Downloaded 32 times
























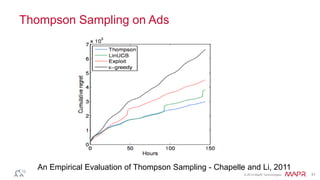























This document discusses how to determine which algorithms and techniques really matter for practical applications. It provides examples of techniques that had a big impact on recommendations, such as result dithering which improved user experience more than advances in recommendation algorithms. It also discusses how techniques like Bayesian bandits and online clustering with sketches can enable effective exploration and handle large, streaming data. Additionally, it describes how search and recommendations can recursively improve each other through indicator matrices.




























































































