Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
WS
Uploaded by
Wataru Shito
102 views
演習II.第1章 ベイズ推論の考え方 Part 3.講義ノート
西南学院大学経済学部 演習2 講義ノート(2021/8/23更新版) 講義ページ: http://courses.wshito.com/semi2/2019-bayes-AI
Data & Analytics
◦
Read more
0
Save
Share
Embed
Embed presentation
Download
Download to read offline
1
/ 5
2
/ 5
3
/ 5
4
/ 5
5
/ 5
More Related Content
PDF
演習II.第1章 ベイズ推論の考え方 Part 3.スライド
by
Wataru Shito
PDF
経済数学II 「第9章 最適化(Optimization)」
by
Wataru Shito
PDF
クラシックな機械学習の入門 4. 学習データと予測性能
by
Hiroshi Nakagawa
PPTX
Vanishing Component Analysis
by
Koji Matsuda
PPTX
第五回統計学勉強会@東大駒場
by
Daisuke Yoneoka
PDF
2012-06-15-トピックを考慮したソーシャルネットワーク上の情報拡散モデル
by
Yuya Yoshikawa
PDF
論文紹介 Semi-supervised Learning with Deep Generative Models
by
Seiya Tokui
PPT
ma99992006id365
by
matsushimalab
演習II.第1章 ベイズ推論の考え方 Part 3.スライド
by
Wataru Shito
経済数学II 「第9章 最適化(Optimization)」
by
Wataru Shito
クラシックな機械学習の入門 4. 学習データと予測性能
by
Hiroshi Nakagawa
Vanishing Component Analysis
by
Koji Matsuda
第五回統計学勉強会@東大駒場
by
Daisuke Yoneoka
2012-06-15-トピックを考慮したソーシャルネットワーク上の情報拡散モデル
by
Yuya Yoshikawa
論文紹介 Semi-supervised Learning with Deep Generative Models
by
Seiya Tokui
ma99992006id365
by
matsushimalab
What's hot
PDF
DL Hacks輪読 Semi-supervised Learning with Deep Generative Models
by
Yusuke Iwasawa
PDF
クラシックな機械学習の入門 9. モデル推定
by
Hiroshi Nakagawa
PPTX
ブートストラップ法とその周辺とR
by
Daisuke Yoneoka
PDF
パターン認識02 k平均法ver2.0
by
sleipnir002
PPT
Tokyo r#10 Rによるデータサイエンス 第五章:クラスター分析
by
hnisiji
PDF
03_深層学習
by
CHIHIROGO
PDF
はじめてのパターン認識輪読会 10章後半
by
koba cky
PDF
みどりぼん読書会 第4章
by
Masanori Takano
PPTX
[DL輪読会]Learning by Association - A versatile semi-supervised training method ...
by
Deep Learning JP
PDF
PRML s1
by
eizoo3010
PPTX
PRMLrevenge_3.3
by
Naoya Nakamura
PDF
パターン認識 08 09 k-近傍法 lvq
by
sleipnir002
PDF
Word2vec alpha
by
KCS Keio Computer Society
PDF
Spring
by
Lutfiana Ariestien
PPTX
[DL輪読会] “Asymmetric Tri-training for Unsupervised Domain Adaptation (ICML2017...
by
Yusuke Iwasawa
PDF
Prml 3 3.3
by
Arata Honda
PPTX
Retrofitting Word Vectors to Semantic Lexicons
by
Sho Takase
PPTX
深層学習①
by
ssuser60e2a31
PDF
PRML輪読#10
by
matsuolab
PPTX
Nexus network connecting the preceding and the following in dialogue generation
by
OgataTomoya
DL Hacks輪読 Semi-supervised Learning with Deep Generative Models
by
Yusuke Iwasawa
クラシックな機械学習の入門 9. モデル推定
by
Hiroshi Nakagawa
ブートストラップ法とその周辺とR
by
Daisuke Yoneoka
パターン認識02 k平均法ver2.0
by
sleipnir002
Tokyo r#10 Rによるデータサイエンス 第五章:クラスター分析
by
hnisiji
03_深層学習
by
CHIHIROGO
はじめてのパターン認識輪読会 10章後半
by
koba cky
みどりぼん読書会 第4章
by
Masanori Takano
[DL輪読会]Learning by Association - A versatile semi-supervised training method ...
by
Deep Learning JP
PRML s1
by
eizoo3010
PRMLrevenge_3.3
by
Naoya Nakamura
パターン認識 08 09 k-近傍法 lvq
by
sleipnir002
Word2vec alpha
by
KCS Keio Computer Society
Spring
by
Lutfiana Ariestien
[DL輪読会] “Asymmetric Tri-training for Unsupervised Domain Adaptation (ICML2017...
by
Yusuke Iwasawa
Prml 3 3.3
by
Arata Honda
Retrofitting Word Vectors to Semantic Lexicons
by
Sho Takase
深層学習①
by
ssuser60e2a31
PRML輪読#10
by
matsuolab
Nexus network connecting the preceding and the following in dialogue generation
by
OgataTomoya
Similar to 演習II.第1章 ベイズ推論の考え方 Part 3.講義ノート
PDF
PRML セミナー
by
sakaguchi050403
PDF
ベイズ統計入門
by
Miyoshi Yuya
PPTX
ベイズ統計学の概論的紹介
by
Naoki Hayashi
PDF
2 3.GLMの基礎
by
logics-of-blue
PDF
演習II.第1章 ベイズ推論の考え方 Part 2.スライド
by
Wataru Shito
PDF
演習II.第1章 ベイズ推論の考え方 Part 2.講義ノート
by
Wataru Shito
PDF
PRML10-draft1002
by
Toshiyuki Shimono
PDF
20190512 bayes hands-on
by
Yoichi Tokita
PDF
PRML第3章_3.3-3.4
by
Takashi Tamura
PPT
ma92008id394
by
matsushimalab
PDF
MLaPP 5章 「ベイズ統計学」
by
moterech
PDF
これからの仮説検証・モデル評価
by
daiki hojo
PDF
統計的因果推論 勉強用 isseing333
by
Issei Kurahashi
PDF
PRML輪読#2
by
matsuolab
PDF
2019年 演習II.第1章 ベイズ推論の考え方 Part 1
by
Wataru Shito
PDF
Prml2.1 2.2,2.4-2.5
by
Takuto Kimura
PDF
PRML2.1 2.2
by
Takuto Kimura
PPTX
第四回統計学勉強会@東大駒場
by
Daisuke Yoneoka
PDF
データ解析14 ナイーブベイズ
by
Hirotaka Hachiya
PDF
ノンパラベイズ入門の入門
by
Shuyo Nakatani
PRML セミナー
by
sakaguchi050403
ベイズ統計入門
by
Miyoshi Yuya
ベイズ統計学の概論的紹介
by
Naoki Hayashi
2 3.GLMの基礎
by
logics-of-blue
演習II.第1章 ベイズ推論の考え方 Part 2.スライド
by
Wataru Shito
演習II.第1章 ベイズ推論の考え方 Part 2.講義ノート
by
Wataru Shito
PRML10-draft1002
by
Toshiyuki Shimono
20190512 bayes hands-on
by
Yoichi Tokita
PRML第3章_3.3-3.4
by
Takashi Tamura
ma92008id394
by
matsushimalab
MLaPP 5章 「ベイズ統計学」
by
moterech
これからの仮説検証・モデル評価
by
daiki hojo
統計的因果推論 勉強用 isseing333
by
Issei Kurahashi
PRML輪読#2
by
matsuolab
2019年 演習II.第1章 ベイズ推論の考え方 Part 1
by
Wataru Shito
Prml2.1 2.2,2.4-2.5
by
Takuto Kimura
PRML2.1 2.2
by
Takuto Kimura
第四回統計学勉強会@東大駒場
by
Daisuke Yoneoka
データ解析14 ナイーブベイズ
by
Hirotaka Hachiya
ノンパラベイズ入門の入門
by
Shuyo Nakatani
More from Wataru Shito
PDF
第3章 遅延学習---最近傍法を使った分類
by
Wataru Shito
PDF
統計的推定の基礎 2 -- 分散の推定
by
Wataru Shito
PDF
統計的推定の基礎 1 -- 期待値の推定
by
Wataru Shito
PDF
第4章 確率的学習---単純ベイズを使った分類
by
Wataru Shito
PDF
演習II.第1章 ベイズ推論の考え方 Part 1.講義ノート
by
Wataru Shito
PDF
マクロ経済学I 「第8章 総需要・総供給分析(AD-AS分析)」
by
Wataru Shito
PDF
マクロ経済学I 「第10章 総需要 II.IS-LM分析とAD曲線」
by
Wataru Shito
PDF
第9回 大規模データを用いたデータフレーム操作実習(3)
by
Wataru Shito
PDF
第8回 大規模データを用いたデータフレーム操作実習(2)
by
Wataru Shito
PDF
経済数学II 「第12章 制約つき最適化」
by
Wataru Shito
PDF
マクロ経済学I 「第9章 総需要 I」
by
Wataru Shito
PDF
経済数学II 「第11章 選択変数が2個以上の場合の最適化」
by
Wataru Shito
PDF
マクロ経済学I 「第6章 開放経済の長期分析」
by
Wataru Shito
PDF
経済数学II 「第8章 一般関数型モデルの比較静学」
by
Wataru Shito
PDF
マクロ経済学I 「第4,5章 貨幣とインフレーション」
by
Wataru Shito
PDF
マクロ経済学I 「第3章 長期閉鎖経済モデル」
by
Wataru Shito
PDF
経済数学II 「第7章 微分法とその比較静学への応用」
by
Wataru Shito
PDF
経済数学II 「第6章 比較静学と導関数の概念」
by
Wataru Shito
PDF
マクロ経済学I 「マクロ経済分析の基礎知識」
by
Wataru Shito
PDF
経済数学II 「第5章 線型モデルと行列代数 II」
by
Wataru Shito
第3章 遅延学習---最近傍法を使った分類
by
Wataru Shito
統計的推定の基礎 2 -- 分散の推定
by
Wataru Shito
統計的推定の基礎 1 -- 期待値の推定
by
Wataru Shito
第4章 確率的学習---単純ベイズを使った分類
by
Wataru Shito
演習II.第1章 ベイズ推論の考え方 Part 1.講義ノート
by
Wataru Shito
マクロ経済学I 「第8章 総需要・総供給分析(AD-AS分析)」
by
Wataru Shito
マクロ経済学I 「第10章 総需要 II.IS-LM分析とAD曲線」
by
Wataru Shito
第9回 大規模データを用いたデータフレーム操作実習(3)
by
Wataru Shito
第8回 大規模データを用いたデータフレーム操作実習(2)
by
Wataru Shito
経済数学II 「第12章 制約つき最適化」
by
Wataru Shito
マクロ経済学I 「第9章 総需要 I」
by
Wataru Shito
経済数学II 「第11章 選択変数が2個以上の場合の最適化」
by
Wataru Shito
マクロ経済学I 「第6章 開放経済の長期分析」
by
Wataru Shito
経済数学II 「第8章 一般関数型モデルの比較静学」
by
Wataru Shito
マクロ経済学I 「第4,5章 貨幣とインフレーション」
by
Wataru Shito
マクロ経済学I 「第3章 長期閉鎖経済モデル」
by
Wataru Shito
経済数学II 「第7章 微分法とその比較静学への応用」
by
Wataru Shito
経済数学II 「第6章 比較静学と導関数の概念」
by
Wataru Shito
マクロ経済学I 「マクロ経済分析の基礎知識」
by
Wataru Shito
経済数学II 「第5章 線型モデルと行列代数 II」
by
Wataru Shito
演習II.第1章 ベイズ推論の考え方 Part 3.講義ノート
1.
第1章 ベイズ推論の考え方 Part
3 市東 亘 2021 年 8 月 23 日 1 概観 テキスト「Python で体験するベイズ推論」pp.15–24 例題: メッセージ数に変化はあるか? • 分析の背後にある統計モデルを理解する. • PyMC3 による実装方法を学ぶ. 2 例題: メッセージ数に変化はあるか? 目的 • メッセージ数がある時点を境に変化したと言えるか? • 変化したならいつ? 0 10 20 30 40 50 60 70 Time (days) 0 10 20 30 40 50 60 70 count of text-msgs received Did the user's texting habits change over time? 図 1: メッセージ受信数 モデル ポアッソン分布 • ある期間を等間隔の区間に分け,その区間に生起するイベントが, – すべての区間で平均的に同じ率で観測され, 1
2.
– 各イベントがこれまでに観測されたイベントに依存せず独立ならば, ⇒ ポアソン分布に従う. •
非負の整数値をとる確率変数 X がポアソン分布に従うとき,確率分布は以下で与えられる. P({X = k}) = λk e−λ k! パラメータ λ > 0 は事象が生起する強度(intensity)を表す. • ポアソン分布の期待値と分散 – E[X] = λ – V ar[X] = λ メッセージ数の確率モデル • メッセージ数 x はポアッソン分布に従うと仮定する. ⇒ xt ∼ Poisson(λ) • E[X] = λ より λ はメッセージ受信数の期待値を表す. • ある時期を境にメッセージ受信数の変化があったかどうかをモデル化するには,ポアッソン 分布のパラメータ λ(メッセージ受信数の期待値)がある時期を境に変化したかを検証すれ ば良い. ⇒ 言い換えると,ある時期を境にメッセージ受信数が従うポアッソン分布に変化が生じた かを検証していることになる. • 確率モデルのまとめ xt ∼ Poisson(λ) where λ = { λ1 for t < τ λ2 for t ≥ τ ベイズ推定の復習 • データを所与の定数として,統計モデルのパラメータを確率変数として考えるのがベイズ 推定. Pr(H|D) = Pr(D|H)Pr(H) Pr(D) ∝ Pr(D|H)Pr(H) f(θ|x) ∝ f(x|θ)f(θ) • 我々が求めたいのはデータが従う統計モデルのパラメータの事後分布関数 ⇒ f(λ|x) ∝ f(x|λ)f(λ), ただし,x はメッセージ数のデータを表す. 西南学院大学 演習 II(2019 年) 2 担当 市東 亘
3.
ベイズモデル • ここでは λ
は λ1, λ2, τ に依存して値が決まるとモデル化する. f(λ|x) ∝ f(x|λ)f(λ) ↔ f({λ1, λ2, τ}|x) ∝ f(x|{λ1, λ2, τ})f({λ1, λ2, τ}) = f(x|{λ1, λ2, τ})f(λ1)f(λ2)f(τ) – 尤度関数: f(xt|{λ1, λ2, τ}) = λxt e−λ xt! , where { λ1 for t < τ λ2 for t ≥ τ – 事前分布: f(τ) =? – 事前分布: f(λi) =? for i = 1, 2 • τ の事前分布を考える – τ はメッセージ数に変化が生じたと考えられる期日. – 特に特定の日に変化が生じたという信念はない. ⇒ 期日全体に一様に分布していると考えられる. ⇒ 理由不十分の原則 – 事前分布: f(τ) = DiscreteUniform(1, 70) • λi の事前分布を考える – λi はポアッソン分布のパラメータで λi > 0. – 非負の確率変数が従う指数分布が使えそう. ⇒ 事前分布は主観的であることを思い出そう! – 事前分布: f(λi) = eα , for i = 1, 2 ただし,α = ( ∑ xt/N)−1 で定数とする. – パラメータ α をこの様に定義すると各区間のメッセージ数の期待値を表す λ と整合的 になる. ⇒ 指数分布の期待値より E[λ] = 1/α. ⇒ 1/α が区間におけるメッセージ数の期待値に適合するように 1/α = ∑ xt/N と定義. – λi の分布はさらに別のパラメータ α に依存することになった! • メッセージ数のベイズモデルまとめ f({λ1, λ2, τ}|x) ∝ f(x|{λ1, λ2, τ})f(λ1)f(λ2)f(τ) – 尤度関数: f(xt|{λ1, λ2, τ}) = λxt e−λ xt! , where { λ1 for t < τ λ2 for t ≥ τ – 事前分布: f(τ) = DiscreteUniform(1, 70) – 事前分布: f(λi) = eα for i = 1, 2 ただし,α = ( ∑ xt/N)−1 で定数とする. 西南学院大学 演習 II(2019 年) 3 担当 市東 亘
4.
確率的プログラミング • 前ページで定義した事前分布と尤度関数を全て定義すれば,Stan や
PyMC3 等のプログラム が事後分布に従うサンプルを生成してくれる. • 事後分布に従うサンプルを用いて確率を計算すれば,事後分布を数式として求める必要もな いし,分布関数の積分も必要ない. PyMC3 の基本 • General API Quickstart: https://docs.pymc.io/notebooks/api_quickstart.html • モデルは with pm.Model() ブロック内に記述する. • 尤度の定義では observed 引数にデータを添付する. • 非確率変数は通常の変数定義で良い.ただし確率変数のサンプルと一緒に記録したければ pm.Deterministic() を使って定義する. コード 1 メッセージ数の変化 1 import numpy as np 2 import pymc3 as pm 3 4 count_data = np.loadtxt("data/txtdata.csv") 5 6 n_count_data = len(count_data) 7 alpha = 1.0 / count_data.mean() 8 idx = np.arange(n_count_data) # 0 から n_count_data-1 までの index の配列を作成 9 10 with pm.Model() as model: # モデル定義 11 lambda_1 = pm.Exponential("lambda_1", alpha) 12 lambda_2 = pm.Exponential("lambda_2", alpha) 13 tau = pm.DiscreteUniform("tau", lower=0, upper=n_count_data) 14 lambda_ = pm.math.switch(tau >= idx, lambda_1, lambda_2) 15 obs = pm.Poisson("obs", lambda_, observed=count_data) 16 17 with model: 18 trace = pm.sample(40000) # サンプルの生成 コード 2 モデル定義ブロック部分 with pm.Model() as model: # 事前分布(確率変数)の定義 lambda_1 = pm.Exponential("lambda_1", alpha) lambda_2 = pm.Exponential("lambda_2", alpha) tau = pm.DiscreteUniform("tau", lower=0, upper=n_count_data) # idx の値に応じて変わる lambda 確率変数の定義 lambda_ = pm.math.switch(tau >= idx, lambda_1, lambda_2) # 尤度の定義 obs = pm.Poisson("obs", lambda_, observed=count_data) pm.model_to_graphviz(model) pm.traceplot(trace) 西南学院大学 演習 II(2019 年) 4 担当 市東 亘
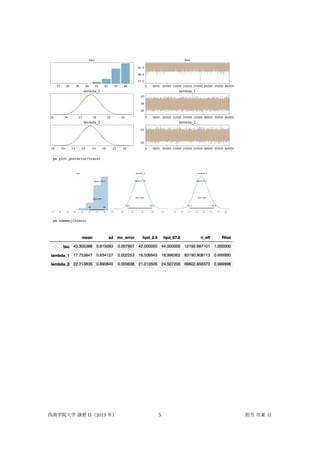
5.
pm.plot_posterior(trace) pm.summary(trace) 西南学院大学 演習 II(2019
年) 5 担当 市東 亘
Download


![– 各イベントがこれまでに観測されたイベントに依存せず独立ならば,
⇒ ポアソン分布に従う.
• 非負の整数値をとる確率変数 X がポアソン分布に従うとき,確率分布は以下で与えられる.
P({X = k}) =
λk
e−λ
k!
パラメータ λ > 0 は事象が生起する強度(intensity)を表す.
• ポアソン分布の期待値と分散
– E[X] = λ
– V ar[X] = λ
メッセージ数の確率モデル
• メッセージ数 x はポアッソン分布に従うと仮定する.
⇒ xt ∼ Poisson(λ)
• E[X] = λ より λ はメッセージ受信数の期待値を表す.
• ある時期を境にメッセージ受信数の変化があったかどうかをモデル化するには,ポアッソン
分布のパラメータ λ(メッセージ受信数の期待値)がある時期を境に変化したかを検証すれ
ば良い.
⇒ 言い換えると,ある時期を境にメッセージ受信数が従うポアッソン分布に変化が生じた
かを検証していることになる.
• 確率モデルのまとめ
xt ∼ Poisson(λ)
where λ =
{
λ1 for t < τ
λ2 for t ≥ τ
ベイズ推定の復習
• データを所与の定数として,統計モデルのパラメータを確率変数として考えるのがベイズ
推定.
Pr(H|D) =
Pr(D|H)Pr(H)
Pr(D)
∝ Pr(D|H)Pr(H)
f(θ|x) ∝ f(x|θ)f(θ)
• 我々が求めたいのはデータが従う統計モデルのパラメータの事後分布関数
⇒ f(λ|x) ∝ f(x|λ)f(λ),
ただし,x はメッセージ数のデータを表す.
西南学院大学 演習 II(2019 年) 2 担当 市東 亘](https://image.slidesharecdn.com/ch01-message-handout-210823072652/85/II-Part-3-2-320.jpg)
![ベイズモデル
• ここでは λ は λ1, λ2, τ に依存して値が決まるとモデル化する.
f(λ|x) ∝ f(x|λ)f(λ)
↔ f({λ1, λ2, τ}|x) ∝ f(x|{λ1, λ2, τ})f({λ1, λ2, τ})
= f(x|{λ1, λ2, τ})f(λ1)f(λ2)f(τ)
– 尤度関数: f(xt|{λ1, λ2, τ}) =
λxt
e−λ
xt!
, where
{
λ1 for t < τ
λ2 for t ≥ τ
– 事前分布: f(τ) =?
– 事前分布: f(λi) =? for i = 1, 2
• τ の事前分布を考える
– τ はメッセージ数に変化が生じたと考えられる期日.
– 特に特定の日に変化が生じたという信念はない.
⇒ 期日全体に一様に分布していると考えられる.
⇒ 理由不十分の原則
– 事前分布: f(τ) = DiscreteUniform(1, 70)
• λi の事前分布を考える
– λi はポアッソン分布のパラメータで λi > 0.
– 非負の確率変数が従う指数分布が使えそう.
⇒ 事前分布は主観的であることを思い出そう!
– 事前分布: f(λi) = eα
, for i = 1, 2
ただし,α = (
∑
xt/N)−1
で定数とする.
– パラメータ α をこの様に定義すると各区間のメッセージ数の期待値を表す λ と整合的
になる.
⇒ 指数分布の期待値より E[λ] = 1/α.
⇒ 1/α が区間におけるメッセージ数の期待値に適合するように 1/α =
∑
xt/N と定義.
– λi の分布はさらに別のパラメータ α に依存することになった!
• メッセージ数のベイズモデルまとめ
f({λ1, λ2, τ}|x) ∝ f(x|{λ1, λ2, τ})f(λ1)f(λ2)f(τ)
– 尤度関数: f(xt|{λ1, λ2, τ}) =
λxt
e−λ
xt!
, where
{
λ1 for t < τ
λ2 for t ≥ τ
– 事前分布: f(τ) = DiscreteUniform(1, 70)
– 事前分布: f(λi) = eα
for i = 1, 2
ただし,α = (
∑
xt/N)−1
で定数とする.
西南学院大学 演習 II(2019 年) 3 担当 市東 亘](https://image.slidesharecdn.com/ch01-message-handout-210823072652/85/II-Part-3-3-320.jpg)

















![[DL輪読会]Learning by Association - A versatile semi-supervised training method ...](https://cdn.slidesharecdn.com/ss_thumbnails/dl-170613062403-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会] “Asymmetric Tri-training for Unsupervised Domain Adaptation (ICML2017...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks20170728-170728025901-thumbnail.jpg?width=640&height=640&fit=bounds)












































