Download as PDF, PPTX


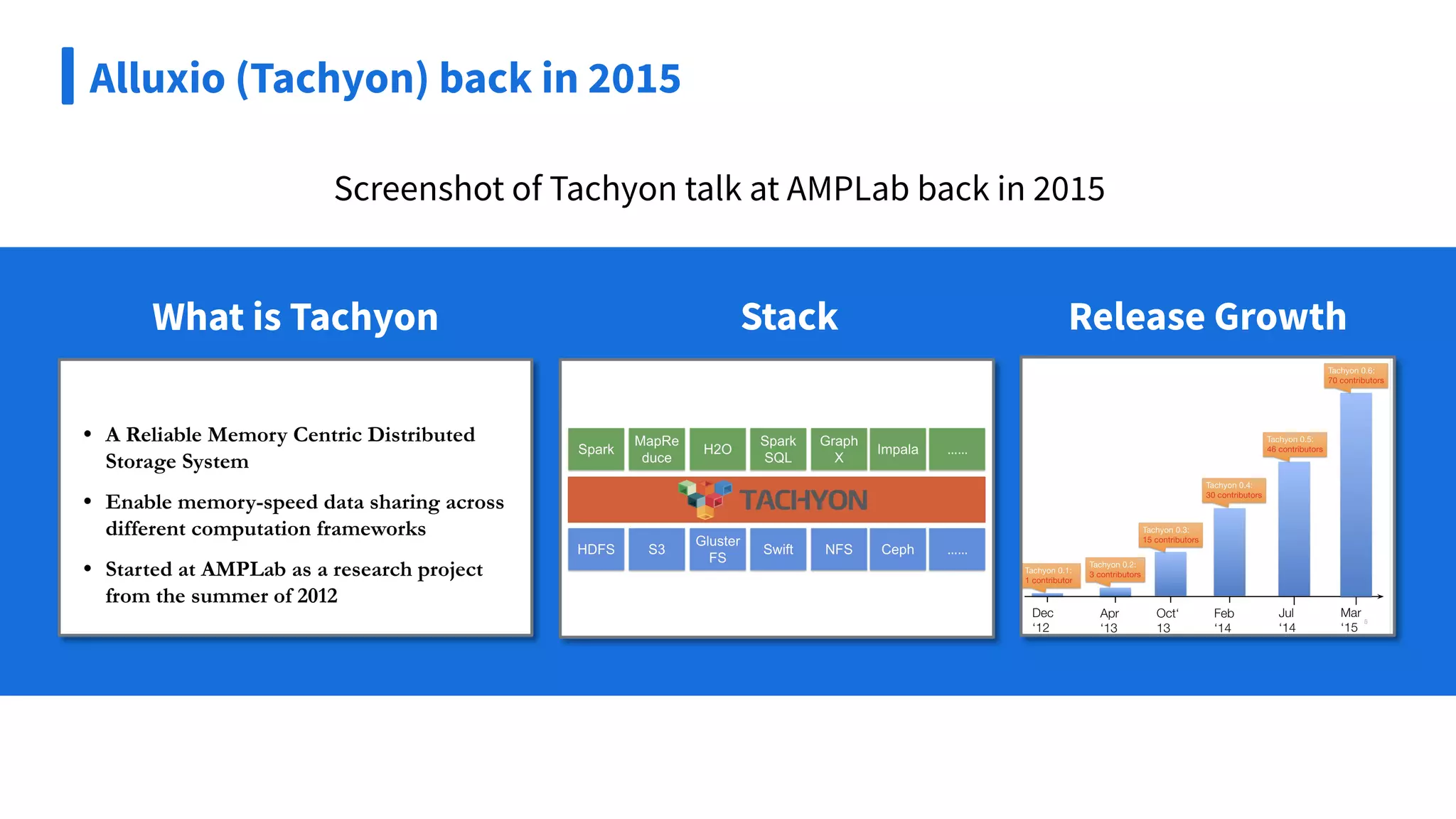
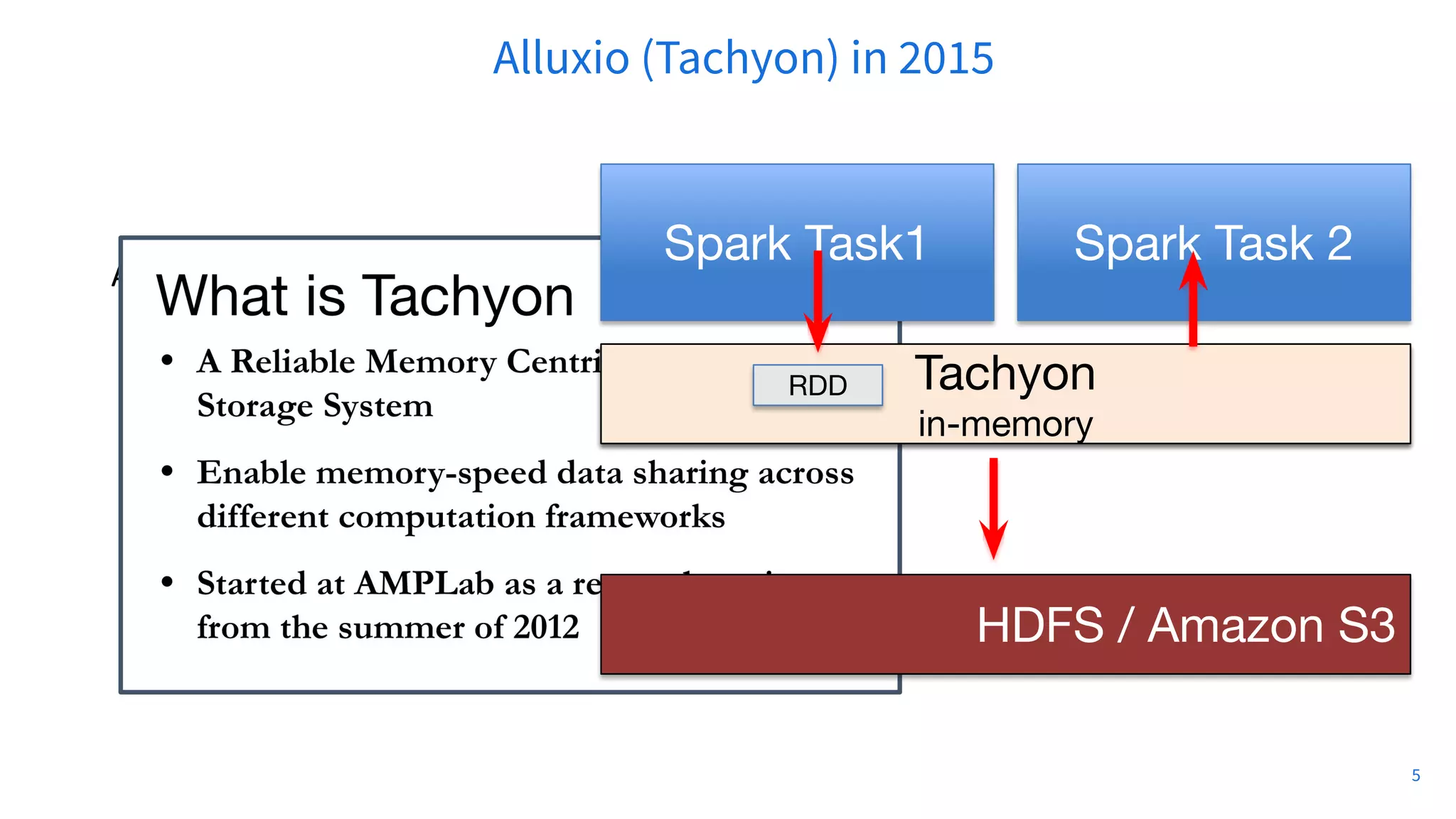
![● Originally a research project (Tachyon) in UC Berkeley AMPLab led by by-then PHD student
Haoyuan Li (Alluxio founder CEO)
● Backed by top VCs (e.g., Andreessen Horowitz) with $70M raised in total, Series C ($50M)
announced in 2021
● Deployed in production at large scale in Facebook, Uber, Microsoft, Tencent, Tiktok and etc
● More than 1200 Contributors on Github. In 2021, more than 40% commits in Github were
contributed by the community users
● The 9th most critical Java-based Open-Source projects on Github by Google/OpenSSF[1]
Alluxio Overview
ALLUXIO 3
[1] Google Comes Up With A Metric For Gauging Critical Open-Source Projects](https://image.slidesharecdn.com/eliminateexpensivedatacopiesacrossregionsorcloudsforanalytics-220702015856-a73176af/75/Architecting-a-Heterogeneous-Data-Platform-Across-Clusters-Regions-and-Clouds-3-2048.jpg)


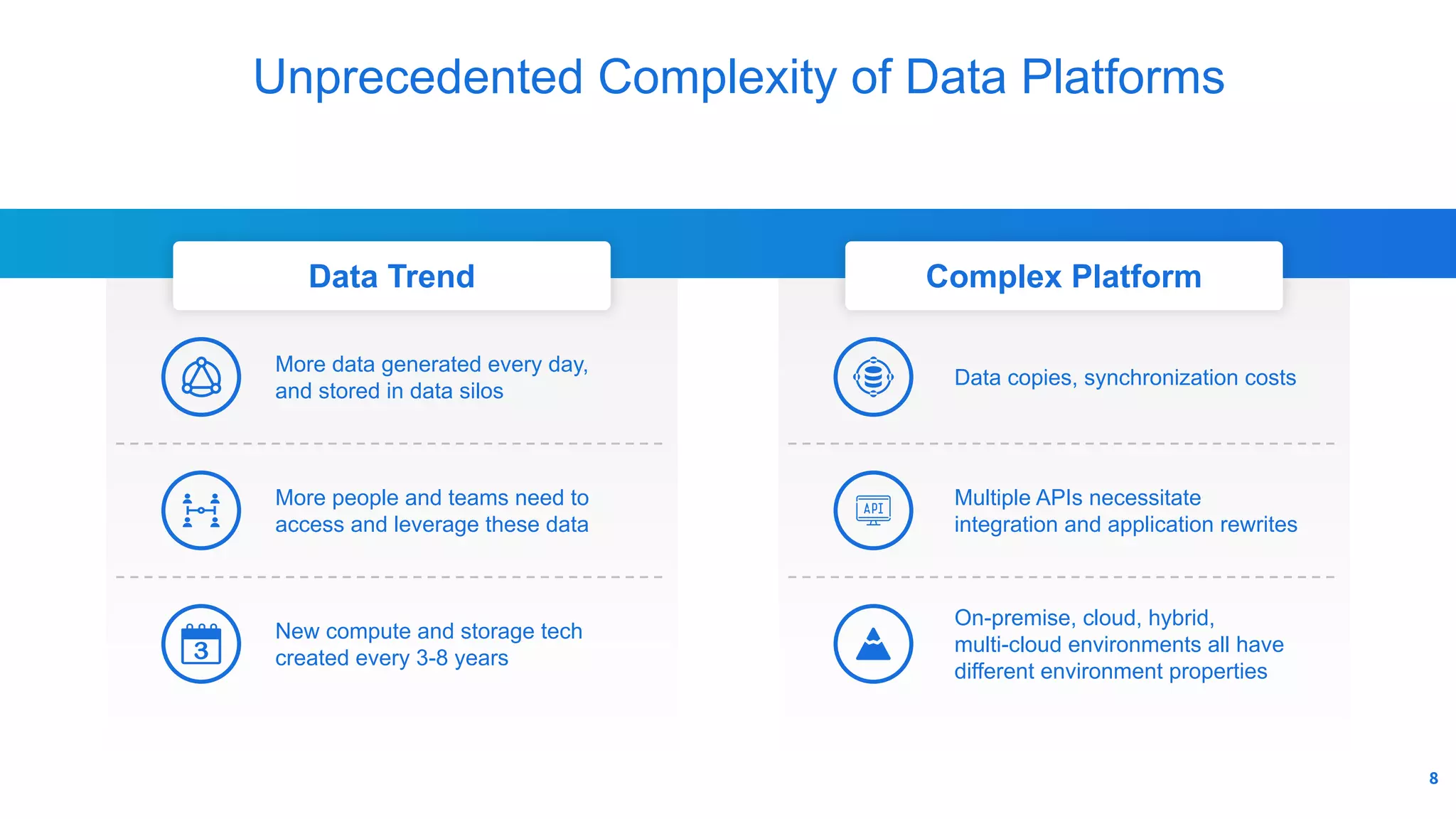
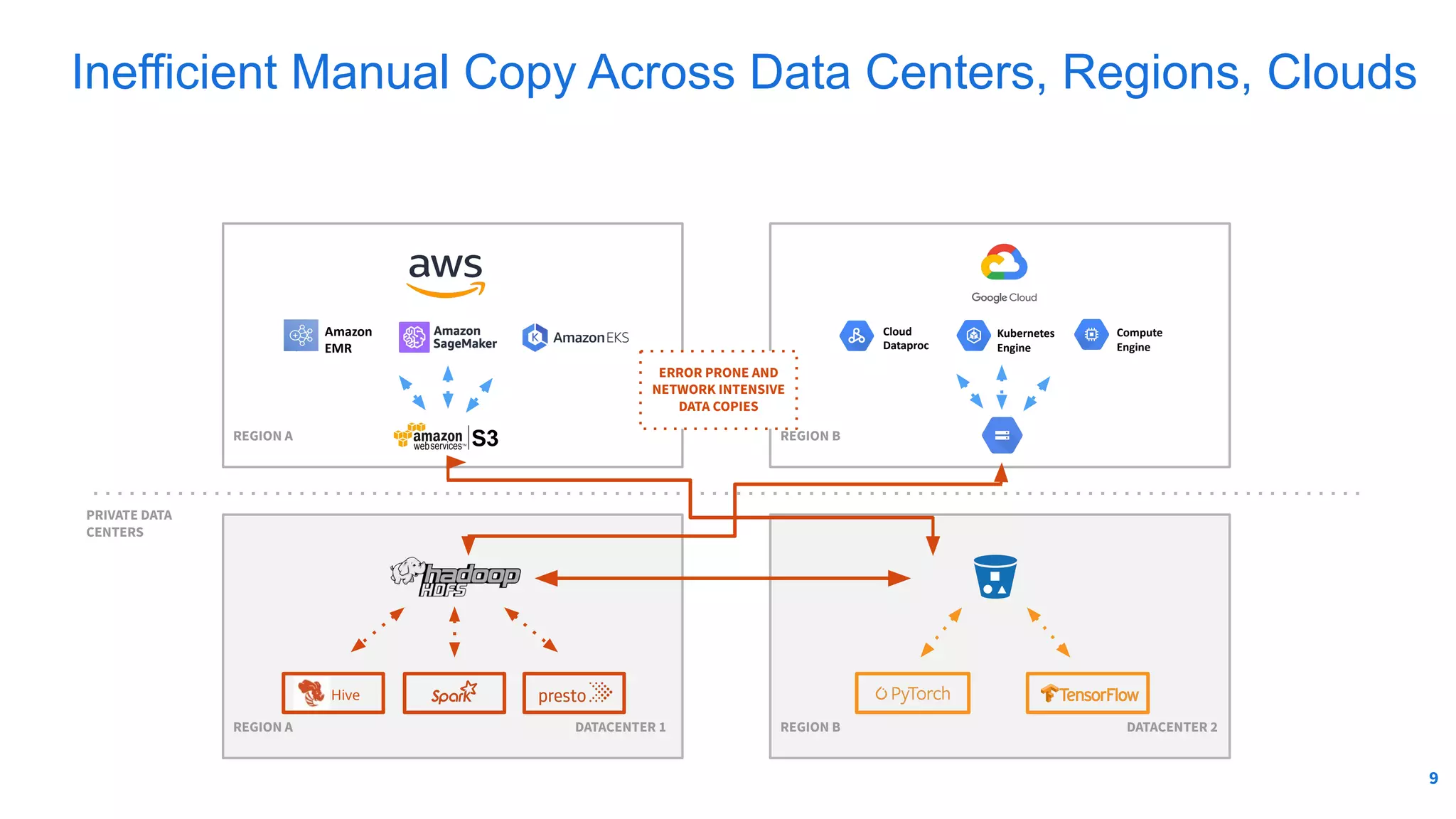


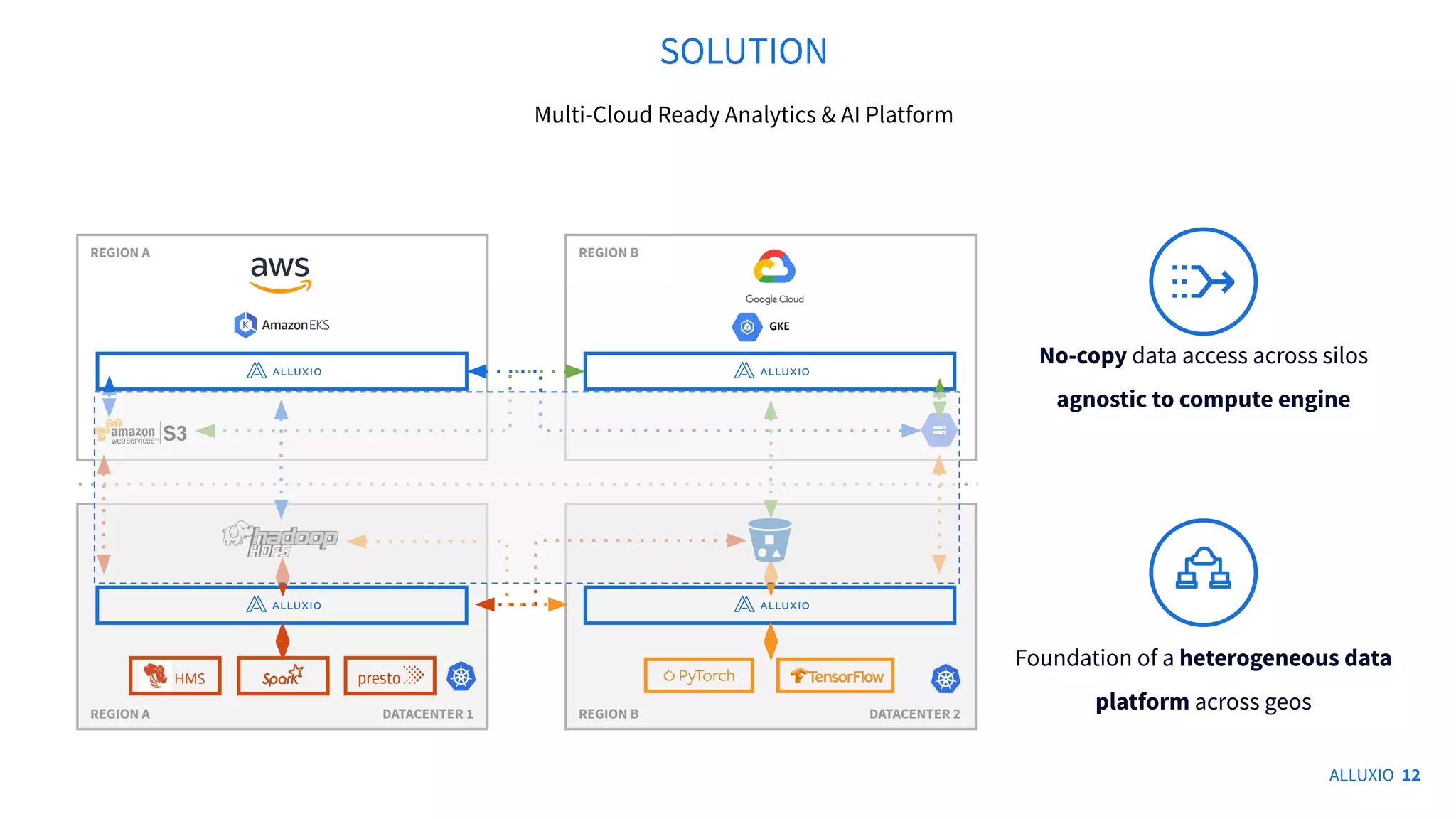


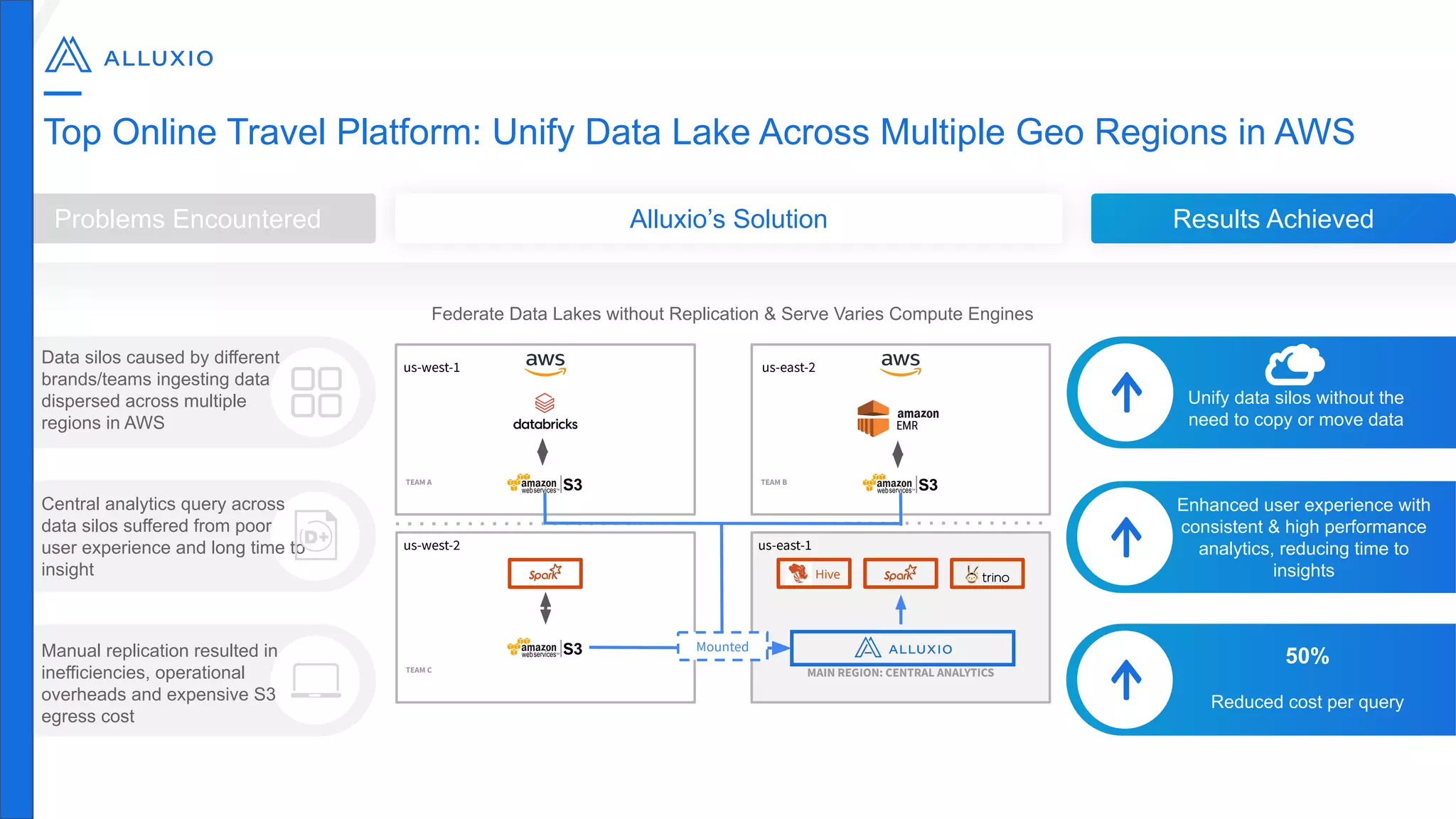
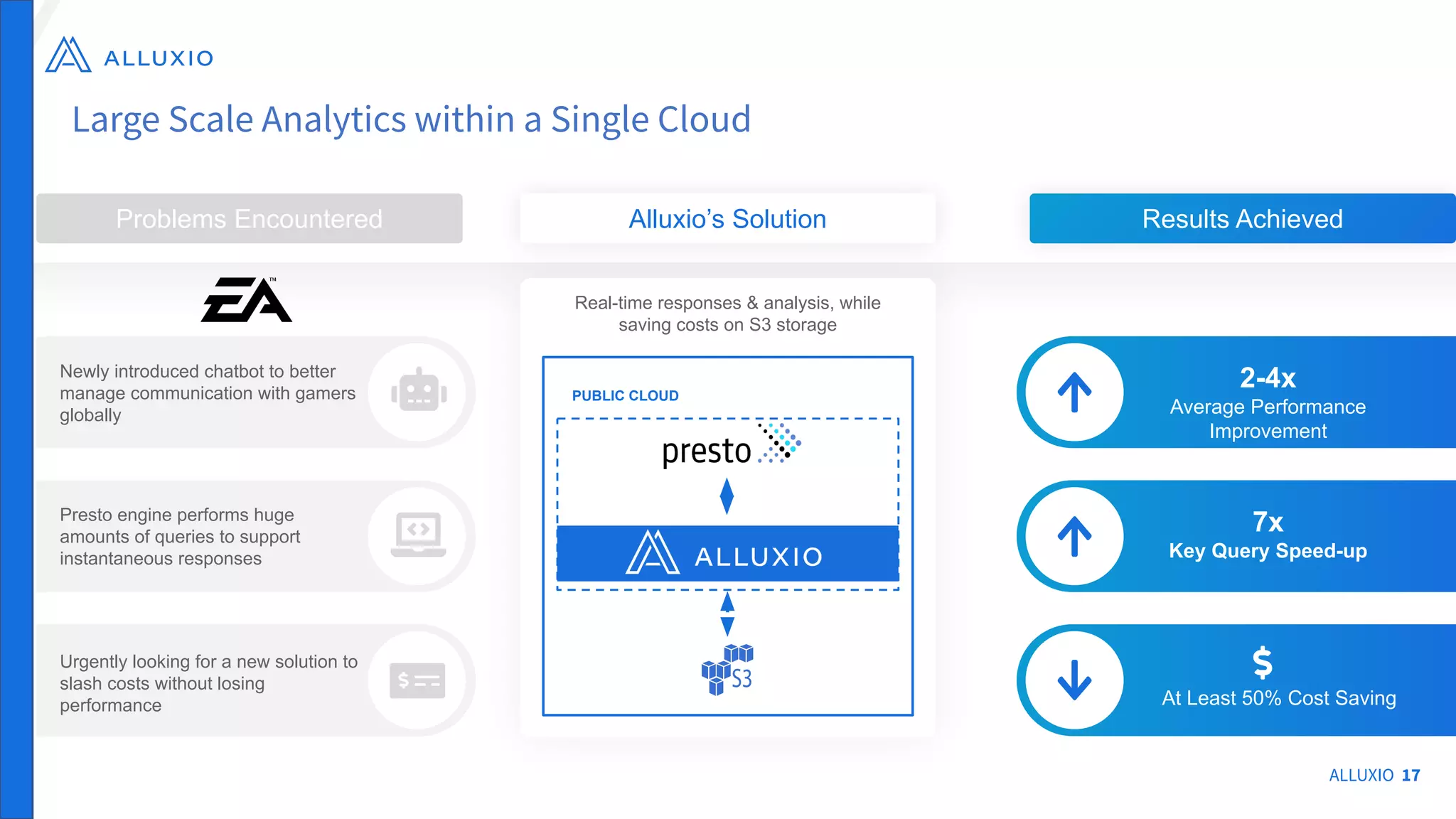

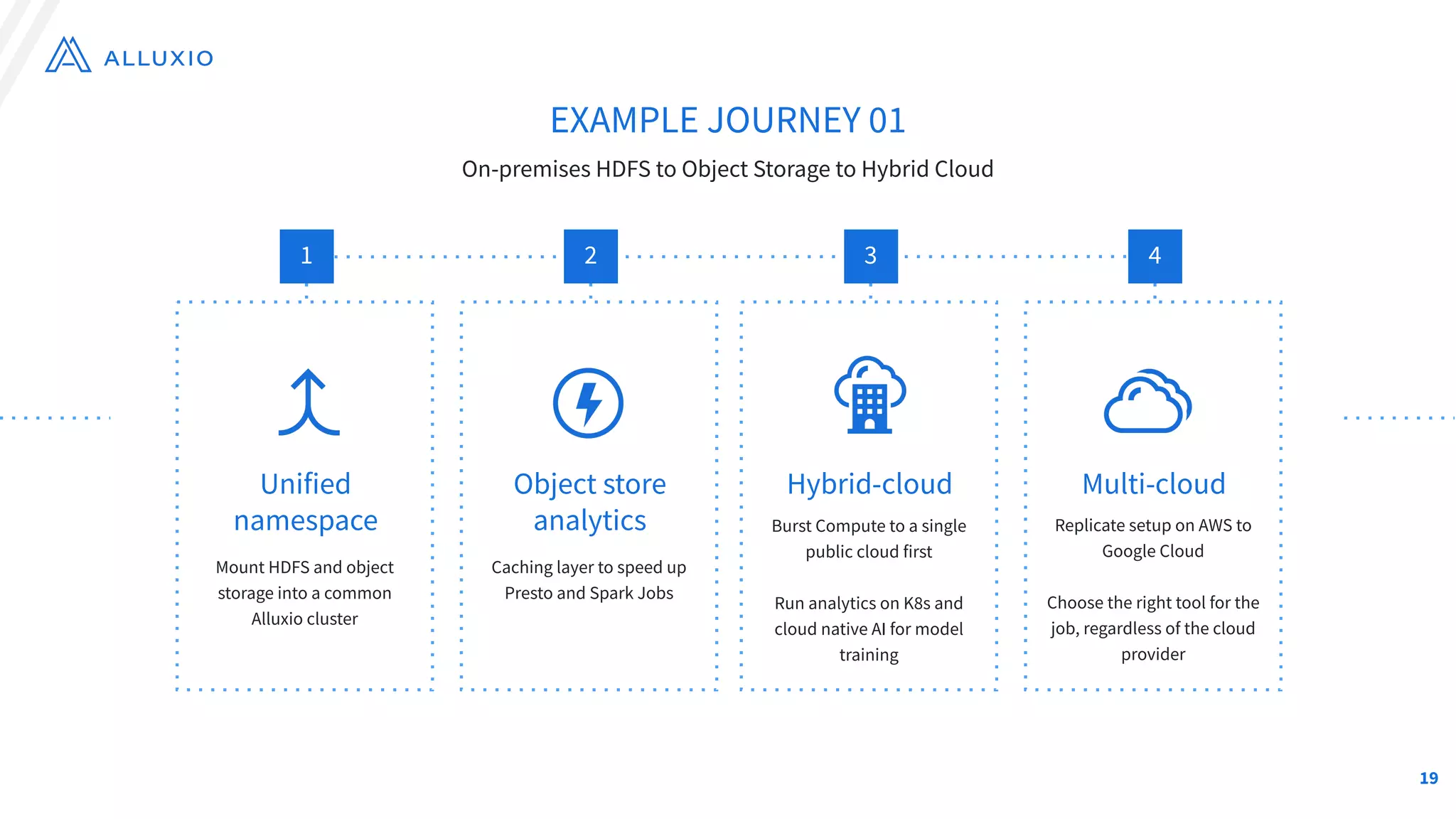
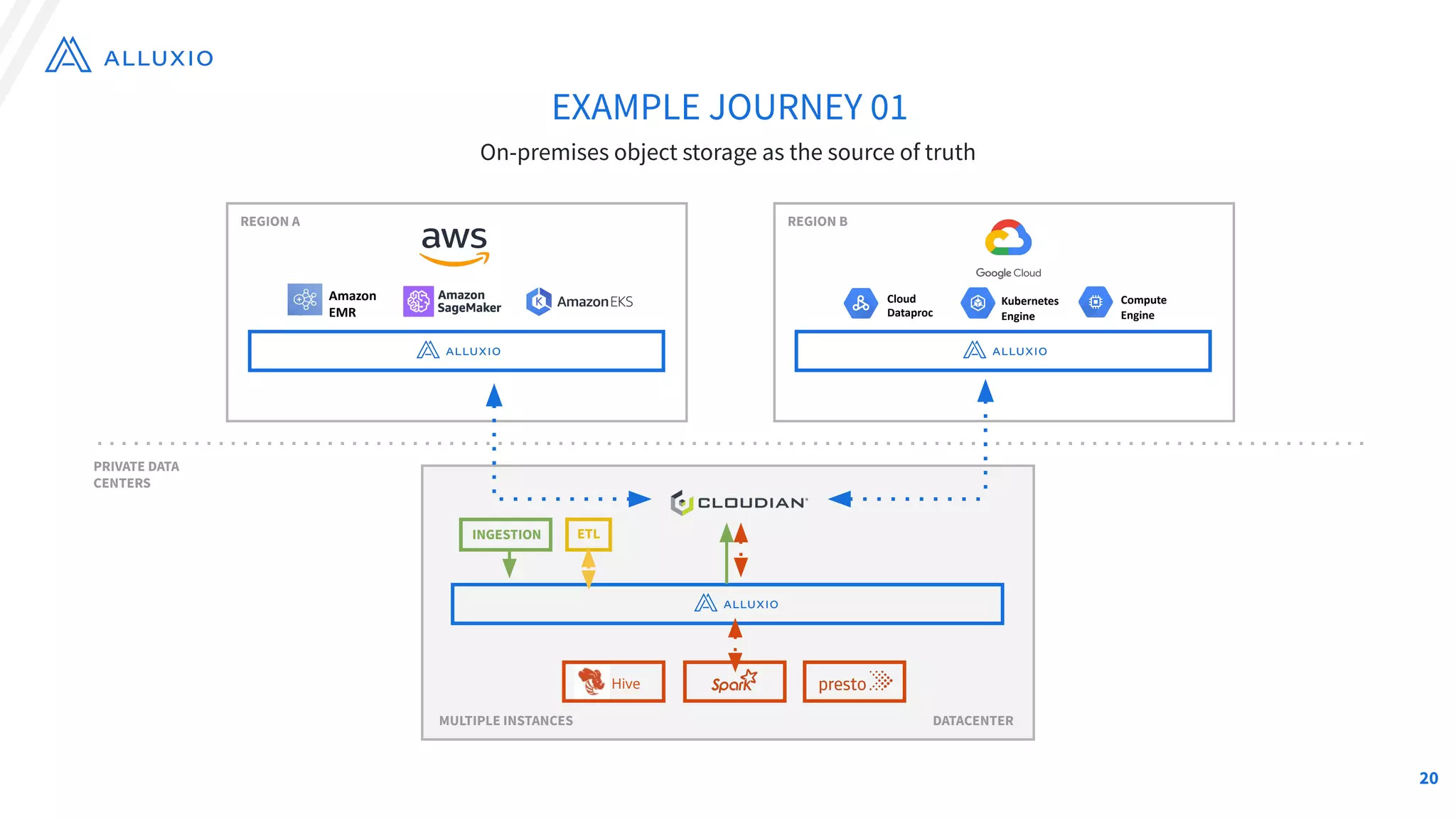

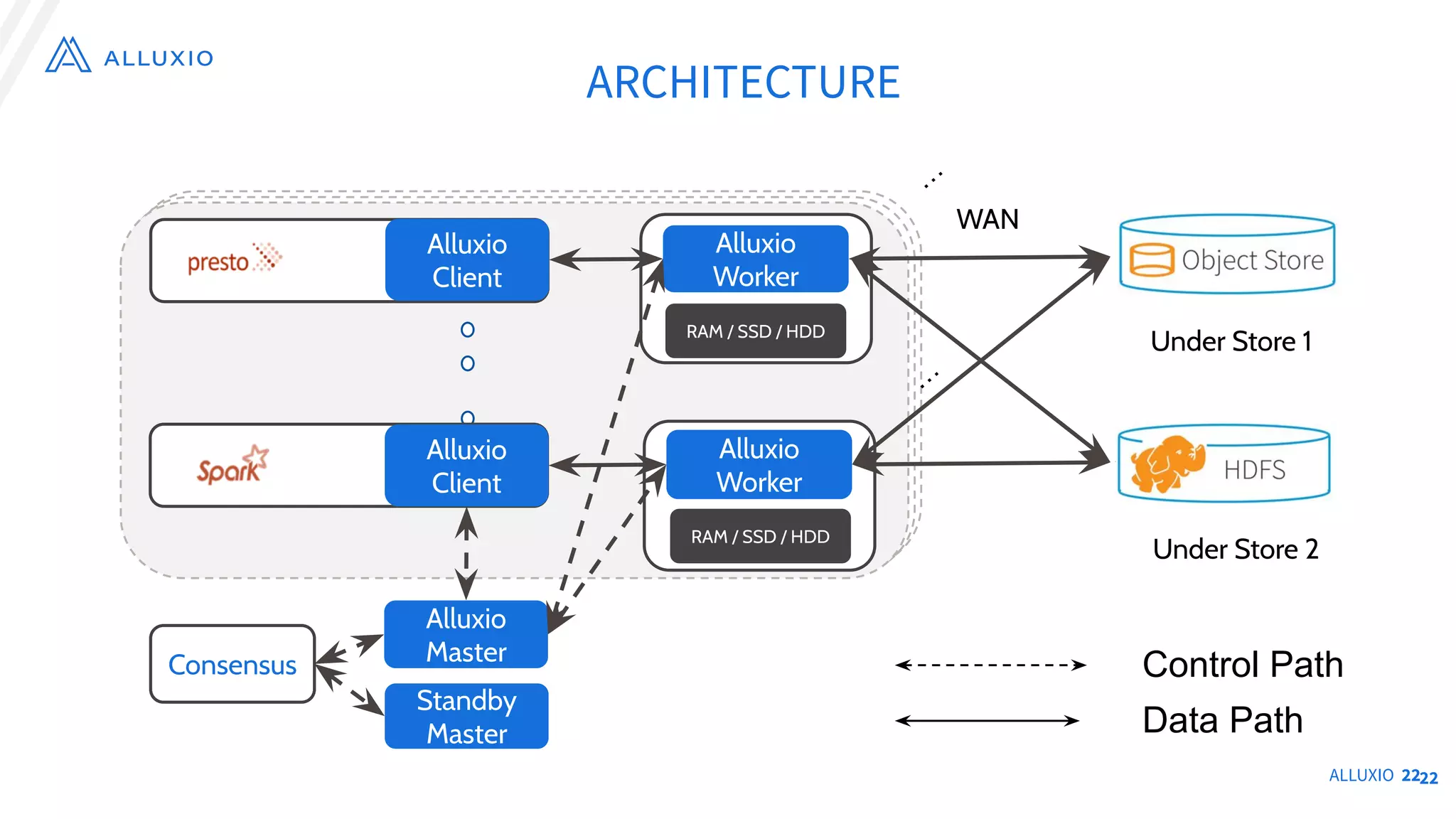
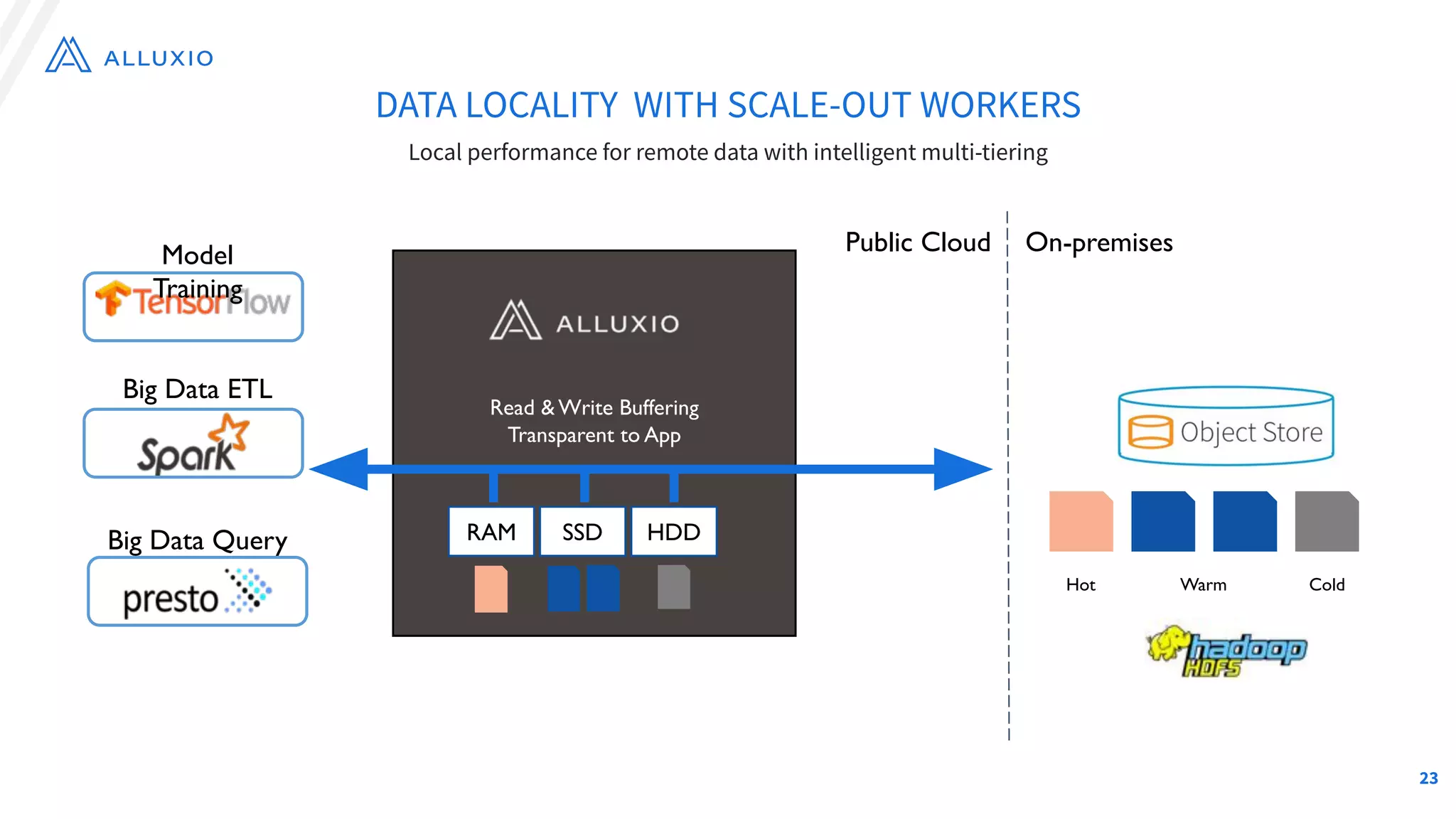
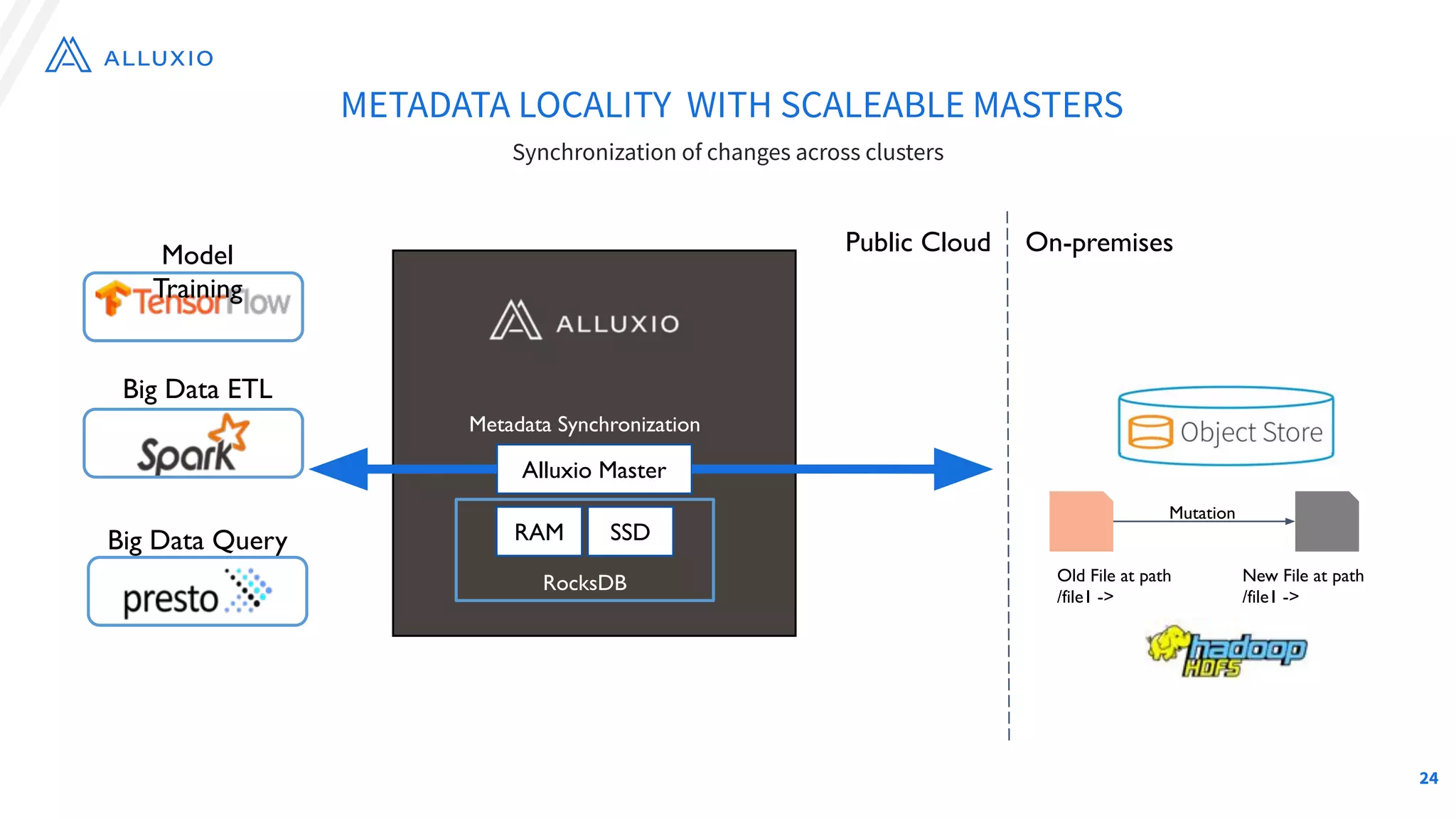
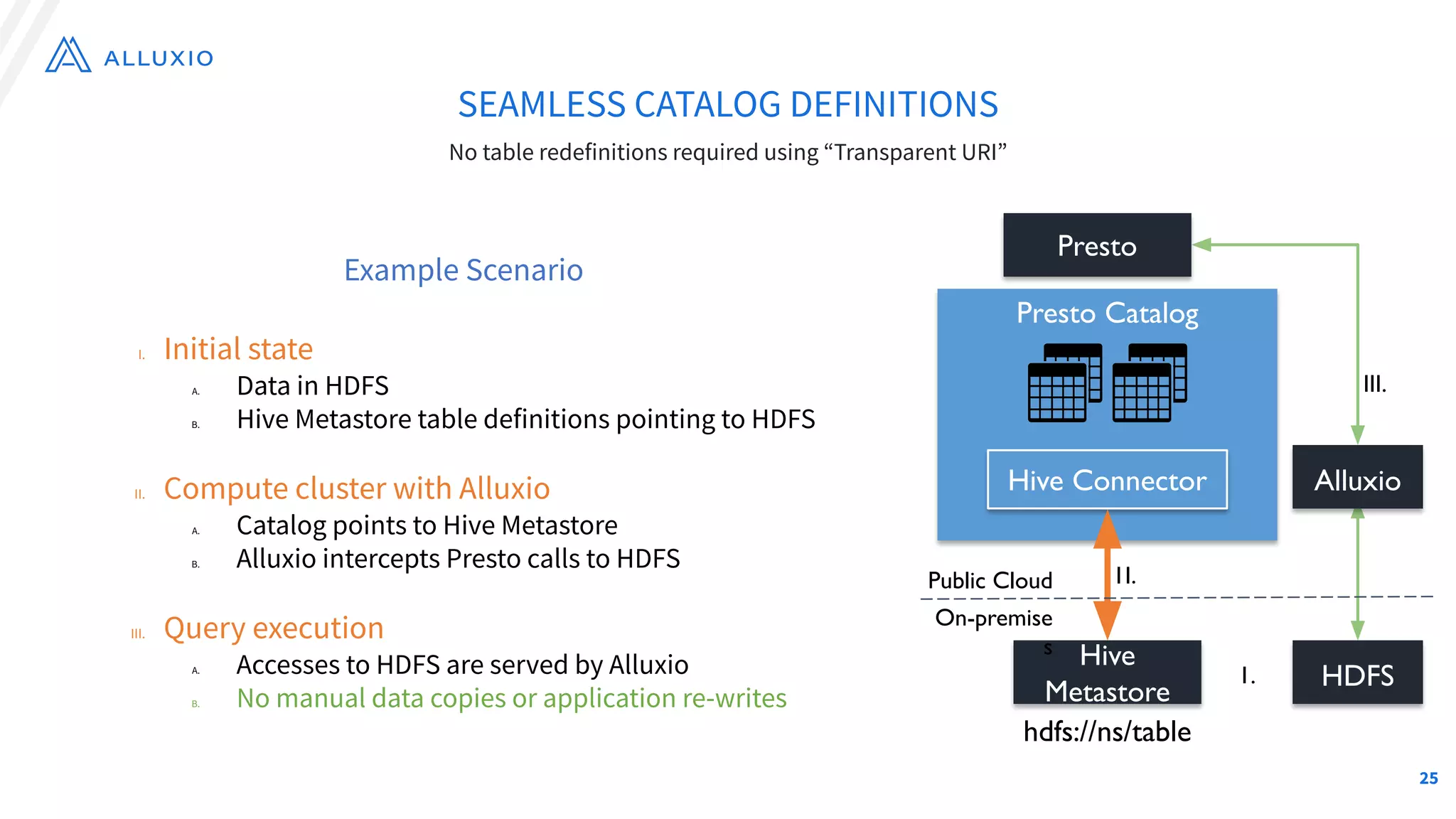
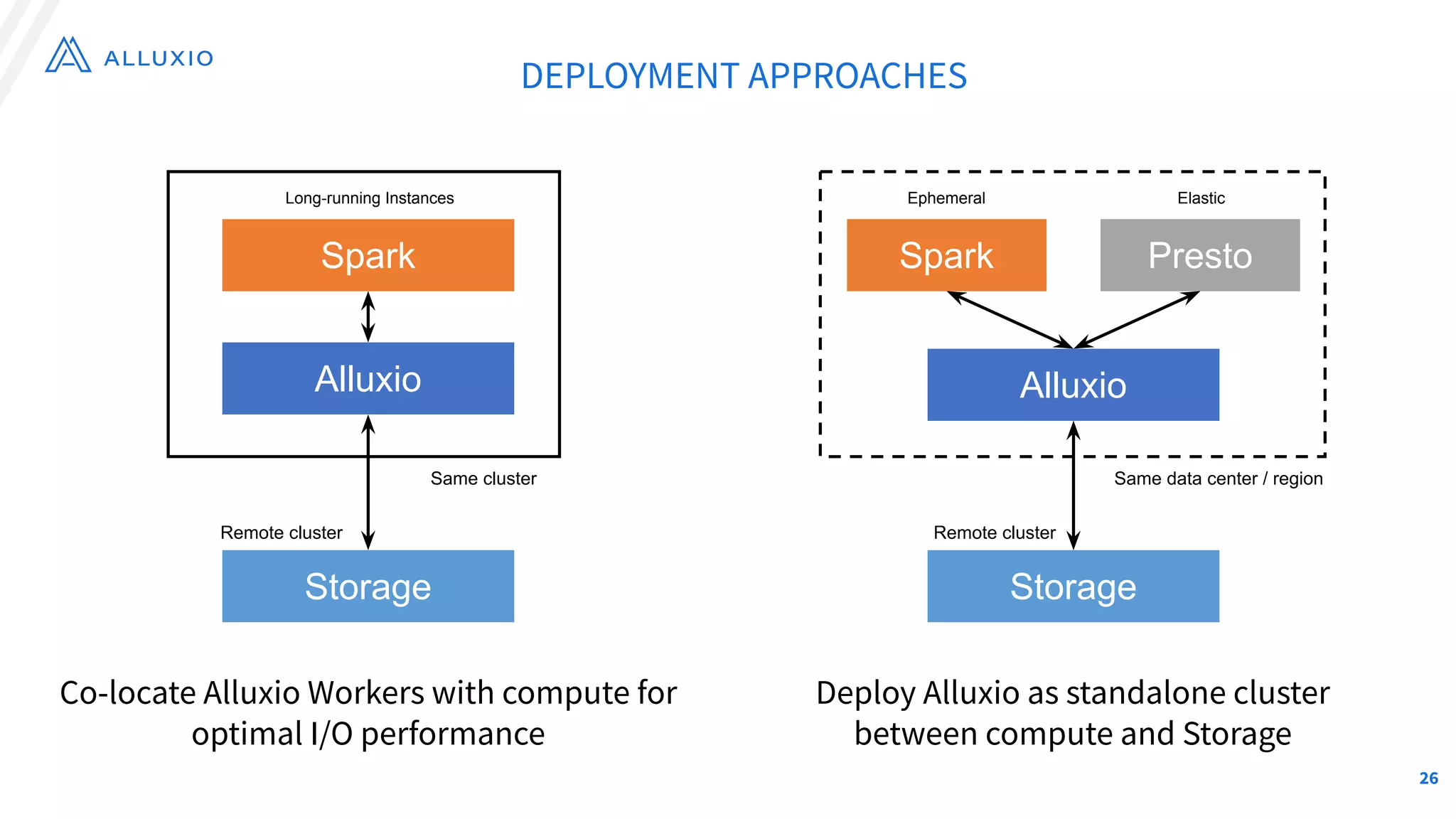
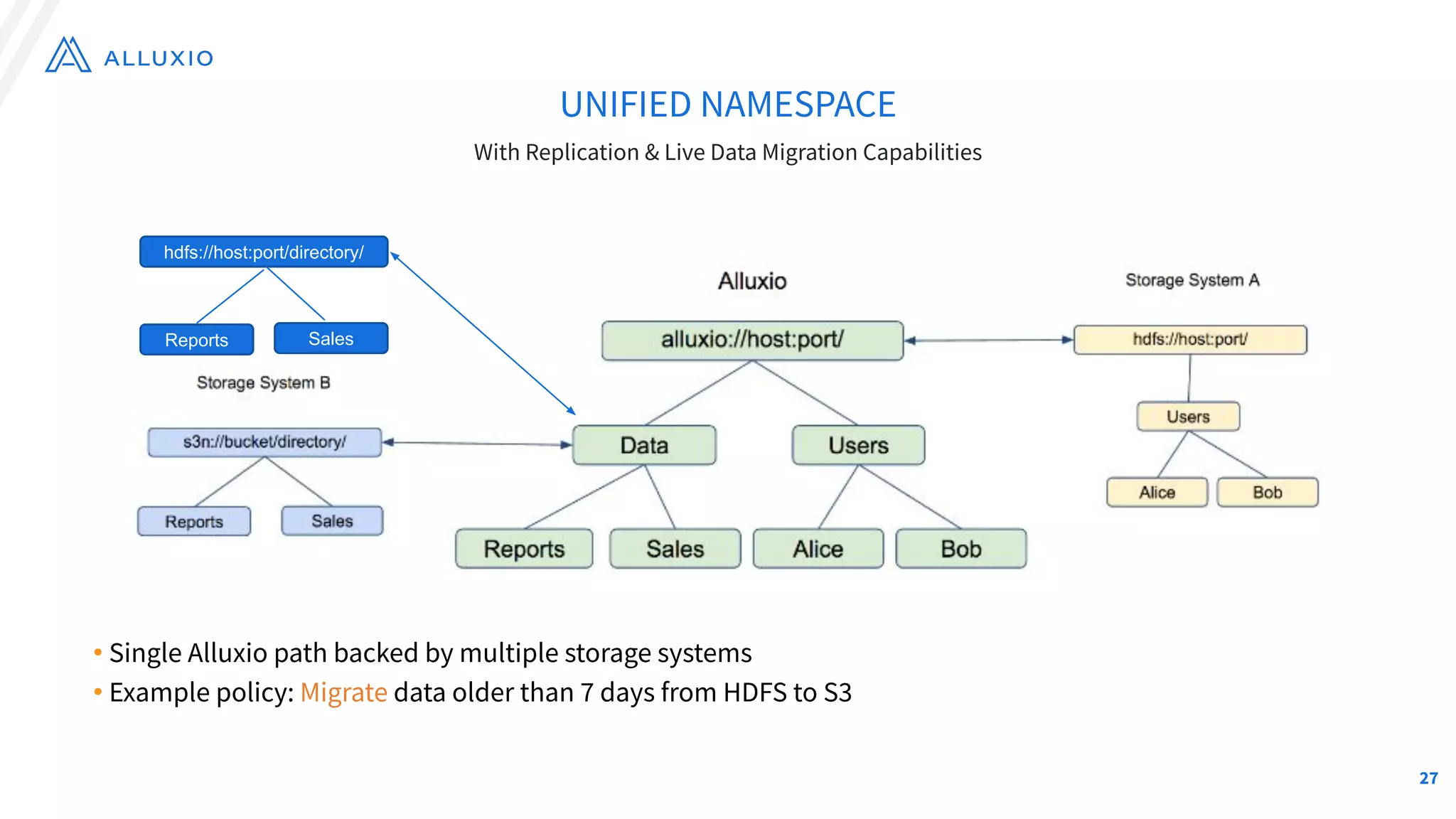



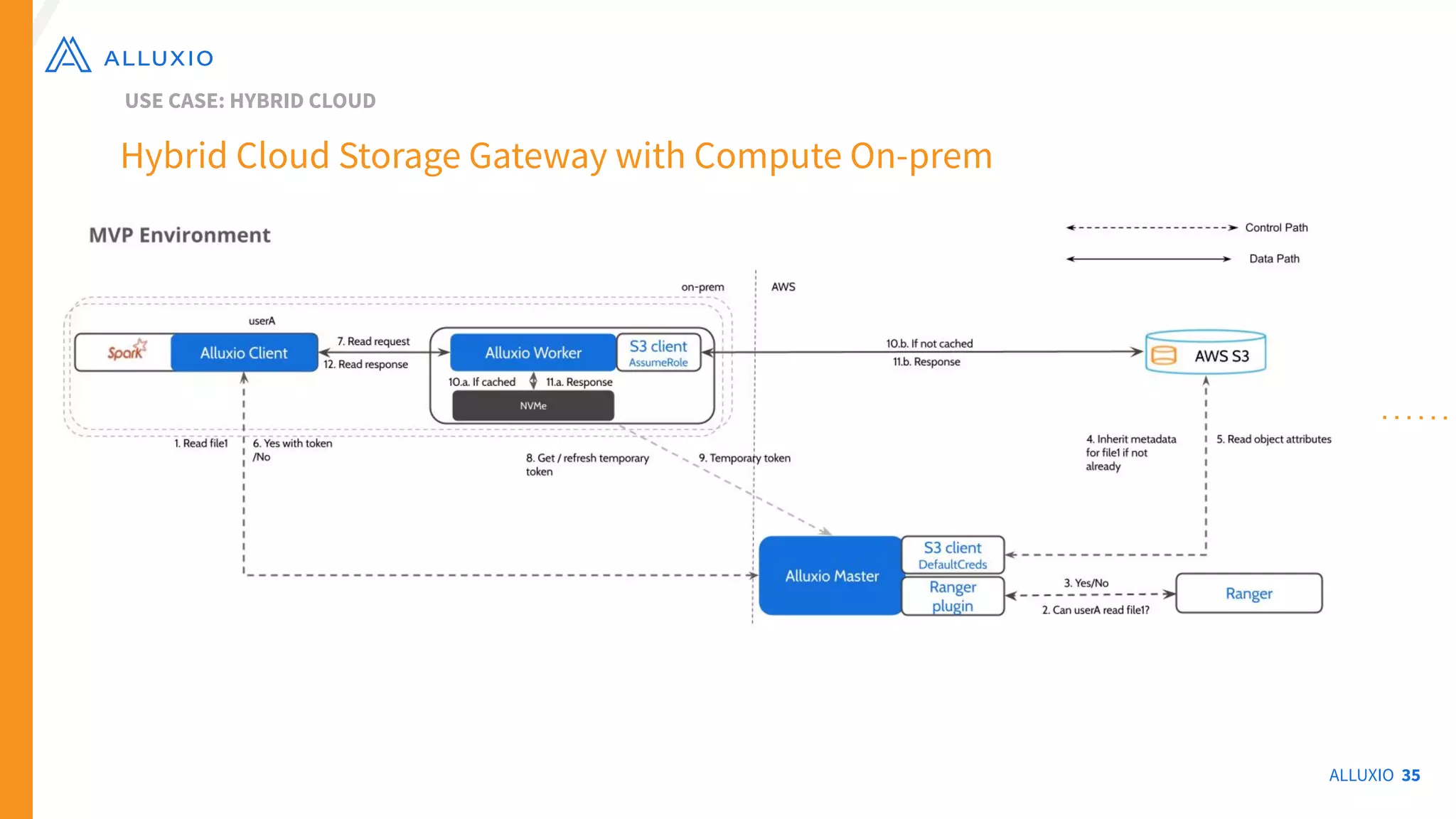
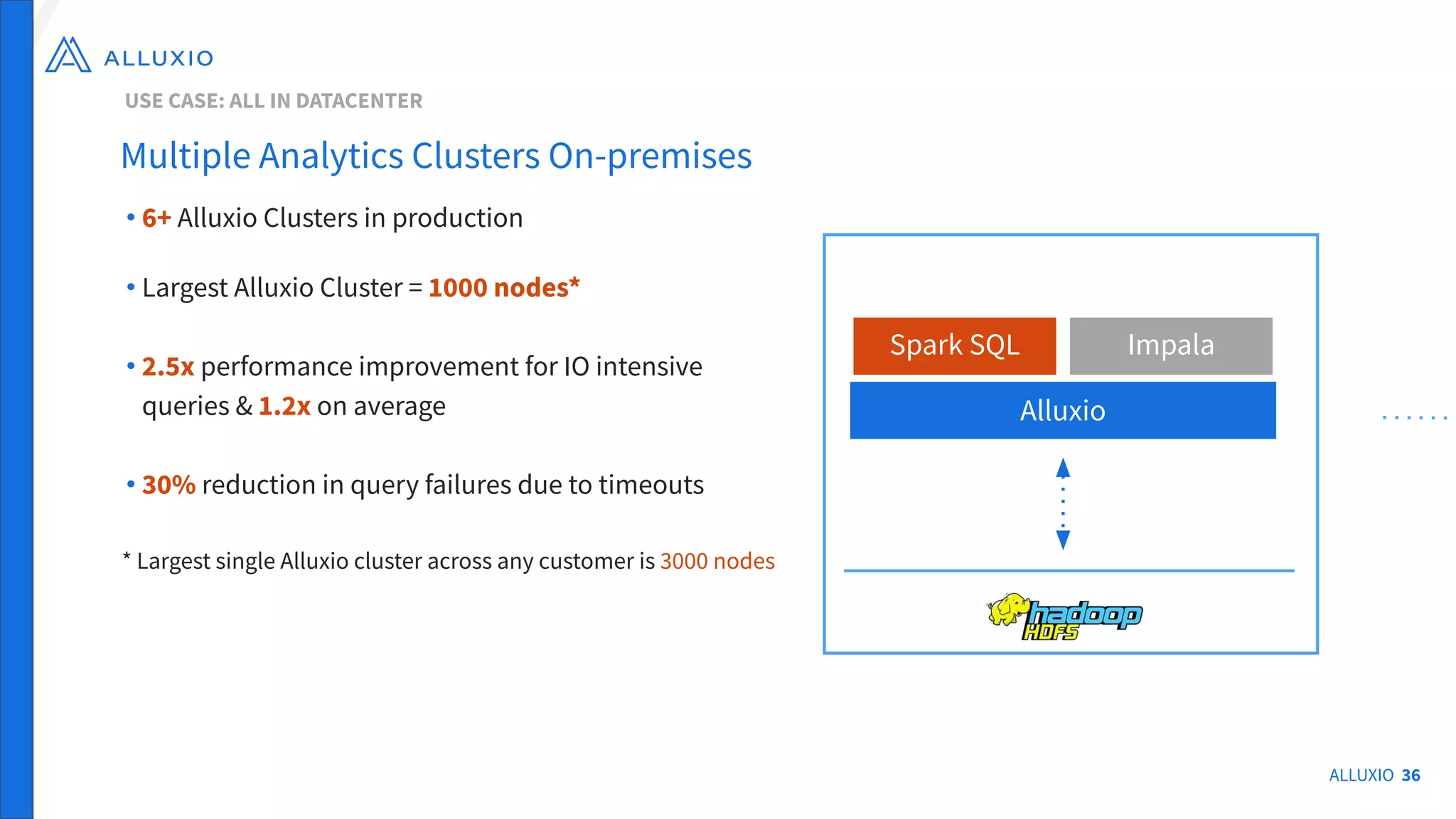

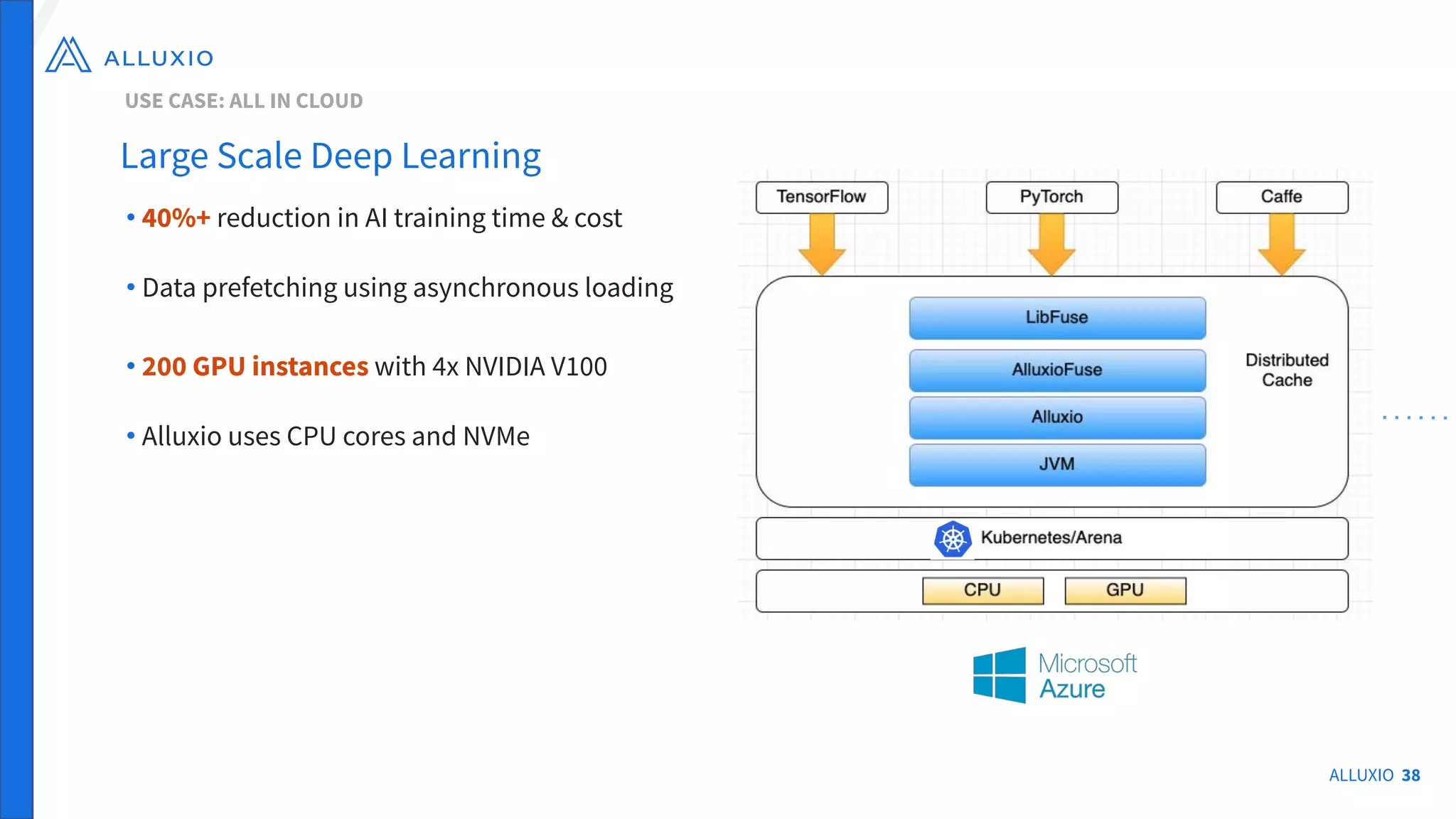
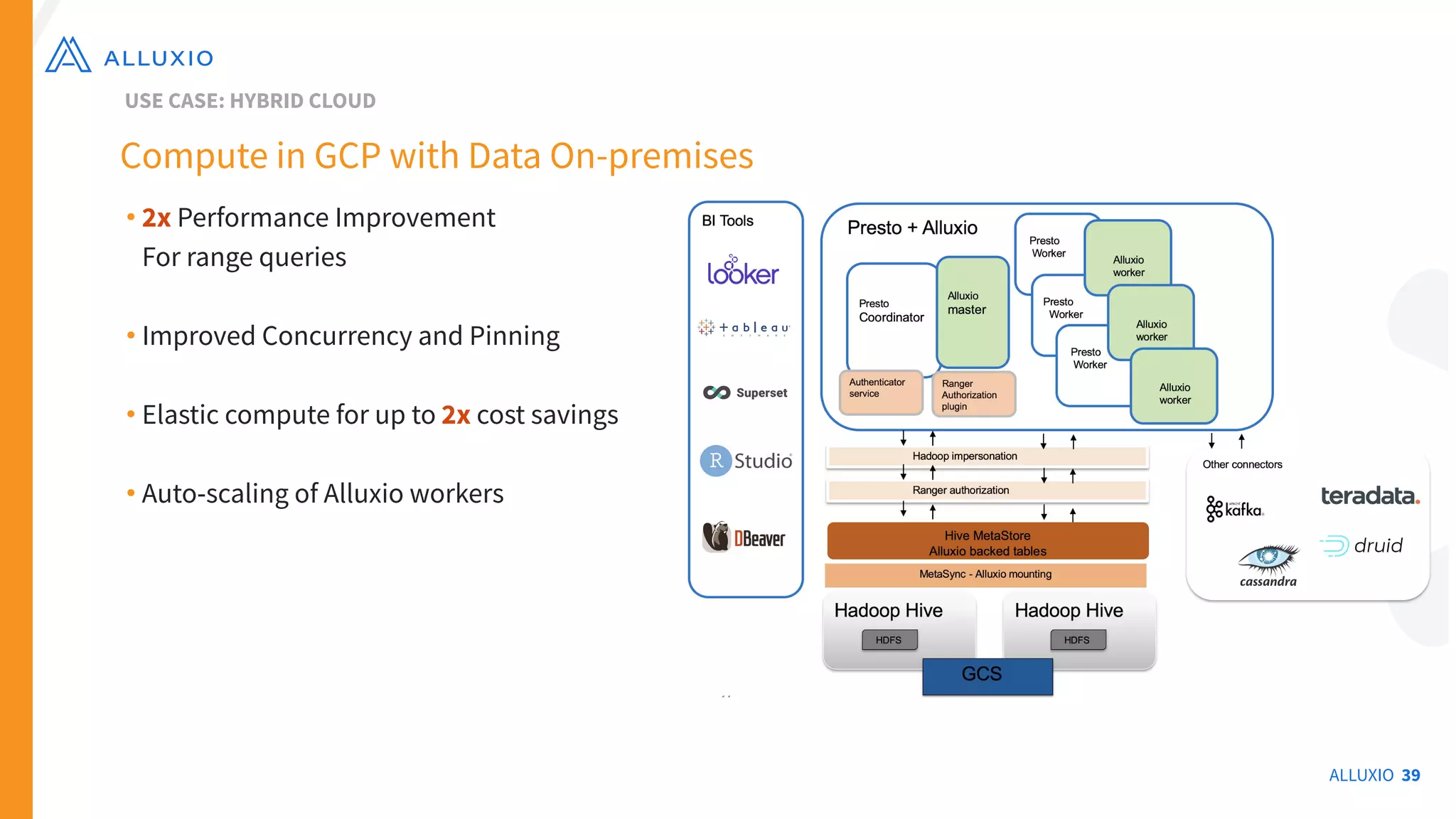
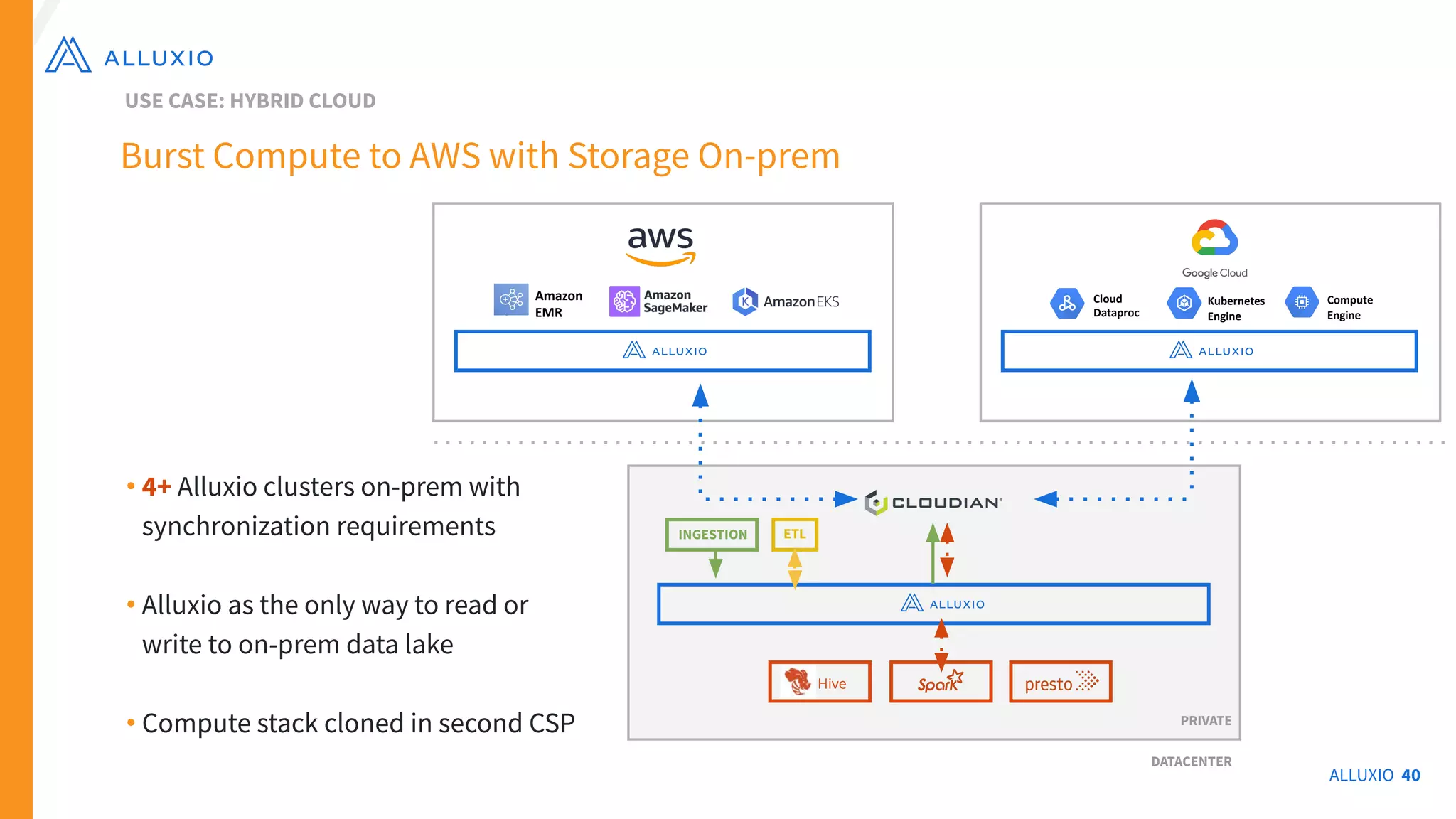
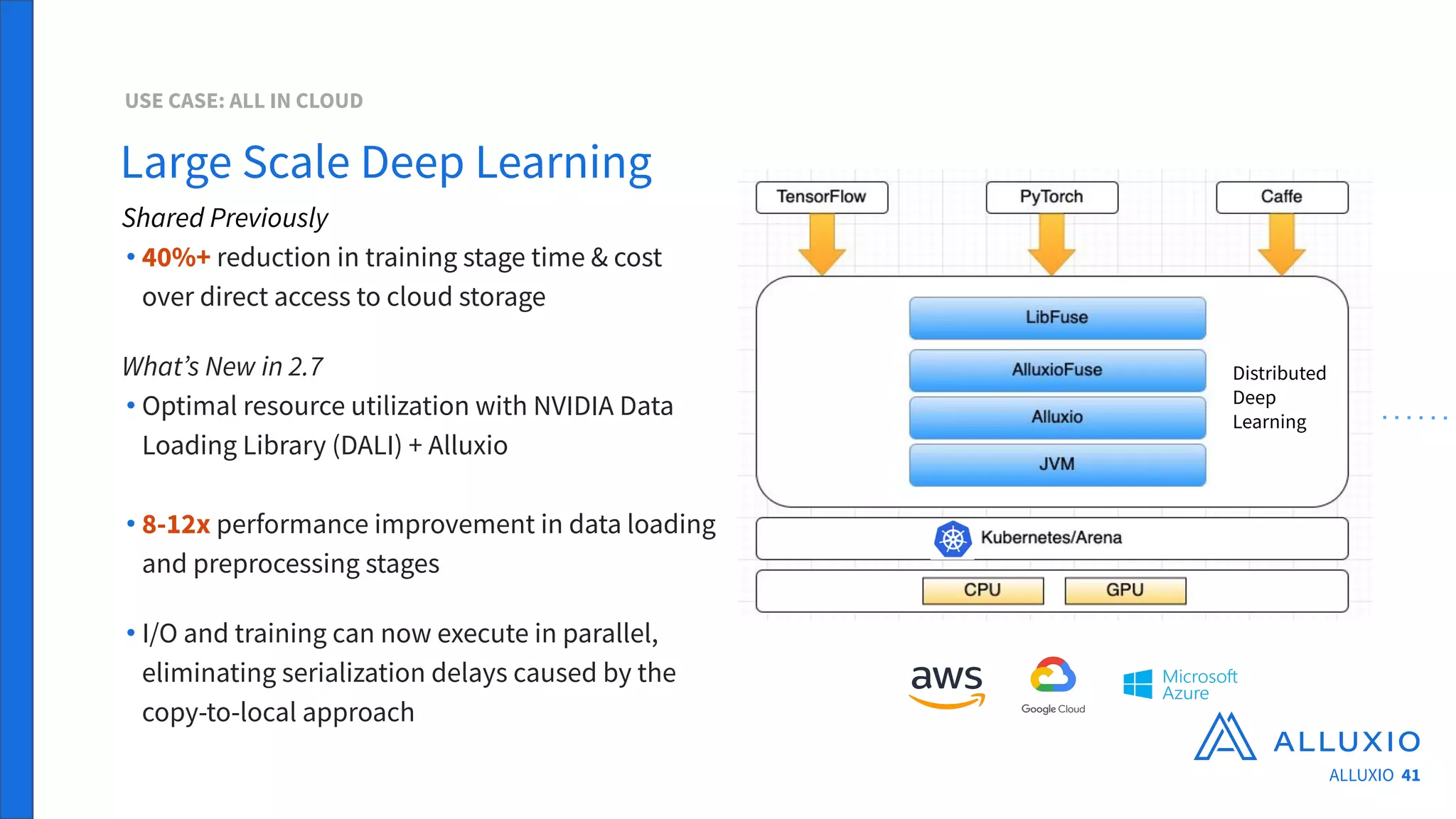
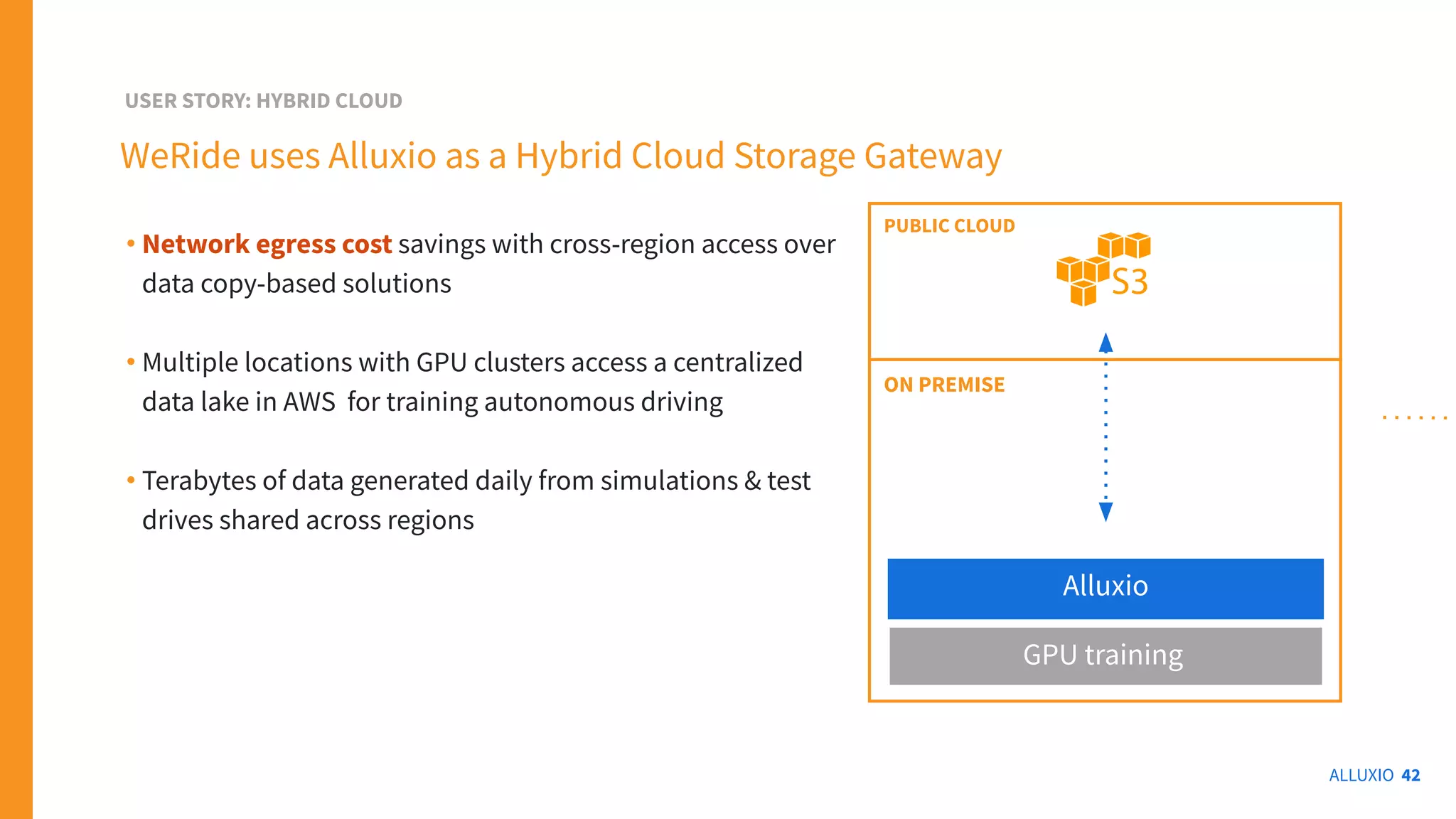


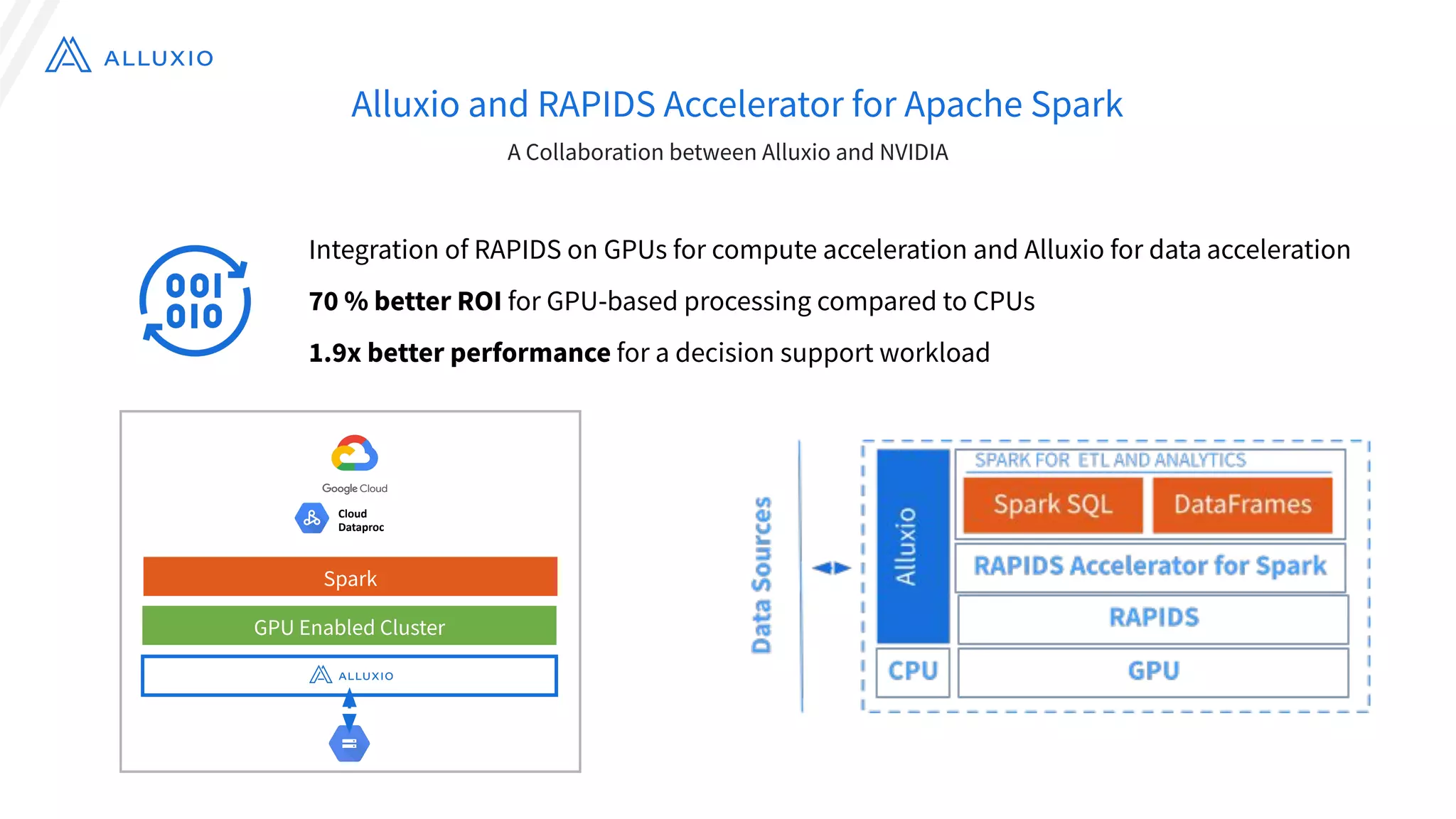

The document outlines Alluxio, a heterogeneous data platform designed to enable efficient access and management of data across diverse computing environments, including on-premises and cloud systems. It details the evolution of the platform from its inception at UC Berkeley to its current status as a critical open-source project, highlighting its extensive community involvement and real-world deployments at major companies. Alluxio addresses data silos and inefficiencies in data operations by offering capabilities like unified data access, improved analytics performance, and cost-saving solutions in hybrid and multi-cloud settings.



































































