





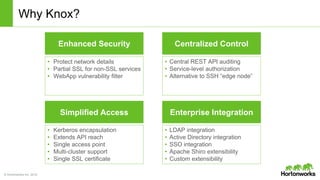
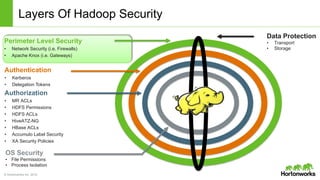
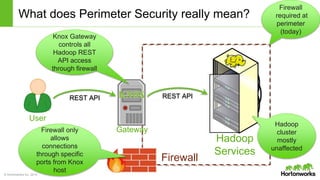


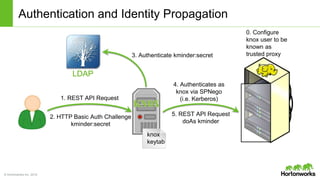
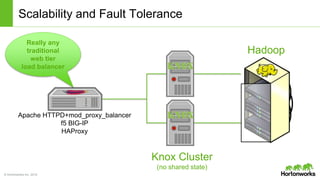




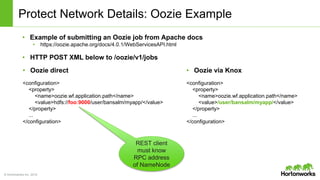
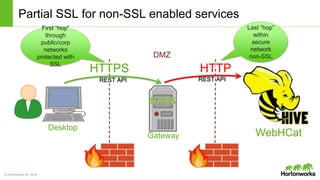


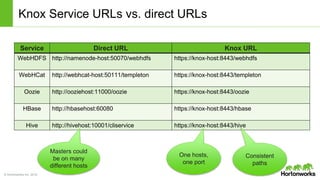

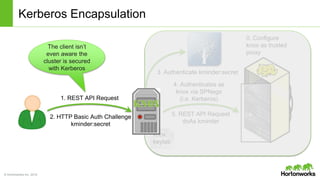
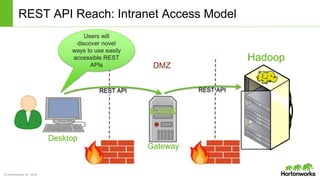
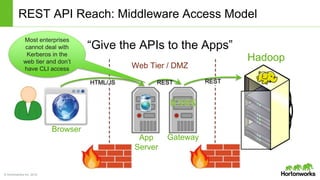
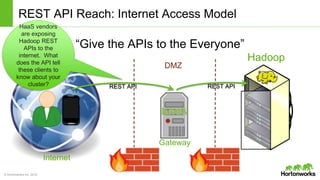
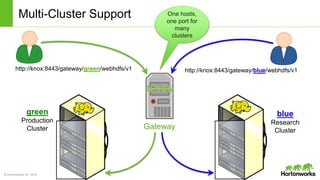
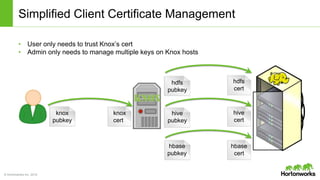

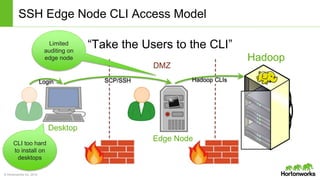
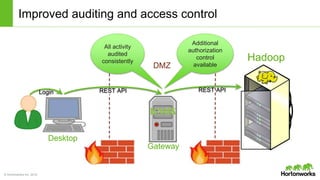

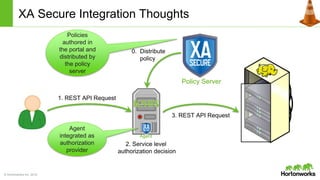

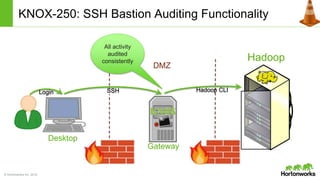





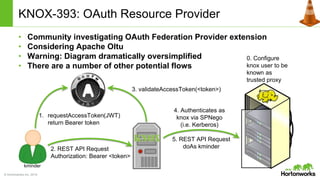
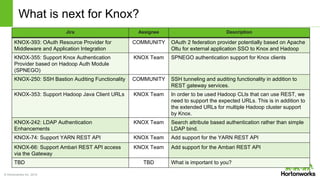



The document discusses the Apache Knox Gateway, which is an extensible reverse proxy framework that securely exposes REST APIs and HTTP-based services from Hadoop clusters. It provides features such as support for common Hadoop services, integration with enterprise authentication systems, centralized auditing of REST API access, and service-level authorization controls. The Knox Gateway aims to simplify access to Hadoop services, enhance security by protecting network details and supporting partial SSL, and enable centralized management and control over REST API access.





















































































