Download to read offline















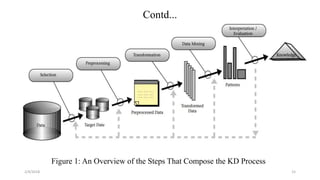





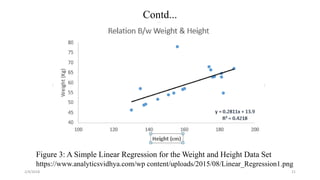


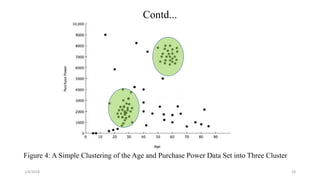




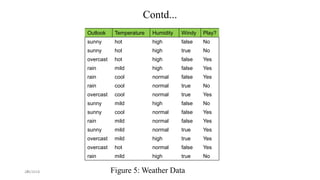
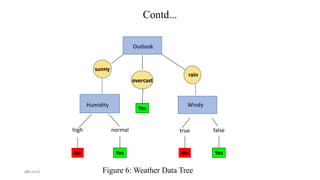







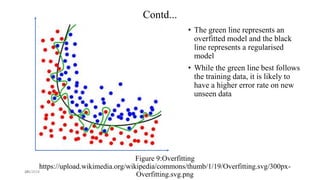







The document discusses knowledge discovery (KD) in databases, emphasizing the need for efficient data analysis techniques due to the increasing volume of data. It details the KD process, various data mining methods, and their real-world applications across fields such as healthcare, marketing, and telecommunications. Challenges in KD, such as managing large databases, high dimensionality, and data integrity, are also explored along with potential solutions.









































































