Download as PDF, PPTX





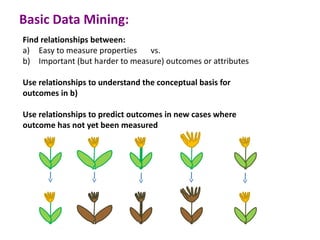

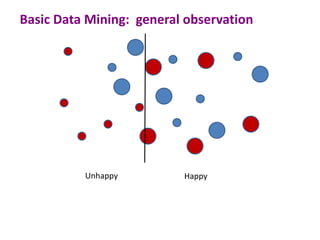
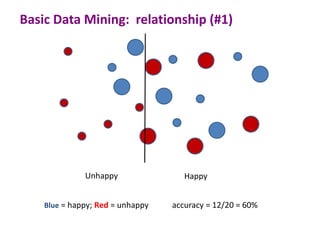
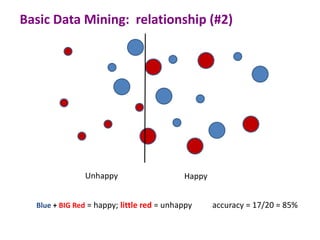

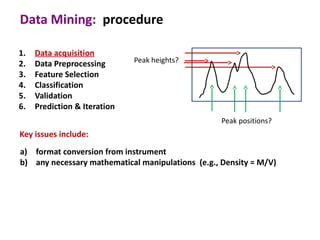

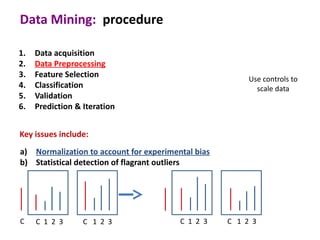
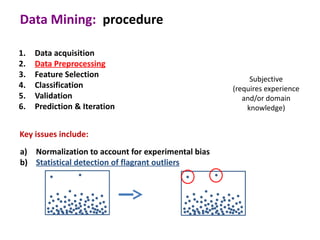

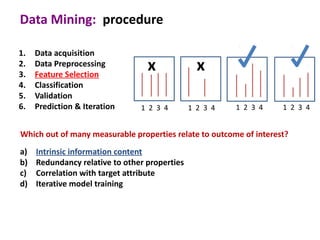
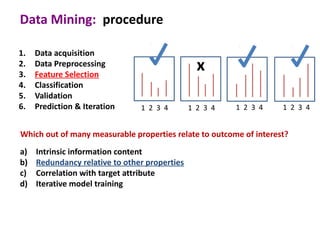
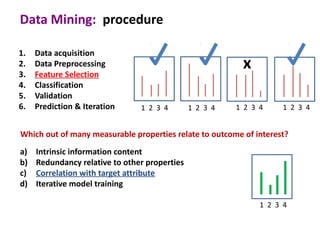


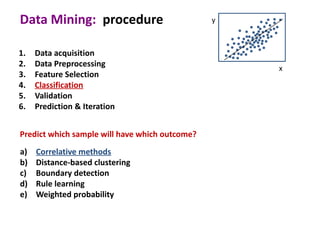
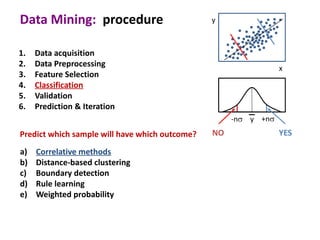

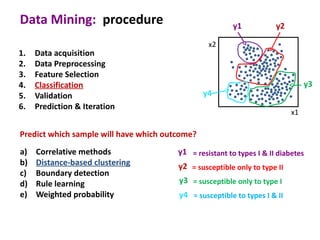

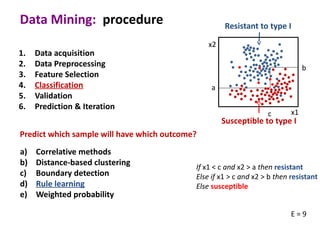


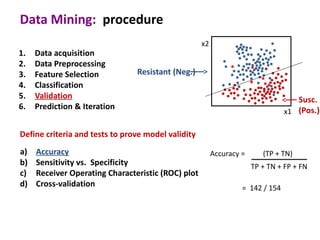
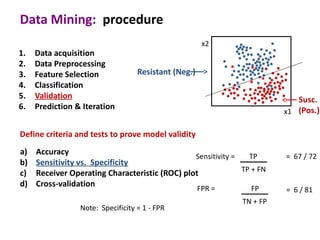
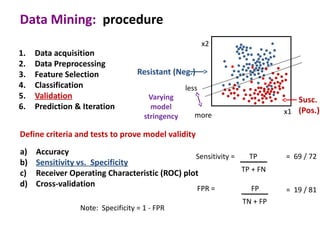
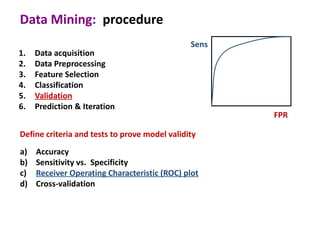
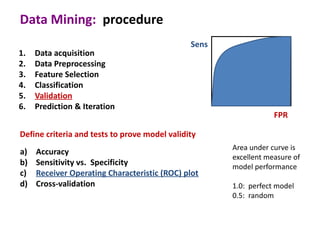





This document discusses the principles and techniques of data mining, particularly in the field of bioinformatics. It covers the procedure of data mining, which includes acquisition, preprocessing, feature selection, classification, validation, and prediction. The lecture aims to help understand relationships between measurable properties and important biological outcomes, emphasizing model validation and iterative improvements based on predictions.





























































































