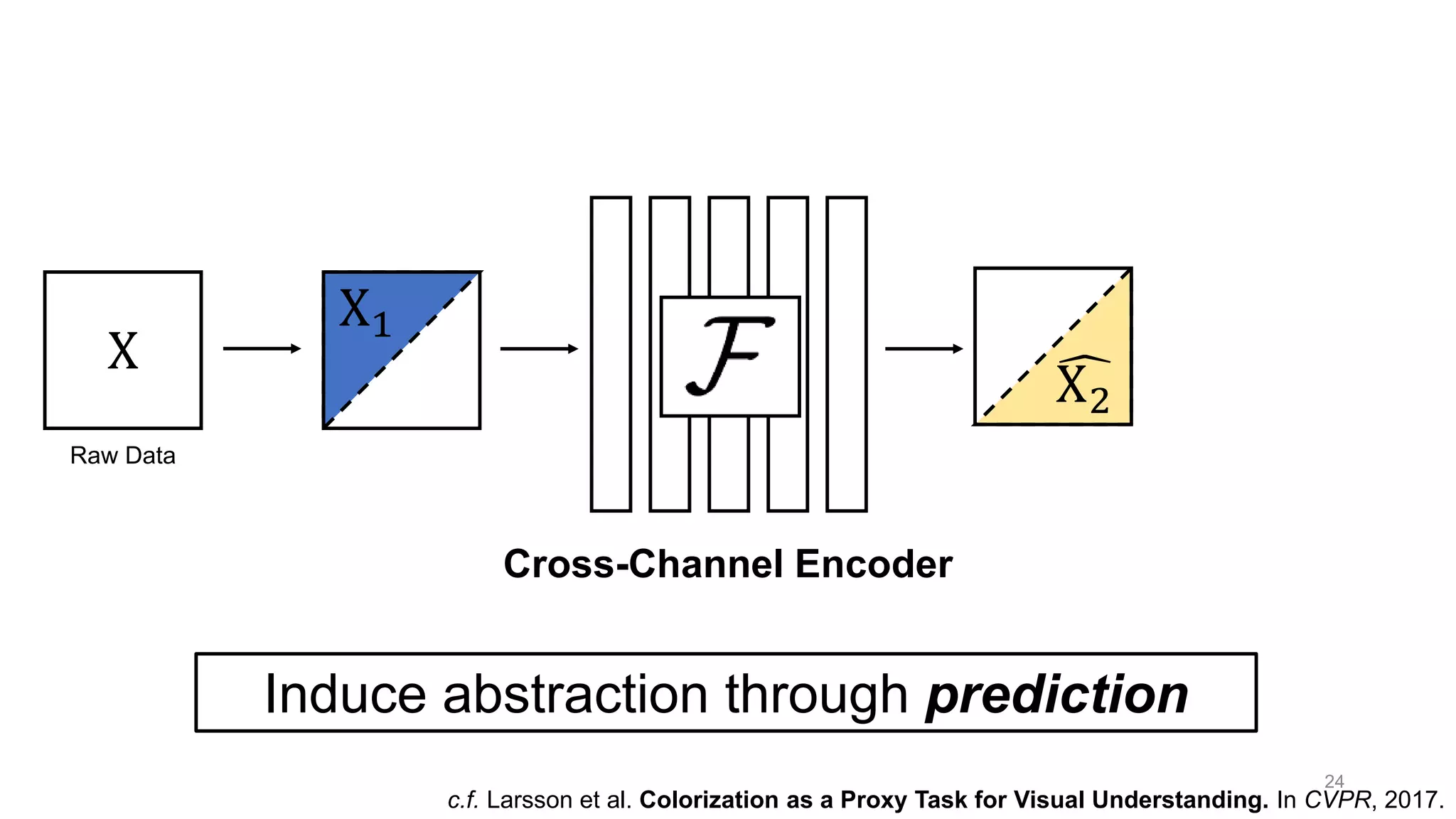
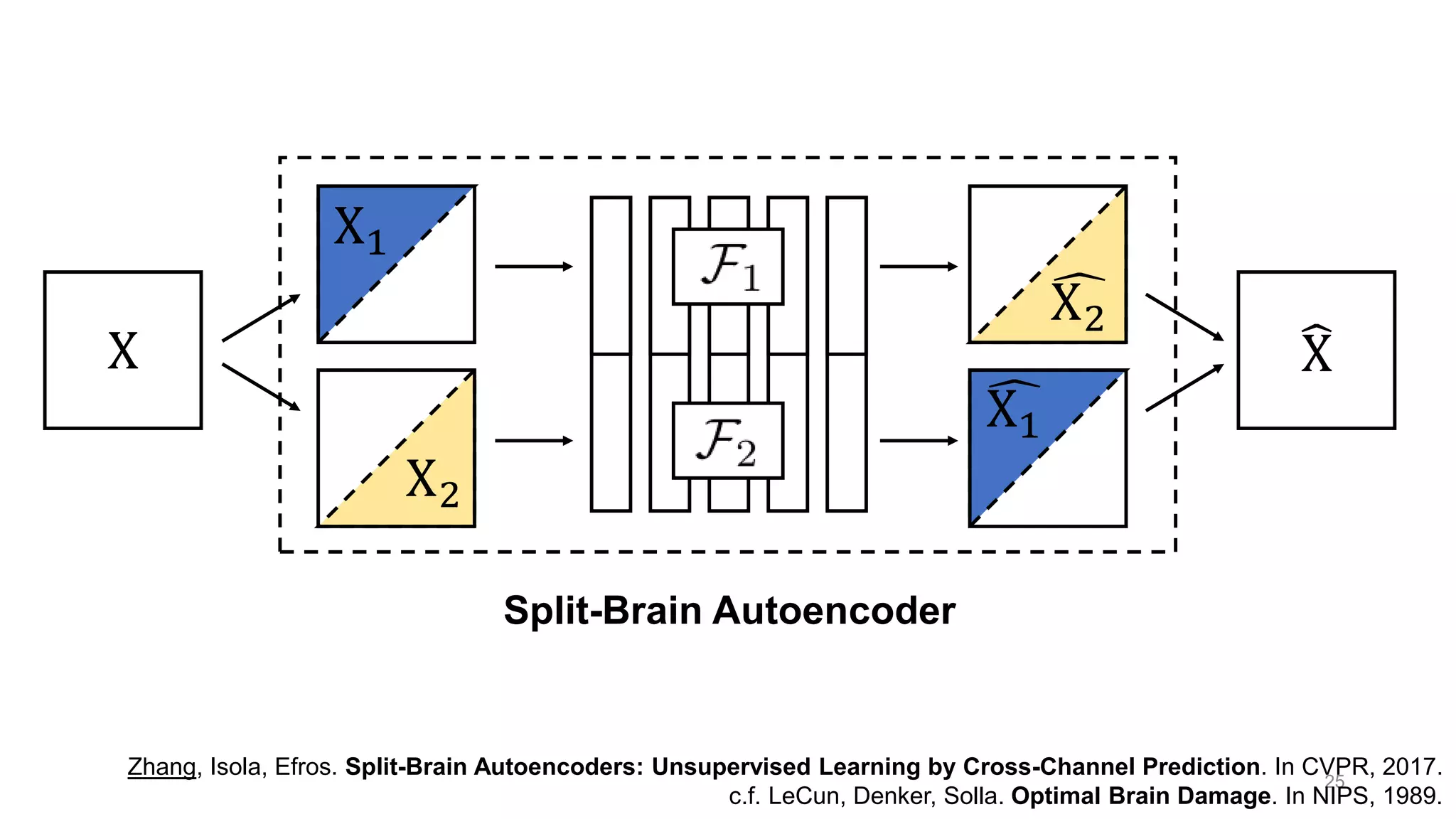
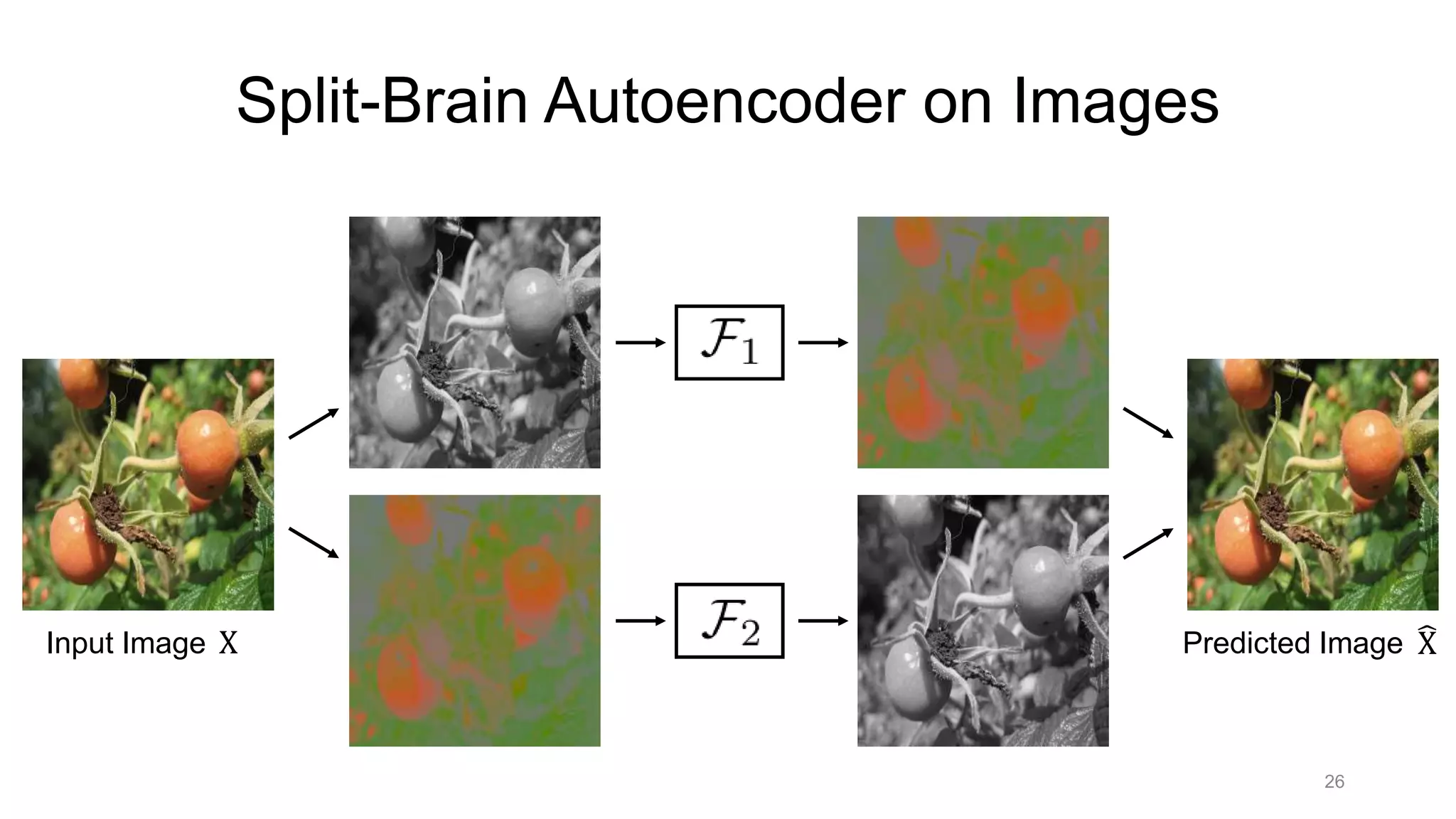
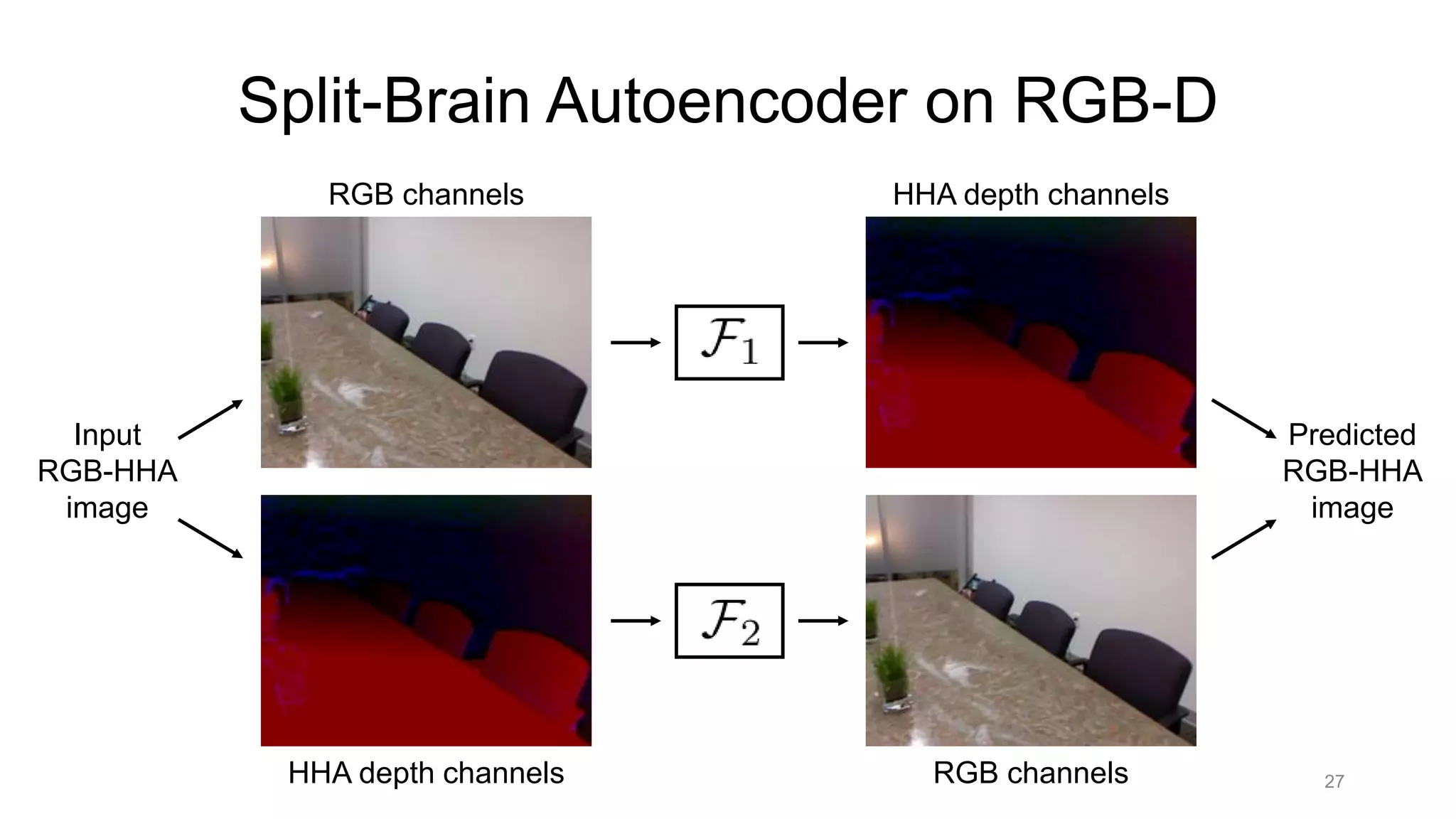
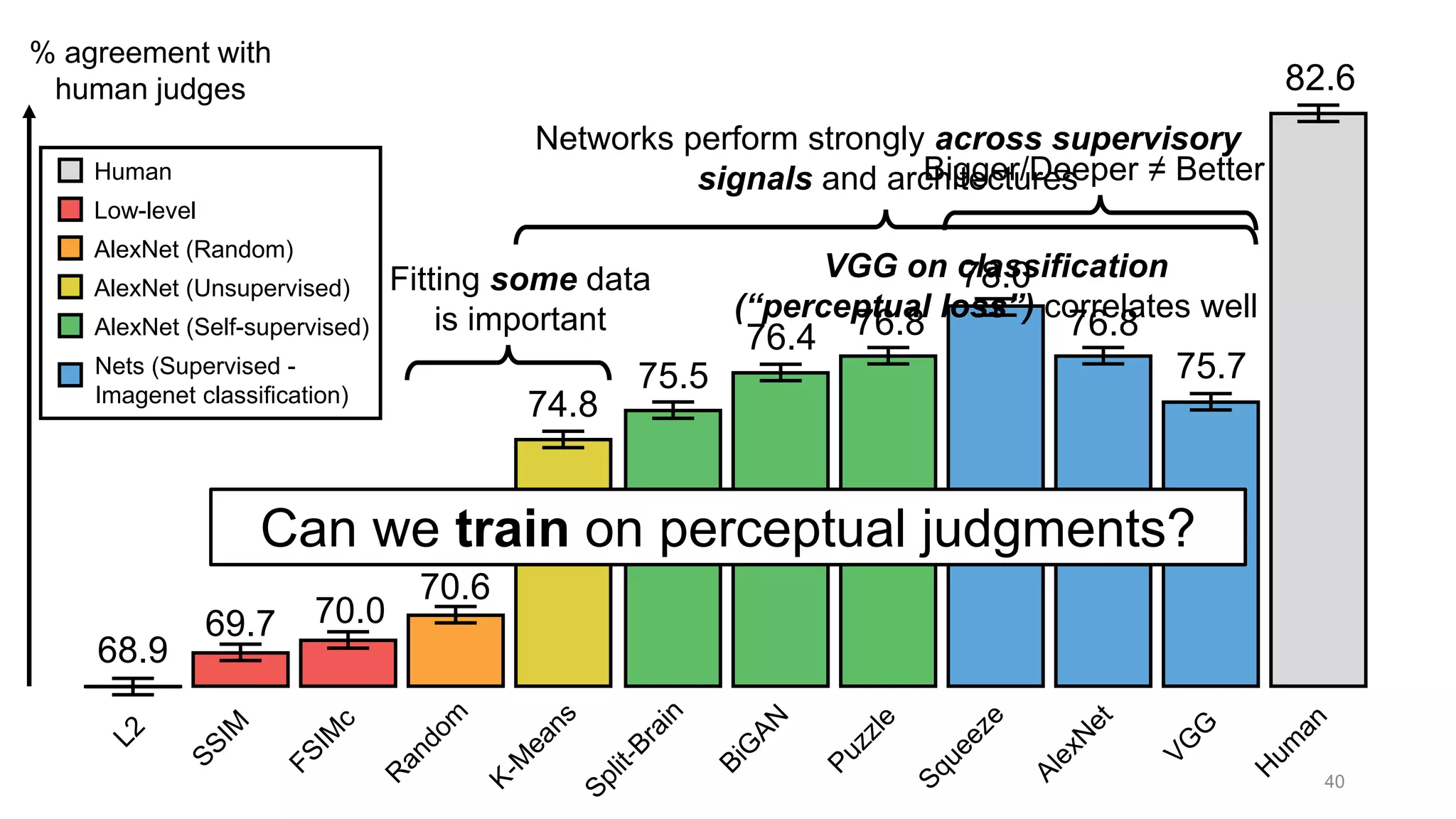
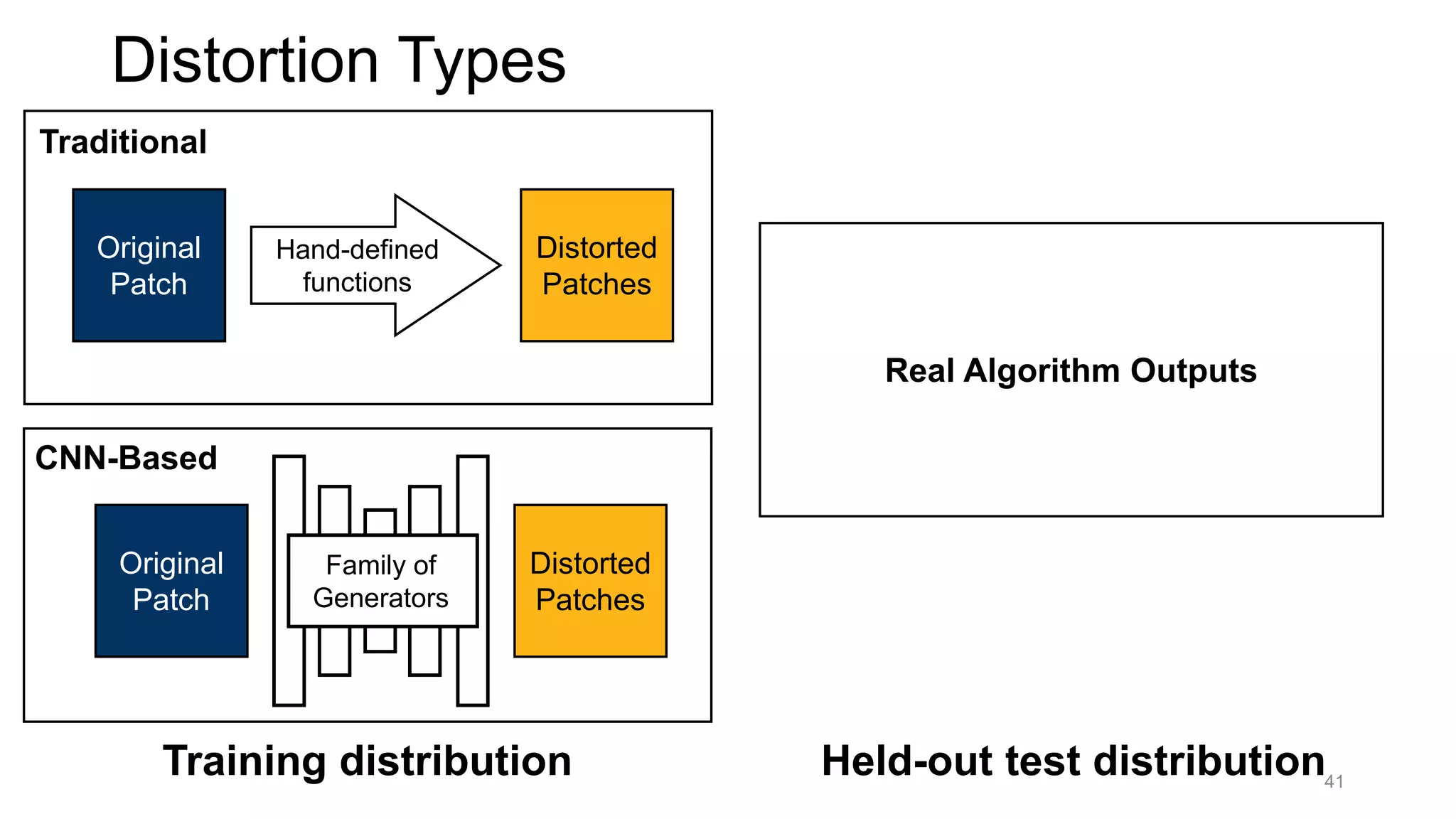
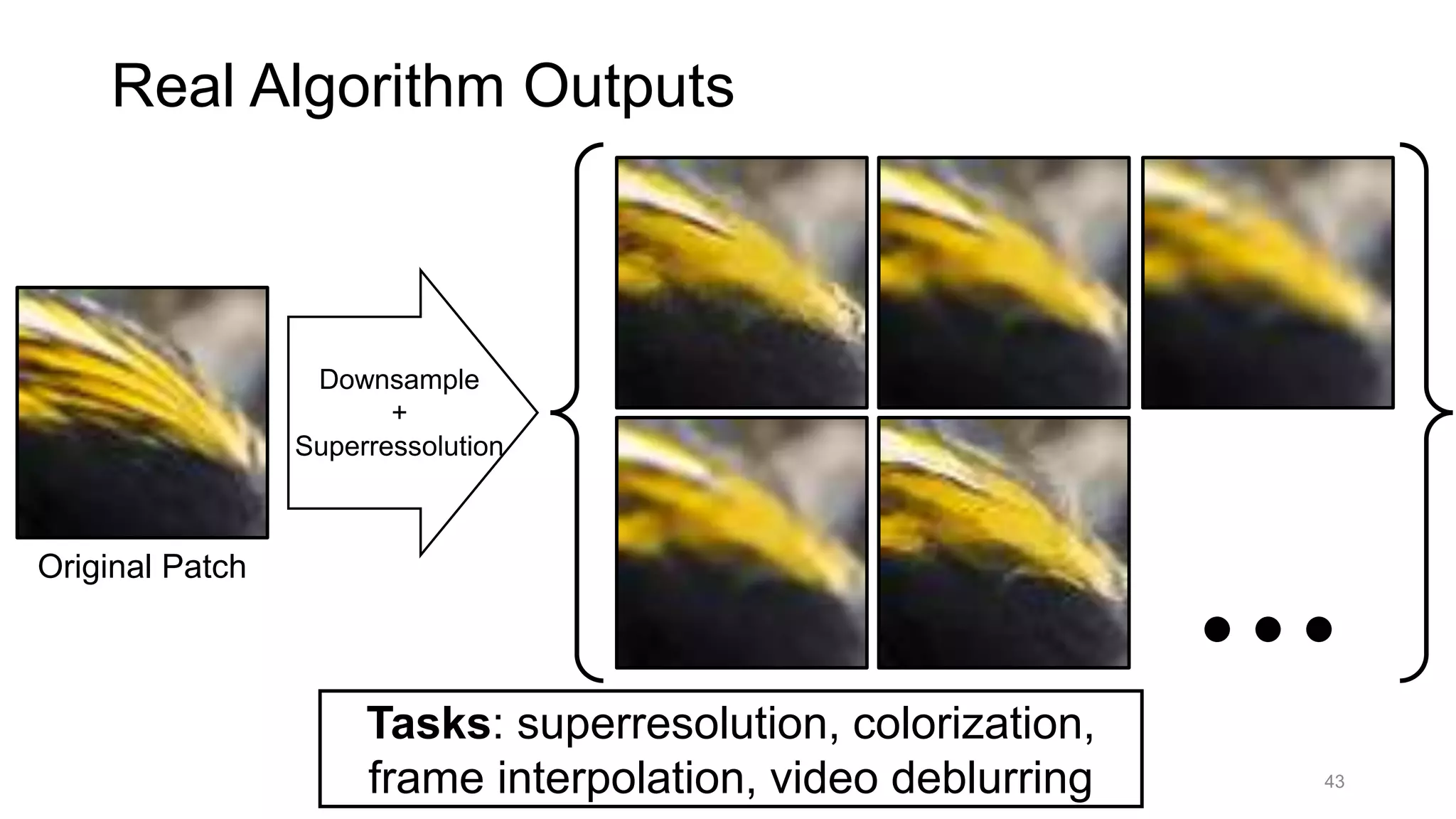
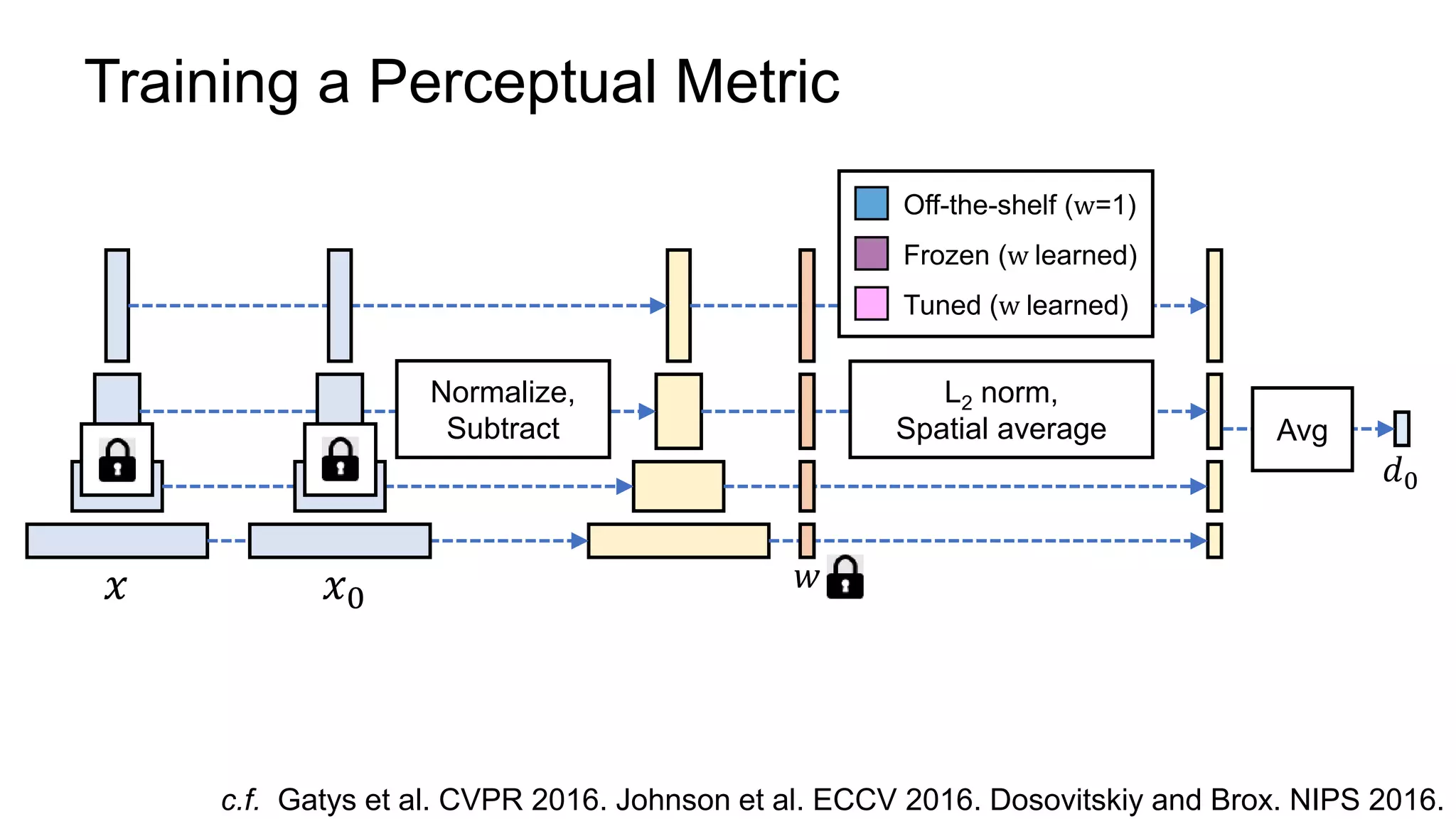
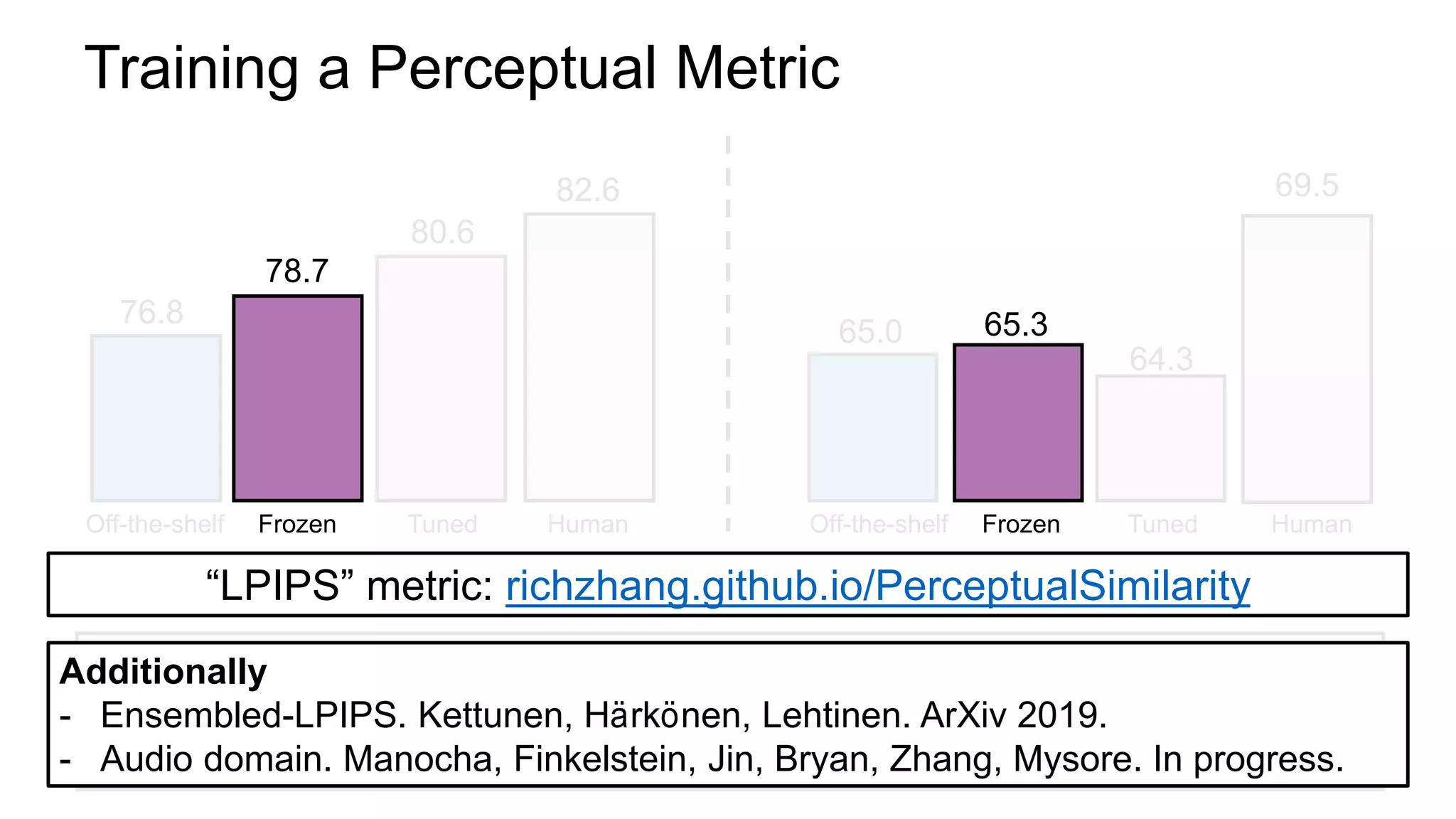
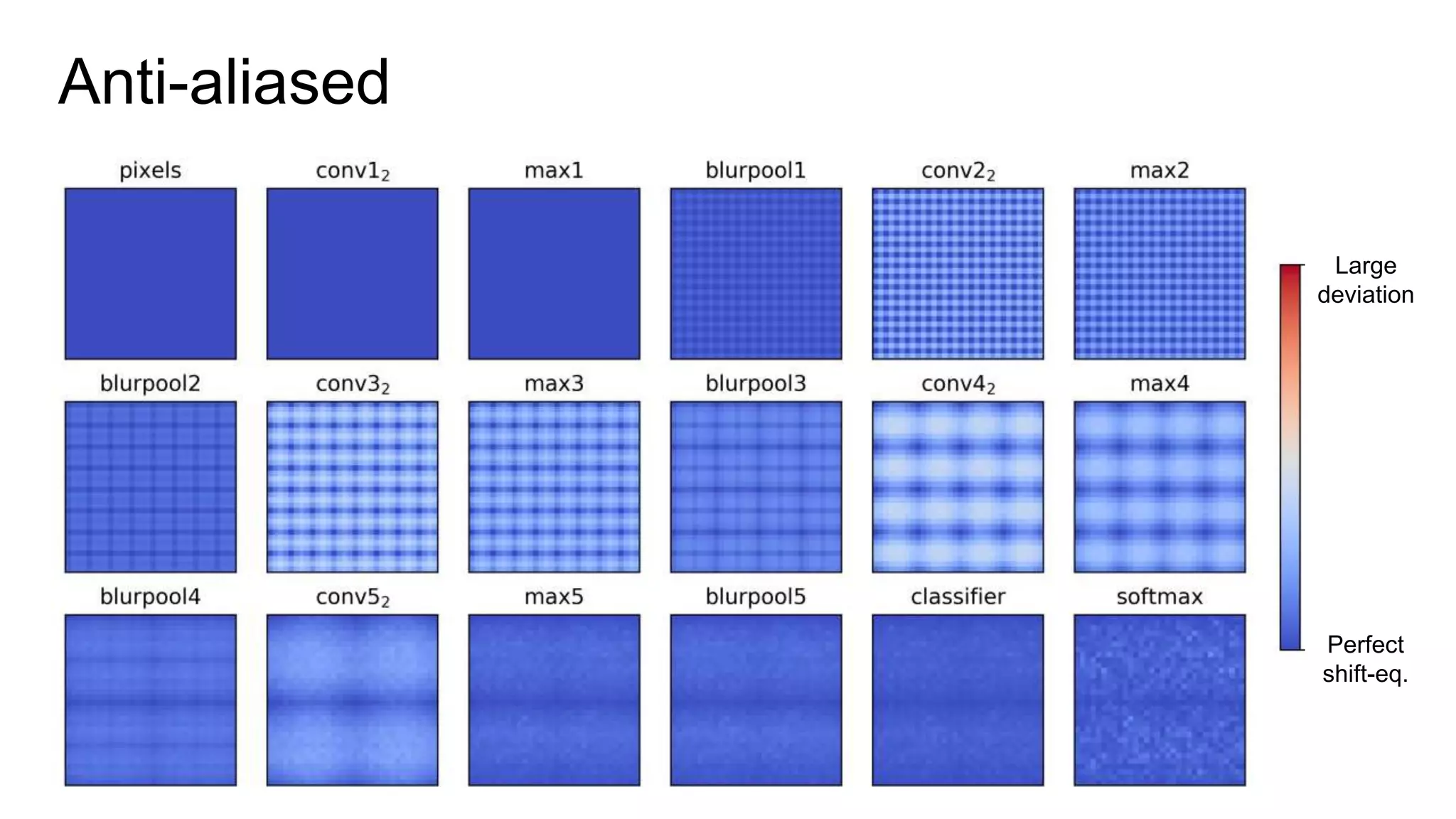
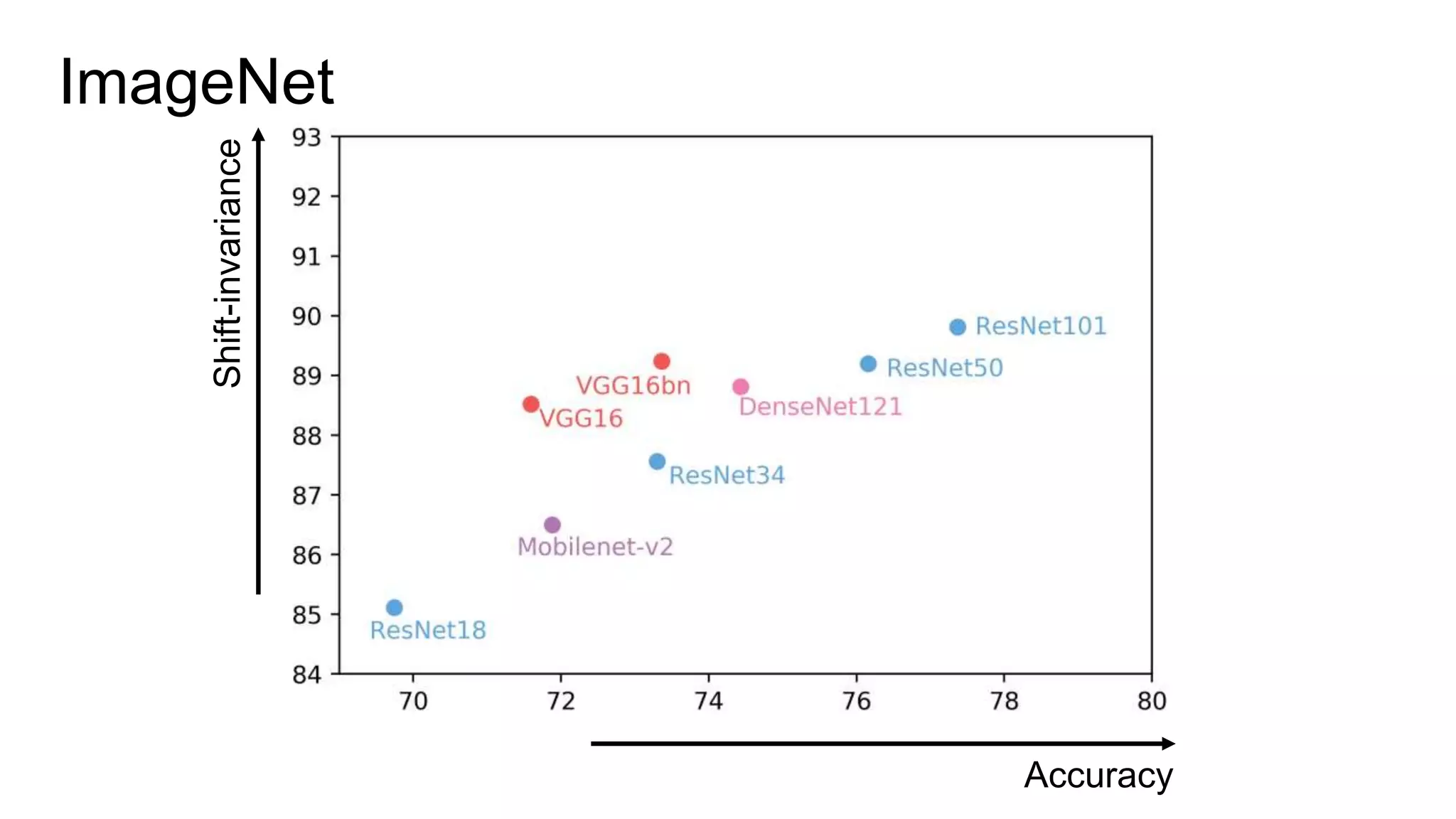
The document discusses the modeling of perceptual similarity and shift-invariance in deep networks in the context of image processing and computer vision. It highlights various techniques including automatic colorization, perceptual losses, split-brain autoencoders, and the breakdown of shift-equivariance in deep learning architectures. Additionally, it addresses approaches to improve the robustness of networks against transformations and the impact of different pooling strategies on the learning process.


























![[5] Understanding the YOLOv8 Architecture.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/5understandingtheyolov8architecture-240724131844-70710c0c-thumbnail.jpg?width=640&height=640&fit=bounds)


























































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)

